JDK1.8
ArrayList Source Analysis--jdk1.8
LinkedList Source Analysis--jdk1.8
HashMap Source Analysis--jdk1.8
AQS Source Analysis--jdk1.8
Overview of AbstractQueuedSynchronizer
AQS is a FIFO-based queue that can be used as a framework for building locks or other related synchronization devices.
_2. AQS provides a two-way Chain table.
AQS is divided into shared mode and exclusive mode.
AQS implements inter-thread communication based on volatile memory visibility and CAS atomicity operations.
AbstractQueuedSynchronizer data structure
_Data structure is the essence of collections, and data structure often limits the role and focus of collections. Understanding various data structures is the only way for us to analyze the source code.
The data structure of_AQS is as follows:Two-way chain table
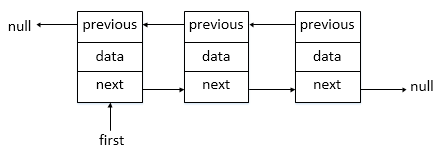
_AQS implements the access control basis of shared resources:
_1.state field, the synchronizer status field.Access control for shared resources
CLH queue, FIFO waiting queue, storing threads with failed competition.Usually the CLH queue is a spin queue, and AQS is blocked
Use of CLH queues: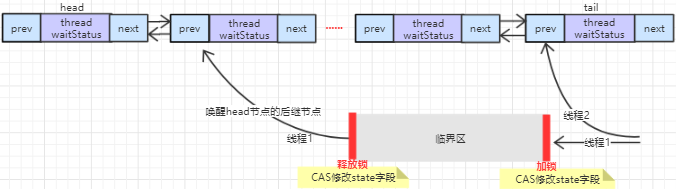
CLH Literacy
Spin lock
Review mutexes before learning about spin locks
mutex
When a thread acquires a mutex, if it finds that the lock is already occupied by another thread, the thread wakes up to sleep and acquires the lock at the appropriate time, such as waking up.
Spin lock
So the spin lock, as its name implies, is spin.That is, when a thread fails to attempt to acquire a lock, it does not sleep or hang, but keeps cycling to check if the lock is released by another thread.
Difference
Mutex locks simply start with more overhead than spin locks.The size of the critical latch time does not affect the cost of mutexes. Spin locks are deadlock detection, which consumes cpu throughout the lock process. Although the starting cost is lower than mutexes, the cost of locking increases linearly with the latch time.
Where applicable
Mutexes are used for operations where the critical zone holds locks for a longer period of time, such as the following
IO operation in critical zone
Complex critical zone codes or large loops
The competition in the critical zone is fierce
Single Core Processor
Spin locks are mainly used when the critical zone holds locks very short and CPU resources are not tight.Deadlock can occur when called recursively.
Thread (Node) Queue
After learning about spin locks, when learning ReentrantLock, a thread is encapsulated as a Node node while waiting for a lock, then joins a queue and detects if the previous node is a head node, and attempts to acquire the lock, returning if the lock is acquired successfully or blocking.Until the last node releases the lock and wakes it up.It looks like there's no hook to spin.This is because the CLH queue inside AQS is a distortion of the CLH queue lock.First let's look at CLH queue locks
CLH Queue Lock
CLH(Craig, Landin, and Hagersten locks): is a spin lock that ensures hunger-free, fair first-come-first-service.
The CLH lock is also an extensible, high performance, fair spin lock based on a chain table, where the requesting thread only spins on the local variable, polling the state of the precursor and ending the spin if the precursor releases the lock. http://www.2cto.com/kf/201412/363574.html More detailed illustrations are available in this article.
CLH Queue in AQS
After learning about spin locks and CLH queue locks, learning CLH queues in AQS is easier.The CLH queue in AQS has changed the CLH queue lock in two places
1. Node structure changes.The node of a CLH queue lock contains a field of Boolean type locked.If you want to acquire a lock, set this lock to true.The locked of the precursor node is then continuously trained to see if the lock is released (this process is called spin).The CLH queue of AQS introduces a head node and a tail node structurally.It also has a reference from the previous node to the next node.
2. The mechanism of waiting for lock acquisition has changed from spin to wait blocking.
MCS
The biggest difference between MSC and CLH is not whether the list of chains is displayed or implicit, but the rules of thread spin: CLH waits spin on the locked domain of the forward node, while MSC waits on its own
Spin wait on the locked domain of a node.Because of this, it solves the problem that CLH has too much memory to obtain locked domain state in the NUMA system architecture.
