This paper introduces the CBAM module, which can be easily added to the network model. The code is simple and easy to understand. The realization of CBAM module is to extract information by exerting channel attention and spatial attention successively. Today's article is also from the team of CBAM, which can be understood as the parallel connection of spatial attention mechanism and channel attention mechanism, but the specific implementation is quite different from that of CBAM. Although the code volume is relatively large, the actual content is not complex.
1. BAM
The whole process of BAM is a bottlenect attention module, which is similar to the name of CBAM. It is also a work completed by the team of CBAM.
CBAM is received by ECCV18 and BAM is received by BMVC18.
CBAM can be seen as a series of channel attention mechanism and spatial attention mechanism (channel first and then space), and BAM can be seen as a parallel of the two.
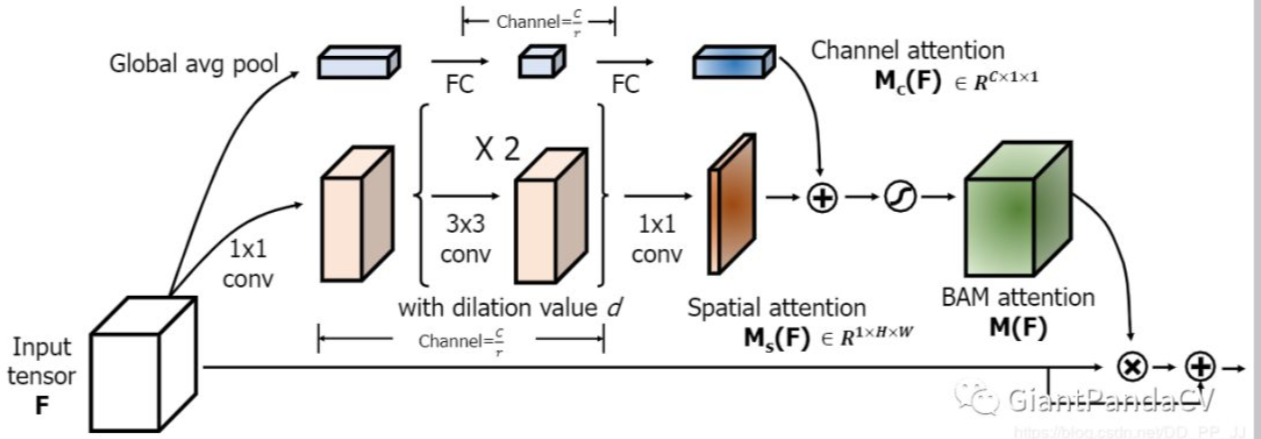
The reason why this module is called bottlenect is that it is placed before the DownSample, which is the pooling layer, as shown in the following figure:
 Transfer failureRe uploadcancel
Transfer failureRe uploadcancel
Because this paper is very similar to the previous one: the theory part of the CBM module, the algorithm implementation part is directly carried out at the bottom.
2. Realization of channel part
class Flatten(nn.Module):
def forward(self, x):
return x.view(x.size(0), -1)
class ChannelGate(nn.Module):
def __init__(self, gate_channel, reduction_ratio=16, num_layers=1):
super(ChannelGate, self).__init__()
self.gate_c = nn.Sequential()
self.gate_c.add_module('flatten', Flatten())
gate_channels = [gate_channel] # eg 64
gate_channels += [gate_channel // reduction_ratio] * num_layers # eg 4
gate_channels += [gate_channel] # 64
# gate_channels: [64, 4, 4]
for i in range(len(gate_channels) - 2):
self.gate_c.add_module(
'gate_c_fc_%d' % i,
nn.Linear(gate_channels[i], gate_channels[i + 1]))
self.gate_c.add_module('gate_c_bn_%d' % (i + 1),
nn.BatchNorm1d(gate_channels[i + 1]))
self.gate_c.add_module('gate_c_relu_%d' % (i + 1), nn.ReLU())
self.gate_c.add_module('gate_c_fc_final',
nn.Linear(gate_channels[-2], gate_channels[-1]))
def forward(self, x):
avg_pool = F.avg_pool2d(x, x.size(2), stride=x.size(2))
return self.gate_c(avg_pool).unsqueeze(2).unsqueeze(3).expand_as(x)It seems that the code is much more than the ChannelAttention module in CBAM. It's easy to compare with it by pasting the ChannelAttention Code:
class ChannelAttention(nn.Module):
def __init__(self, in_planes, rotio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.sharedMLP = nn.Sequential(
nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False), nn.ReLU(),
nn.Conv2d(in_planes // rotio, in_planes, 1, bias=False))
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avgout = self.sharedMLP(self.avg_pool(x))
maxout = self.sharedMLP(self.max_pool(x))
return self.sigmoid(avgout + maxout)First, let's talk about the processing flow of ChannelGate:
- Test with AVG? Pool2d
- >>> import torch.nn.functional as F
- >>> import torch
- >>> x = torch.ones((12, 8, 64, 64))
- >>> x.shape torch.Size([12, 8, 64, 64])
- >>> F.avg_pool2d(x,x.size(2), stride=x.size(2)).shape torch.Size([12, 8, 1, 1])
- >>>The effect is the same as adaptive avgpool2d (1).
