Catalog
1.3 Installation Pack Download
II. Installation and deployment
2.1. Unzip and modify configuration files
2.2 Copy files to two other machines
3.2 Start spark-shell connection cluster
3.2 Submit spark tasks to the cluster
First, Preface
1.1 Cluster Planning
Three CentOS 7 servers that have been configured for secure login are required:
| IP address | hosts | Node identity |
| 172.16.49.246 | docker01 | Master,Worker |
| 172.16.49.247 | docker02 | Worker |
| 172.16.49.248 | docker03 | Worker |
1.2 Pre-condition
1) Install JDK 1.8 in advance, please refer to: https://www.t9vg.com/archives/346
2) Install Scala in advance, please refer to: https://www.t9vg.com/archives/635
1.3 Installation Pack Download
Official download page: http://spark.apache.org/downloads.html
This article uses spark-2.2.2-bin-hadoop 2.7, download address: https://pan.baidu.com/s/1kEQ09N8VPG_9oLwoxwDUaA Password: 22gk
II. Installation and deployment
2.1. Unzip and modify configuration files
###Unzip spark tar -zxvf spark-2.2.2-bin-hadoop2.7.tgz ###Modify conf cd conf/ mv slaves.template slaves vim slaves ###Add Work Nodes docker01 docker02 docker03 ###Edit sbin/spark-config file and add configuration file export JAVA_HOME=/usr/local/jdk1.8.0_91 #This is modified according to its own java_home
Configure the environment variables of the whole cluster (optional). Configure the environment variables of the whole cluster further through conf/spark-env.sh. Here are the following variables. First, use the default values.
| variable | describe |
| SPARK_MASTER_IP | Bind an external IP to master. |
| SPARK_MASTER_PORT | Start master from another port (default: 7077) |
| SPARK_MASTER_WEBUI_PORT | Master's web UI port (default: 8080) |
| SPARK_WORKER_PORT | Start a dedicated port for Spark worker (default: random) |
| SPARK_WORKER_DIR | Scale space and directory path of log input (default: SPARK_HOME/work); |
| SPARK_WORKER_CORES | Number of CPU kernels available for jobs (default: all available); |
| SPARK_WORKER_MEMORY | The memory capacity available for jobs is 1000M or 2G in default format (default: 1 GB of all RAM is removed from the operating system); note that each job's own memory space is determined by SPARK_MEM. |
| SPARK_WORKER_WEBUI_PORT | worker's web UI startup port (default: 8081) |
| SPARK_WORKER_INSTANCES | The number of workers running on each machine (default: 1). When you have a very powerful computer and need multiple Spark worker processes, you can modify the default value to be greater than 1. If you set this value. Make sure that SPARK_WORKER_CORE explicitly limits the number of cores pe r worker, otherwise each worker will try to use all cores. |
