This article mainly records the understanding of * * aspect level sentient classification with heat (hierarchitectual attachment) * * paper and mainly explains its model.
This model proposes a two-layer Attention network based on aspect word for classification. The two-layer Attention first learns aspect information from sentences, and then focuses on specific emotional information based on aspect and aspect information extracted from sentences. Sentence: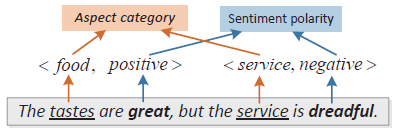
Given the aspect word "food", the double-layer Attention model first focuses on the word "takes" (aspect terms) based on "food", and then finds the word "great" based on the word "food" and "takes". In this way, based on the aspect terms, we can better determine the emotional tendency of a given aspect.
One Model
1.1 HEAT network structure
Its structure is as follows: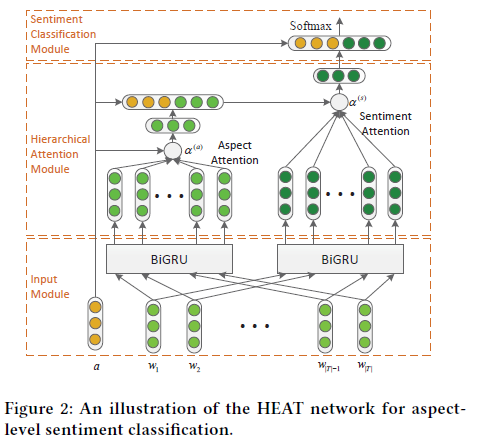
Input Model: input module encodes sentences and aspect words into vector form
Hierarchical Attention Model: use two layers of attention to obtain aspect information (aspect attention layer) and aspect specific sentient information (sentient attention layer)
Sentient classification model: emotional classification
1.2 Input Model
Using the bidirectional GRU model to learn the vector representation of sentences, its main definitions are as follows:
We order: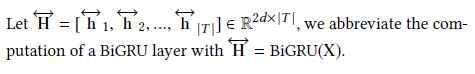
1.3 Hierarchical Attention Model
Aspect Attention
Aspect Attention finds possible aspect terms whose input is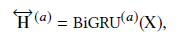
The attention mechanism calculates the weight of each word based on the given aspect representation and sentence feature representation: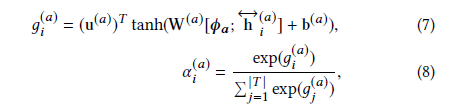

Therefore, the aspect information of the final sentence is the weight accumulation of features: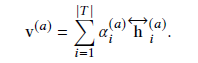
Sentiment attention
Sentient attention extracts emotional features of sentences based on aspect words and aspect information. Similar to aspect attention, its input is the output of BiGRU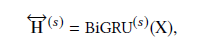
Because aspect information and sentient information need different characteristics, the two GRU models do not share parameters.
Then, the attention score of each word is calculated based on the feature vector, aspect feature and aspect feature of the sentence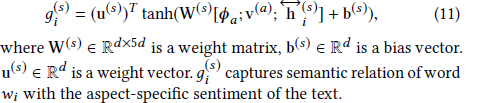
In order to better calculate the weight of attention, the local information of aspect terms is considered in this paper. Use the location mask layer to focus on the local information of the aspect terms. Using a local matrix to achieve:
In this way, words closer to the aspect term will have greater weight, so the sentient attention score is calculated as: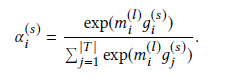
The emotional feature of a given aspect sentence is the weight accumulation of sentence features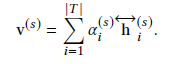
1.4 Setiment Classfication Model

II. Core code
class HEAT(nn.Module):
def __init__(self, word_embed_dim, output_size, vocab_size, aspect_size, args=None):
super(HEAT, self).__init__()
self.input_size = word_embed_dim if (args.use_elmo == 0) else ( word_embed_dim + 1024 if args.use_elmo == 1 else 1024)
self.hidden_size = args.n_hidden
self.output_size = output_size
self.max_length = 1
self.lr = 0.0005
self.word_rep = WordRep(vocab_size, word_embed_dim, None, args)
self.rnn_a = nn.GRU(self.input_size, self.hidden_size // 2, bidirectional=True)
self.AE = nn.Embedding(aspect_size, word_embed_dim)
self.W_h_a = nn.Linear(self.hidden_size, self.hidden_size)
self.W_v_a = nn.Linear(word_embed_dim, self.input_size)
self.w_a = nn.Linear(self.hidden_size + word_embed_dim, 1)
self.W_p_a = nn.Linear(self.hidden_size, self.hidden_size)
self.W_x_a = nn.Linear(self.hidden_size, self.hidden_size)
self.rnn_p = nn.GRU(self.input_size, self.hidden_size // 2, bidirectional=True)
self.W_h = nn.Linear(self.hidden_size, self.hidden_size)
self.W_v = nn.Linear(word_embed_dim+self.hidden_size, word_embed_dim+self.hidden_size)
self.w = nn.Linear(2*self.hidden_size + word_embed_dim, 1)
self.W_p = nn.Linear(self.hidden_size, self.hidden_size)
self.W_x = nn.Linear(self.hidden_size, self.hidden_size)
self.decoder_p = nn.Linear(self.hidden_size+word_embed_dim, output_size)
self.dropout = nn.Dropout(args.dropout)
self.optimizer = torch.optim.Adam(self.parameters(), lr=self.lr)
def forward(self, input_tensors):
assert len(input_tensors) == 3
aspect_i = input_tensors[2]
#Get the characteristic representation of sentences
sentence = self.word_rep(input_tensors)
#Length of sentence
length = sentence.size()[0]
#Two Grus: one for Aspect attention and one for sentient attention
output_a, hidden = self.rnn_a(sentence)
output_p, _ = self.rnn_p(sentence)
#[length,128]
output_a = output_a.view(output_a.size()[0], -1)
output_p = output_p.view(length, -1)
#Eigenvector representation of subject words [1200]
aspect_e = self.AE(aspect_i)
aspect_embedding = aspect_e.view(1, -1)
#[length,200] expand subject words into vectors of sentences
aspect_embedding = aspect_embedding.expand(length, -1)
#Get the weight of the aspect for each word in the sentence [length,428]
M_a = F.tanh(torch.cat((output_a, aspect_embedding), dim=1))
#[1,length]
weights_a = F.softmax(self.w_a(M_a), dim=0).t()
# Get the aspect information of the sentence based on the subject word [1128]
r_a = torch.matmul(weights_a, output_a)
#sentiment attention
#[length,128]
r_a_expand = r_a.expand(length, -1)
#[length,328]
query4PA = torch.cat((r_a_expand, aspect_embedding), dim=1)
#[length,456]
M_p = F.tanh(torch.cat((output_p, query4PA), dim=1))
#[length,1]
g_p = self.w(M_p)
# print(g_p)
weights_p = F.softmax(g_p, dim=0).t()
#sentiment feature
r_p = torch.matmul(weights_p, output_p)
r = torch.cat((r_p, aspect_e), dim=1)
#output
decoded = self.decoder_p(r)
ouput = decoded
return ouput

