Comparison of three containers
| project | ArrayMap | SparseArray | HashMap |
|---|---|---|---|
| concept | Memory optimized HashMap | Performance optimized ArrayMap with key int | Access O(1) Map with a large amount of memory |
| data structure | Two arrays: A Hash with Key Another Key and Value are stored | Two arrays: A stored Key Another save Value | Array + linked list / red black tree |
| Application scenario | 1. Data volume is less than 1000; 2. There is a Map in the data; | 1. Data volume is less than 1000; 2. key must be an int class; | The first two are not suitable for use |
- All three are thread unsafe
ArrayMap
data structure
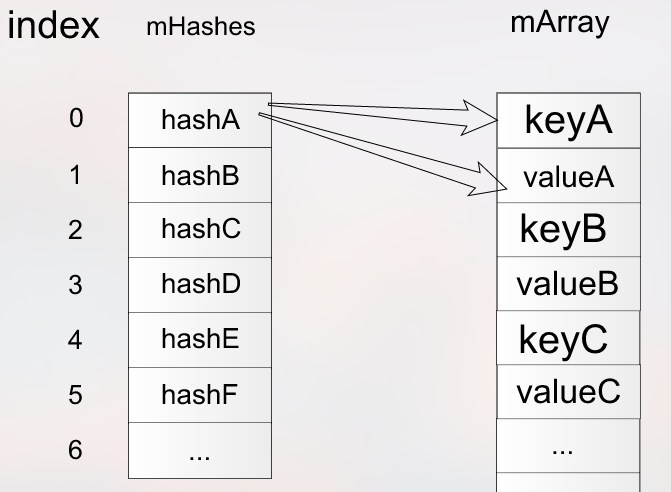
Two arrays:
- mHashes: store the hash value of the key
- Mmarray: an Object array. key value is stored in even index and value is stored in odd index
mHashes[index] = hash; //Optimization with bit operation mArray[index<<1] = key; //Equivalent to maarray [index * 2] = key; mArray[(index<<1)+1] = value; //Equivalent to maarray [index * 2 + 1] = value;
Therefore, the size of M array is twice that of M hashes
Storage logic
get()
- Calculate the hash value according to the key (if the key is null, take 0 directly)
- Find the index corresponding to the hash value in the mHashes array
- If index < 0, it indicates that it is not found and returns null; If index > 0, the Value is retrieved from the mmarray and returned
Among them, the second step takes the most time and uses binary search to optimize
Therefore, the query time complexity of ArrayMap is O(log n)
put()
- Calculate the hash value according to the key (if the key is null, take 0 directly)
- Find the index corresponding to the hash value in the mHashes array
- If index > 0, the existing value of mararray can be directly replaced with a new value
- If index < 0, it means that the current key does not exist. Take index inversely to get the subscript to be inserted
- Judge whether capacity expansion is required according to the index
- Copy the array to make room for the position of index
- Put the new value in the index position
Key: remove the subscript indexOf()
int indexOf(Object key, int hash) {
final int N = mSize;
// Important fast case: if the current table is empty, return directly
if (N == 0) {
return ~0;//Returns the largest negative number
}
//Binary search returns the negation of the subscript to be inserted
int index = binarySearchHashes(mHashes, N, hash);
//If it is less than 0, it means that the key has not been saved. Return
if (index < 0) {
return index;
}
// If the index > 0 and the key just corresponds to the, it just found and returned
if (key.equals(mArray[index<<1])) {
return index;
}
//Search under Hash collision
// Backward lookup
int end;
