Note: Both commit() and execute() of database pymysql submit data synchronously to the database when submitting data. Because of the resolution of scrapy framework data and the asynchronous multi-threaded, scrapy's data resolution speed is much higher than the speed at which data is written to the database.If the data is written too slowly, it will block the database write and affect the efficiency of the database write.
Writing data asynchronously through multiple threads can improve data writing speed.
Use the twsited asynchronous IO framework to write data asynchronously.
Parameter format in code: * means tuple, ** means dictionary (fixed writing!Non-Custom!)
Sample code:
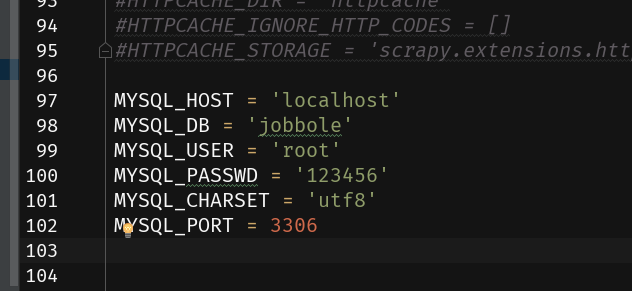
Configure the database parameters in settings.py as follows:
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
from scrapy.pipelines.images import ImagesPipeline
class JobbolePipeline(object):
def process_item(self, item, spider):
return item
# Define a Pipline to process pictures
class ImagePipeline(ImagesPipeline):
def item_completed(self, results, item, info):
print('---',results)
return item
# If the pictures are downloaded successfully, this article has pictures.If there is no path path in results, there are no pictures.
# [(True, {'path': ''})]
# if results:
# try:
# img_path = results[0][1]['path']
# except Exception as e:
# print('img_path get exception,', e)
# img_path ='No Pictures'
# else:
# img_path ='No Pictures'
# Once the judgment is complete, the variable img_path needs to be saved back into the item.
# Both commit() and execute() of database pymysql submit data synchronously to the database when submitting data. Because of the resolution of scrapy framework data and the asynchronous multi-threaded, scrapy's data resolution speed is much higher than the speed at which data is written to the database.If the data is written too slowly, it will block the database write and affect the efficiency of the database write.
# Writing data asynchronously through multiple threads can improve data writing speed.
from pymysql import cursors
# Use the twsited asynchronous IO framework to write data asynchronously.
from twisted.enterprise import adbapi
class MySQLTwistedPipeline(object):
"""
MYSQL_HOST = 'localhost'
MYSQL_DB = 'jobbole'
MYSQL_USER = 'root'
MYSQL_PASSWD = '123456'
MYSQL_CHARSET = 'utf8'
MYSQL_PORT = 3306
"""
def __init__(self, dbpool):
self.dbpool = dbpool
@classmethod
def from_settings(cls, settings):
params = dict(
host=settings['MYSQL_HOST'],
db=settings['MYSQL_DB'],
user=settings['MYSQL_USER'],
passwd=settings['MYSQL_PASSWD'],
charset=settings['MYSQL_CHARSET'],
port=settings['MYSQL_PORT'],
cursorclass=cursors.DictCursor,
)
# Initialize database connection pool (thread pool)
# Parameter 1: Driver for mysql
# Parameter 2: Configuration information for connecting mysql
dbpool = adbapi.ConnectionPool('pymysql', **params)
return cls(dbpool)
def process_item(self, item, spider):
# Within this function, the connection pool object is used to start manipulating the data and writing it to the database.
# pool.map(self.insert_db, [1,2,3])
# Synchronization blocking method: cursor.execute() commit()
# Asynchronous and non-blocking
# Parameter 1: function insert_db to be executed in asynchronous tasks;
# Parameter 2: The parameter passed to the function insert_db
query = self.dbpool.runInteraction(self.insert_db, item)
# If an asynchronous task fails to execute, you can listen through ErrBack() to add a callback event to insert_db that fails to execute
query.addErrback(self.handle_error)
return item
def handle_error(self, field):
print('-----Database write failure:',field)
def insert_db(self, cursor, item):
insert_sql = "INSERT INTO bole(title, date_time, tags, content, zan_num, keep_num, comment_num, img_src) VALUES (%s, %s, %s, %s, %s, %s, %s, %s)"
cursor.execute(insert_sql, (item['title'], item['date_time'], item['tags'], item['content'], item['zan_num'], item['keep_num'], item['comment_num'], item['img_src']))
# After execute(), commit() is no longer required, and commit operations occur within the connection pool.