Application of gcc compile option pg in embedded profile
Problem introduction
First of all, this paper mainly describes how to use the - pg compilation option of gcc to implement some function level profile s, code coverage tests and even trace functions in the embedded bare metal or RTOS system environment. About this compilation option GCC documents It is described, but it should be noted here that this option is generally combined with gprof in glibc to realize complete and complex performance tracking. As we all know, embedded development environments at MCU level often have no operating system support, only RTOS or even bare metal environment. Therefore, this paper proposes a simple but effective way to implement trace in bare metal environment. The author hasn't developed in RTOS for a long time. Recently, I suddenly got an inspiration in studying and using ftrace in linux kernel. Therefore, I wrote down this topic and completed this article during the Mid Autumn Festival holiday.
Design and Implementation
development environment
At present, the author has no MCU hardware platform, and has been studying RISCV architecture recently. Therefore, this example uses QEMU RISCV64 environment. I transplanted freertos on this platform as a subsystem of some cores, which is just right for this experiment. Friends interested in the construction of my development environment can read my series of blogs -< Building embedded linux system from 0 based on QEMU riscv >. However, it should be emphasized that this method can be applied to other common embedded platforms, such as arm's cortex-m, cortex-r, cortex-a, riscv32 series and so on.
-pg compilation options
This option is generally used in conjunction with gprof in glibc. For general usage, this option needs to be added in both compilation and linking. However, in the environment of newlibc, there is no implementation of gprof. Therefore, we only need to add - pg in the compilation option.
- @$(CC) -c $(CFLAGS) -Wa,-a,-ad,-alms=$(OBJ_DIR)/$(notdir $(<:.c=.lst)) $< -o $@ + @$(CC) -c $(CFLAGS) -pg -Wa,-a,-ad,-alms=$(OBJ_DIR)/$(notdir $(<:.c=.lst)) $< -o $@
-The pg option is used to add a call named_ The hook function of mcount is defined as follows:
void _mcount(uint64_t caller_ra);
We implement this function to achieve the purpose we need. This function can be implemented by assembly or c. This paper is simple and easy to understand, using c code.
Design ideas
We know that after adding the -pg compilation option, all functions in the code will be called before the formal function is executed. mcount hook function, add one first_ mcount null function. Check the disassembly result. The code fragment is as follows:
int main(void)
{
bf803820: 1141 addi sp,sp,-16
bf803822: e406 sd ra,8(sp)
bf803824: 8506 mv a0,ra
bf803826: 496000ef jal ra,bf803cbc <_mcount>
bf80382a: ffffd517 auipc a0,0xffffd
...
void dump_regs(struct stack_frame *regs)
{
bf803866: 1141 addi sp,sp,-16
bf803868: e406 sd ra,8(sp)
bf80386a: e022 sd s0,0(sp)
bf80386c: 842a mv s0,a0
bf80386e: 8506 mv a0,ra
bf803870: 44c000ef jal ra,bf803cbc <_mcount>
You can see that it is called before each function_ mcount, so if we're_ mcount reads out the address in the ra register of the program, and we know that the function called us. By counting these callers, we can analyze the code coverage, calculate the call rate for a certain time, and get the code call density and other information. Here again, if it is arm, read LR / R14 (link register). Here, the embedded assembly is used to read ra to curr_ra variable, view disassembly Code:
void _mcount(uint64_t caller_ra)
{
uint64_t curr_ra;
__asm__ __volatile__("mv %0, ra":"=r"(curr_ra));
}
bf803ab8: 1141 addi sp,sp,-16 bf803aba: e406 sd ra,8(sp) bf803abc: 8506 mv a0,ra bf803abe: ffbff0ef jal ra,bf803ab8 <_mcount> bf803ac2: 8786 mv a5,ra bf803ac4: 60a2 ld ra,8(sp) bf803ac6: 0141 addi sp,sp,16 bf803ac8: 8082 ret
The problem here is if_ mcount itself is inserted_ mcount calls to form a recursive call, which can't jump out. In fact, it's a good solution. Just tell the compiler that this function doesn't insert hook. attribute ((no_instrument_function)) can modify the function (this method is also applicable to functions that you don't care about and don't intend to include in Statistics). Modify it as follows:
void __attribute__ ((no_instrument_function)) _mcount(uint64_t caller_ra)
{
uint64_t curr_ra;
__asm__ __volatile__("mv %0, ra":"=r"(curr_ra));
}
bf803ab8: 8786 mv a5,ra bf803aba: 8082 ret
The code is very simple. It reads ra to curr_ra, then the rest of the implementation will be easy. We are responsible for the curr we collected_ ra can analyze many problems by counting statistics. I will give an example:
//profiling.c
#include "profiling.h"
#include "debug_log.h"
#define PROF_MASK (~(PROF_ERR - 1))
#define ARRAY_SIZE(x) (sizeof(x) / sizeof((x)[0]))
typedef struct
{
uint64_t base_addr; /*!< (aligned) base address range of PC sample */
uint64_t hit_cnt; /*!< hit count (a decay mecahnism automatically drops it) */
uint64_t hit_ratio; /*!< 10-bit resolution hit ratio, */
} prof_unit_t;
typedef struct
{
uint32_t prof_cnt; /*!< totoal hit count of profiling */
uint32_t decay_ndx; /*!< which item to decay its hit_cnt */
prof_unit_t items[PROF_CNT];
} prof_t;
prof_t call_prof;
uint64_t ignr_list[] =
{
0xbf802a0a,
// todo: add pc address ranges that you do not care, such as idle function.