AbstractQueuedSynchronizer Source Code Analysis
/*
* Provides an infrastructure based on FIFO queues that can be used to build locks or other related synchronization devices
* Bidirectional Chain List
*/
public abstract class AbstractQueuedSynchronizer
extends AbstractOwnableSynchronizer
implements java.io.Serializable {
/**
* Parameterless construction method
*/
protected AbstractQueuedSynchronizer() { }
/**
* <pre>
* +------+ prev +-----+ +-----+
* head | | <---- | | <---- | | tail
* +------+ +-----+ +-----+
* </pre>
*/
static final class Node {
/** Marker to indicate a node is waiting in shared mode Mode, divided into sharing and exclusive sharing mode */
static final Node SHARED = new Node();
/** Marker to indicate a node is waiting in exclusive mode Exclusive Mode */
static final Node EXCLUSIVE = null;
/** waitStatus value to indicate thread has cancelled
* Value of node state node watiStatus
* CANCELLED,Value is 1, final state, node cancelled due to timeout or interrupt
* SIGNAL,A value of -1 indicates that the current node's successor node contains threads that need to run, that is, unpark, so when the current node release s or cancels, it must unpark its successor node
* CONDITION,A value of -2 indicates that the current node is waiting for condition, that is, the node is in the conditional queue and will not be used for sync queue until the node status is set to 0
* PROPAGATE,A value of -3 indicates that subsequent acquireShared in the current scenario can execute releaseShared and should be propagated to other nodes
* A value of 0 indicates that the current node is in the sync queue waiting to acquire a lock
* */
static final int CANCELLED = 1;
/** waitStatus value to indicate successor's thread needs unparking */
static final int SIGNAL = -1;
/** waitStatus value to indicate thread is waiting on condition */
static final int CONDITION = -2;
/**
* waitStatus value to indicate the next acquireShared should
* unconditionally propagate
*/
static final int PROPAGATE = -3;
/**
* Status field, taking on only the values:
* SIGNAL: The successor of this node is (or will soon be)
* blocked (via park), so the current node must
* unpark its successor when it releases or
* cancels. To avoid races, acquire methods must
* first indicate they need a signal,
* then retry the atomic acquire, and then,
* on failure, block.
* CANCELLED: This node is cancelled due to timeout or interrupt.
* Nodes never leave this state. In particular,
* a thread with cancelled node never again blocks.
* CONDITION: This node is currently on a condition queue.
* It will not be used as a sync queue node
* until transferred, at which time the status
* will be set to 0. (Use of this value here has
* nothing to do with the other uses of the
* field, but simplifies mechanics.)
* PROPAGATE: A releaseShared should be propagated to other
* nodes. This is set (for head node only) in
* doReleaseShared to ensure propagation
* continues, even if other operations have
* since intervened.
* 0: None of the above
* node state
*/
volatile int waitStatus;
/**
* Precursor Node
*/
volatile Node prev;
/**
* Succeeding nodes
*/
volatile Node next;
/**
* Threads corresponding to nodes
*/
volatile Thread thread;
/**
* Next Waiter
*/
Node nextWaiter;
/**
* Whether the node is waiting in shared mode
*/
final boolean isShared() {
return nextWaiter == SHARED;
}
/**
* Gets the precursor node, throws an exception if the precursor node is empty
*/
final Node predecessor() throws NullPointerException {
// Save Precursor Nodes
Node p = prev;
if (p == null) // The precursor node is empty, throwing an exception
throw new NullPointerException();
else // Precursor node is not empty, return
return p;
}
// non-parameter constructor
Node() { // Used to establish initial head or SHARED marker
}
// Constructor
Node(Thread thread, Node mode) { // Used by addWaiter
this.nextWaiter = mode;
this.thread = thread;
}
// Constructor
Node(Thread thread, int waitStatus) { // Used by Condition
this.waitStatus = waitStatus;
this.thread = thread;
}
}
/**
* CLH Head Node in Queue
*/
private transient volatile Node head;
/**
* CLH End of Queue
*/
private transient volatile Node tail;
/**
* Synchronization status
* If multithreaded synchronization succeeds in obtaining resources, the state field increases; if a thread releases resources, the state field decreases.
