After nearly two years of optimization and polishing, Apache shardingsphere version 5.0.0 GA was finally officially released this month. Compared with version 4.1.1 GA, version 5.0.0 GA has been greatly optimized at the kernel level. Firstly, the kernel is completely transformed based on the pluggable architecture, and various functions in the kernel can be combined and superimposed arbitrarily. Secondly, in order to improve SQL distributed query capability, version 5.0.0 GA has created a new Federation execution engine to meet users' complex business scenarios. In addition, version 5.0.0 GA has also been greatly optimized at the level of kernel function API, in order to reduce the cost of users using these functions. This article will give you a detailed interpretation of these major kernel optimizations in the 5.0.0 GA version, compare the differences between the two GA versions, and take the typical scenarios of data fragmentation, read-write separation and encryption and decryption integration as an example to help users better understand these optimizations and complete the version upgrade.
Author introduction
Duan Zhengqiang
SphereEx senior middleware development engineer, Apache ShardingSphere Committer.
In 2018, he began to contact Apache ShardingSphere middleware, once led the database and table division of massive data in the company, and has rich practical experience; I love open source and am willing to share. At present, I focus on the development of Apache ShardingSphere kernel module.
Pluggable architecture kernel
Apache ShardingSphere version 5.0.0 GA puts forward a new concept of Database Plus, which aims to build the upper standard and ecology of heterogeneous databases and provide users with the ability of accuracy and differentiation. Database Plus has the characteristics of connection, increment and pluggability. Specifically, Apache ShardingSphere can connect different heterogeneous databases. Based on the basic services of heterogeneous databases, it provides incremental functions such as data fragmentation, data encryption and decryption and distributed transactions. In addition, through the pluggable platform, the incremental functions provided by Apache ShardingSphere can be expanded infinitely, and users can also expand flexibly according to their needs. The emergence of the Database Plus concept has transformed ShardingSphere from a database and table middleware into a powerful distributed database ecosystem. By practicing the concept of Database Plus and based on the extension points provided by the pluggable platform, the Apache ShardingSphere kernel has also been comprehensively pluggable. The following figure shows the new pluggable architecture kernel:
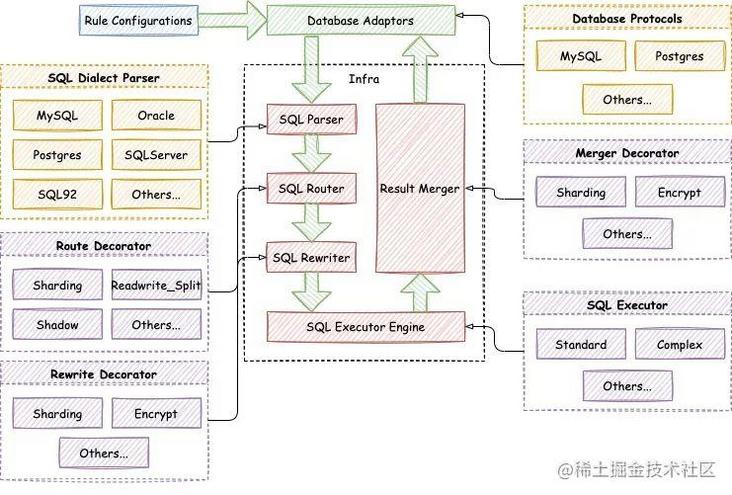
The metadata loading, SQL parsing, SQL routing, SQL rewriting, SQL execution and result merging in the Apache ShardingSphere kernel process provide rich extension points. Based on these extension points, Apache ShardingSphere realizes the functions of data fragmentation, read-write separation, encryption and decryption, shadow database pressure test and high availability by default.
According to whether the extension point is based on technology or function implementation, we can divide the extension point into function extension point and technology extension point. In the Apache ShardingSphere kernel process, the extension points of SQL parsing engine and SQL execution engine belong to technical extension points, while the extension points of metadata loading, SQL routing engine, SQL rewriting engine and result merging engine belong to functional extension points.
SQL parsing engine extension points mainly include SQL syntax tree parsing and SQL syntax tree traversal. Based on these two extension points, the SQL parsing engine of Apache ShardingSphere supports the parsing and traversal of database dialects such as MySQL, PostgreSQL, Oracle, SQLServer, openGauss and SQL92 by default. Based on these two extension points, users can also implement database dialects that are not supported by Apache ShardingSphere SQL parsing engine, and develop new functions such as SQL audit.
The SQL execution engine extension point provides extensions according to different execution methods. At present, Apache ShardingSphere SQL execution engine has provided single thread execution engine and multi thread execution engine. The single thread execution engine is mainly used to process the execution of statements containing transactions, while the multi thread execution engine is suitable for scenarios without transactions to improve the performance of SQL execution. In the future, Apache ShardingSphere will provide more execution engines such as MPP execution engine based on the execution engine extension point to meet the requirements of SQL execution in distributed scenarios.
Based on the function extension points, Apache ShardingSphere provides functions such as data slicing, read-write separation, encryption and decryption, shadow library pressure measurement and high availability. These functions realize all or part of the function extension points according to their respective requirements, and provide functions such as slicing strategy, and Internal extension points such as distributed ID generation and load balancing algorithm. The following are the extension points of Apache ShardingSphere kernel function implementation:
- Data slicing: it realizes all function extension points of metadata loading, SQL routing, SQL rewriting and result merging. Within the data slicing function, it also provides extension points such as slicing algorithm and distributed ID;
- Read write separation: the function extension point of SQL routing is realized, and the load balancing algorithm extension point is provided inside the function;
- Encryption and decryption: the extension points of metadata loading, SQL rewriting and result merging are realized, and the extension points of encryption and decryption algorithm are provided internally;
- Shadow database pressure measurement: it realizes the extension point of SQL routing. Within the shadow database pressure measurement function, it provides the extension point of shadow algorithm;
- High availability: implements the extension point of SQL routing.