- Then through the gate ﹣ C module, the inner part is changed into a [batch size, channel] shaped sensor through Flatten, and then the rear part is Linear module for Linear transformation. (ps: Although the code looks many, but the function is simple) this part is a little similar to the SE module, but multiple Linear layers can be added, which contains more information.
- Finally, according to the shape of the input sensor x, we can get the attention of the channel.
Then I'll talk about the difference with channel attention in CBM:
- In CBM, adaptive avgpooling is used first, and then channel processing is implemented by convolution; in BAM, adaptive avgpooling is also used, and then multiple Linear transformations are performed to obtain channel attention. In fact, when the feature map size is 11, there is no difference between the two in terms of mathematical principles. Specifically, we can refer to the question of knowledge: what are the similarities and differences between 1 × 1 convolution kernel and full connection layer?
- sigmoid is used for activation function in CBM, ReLU is used for channel part in BAM, and BN layer is added.
3. Spatial attention mechanism
class SpatialGate(nn.Module):
def __init__(self,
gate_channel,
reduction_ratio=16,
dilation_conv_num=2,
dilation_val=4):
super(SpatialGate, self).__init__()
self.gate_s = nn.Sequential()
self.gate_s.add_module(
'gate_s_conv_reduce0',
nn.Conv2d(gate_channel,
gate_channel // reduction_ratio,
kernel_size=1))
self.gate_s.add_module('gate_s_bn_reduce0',
nn.BatchNorm2d(gate_channel // reduction_ratio))
self.gate_s.add_module('gate_s_relu_reduce0', nn.ReLU())
# Multiple empty convolutions enrich the receptive field
for i in range(dilation_conv_num):
self.gate_s.add_module(
'gate_s_conv_di_%d' % i,
nn.Conv2d(gate_channel // reduction_ratio,
gate_channel // reduction_ratio,
kernel_size=3,
padding=dilation_val,
dilation=dilation_val))
self.gate_s.add_module(
'gate_s_bn_di_%d' % i,
nn.BatchNorm2d(gate_channel // reduction_ratio))
self.gate_s.add_module('gate_s_relu_di_%d' % i, nn.ReLU())
self.gate_s.add_module(
'gate_s_conv_final',
nn.Conv2d(gate_channel // reduction_ratio, 1, kernel_size=1))
def forward(self, x):
return self.gate_s(x).expand_as(x)It can be seen here that the code volume is much larger than the spatial attention in CBM, and the comparison is still made:
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3,7), "kernel size must be 3 or 7"
padding = 3 if kernel_size == 7 else 1
self.conv = nn.Conv2d(2,1,kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avgout = torch.mean(x, dim=1, keepdim=True)
maxout, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avgout, maxout], dim=1)
x = self.conv(x)
return self.sigmoid(x)This part of spatial attention processing has its own characteristics. First, let's talk about the process in BAM:
- After a conv+bn+relu module, the channel is indented and the information is compressed.
- After that, the void ratio is set to 4 (the default) through multiple dilated conv+bn+relu modules.
- Finally, after a convolution, the channel is compressed to 1.
- Finally, it is extended to the shape of sensor X.
The difference is:
- In CBAM, the max and AVG between channels are processed into a feature with two channels, and then the final map is obtained by convolution + Sigmoid
- In BAM, the information processing is completed by convolution or hole convolution, which is more computationally intensive, but the information is more abundant because of the fusion of multiple receptive fields.
4. BAM fusion
class BAM(nn.Module):
def __init__(self, gate_channel):
super(BAM, self).__init__()
self.channel_att = ChannelGate(gate_channel)
self.spatial_att = SpatialGate(gate_channel)
def forward(self, x):
att = 1 + F.sigmoid(self.channel_att(x) * self.spatial_att(x))
return att * xThe final fusion is very simple. It should be noted that the two are multiplied and normalized by sigmoid.
Thank: https://cloud.tencent.com/developer/article/1582038 I don't know how to reprint it. I copied it directly. Please forgive me