* The semaphore records the number of times the thread held a lock.The thread releases the semaphore-1 each time.Zero semaphore means the lock is actually released
*/
private volatile int state;
/**
* @return current state value
*/
protected final int getState() {
return state;
}
/**
* @param newState the new state value
*/
protected final void setState(int newState) {
state = newState;
}
/**
* Use unsafe cas to compare and exchange to ensure atomicity
*/
protected final boolean compareAndSetState(int expect, int update) {
// See below for intrinsics setup to support this
return unsafe.compareAndSwapInt(this, stateOffset, expect, update);
}
AbstractQueuedSynchronizer Inheritance and Implementation Analysis
AbstractQueuedSynchronizer extends AbstractOwnableSynchronizer
AbstractOwnableSynchronizer is an abstract class that implements the Serializable interface, defines exclusive mode, sets and retrieves Thread information for threads in exclusive mode.
_2.ArrayList implements List <E>, RandomAccess, Cloneable, Serializable interfaces
_1) List<E>interface. Since ArrayList inherits from the AbstractList abstract class and AbstractList already implements the List interface, why should the ArrayList class implement the List interface again?We look down with questions:
public class Demo1 extends ArrayList {
public static void main(String[] args) {
//Return []
System.out.println(Arrays.toString(Demo1.class.getInterfaces()));
}
public class Demo2 implements Serializable {
public static void main(String[] args) {
//Return to [interface java.io.Serializable]
System.out.println(Arrays.toString(Demo2.class.getInterfaces()));
}
public class Test{
public static void main(String[] args) {
Serializable c1 = new Demo1();//Implementation interface not shown
Serializable c2 = new Demo2();//Show implementation interface
Serializable proxy2 = createProxy(c2);
proxy2.foo();
Serializable proxy1 = createProxy(c1);
proxy1.foo();
}
private static <T> T createProxy(final T obj) {
final InvocationHandler handler = new InvocationHandler() {
@Override
public Object invoke(Object proxy, Method method, Object[] args)
throws Throwable {
return method.invoke(obj, args);
}
};
//Implement interface proxy, Demo1 error, Demo2 success
//java.lang.ClassCastException: $Proxy1 cannot be cast to
//example.Test$Serializable
return (T) Proxy.newProxyInstance(obj.getClass().getClassLoader(), obj
.getClass().getInterfaces(), handler);
}You can see that this design makes sense, so this is not an error, probably because the author Josh Bloch designed it to facilitate proxying.
Reference and: Josh, author of collection development, said
_2)RandomAccess interface, a markup interface that is generally used for List implementations to indicate that they support fast (usually constant-time) random access. The primary purpose of this interface is to allow common algorithms to change their behavior in order to provide good results when applied to random or sequential access listsGood performance, if the interface is implemented, it will be traversed using a normal for loop with higher performance, but if the interface is not implemented, it will be iterated using an Iterator, which will result in higher performance, such as a linkedList.So this tagging is just to let us know how we get better data performance
_3)Cloneable interface, you can use the Object.Clone() method.
_4)Serializable interface, serialized interface, indicating that the class can be serialized, what is serialization?Simply put, it is possible to change from a class to a byte stream transport, and deserialization is to change from a byte stream to the original class
ArrayList Core Method Analysis
1. add method (4 overloaded implementations) --Plus

1)add(E);//Add elements directly at the end by default
/**
* New Elements
*/
public boolean add(E e) {
//Assign initial length or expansion, add element, current actual size+1 length
ensureCapacityInternal(size + 1); // Increments modCount!!
//Add Elements
elementData[size++] = e;
return true;
}
/**
* Make sure the elemenData array has the appropriate size
* If the element is empty, the copy length defaults to 10 or greater
* @author jiaxiaoxian
* @date 2019 February 12, 2001
*/
private void ensureCapacityInternal(int minCapacity) {
if (elementData == EMPTY_ELEMENTDATA) {//If the array is empty, take the maximum from size+1 and default value 10
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
ensureExplicitCapacity(minCapacity);
}
/**
* Make sure the elemenData array has the appropriate size
* @author jiaxiaoxian
* @date 2019 February 12, 2001
* Expansion if length is greater than element length
*/
private void ensureExplicitCapacity(int minCapacity) {
//Record the number of modifications, inconsistencies in iterations trigger the fail-fast mechanism, so the correct way to delete elements in traversal is to use Iterator.remove()
modCount++;
if (minCapacity - elementData.length > 0)
grow(minCapacity); //Expansion
}
/**
* Expansion
*/
private void grow(int minCapacity) {
int oldCapacity = elementData.length; // Old capacity
int newCapacity = oldCapacity + (oldCapacity >> 1); // The new capacity is 1.5 times the old capacity
if (newCapacity - minCapacity < 0) // New capacity is smaller than parameter specified capacity, modify new capacity
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0) // New capacity greater than maximum capacity
newCapacity = hugeCapacity(minCapacity); // Specify new capacity
// minCapacity is usually close to size, so this is a win:copy expansion
elementData = Arrays.copyOf(elementData, newCapacity);
}
//Error if less than 0, maximum if greater than maximum
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
}2)add(int index, E element);//Add element to subscript
/**
* Add element to subscript
*/
public void add(int index, E element) {
//Determine if subscript is out of bounds
rangeCheckForAdd(index);
//Assign initial length or capacity
ensureCapacityInternal(size + 1); // Increments modCount!!