0,
0,
};
/**
* @brief Record sampling pc address
*
* @param p_item Record list
* @param pc Sample pc pointer
*/
void __attribute__ ((no_instrument_function)) prof_on_hit(prof_unit_t *p_item, uint64_t pc)
{
/* Record the address, add hitcnt and calculate hitRatio */
p_item->base_addr = pc & PROF_MASK;
call_prof.prof_cnt += PROF_HITCNT_INC;
p_item->hit_cnt += PROF_HITCNT_INC;
p_item->hit_ratio =(uint32_t)(((uint64_t)(p_item->hit_cnt) << 10) / call_prof.prof_cnt);
/* Item Bubble sorting */
prof_unit_t tmp_item;
for (; p_item != call_prof.items && p_item[0].hit_cnt > p_item[-1].hit_cnt; p_item--)
{
tmp_item = p_item[0];
p_item[0] = p_item[-1];
p_item[-1] = tmp_item;
}
}
/**
* @brief Sampling PC pointer
*
* @param pc Sample PC pointer
*/
void __attribute__ ((no_instrument_function)) profiling(uint32_t pc)
{
uint32_t i;
prof_unit_t *p_item = &call_prof.items[0];
/* Traverse the ignore list, ignoring the specified area pc */
for (i = 0; i < ARRAY_SIZE(ignr_list); i++)
{
if (pc - ignr_list[i] < PROF_ERR)
{
return;
}
}
#if PROF_DECAY
/* Attenuation processing, regularly reduce the number of hitcnts, so as to ignore the code with high density only during initialization */
if (call_prof.items[call_prof.decay_ndx].hit_cnt > 1)
{
call_prof.items[call_prof.decay_ndx].hit_cnt--;
call_prof.prof_cnt--;
}
if (++call_prof.decay_ndx == PROF_CNT)
{
call_prof.decay_ndx = 0;
}
#endif
uint32_t free_ndx = PROF_CNT;
/* Search for existing pc samples */
for (i = 0, p_item = call_prof.items; i < PROF_CNT; i++, p_item++)
{
if (p_item->base_addr == (pc & PROF_MASK))
{
prof_on_hit(p_item, pc);
break;
}
else if (free_ndx == PROF_CNT && p_item->hit_cnt == 0)
{
/* Record empty items */
free_ndx = i;
}
}
if (i == PROF_CNT)
{
if (free_ndx < PROF_CNT)
{
/* Assign new items */
prof_on_hit(call_prof.items + free_ndx, pc);
}
else
{
/* Replace last items */
free_ndx = PROF_CNT - 1;
call_prof.prof_cnt -= call_prof.items[free_ndx].hit_cnt;
call_prof.items[free_ndx].hit_cnt = 0;
prof_on_hit(call_prof.items + free_ndx, pc);
}
}
}
void __attribute__ ((no_instrument_function)) _mcount(uint64_t caller_ra)
{
uint64_t curr_ra;
__asm__ __volatile__("mv %0, ra":"=r"(curr_ra));
#ifndef PROF_CUSTOMIZE_PROC
profiling(curr_ra-4);
#else
/* TODO:
1.Using custom protocols to convert curr_ra data is sent out for processing, such as sending it to pc through serial port or processing
Write to flash/sd and other storage devices.
2.caller_ra It is the return address at the end of the function we collected, so we try it if conditions permit
Modifying the code segment of this address can even dynamically hook the end timing of this function, so it can
To trace the function, for example, to count the execution time of the function. Here, just throw a brick to attract jade.
