Scrapy is a fast, high-level screen capture and Web Capture framework developed by Python. It is used to capture Web sites and extract structured data from pages. Its most attractive feature is that anyone can easily modify it according to their needs.
MongoDB NoSql is a very popular open source non-relational database, which stores data in the form of "key-value". Big data Quantity, high concurrency and weak transaction have great advantages.
When Scrapy and MongoDB What kind of spark will the two collide? and MongoDB What kind of spark will the two collide? Now let's do a simple crawl novel TEST
1. Install Scrapy
pip install scrapy
2. Download and install MongoDB Visualization of Mongo VUE
[MongoDB Download address] (https://www.mongodb.org/)
The steps for downloading and installing are omitted, and a data folder is created under the bin directory to store the data.
[MongoVUE download address] (http://www.mongovue.com/)
After installation, we need to create a database.
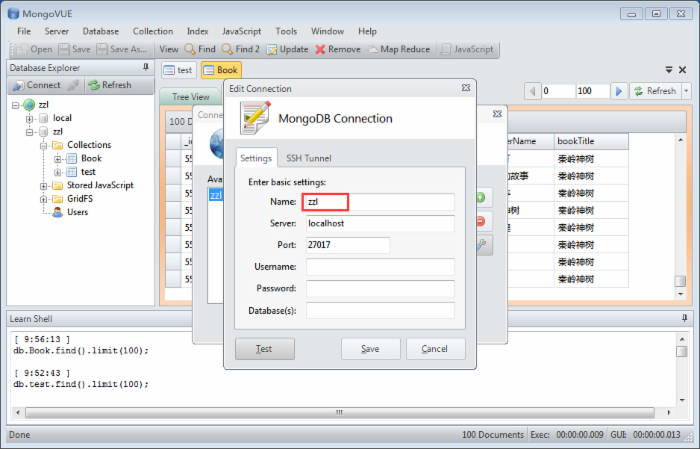
3. Create a Scrapy project
scrapy startproject novelspider
Directory structure: where novspider.py is created manually (contrloDB doesn't need to be ignored)
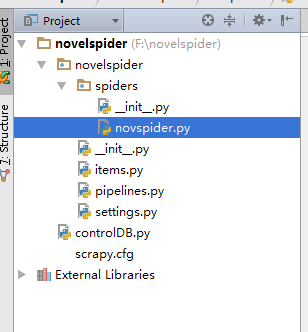
4. Coding
Target website: http://www.daomubiji.com/
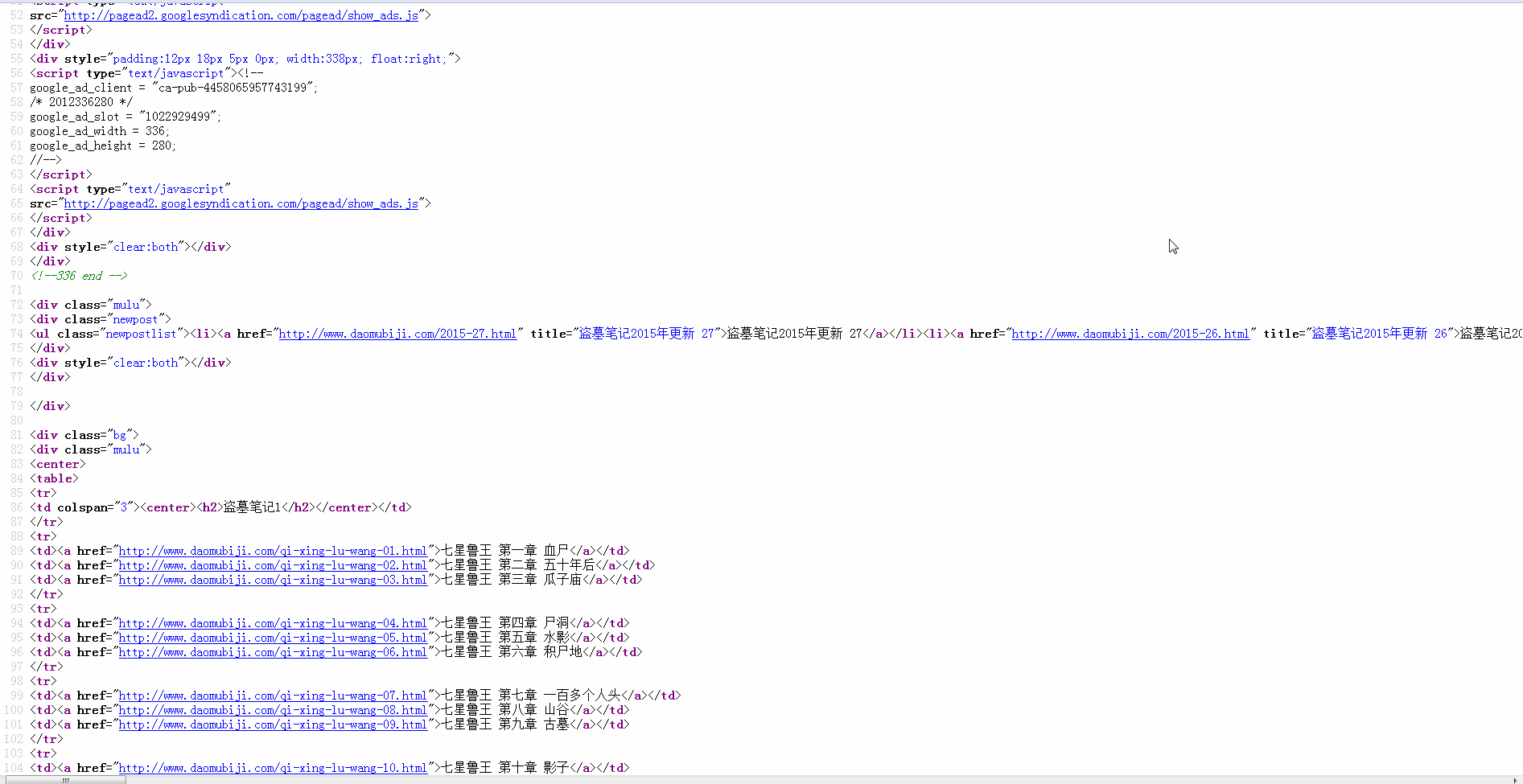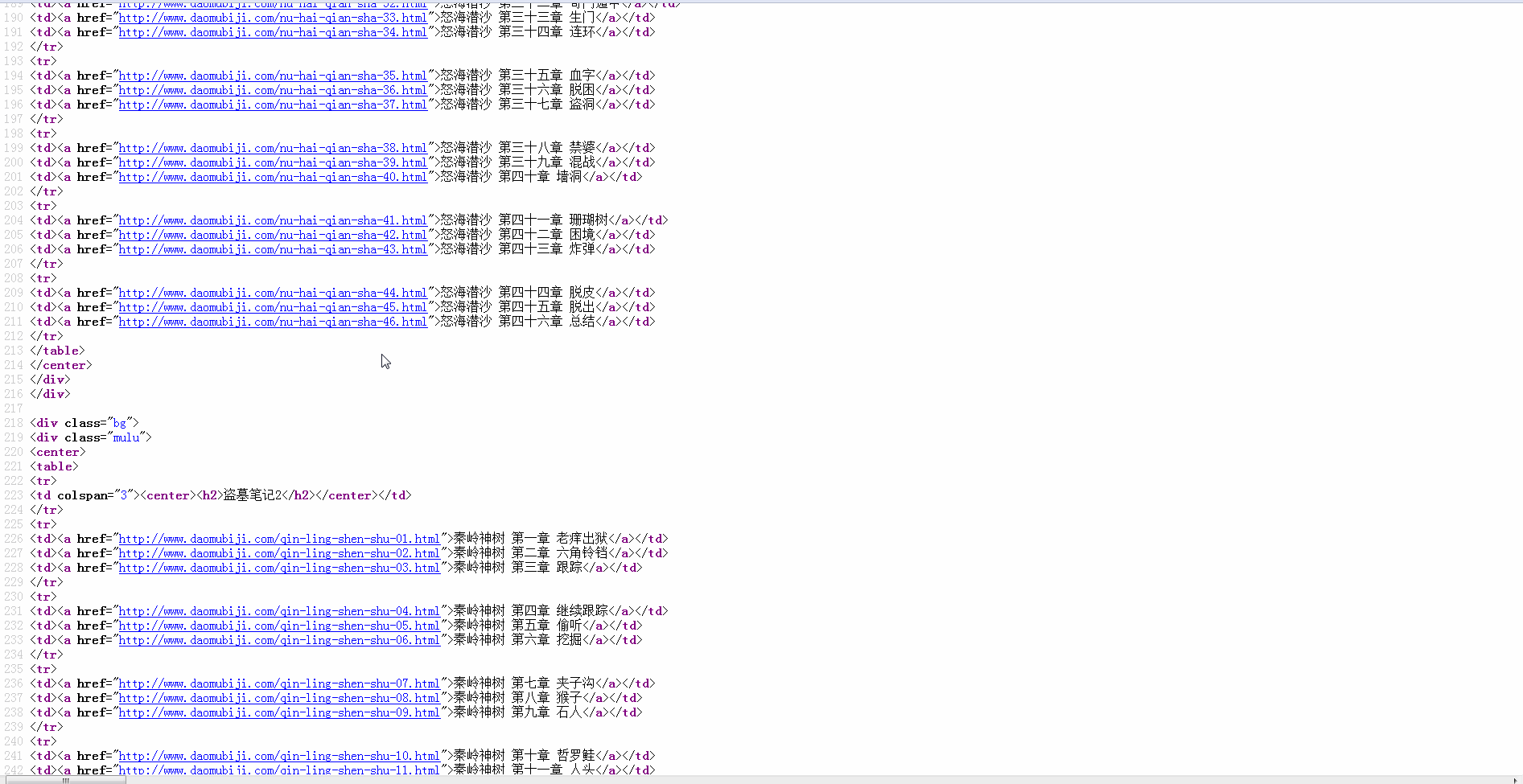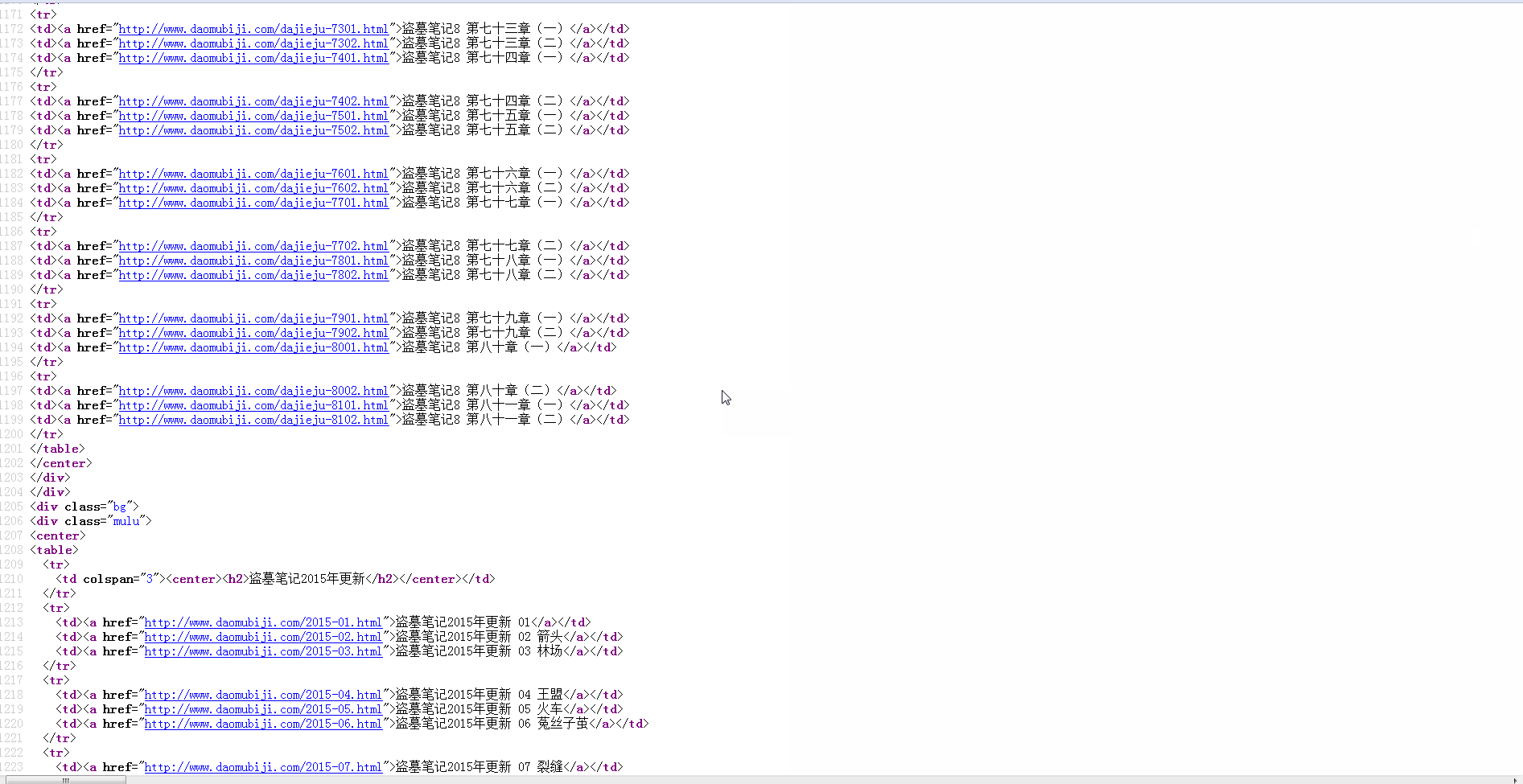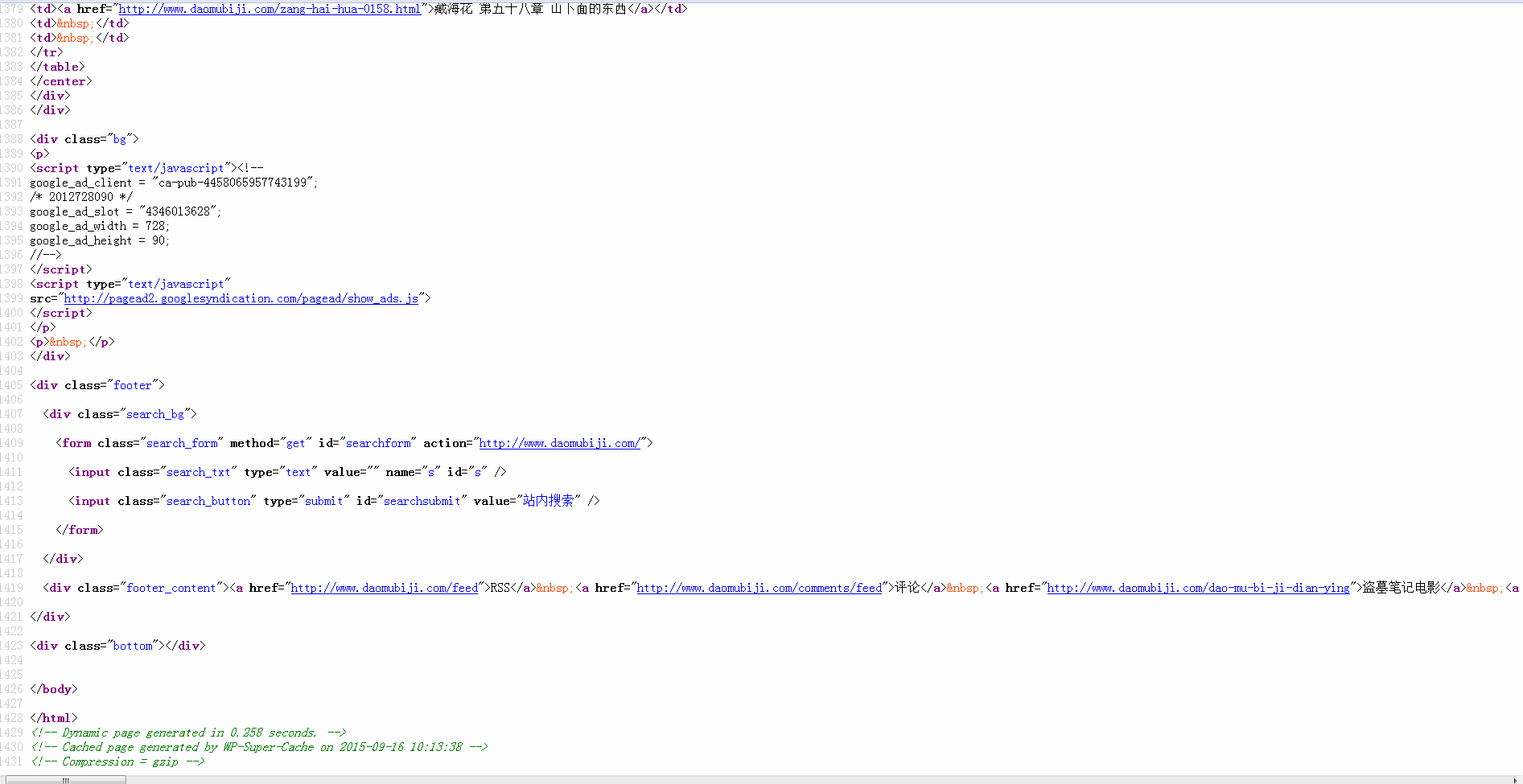
settings.py