//Unify size-index elements in the source array from the index position by one bit
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
//assignment
elementData[index] = element;
size++;
}
/**
* Determine if subscript is out of bounds
*/
private void rangeCheckForAdd(int index) {
if (index > size || index < 0)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
/**
* src:Source Array
* srcPos:Starting position of source array to copy
* dest:Destination Array
* destPos:Starting position of destination array placement
* length:Length of replication
* Note: both src and dest must be arrays of the same type or convertible type
*/
public static native void arraycopy(Object src, int srcPos,
Object dest, int destPos,
int length);3)addAll(Collection<? extends E> c);//Add Collection Type Element
/**
* Add all elements in the collection to the end of this list in the order of the elements returned by the iterator for the specified collection
*/
public boolean addAll(Collection<? extends E> c) {
Object[] a = c.toArray();
int numNew = a.length;
ensureCapacityInternal(size + numNew); // Increments modCount
//Copy array a[0,...,numNew-1] to array elementData[size,...,size+numNew-1]
System.arraycopy(a, 0, elementData, size, numNew);
size += numNew;
return numNew != 0;
}4)addAll(int index, Collection<? extends E> c);//Specify the location to add Collection type elements
/**
* Inserts all elements in the specified collection into this list from the specified location in the order returned by the iterator of the specified collection
*/
public boolean addAll(int index, Collection<? extends E> c) {
//Determine if subscript is out of bounds
rangeCheckForAdd(index);
Object[] a = c.toArray();
int numNew = a.length;
ensureCapacityInternal(size + numNew); // Increments modCount
int numMoved = size - index;
//First copy the array elementData[index,...,index+numMoved-1] to elementData[index+numMoved,...,index+2*numMoved-1]
//That is, unify the numMoved elements in the source array from the index position and move them back numNew bits
if (numMoved > 0)
System.arraycopy(elementData, index, elementData, index + numNew,
numMoved);
System.arraycopy(a, 0, elementData, index, numNew);
size += numNew;
return numNew != 0;
}Summary:
_Normally it will expand 1.5 times, but in special cases (the new expanded array size has reached its maximum), it will only take the maximum.
2.remove method (4 overloaded implementations) - delete

1)remove(int index); //Delete element_according to specified subscript
/**
* Delete element according to specified subscript
*/
public E remove(int index) {
//Determine if the index is out of bounds
rangeCheck(index);
modCount++;
//Get old elements
E oldValue = elementData(index);
//Move forward all elements after the index position in the array elementData by one bit
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
//Set the last position of the original array to null, cleaned up by GC
elementData[--size] = null; // clear to let GC do its work
return oldValue;
} 2)remove(Object o); //Delete element_according to specified element
/**
* Remove the specified element that first appears in the ArrayList (if it exists), allowing duplicate elements to be stored in the ArrayList
*/
public boolean remove(Object o) {
// Since null s are allowed in ArrayList s, the following two scenarios are handled separately.