| SPARK_DAEMON_MEMORY | Memory space allocated to Spark master and worker daemons (default: 512m) |
| SPARK_DAEMON_JAVA_OPTS | JVM options for Spark master and worker daemons (default: none) |
2.2 Copy files to two other machines
scp -r spark-2.2.2-bin-hadoop2.7/ docker02:/hadoop/ scp -r spark-2.2.2-bin-hadoop2.7/ docker03:/hadoop/
3. Operation and testing
3.1 Start Cluster
###Run commands on any machine [root@docker01 spark-2.2.2-bin-hadoop2.7]# sbin/start-all.sh starting org.apache.spark.deploy.master.Master, logging to /hadoop/spark-2.2.2-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.master.Master-1-docker01.out docker03: starting org.apache.spark.deploy.worker.Worker, logging to /hadoop/spark-2.2.2-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-localhost.localdomain.out docker02: starting org.apache.spark.deploy.worker.Worker, logging to /hadoop/spark-2.2.2-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-docker02.out docker01: starting org.apache.spark.deploy.worker.Worker, logging to /hadoop/spark-2.2.2-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-docker01.out ###jps command to view startup [root@docker01 spark-2.2.2-bin-hadoop2.7]# jps 13168 Worker 13076 Master 13244 Jps [root@docker02 hadoop]# jps 8704 Jps 8642 Worker [root@docker03 hadoop]# jps 8704 Jps 8642 Worker
Access the web interface: docker01:8080
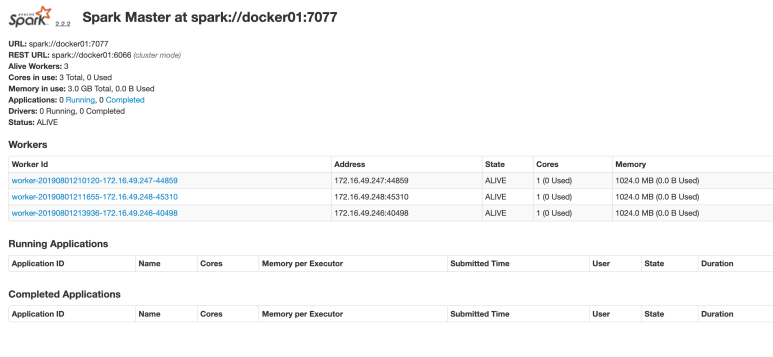
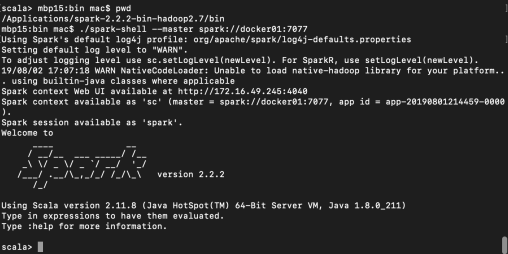
3.2 Start spark-shell connection cluster
#Connect to server cluster spark-shell on local client mbp15:bin mac$ ./spark-shell --master spark://docker01:7077
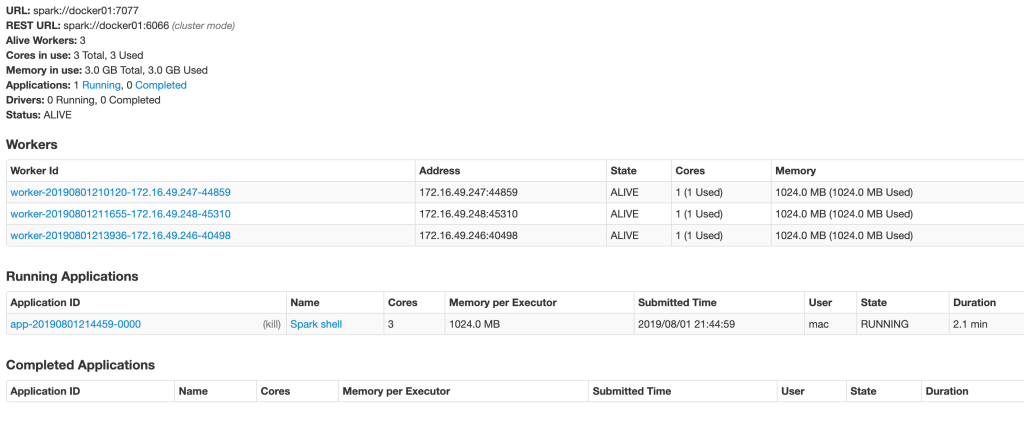
At this time, spark's monitoring interface will have corresponding tasks to display:
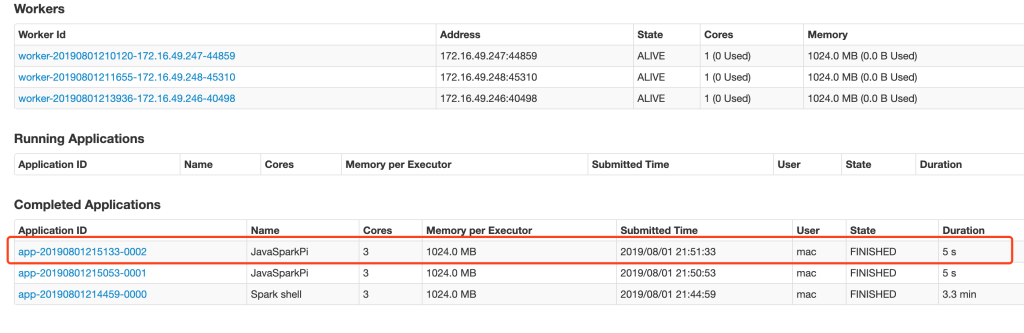
3.2 Submit spark tasks to the cluster
This article will submit an example from spark
### - class: namespace (package name) +class name; - master: master of spark cluster;.Jar: jar package location; 3: core parallelism mbp15:bin mac$ ./spark-submit --class org.apache.spark.examples.JavaSparkPi --master spark://docker01:7077 ../examples/jars/spark-examples_2.11-2.2.2.jar 3
Note: spark-client and spark cluster need the same version, otherwise error will be reported: Can only call getServlet Handlers on a running Metrics System
Please indicate the source for reprinting.
Welcome to join: Java/Scala / Big Data / Spring Cloud technology to discuss qq group: 854150511
This article is reproduced to: https://www.t9vg.com/archives/631