BOT_NAME = 'novelspider' SPIDER_MODULES = ['novelspider.spiders'] NEWSPIDER_MODULE = 'novelspider.spiders' ITEM_PIPELINES = ['novelspider.pipelines.NovelspiderPipeline'] #Method of Importing pipelines.py USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:39.0) Gecko/20100101 Firefox/39.0' COOKIES_ENABLED = True MONGODB_HOST = '127.0.0.1' MONGODB_PORT = 27017 MONGODB_DBNAME = 'zzl' #Database name MONGODB_DOCNAME = 'Book' #Table name
pipelines.py
from scrapy.conf import settings import pymongo class NovelspiderPipeline(object): def __init__(self): host = settings['MONGODB_HOST'] port = settings['MONGODB_PORT'] dbName = settings['MONGODB_DBNAME'] client = pymongo.MongoClient(host=host, port=port) tdb = client[dbName] self.post = tdb[settings['MONGODB_DOCNAME']] def process_item(self, item, spider): bookInfo = dict(item) self.post.insert(bookInfo) return item
items.py
from scrapy import Item,Field class NovelspiderItem(Item): # define the fields for your item here like: # name = scrapy.Field() bookName = Field() bookTitle = Field() chapterNum = Field() chapterName = Field() chapterURL = Field()
Create novspider.py in the spiders directory
from scrapy.spiders import CrawlSpider
from scrapy.selector import Selector
from novelspider.items import NovelspiderItem
class novSpider(CrawlSpider):
name = "novspider"
redis_key = 'novspider:start_urls'
start_urls = ['http://www.daomubiji.com/']
def parse(self,response):
selector = Selector(response)
table = selector.xpath('//table')