*/
#endif
}
void print_profiling(void)
{
#ifndef PROF_CUSTOMIZE_PROC
for(uint64_t i=0;i<PROF_CNT;i++)
{
debug_log("No. %d\n",i);
debug_log("--- base_addr\t 0x%lx\n",call_prof.items[i].base_addr);
debug_log("--- hit_cnt\t %ld\n",call_prof.items[i].hit_cnt);
debug_log("--- hit_ratio\t %ld\n",call_prof.items[i].hit_ratio);
}
#endif
}
//profiling.h #ifndef _PROFILING_H_ #define _PROFILING_H_ #include <stdint.h> #include <string.h> #define PROF_DECAY 1 // whether hitCnt should decay, faster decay makes most time consuming functions seems to have even more hit count #define PROF_CNT 30 #define PROF_ERR 1 #define PROF_HITCNT_INC 10 //#define PROF_CUSTOMIZE_PROC extern void print_profiling(void); #endif /* _PROFILING_H_ */
We call print every 10s in a task_ Profiling, run the program, and the output results are as follows:
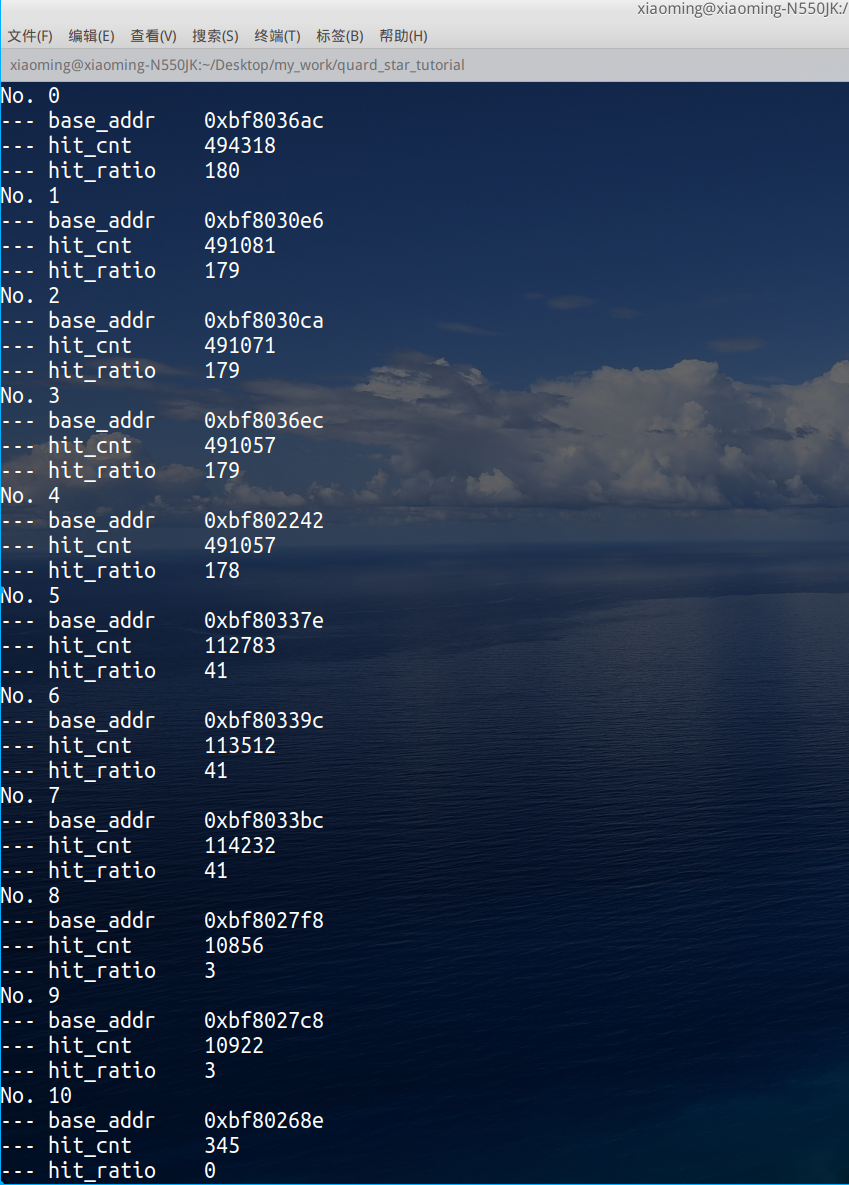
At this point, view the detected base_addr addresses can know which addresses will be called more frequently. Optimizing these functions may improve your program performance, which may be of value for running some simple algorithm tuning on the mcu platform.
epilogue
The example given at the end of this article is just to attract jade. Maybe you have noticed void_ The mcount (uint64_t caller_ra) function takes one parameter, caller_ RA, we don't use this address, but it also has some value. This address is_ The return address of the caller of mcount function after execution. If we make some hook s at the return address, we can count the execution time of each function, such as_ Start the timer in mcount and call_ RA ends the timing for function level trace.
In addition, in this paper, the technology of high-frequency call functions is carried out in the form of statistics. In order to save memory overhead, only 30 addresses are counted. If you need to conduct complete code coverage test, you can actually_ mcount can send the collected address to PC through serial port / USB, analyze and draw in real time through PC host computer, or save the data log to sd card / flash and other storage devices for offline analysis in the future.
Finally, here is a point to explain. When using RTOS, you also need to pay attention to the problem of multithreading concurrency to avoid inaccurate statistical results. This example is only to illustrate that the implementation is rough. If it is used in a practical project, please be sure to understand the principle and design properly.