An asynchronous agent pool is implemented using python asyncio. The free agent on the agent website is crawled according to the rules and stored in redis after verifying its validity. The number of agents is regularly expanded and the validity of agents in the pool is checked to remove invalid agents. At the same time, a server is implemented with aiohttp, and other programs can access the corresponding url to get the agent from the agent pool.
Source code
Environmental Science
- Python 3.5+
- Redis
- Phantom JS (optional)
- Supervisord (optional)
Because async and await grammars of asyncio are widely used in the code, they are only provided in Python 3.5, so it's better to use Python 3.5 or more, I use Python 3.6.
rely on
- redis
- aiohttp
- bs4
- lxml
- requests
- selenium
The selenium package is mainly used to operate on Phantom JS.
The code is described below.
1. Reptilian part
Core code
async def start(self):
for rule in self._rules:
parser = asyncio.ensure_future(self._parse_page(rule)) # Parse pages to get proxies according to rules
logger.debug('{0} crawler started'.format(rule.__rule_name__))
if not rule.use_phantomjs:
await page_download(ProxyCrawler._url_generator(rule), self._pages, self._stop_flag) # Climbing the pages of Real Web Sites
else:
await page_download_phantomjs(ProxyCrawler._url_generator(rule), self._pages,
rule.phantomjs_load_flag, self._stop_flag) # Crawling with Phantom JS
await self._pages.join()
parser.cancel()
logger.debug('{0} crawler finished'.format(rule.__rule_name__))The core code above is actually a production-consumer model implemented with asyncio.Queue. The following is a simple implementation of the model:
import asyncio
from random import random
async def produce(queue, n):
for x in range(1, n + 1):
print('produce ', x)
await asyncio.sleep(random())
await queue.put(x) # Put item s in queue
async def consume(queue):
while 1:
item = await queue.get() # Waiting to get item from queue
print('consume ', item)
await asyncio.sleep(random())
queue.task_done() # Notify queue that the current item has been processed
async def run(n):
queue = asyncio.Queue()
consumer = asyncio.ensure_future(consume(queue))
await produce(queue, n) # Waiting for the end of the producer
await queue.join() # Block until queue is not empty
consumer.cancel() # Cancel the consumer task, otherwise it will always block the get method
def aio_queue_run(n):
loop = asyncio.get_event_loop()
try:
loop.run_until_complete(run(n)) # Continue running event loop until task run(n) ends
finally:
loop.close()
if __name__ == '__main__':
aio_queue_run(5)Running the above code, one possible output is as follows:
produce 1 produce 2 consume 1 produce 3 produce 4 consume 2 produce 5 consume 3 consume 4 consume 5
Crawl page
async def page_download(urls, pages, flag):
url_generator = urls
async with aiohttp.ClientSession() as session:
for url in url_generator:
if flag.is_set():
break
await asyncio.sleep(uniform(delay - 0.5, delay + 1))
logger.debug('crawling proxy web page {0}'.format(url))
try:
async with session.get(url, headers=headers, timeout=10) as response:
page = await response.text()
parsed = html.fromstring(decode_html(page)) # Use bs4 To assist lxml Decoding web pages:http://lxml.de/elementsoup.html#Using only the encoding detection
await pages.put(parsed)
url_generator.send(parsed) # Get the address of the next page based on the current page
except StopIteration:
break
except asyncio.TimeoutError:
logger.error('crawling {0} timeout'.format(url))
continue # TODO: use a proxy
except Exception as e:
logger.error(e)
Using aiohttp web crawling function, most proxy websites can use the above method to crawl, for websites using js dynamic page generation can use selenium control PhantomJS To crawl - This project does not require high efficiency of crawlers, the update frequency of proxy websites is limited, do not need frequent crawling, can fully use Phantom JS.
Analytical agent
The simplest way is to parse the proxy with xpath. If you use Chrome browser, you can get the XPath of the selected page elements directly by right-clicking.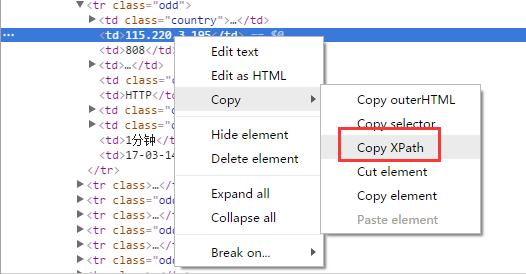
Installing Chrome's extension "XPath Helper" allows you to run and debug xpath directly on the page, which is very convenient: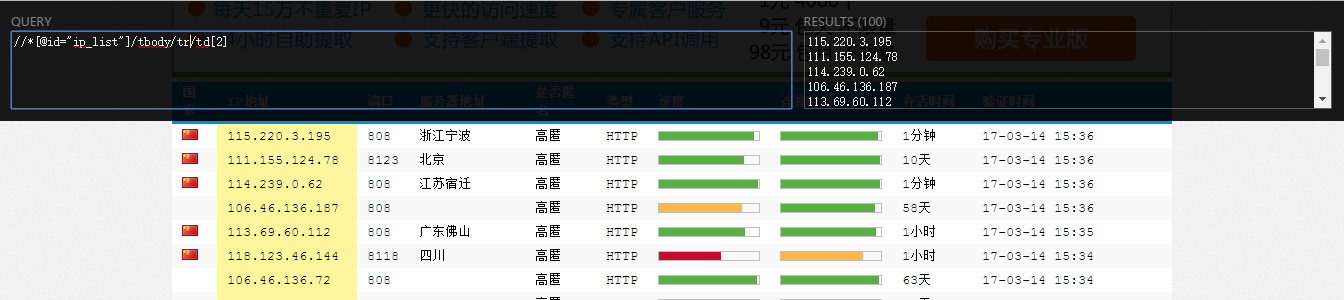
Beautiful Soup does not support xpath. It uses lxml to parse the page. The code is as follows:
async def _parse_proxy(self, rule, page):
ips = page.xpath(rule.ip_xpath) # Parsing ip address set of list type according to xpath
ports = page.xpath(rule.port_xpath) # Parsing ip address set of list type according to xpath
if not ips or not ports:
logger.warning('{2} crawler could not get ip(len={0}) or port(len={1}), please check the xpaths or network'.