if (o == null) {
for (int index = 0; index < size; index++)
if (elementData[index] == null) {
//Private removal methods, skipping boundary checks for index parameters, and returning no values
fastRemove(index);
return true;
}
} else {
for (int index = 0; index < size; index++)
if (o.equals(elementData[index])) {
fastRemove(index);
return true;
}
}
return false;
}
/*
* Quickly delete elements based on Subscripts
*/
private void fastRemove(int index) {
modCount++;
//Move forward all elements after the index position in the array elementData by one bit
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; // clear to let GC do its work
}
/**
* Empty the ArrayList, set all elements to null, wait for garbage collection to recycle this, so it's called clear
*/
public void clear() {
modCount++;
// clear to let GC do its work
for (int i = 0; i < size; i++)
elementData[i] = null;
size = 0;
}
3)removeAll(Collection<?> c); //Delete all elements contained in the specified container c
/**
* Deletes all elements contained in the ArrayList in the specified container c
*/
public boolean removeAll(Collection<?> c) {
//Check whether the specified object c is empty
Objects.requireNonNull(c);
return batchRemove(c, false);
}
/**
* Delete All
* @author jiaxiaoxian
* @date 2019 February 12, 2001
*/
private boolean batchRemove(Collection<?> c, boolean complement) {
final Object[] elementData = this.elementData;
int r = 0, w = 0; //Read-Write Dual Pointer
boolean modified = false;
try {
for (; r < size; r++)
if (c.contains(elementData[r]) == complement) //Determines if the specified container c contains elementData[r] elements
elementData[w++] = elementData[r];
} finally {
// Preserve behavioral compatibility with AbstractCollection,
// even if c.contains() throws.
if (r != size) {
System.arraycopy(elementData, r,
elementData, w,
size - r);
w += size - r;
}
if (w != size) {
// clear to let GC do its work
for (int i = w; i < size; i++)
elementData[i] = null;
modCount += size - w;
size = w;
modified = true;
}
}
return modified;
}4)removeIf(Predicate<? super E> filter); //Filter (delete) elements in a set according to certain rules
/**
* Filter (delete) elements in a collection according to certain rules
* For example: idList.removeIf (id -> ID == nul);
* Remove id null from List idList collection
* @param filter
* @return
*/
@Override
public boolean removeIf(Predicate<? super E> filter) {
Objects.requireNonNull(filter);
// figure out which elements are to be removed
// any exception thrown from the filter predicate at this stage
// will leave the collection unmodified
int removeCount = 0;
final BitSet removeSet = new BitSet(size);
final int expectedModCount = modCount;
final int size = this.size;
for (int i=0; modCount == expectedModCount && i < size; i++) {
@SuppressWarnings("unchecked")
final E element = (E) elementData[i];
if (filter.test(element)) {
removeSet.set(i);
removeCount++;
}
}
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
// shift surviving elements left over the spaces left by removed elements
final boolean anyToRemove = removeCount > 0;
if (anyToRemove) {
final int newSize = size - removeCount;
for (int i=0, j=0; (i < size) && (j < newSize); i++, j++) {
i = removeSet.nextClearBit(i);
elementData[j] = elementData[i];
}
for (int k=newSize; k < size; k++) {
elementData[k] = null; // Let gc do its work
}
this.size = newSize;
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
modCount++;
}
return anyToRemove;
}Summary:
The_remove function user removes the element with the specified subscript, moves the element with the specified subscript to the end of the array forward by one unit, and sets the last element of the array to null, which is to make it easier for the GC to use the whole array later when it is not used, as a small trick.
3.set method--change
/**
* Override the specified subscript element
*/
public E set(int index, E element) {
//Determine if the index is out of bounds
rangeCheck(index);
//Get old elements
E oldValue = elementData(index);
//Overlay as new element
elementData[index] = element;
//Return old elements
return oldValue;
}
/**
* Determine if subscript is out of bounds
*/
private void rangeCheck(int index) {
if (index >= size)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}4.get method--check
/**
* Returns the value of the specified index
*/
public E get(int index) {
//Determine if the index is out of bounds
rangeCheck(index);
return elementData(index);
}
/**
* @author jiaxiaoxian
* @date 2019 February 12, 2001
* Returns the value of the subscript element
*/
@SuppressWarnings("unchecked")
E elementData(int index) {
return (E) elementData[index];
}5.indexOf Method--Find Subscript
/**
* Find subscript, if null, compare directly with null, return subscript
*/
public int indexOf(Object o) {
if (o == null) {
for (int i = 0; i < size; i++)
if (elementData[i]==null)
return i;
} else {
for (int i = 0; i < size; i++)
if (o.equals(elementData[i]))
return i;
}
return -1;
}
/**
* Find the last subscript, looping down
*/
public int lastIndexOf(Object o) {
if (o == null) {
for (int i = size-1; i >= 0; i--)
if (elementData[i]==null)
return i;
} else {
for (int i = size-1; i >= 0; i--)
if (o.equals(elementData[i]))
return i;
}
return -1;
}6.clone Method--Cloning
/**
* Copy, return a shallow copy of this ArrayList
*/
public Object clone() {
try {
ArrayList<?> v = (ArrayList<?>) super.clone();
v.elementData = Arrays.copyOf(elementData, size);
v.modCount = 0;
return v;
} catch (CloneNotSupportedException e) {
// this shouldn't happen, since we are Cloneable
throw new InternalError(e);
}
}7.trimToSize Method--Remove Redundant Capacity
/**
* Judging the actual size of the data and removing redundant capacity after auto-growth
* This method is used to reclaim excess memory.That is, once we have determined that the collection does not add extra elements, calling the trimToSize() method will just resize the array that implements the collection to the size of the collection elements.