for (end = index + 1; end < N && mHashes[end] == hash; end++) {
if (key.equals(mArray[end << 1])) return end;
}
// Find forward
for (int i = index - 1; i >= 0 && mHashes[i] == hash; i--) {
if (key.equals(mArray[i << 1])) return i;
}
//If none of the above is found, the last end is the position to be inserted. Similarly, take the inverse first and then return
return ~end;
}
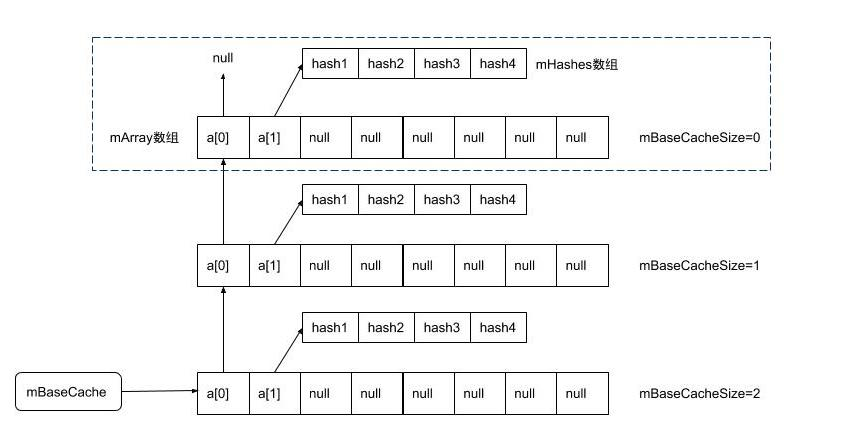
Caching mechanism
- In many scenarios in Android, the amount of data is relatively small at first. In order to avoid frequent creation and recycling of array objects, ArrayMap has designed two buffer pools, mBaseCache and mTwiceBaseCache
- The caching mechanism is triggered only when the size is 4 and 8. Therefore, it is best to use new ArrayMap(4) or new ArrayMap(8) to minimize the creation of objects.
- Cache reuse is an array of size 4 or 8
- Implementation idea: string the array to be cached into a one-way linked list. Creating cache is to insert elements in the linked list header, and reuse is to delete the linked list header elements
private static final int BASE_SIZE = 4;
Create cache
private static void freeArrays(final int[] hashes, final Object[] array, final int size) {
if (hashes.length == (BASE_SIZE * 2)) { //hashes and array of arrays with cache size of 8
synchronized (ArrayMap.class) {
// When the number of cache pools with size 8 is less than 10, it is put into the cache pool
if (mTwiceBaseCacheSize < CACHE_SIZE) {
//Just regard array[0] as the next of the one-way linked list node. Here, connect array to the original cache
array[0] = mTwiceBaseCache;
//Save hashes to node
array[1] = hashes;
for (int i = (size << 1) - 1; i >= 2; i--) {
//Clear unwanted data
array[i] = null;
}
//Point the head node to the array and insert the linked list into the head node
mTwiceBaseCache = array;
mTwiceBaseCacheSize++;
}
}
} else if (hashes.length == BASE_SIZE) { //Similarly
synchronized (ArrayMap.class) {
if (mBaseCacheSize < CACHE_SIZE) {
array[0] = mBaseCache;
array[1] = hashes;
for (int i = (size << 1) - 1; i >= 2; i--) {
array[i] = null;
}
mBaseCache = array;
mBaseCacheSize++;
}
}
}
}
3-tier cache structure:
freeArrays() trigger timing:
| opportunity | reason |
|---|---|
| removeAt() removes the last element | You do not need an array at this time. Try to recycle |
| Perform clear | ditto |
| Execute ensureCapacity() when the current capacity is less than the expected capacity | Sample |
| Execute put() when the capacity is full | ditto |
Reuse cache
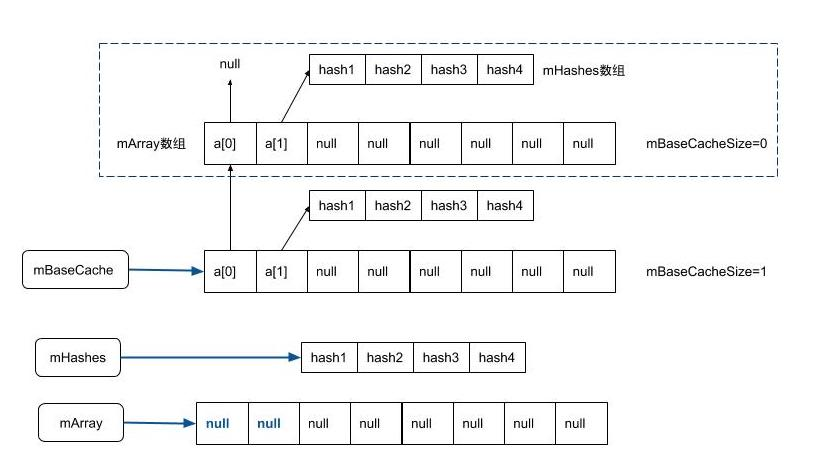
private void allocArrays(final int size) {
if (size == (BASE_SIZE*2)) { //When allocating an object of size 8, first view the cache pool
synchronized (ArrayMap.class) {