format(len(ips), len(ports), rule.__rule_name__))
return
proxies = map(lambda x, y: '{0}:{1}'.format(x.text.strip(), y.text.strip()), ips, ports)
if rule.filters: # Filtering agents based on filtering fields, such as "high concealment" and "transparency"
filters = []
for i, ft in enumerate(rule.filters_xpath):
field = page.xpath(ft)
if not field:
logger.warning('{1} crawler could not get {0} field, please check the filter xpath'.
format(rule.filters[i], rule.__rule_name__))
continue
filters.append(map(lambda x: x.text.strip(), field))
filters = zip(*filters)
selector = map(lambda x: x == rule.filters, filters)
proxies = compress(proxies, selector)
for proxy in proxies:
await self._proxies.put(proxy) # The parsed proxy is put into asyncio.QueueCrawler rule
Rules for website crawling, proxy parsing, filtering and so on are defined by the rule classes of each proxy website, which use metaclass and base class to manage the rule classes. The base class is defined as follows:
class CrawlerRuleBase(object, metaclass=CrawlerRuleMeta):
start_url = None
page_count = 0
urls_format = None
next_page_xpath = None
next_page_host = ''
use_phantomjs = False
phantomjs_load_flag = None
filters = ()
ip_xpath = None
port_xpath = None
filters_xpath = ()The meaning of each parameter is as follows:
-
Start_url (required)
The crawler's start page. -
Ip_xpath (required)
Crawl the xpath rule of IP. -
Port_xpath (required)
The xpath rule for crawling port numbers. -
page_count
Number of pages crawled. -
urls_format
The format string of page address generates the address of page n through urls_format.format(start_url, n), which is a common page address format. -
next_page_xpath,next_page_host
The URL of the next page is obtained by xpath rule (usually relative path), and the address of the next page is obtained by combining host: next_page_host + url. -
use_phantomjs, phantomjs_load_flag
use_phantomjs is used to identify whether Phantom JS is needed to crawl the site. If used, phantomjs_load_flag (an element on the web page, str type) is defined as the symbol of the loading of the Phantom JS page. -
filters
Filter field sets, iterative types. Used for filtering agents.
The xpath rules of each filter field are crawled and correspond to the filter field one by one in order.
The metaclass CrawlerRuleMeta is used to manage the definition of rule classes. For example, if you define use_phantomjs=True, you must define phantomjs_load_flag, otherwise an exception will be thrown, which will not be repeated here.
The rules that have been implemented are West thorn agent,Quick acting,360 agency,66 agency and Secret agent . Adding a new rule class is also simple. You define a new rule class YourRuleClass by inheriting Crawler RuleBase, place it in the proxy pool/rules directory, and add from. import YourRuleClass in the _init_ py directory (so you can get all the rule classes through Crawler RuleBase. _subclasses_(), restart the running proxy pool and apply the new rule.
2. Inspection section
Although there are many free agents, there are not many available ones, so it is necessary to check them after crawling into the agent pool, so that an effective agent can be put into the agent pool, and the agent is also time-effective, and the agent in the pool should be checked regularly to remove the invalid agent in time.
This part is very simple, using aiohttp to access a website through a proxy, if the time-out, the proxy is invalid.
async def validate(self, proxies):
logger.debug('validator started')
while 1:
proxy = await proxies.get()
async with aiohttp.ClientSession() as session:
try:
real_proxy = 'http://' + proxy
async with session.get(self.validate_url, proxy=real_proxy, timeout=validate_timeout) as resp:
self._conn.put(proxy)
except Exception as e:
logger.error(e)
proxies.task_done()3. server section
A web server is implemented using aiohttp. After startup, the home page can be displayed by visiting http://host:port:
- Visit http://host:port/get to get a proxy from the proxy pool, such as:'127.0.0.1:1080';
- Visit http://host:port/get/n to get n agents from the agent pool, such as: "['127.0.0.1:1080','127.0.0.1:443','127.0.1:80']";
- Visit http://host:port/count to get the capacity of the proxy pool, such as:'42'.