* Note: This method takes time to copy array elements, so it should be called after making sure that no elements will be added
*/
public void trimToSize() {
modCount++;
if (size < elementData.length) {
elementData = Arrays.copyOf(elementData, size);
}
}8.Itr internal classes--like Iterator, can help us traverse lists, add, delete, change checks, etc.
/**
* Instantiate an Itr object and return
*/
public Iterator<E> iterator() {
return new Itr();
}
/**
* Internal classes, like Iterator, can help us traverse lists, add, delete, change, and so on
*/
private class Itr implements Iterator<E> {
int cursor; // index of next element to return next element
int lastRet = -1; // index of last element returned; -1 if no such current element
int expectedModCount = modCount; //modCount is used to determine if there are multiple threads accessing modifications
public boolean hasNext() {
return cursor != size;
}
@SuppressWarnings("unchecked")
public E next() {
checkForComodification();
int i = cursor;
if (i >= size)
throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length)
throw new ConcurrentModificationException();
cursor = i + 1;
return (E) elementData[lastRet = i];
}
public void remove() {
if (lastRet < 0)
throw new IllegalStateException();
checkForComodification();
try {
ArrayList.this.remove(lastRet);
cursor = lastRet;
lastRet = -1;
expectedModCount = modCount;
} catch (IndexOutOfBoundsException ex) {
throw new ConcurrentModificationException();
}
}
@Override
@SuppressWarnings("unchecked")
public void forEachRemaining(Consumer<? super E> consumer) {
Objects.requireNonNull(consumer);
final int size = ArrayList.this.size;
int i = cursor;
if (i >= size) {
return;
}
final Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length) {
throw new ConcurrentModificationException();
}
while (i != size && modCount == expectedModCount) {
consumer.accept((E) elementData[i++]);
}
// update once at end of iteration to reduce heap write traffic
cursor = i;
lastRet = i - 1;
checkForComodification();
}
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
} 9.ListItr Internal Class--inherits the Internal Class Itr and adds functions such as traversing forward, adding elements, changing element content, etc.
/**
* This class inherits the internal class Itr
* In addition to the functionality of the previous class, functions such as traversing forward, adding elements, changing element content have been added.
*/
private class ListItr extends Itr implements ListIterator<E> {
ListItr(int index) {
super();
cursor = index;
}
public boolean hasPrevious() {
return cursor != 0;
}
public int nextIndex() {
return cursor;
}
public int previousIndex() {
return cursor - 1;
}
@SuppressWarnings("unchecked")
public E previous() {
checkForComodification();
int i = cursor - 1;
if (i < 0)
throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length)
throw new ConcurrentModificationException();
cursor = i;
return (E) elementData[lastRet = i];
}
public void set(E e) {
if (lastRet < 0)
throw new IllegalStateException();
checkForComodification();
try {
ArrayList.this.set(lastRet, e);
} catch (IndexOutOfBoundsException ex) {
throw new ConcurrentModificationException();
}
}
public void add(E e) {
checkForComodification();
try {
int i = cursor;
ArrayList.this.add(i, e);
cursor = i + 1;
lastRet = -1;
expectedModCount = modCount;
} catch (IndexOutOfBoundsException ex) {
throw new ConcurrentModificationException();
}
}
} 10.SubList Internal Class--Building a Subset Class Based on Array List
/**
* Although this class is very long, most of its method calls are actually in ArrayList
* ListIterator A few changes have been made to this class using an anonymous internal class, but it's also similar
* After all, this class is just a subset class based on ArrayList, so let's not go into it.