if (mTwiceBaseCache != null) { // When the cache pool is not empty
final Object[] array = mTwiceBaseCache;
//Remove the mmarray from the cache pool
mArray = array;
//The linked list deletes the head node, that is, the next bit of the original head node becomes the head node
mTwiceBaseCache = (Object[])array[0];
//Extract mHashes from the original header node
mHashes = (int[])array[1];
//Clear the data of the original header node
array[0] = array[1] = null;
mTwiceBaseCacheSize--; //Cache pool size minus 1
return;
}
}
} else if (size == BASE_SIZE) { //Similarly
synchronized (ArrayMap.class) {
if (mBaseCache != null) {
final Object[] array = mBaseCache;
mArray = array;
mBaseCache = (Object[])array[0];
mHashes = (int[])array[1];
array[0] = array[1] = null;
mBaseCacheSize--;
return;
}
}
}
// If the allocation size is other than 4 and 8, a new array is created directly
mHashes = new int[size];
mArray = new Object[size<<1];
}
Data structure in layer 2 Cache:
Alloccarrays trigger timing
| opportunity | reason |
|---|---|
| Constructor to execute ArrayMap | Construct the first array |
| Execute removeAt() when the capacity tightening mechanism is met | Try array multiplexing |
| Execute ensureCapacity() when the current capacity is less than the expected capacity | Sample |
| Execute put() when the capacity is full | ditto |
Capacity adjustment mechanism
expand
- In put, check and expand if conditions are met
public V put(K key, V value) {
...
final int osize = mSize;
//Capacity expansion is required when mSize is greater than or equal to the length of mHashes array
if (osize >= mHashes.length) {
//Make up 4 for those less than 4 and 8 for those less than 8, otherwise the capacity will be expanded by 1.5 times (osize + (osize > > 1))
final int n = osize >= (BASE_SIZE * 2) ? (osize + (osize >> 1))
: (osize >= BASE_SIZE ? (BASE_SIZE * 2) : BASE_SIZE);
allocArrays(n);
}
}
reduce
public V removeAt(int index) {
final int osize = mSize;
//When mSize is greater than 1, you need to decide whether to tighten it according to the situation
if (osize > 1) {
//When the array capacity mSize is greater than 8 and the amount of data stored is less than 1 / 3 of the capacity, it is reduced
if (mHashes.length > (BASE_SIZE * 2) && mSize < mHashes.length / 3) {
//If the mSize is less than 8, supplement 8. Otherwise, apply for the array according to 1.5 times the mSize
final int n = osize > (BASE_SIZE * 2) ? (osize + (osize >> 1)) : (BASE_SIZE * 2);
allocArrays(n);
}
}
}
- When the array utilization is less than 1 / 3, it will be reduced by 50% or more( 1 3 \frac{1}{3} 31*1.5= 1 2 \frac{1}{2} 21)
Parameter mIdentityHashCode
- The default is false, which allows the same value in mHashes
- Implementation logic:
public V put(K key, V value) {
...