for each in table:
bookName = each.xpath('tr/td[@colspan="3"]/center/h2/text()').extract()[0]
content = each.xpath('tr/td/a/text()').extract()
url = each.xpath('tr/td/a/@href').extract()
for i in range(len(url)):
item = NovelspiderItem()
item['bookName'] = bookName
item['chapterURL'] = url[i]
try:
item['bookTitle'] = content[i].split(' ')[0]
item['chapterNum'] = content[i].split(' ')[1]
except Exception,e:
continue
try:
item['chapterName'] = content[i].split(' ')[2]
except Exception,e:
item['chapterName'] = content[i].split(' ')[1][-3:]
yield item
5. Start Project Command: scrapy crawl novspider.
Grab results
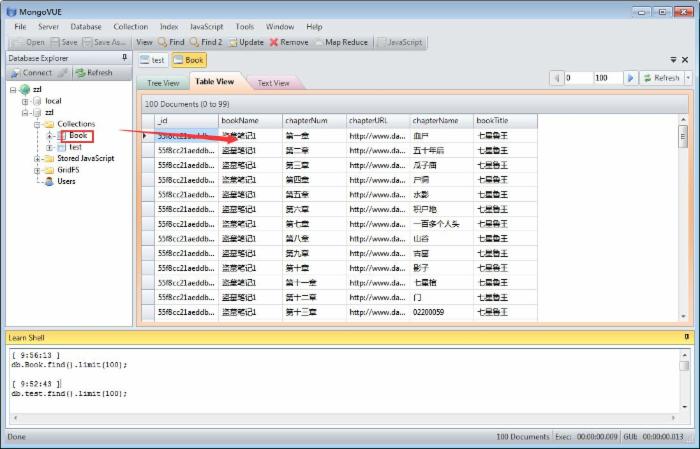
Reprinted at: https://www.cnblogs.com/JackQ/p/4843701.html