Because the home page is a static html page, in order to avoid the overhead of opening, reading and closing the html file every time a request to visit the home page, it is cached in redis. The modification time of the html file is used to judge whether it has been modified or not. If the modification time is different from that of the redis cache, the html file is read again. And update the cache, otherwise get the content of the home page from redis.
The return agent is implemented by aiohttp.web.Response(text=ip.decode('utf-8'). Text requires str type, while the bytes type is obtained from redis and needs to be converted. Multiple agents returned can be converted to list type using eval.
Returning to the home page is different through aiohttp.web.Response(body=main_page_cache, content_type='text/html'), where body requires bytes type, which directly returns the cache retrieved from redis. conten_type='text/html'is indispensable. Otherwise, the home page cannot be loaded through browser, but will be downloaded when running the sample code in the official document. Note that the sample code basically does not set content_type.
This part is not complicated. Note the points mentioned above. For the path of static resource files used on the home page, you can refer to the previous blog.< Adding static resource paths to aiohttp>.
4. operation
The function of the whole agent pool is divided into three separate parts:
- proxypool
Check the capacity of the agent pool regularly. If it is below the lower limit, start the agent crawler and check the agent. The tested crawler is put into the agent pool, and stop the crawler when it reaches the required number. - proxyvalidator
It is used to periodically inspect agents in the agent pool and remove invalid agents. - proxyserver
Start the server.
These three separate tasks run through three processes, which can be managed using supervisod under Linux. Here is an example of supervisord configuration file:
; supervisord.conf [unix_http_server] file=/tmp/supervisor.sock [inet_http_server] port=127.0.0.1:9001 [supervisord] logfile=/tmp/supervisord.log logfile_maxbytes=5MB logfile_backups=10 loglevel=debug pidfile=/tmp/supervisord.pid nodaemon=false minfds=1024 minprocs=200 [rpcinterface:supervisor] supervisor.rpcinterface_factory = supervisor.rpcinterface:make_main_rpcinterface [supervisorctl] serverurl=unix:///tmp/supervisor.sock [program:proxyPool] command=python /path/to/ProxyPool/run_proxypool.py redirect_stderr=true stdout_logfile=NONE [program:proxyValidator] command=python /path/to/ProxyPool/run_proxyvalidator.py redirect_stderr=true stdout_logfile=NONE [program:proxyServer] command=python /path/to/ProxyPool/run_proxyserver.py autostart=false redirect_stderr=true stdout_logfile=NONE
Because the project itself has logs configured, there is no need to capture stdout and stderr with supervisor. When supervisord is started through supervisord-c supervisord.conf, proxy Pool and proxy Server will start automatically. Proxy Server needs to start manually. Visiting http://127.0.0.1:9001, you can manage these three processes through web pages: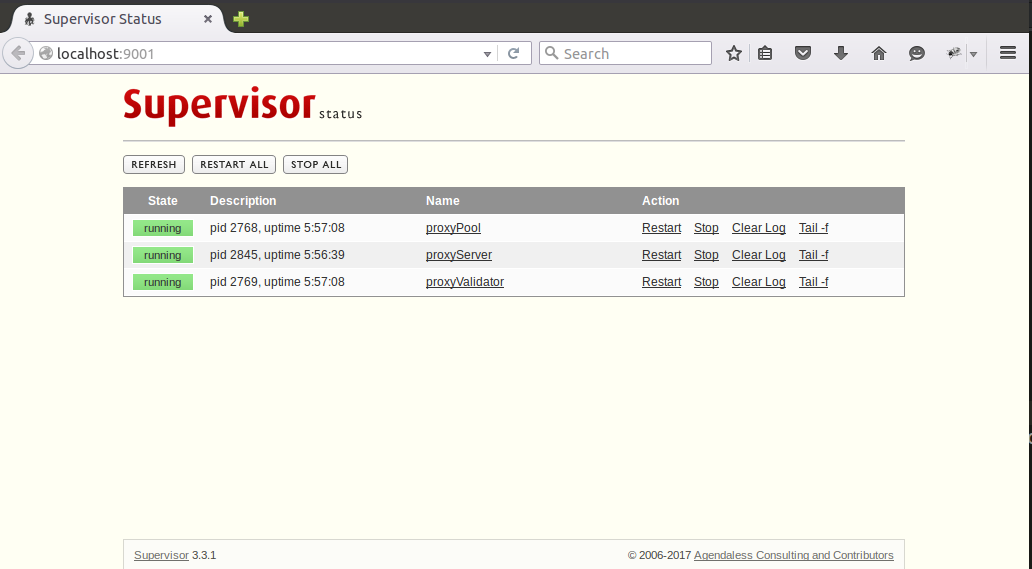
supervisod Official documents At present (version 3.3.1) does not support Python 3, but I did not find any problems in using it. Maybe because I did not use the complex function of supervisor, I just used it as a simple tool for process status monitoring and start-stop.