*/
private class SubList extends AbstractList<E> implements RandomAccess {
private final AbstractList<E> parent;
private final int parentOffset;
private final int offset;
int size;
SubList(AbstractList<E> parent,
int offset, int fromIndex, int toIndex) {
this.parent = parent;
this.parentOffset = fromIndex;
this.offset = offset + fromIndex;
this.size = toIndex - fromIndex;
this.modCount = ArrayList.this.modCount;
}
public E set(int index, E e) {
// Verify that the index is legal
rangeCheck(index);
//Implement fail-fast mechanism (operation additions and deletions are not allowed in iterations)
checkForComodification();
// Old Value
E oldValue = ArrayList.this.elementData(offset + index);
// Assign new values
ArrayList.this.elementData[offset + index] = e;
return oldValue;
}
public E get(int index) {
// Verify that the index is legal
rangeCheck(index);
//Implement fail-fast mechanism (operation additions and deletions are not allowed in iterations)
checkForComodification();
return ArrayList.this.elementData(offset + index);
}
public int size() {
checkForComodification();
return this.size;
}
public void add(int index, E e) {
rangeCheckForAdd(index);
checkForComodification();
parent.add(parentOffset + index, e);
this.modCount = parent.modCount;
this.size++;
}
public E remove(int index) {
rangeCheck(index);
checkForComodification();
E result = parent.remove(parentOffset + index);
this.modCount = parent.modCount;
this.size--;
return result;
}
protected void removeRange(int fromIndex, int toIndex) {
checkForComodification();
parent.removeRange(parentOffset + fromIndex,
parentOffset + toIndex);
this.modCount = parent.modCount;
this.size -= toIndex - fromIndex;
}
public boolean addAll(Collection<? extends E> c) {
return addAll(this.size, c);
}
public boolean addAll(int index, Collection<? extends E> c) {
rangeCheckForAdd(index);
int cSize = c.size();
if (cSize==0)
return false;
checkForComodification();
parent.addAll(parentOffset + index, c);
this.modCount = parent.modCount;
this.size += cSize;
return true;
}
public Iterator<E> iterator() {
return listIterator();
}
public ListIterator<E> listIterator(final int index) {
checkForComodification();
rangeCheckForAdd(index);
final int offset = this.offset;
return new ListIterator<E>() {
int cursor = index;
int lastRet = -1;
int expectedModCount = ArrayList.this.modCount;
public boolean hasNext() {
return cursor != SubList.this.size;
}
@SuppressWarnings("unchecked")
public E next() {
checkForComodification();
int i = cursor;
if (i >= SubList.this.size)
throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData;
if (offset + i >= elementData.length)
throw new ConcurrentModificationException();
cursor = i + 1;
return (E) elementData[offset + (lastRet = i)];
}
public boolean hasPrevious() {
return cursor != 0;
}
@SuppressWarnings("unchecked")
public E previous() {
checkForComodification();
int i = cursor - 1;
if (i < 0)
throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData;
if (offset + i >= elementData.length)
throw new ConcurrentModificationException();
cursor = i;
return (E) elementData[offset + (lastRet = i)];
}
@SuppressWarnings("unchecked")
public void forEachRemaining(Consumer<? super E> consumer) {
Objects.requireNonNull(consumer);
final int size = SubList.this.size;
int i = cursor;
if (i >= size) {
return;
}
final Object[] elementData = ArrayList.this.elementData;
if (offset + i >= elementData.length) {
throw new ConcurrentModificationException();
}
while (i != size && modCount == expectedModCount) {
consumer.accept((E) elementData[offset + (i++)]);
}
// update once at end of iteration to reduce heap write traffic
lastRet = cursor = i;
checkForComodification();
}
public int nextIndex() {
return cursor;
}
public int previousIndex() {
return cursor - 1;
}
public void remove() {
if (lastRet < 0)
throw new IllegalStateException();
checkForComodification();
try {
SubList.this.remove(lastRet);
cursor = lastRet;
lastRet = -1;
expectedModCount = ArrayList.this.modCount;
} catch (IndexOutOfBoundsException ex) {
throw new ConcurrentModificationException();
}
}
public void set(E e) {
if (lastRet < 0)
throw new IllegalStateException();
checkForComodification();
try {
ArrayList.this.set(offset + lastRet, e);
} catch (IndexOutOfBoundsException ex) {
throw new ConcurrentModificationException();
}
}
public void add(E e) {
checkForComodification();
try {
int i = cursor;
SubList.this.add(i, e);
cursor = i + 1;
lastRet = -1;
expectedModCount = ArrayList.this.modCount;