//If it is true, the system default HashCode is used, that is, each object is different according to the memory address; if it is false, the rewritten is called to avoid object duplication
hash = mIdentityHashCode ? System.identityHashCode(key) : key.hashCode();
index = indexOf(key, hash);
...
}
SparseArray
- The Key of SparseArray must be int
- When the amount of data is 100, the performance is better than HashMap, about 0-50%;
- The bottom layer is two arrays, mKeys and mValues, which store keys and values respectively, and their indexes correspond to each other
Capacity expansion mechanism
- use Help class GrowingArrayUtils Operate
public static int growSize(int currentSize) {
//Capacity expansion rule: if the current capacity is less than 5, return 8; otherwise, double the capacity expansion
return currentSize <= 4 ? 8 : currentSize * 2;
}
- Therefore, the maximum capacity is not set,
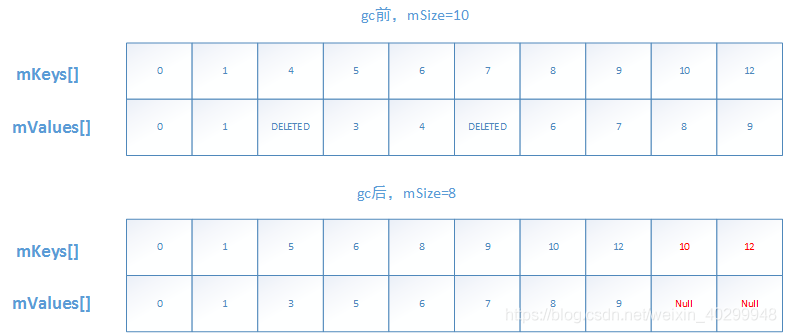
Delayed deletion mechanism
- When SparseArray is DELETED, the array will not be directly operated. Instead, the position to be DELETED will be set to the flag bit DELETED. At the same time, there will be a flag bit mGarbage to identify whether there is invalid data potentially delayed deletion (it will be set to true as long as there is a deletion operation)
- Advantages: reduce array operations and improve efficiency. For example, frequent deletion does not need to operate the array; when inserting elements into DELETED, it does not need to operate the array
//A constant Object acts as the flag bit private static final Object DELETED = new Object();
- When inserting an element, if it is DELETED, it can be replaced directly without operating the array, which is more efficient. If not, first clear the data according to mGarbage gc(), and then operate the array
//Push the normal element forward and squeeze out the DELETED position
private void gc() {
//n represents the length of the array before gc;
int n = mSize;
int o = 0;//Valid subscript length
int[] keys = mKeys;
Object[] values = mValues;
for (int i = 0; i < n; i++) {
Object val = values[i];
//Every time DELETED is encountered, the size of i-o is + 1;
if (val != DELETED) {
//When non DELETED data is encountered later, the key and value of subsequent elements are moved forward
if (i != o) {
keys[o] = keys[i];
values[o] = val;
values[i] = null;
}
o++;
}
}
//At this time, there is no garbage data, and the sequence number of o indicates the size of mSize
mGarbage = false;
mSize = o;
}
Changes before and after gc():
Access logic
put()
- Find the index of the second key in mKeys
- If index > 0, the data already exists and can be replaced directly
- If index < 0 or the corresponding Value is DELETE, the data does not exist and can be replaced directly
- Otherwise, perform gc() to find the insertion location index again, and then insert the data into mKeys and mValues
get()
- Find the index of the second key in mKeys
- If index < 0 or the corresponding value is DELETE, it indicates that the data does not exist and returns null. Otherwise, it returns value
- Because the key of SparseArray must be int, there is no need to deal with the case where the key is null
reference material
ArrayMap analysis 1
ArrayMap analysis 2
ArrayMap analysis 3
SparseArray analysis 1
SparseArray analysis 2