} catch (IndexOutOfBoundsException ex) {
throw new ConcurrentModificationException();
}
}
final void checkForComodification() {
if (expectedModCount != ArrayList.this.modCount)
throw new ConcurrentModificationException();
}
};
}
public List<E> subList(int fromIndex, int toIndex) {
subListRangeCheck(fromIndex, toIndex, size);
return new SubList(this, offset, fromIndex, toIndex);
}
private void rangeCheck(int index) {
if (index < 0 || index >= this.size)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
private void rangeCheckForAdd(int index) {
if (index < 0 || index > this.size)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
private String outOfBoundsMsg(int index) {
return "Index: "+index+", Size: "+this.size;
}
/**
* Implement fail-fast mechanism
* Modifications are not allowed in thread unsafe iterations
* @author jiaxiaoxian
* @date 2019 February 12, 2001
*/
private void checkForComodification() {
if (ArrayList.this.modCount != this.modCount)
throw new ConcurrentModificationException();
}
public Spliterator<E> spliterator() {
checkForComodification();
return new ArrayListSpliterator<E>(ArrayList.this, offset,
offset + this.size, this.modCount);
}
}11.ArrayList Spliterator Internal Class--Parallel Iteration, Index-Based Bisplitting, Lazy Initialization of the Splitter
/**
* @since 1.8
* Instantiate an ArrayListSpliterator object and return
*/
@Override
public Spliterator<E> spliterator() {
return new ArrayListSpliterator<>(this, 0, -1, 0);
}
/**
* Index-based split-by-two, lazily initialized Spliterator
* Parallel Iteration
* Index-based splitting, lazy initialization of pliterator
* */
static final class ArrayListSpliterator<E> implements Spliterator<E> {
private final ArrayList<E> list;
private int index; // current index, modified on advance/split
private int fence; // -1 until used; then one past last index
private int expectedModCount; // initialized when fence set
/** Create new spliterator covering the given range */
ArrayListSpliterator(ArrayList<E> list, int origin, int fence,
int expectedModCount) {
this.list = list; // OK if null unless traversed
this.index = origin;
this.fence = fence;
this.expectedModCount = expectedModCount;
}
private int getFence() { // initialize fence to size on first use
int hi; // (a specialized variant appears in method forEach)
ArrayList<E> lst;
if ((hi = fence) < 0) {
if ((lst = list) == null)
hi = fence = 0;
else {
expectedModCount = lst.modCount;
hi = fence = lst.size;
}
}
return hi;
}
public ArrayListSpliterator<E> trySplit() {
int hi = getFence(), lo = index, mid = (lo + hi) >>> 1;
return (lo >= mid) ? null : // divide range in half unless too small
new ArrayListSpliterator<E>(list, lo, index = mid,
expectedModCount);
}
public boolean tryAdvance(Consumer<? super E> action) {
if (action == null)
throw new NullPointerException();
int hi = getFence(), i = index;
if (i < hi) {
index = i + 1;
@SuppressWarnings("unchecked") E e = (E)list.elementData[i];
action.accept(e);
if (list.modCount != expectedModCount)
throw new ConcurrentModificationException();
return true;
}
return false;
}
public void forEachRemaining(Consumer<? super E> action) {
int i, hi, mc; // hoist accesses and checks from loop
ArrayList<E> lst; Object[] a;
if (action == null)
throw new NullPointerException();
if ((lst = list) != null && (a = lst.elementData) != null) {
if ((hi = fence) < 0) {
mc = lst.modCount;
hi = lst.size;
}
else
mc = expectedModCount;
if ((i = index) >= 0 && (index = hi) <= a.length) {
for (; i < hi; ++i) {
@SuppressWarnings("unchecked") E e = (E) a[i];
action.accept(e);
}
if (lst.modCount == mc)
return;
}
}
throw new ConcurrentModificationException();
}
public long estimateSize() {
return (long) (getFence() - index);
}
public int characteristics() {
return Spliterator.ORDERED | Spliterator.SIZED | Spliterator.SUBSIZED;
}
}Summary of ArrayList
1) ArayList can hold null s, essentially an array of Object [] type. 2) ArayList differs from arrays in that it automatically expands size, and the key method is the gorw() method. 3) ArayList is fast in querying data because it is an array in nature. In insertion and deletion, performance degrades a lot, moving a lot of data is necessary to achieve the desired effect, whereas LinkedList is the opposite. 4) The arrayList implements RandomAccess, so the for loop is recommended when traversing it. 5) The initial length is recommended when initializing arrays. Repeated expansion can increase time consumption and affect performance efficiency.