Based on these extension points, the Apache ShardingSphere function has a very large extensible space. Functions such as multi tenant and SQL audit can be seamlessly integrated into the Apache ShardingSphere ecosystem through the extension points. In addition, users can also complete customized function development based on extension points according to their own business needs, and quickly build a set of distributed database system. For a detailed description of pluggable architecture extension points, please refer to the developer manual on the official website:
https://shardingsphere.apache...
From a comprehensive comparison, the main differences between the pluggable architecture kernel of version 5.0.0 GA and the kernel of version 4.1.1 GA are as follows:
| edition | 4.1.1 GA | 5.0.0 GA |
|---|---|---|
| location | Database and table Middleware | Distributed database ecosystem |
| function | Provide basic functions | Provide infrastructure and best practices |
| coupling | Large coupling and function dependence | Isolated from each other |
| Combined use | The fixed combination mode must be based on data fragmentation and superimposed with functions such as read-write separation, encryption and decryption | The functions can be combined freely, and the functions such as data slicing, read-write separation, shadow library pressure measurement, encryption and decryption and high availability can be superimposed and combined arbitrarily |
Firstly, from the perspective of project positioning, version 5.0.0 GA realizes the transformation from database and table middleware to distributed database ecosystem with the help of pluggable architecture. All functions can be integrated into the distributed database ecosystem through pluggable architecture. Secondly, from the perspective of project functions, version 4.1.1 GA only provides some basic functions, while version 5.0.0 GA focuses more on providing infrastructure and the best practices of some functions. Users can abandon these functions and develop customized functions based on kernel infrastructure. From the perspective of functional coupling, the kernel functions of version 5.0.0 GA are isolated from each other, which can ensure the stability of the kernel to the greatest extent. Finally, from the perspective of function combination, version 5.0.0 GA realizes the same level of functions. The functions of data fragmentation, read-write separation, shadow library pressure test, encryption and decryption and high availability can be combined arbitrarily according to the needs of users. In version 4.1.1 GA, when users use these functions in combination, they must focus on data fragmentation, and then superimpose other functions.
Through these comparisons, it can be seen that the pluggable kernel of version 5.0.0 GA has been comprehensively enhanced, and users can stack and combine functions like building blocks, so as to meet more business needs. However, the adjustment of pluggable architecture has also led to great changes in the use of kernel functions. In the subsequent content of this article, we will introduce in detail how to combine these functions in 5.0.0 GA version through examples.
Federation Execution Engine
Federation execution engine is another highlight function of the 5.0.0 GA kernel. Its goal is to support distributed query statements that cannot be executed in 4.1.1 GA, such as cross database instance Association queries and sub queries. With the emergence of federation execution engine, business R & D personnel no longer need to care about the use scope of SQL, can focus on business function development, and reduce the functional restrictions at the business level.
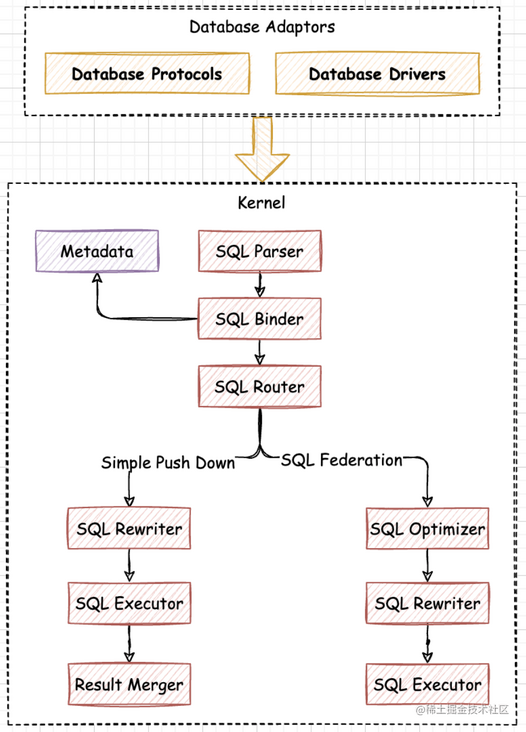
The figure above shows the processing flow of the Federation execution engine. Generally speaking, it still follows the steps of SQL parsing, SQL routing, SQL rewriting and SQL execution. The only difference is that the Federation execution engine additionally introduces SQL optimization to optimize distributed query statements by RBO (Rule Based Optimizer) and CBO (Cost Based Optimizer), So as to obtain the execution plan with the least cost. In the SQL routing phase, the routing engine will decide whether to execute SQL through the Federation execution engine according to whether the SQL statement spans multiple database instances.
The federation execution engine is currently in rapid development and still needs a lot of optimization. It is also an experimental function. Therefore, it is turned off by default. If you want to experience the federation execution engine, you can turn on the function by configuring SQL Federation enabled: true.
The Federation execution engine is mainly used to support association queries and sub queries across multiple database instances, as well as aggregate queries not supported by some kernels. Let's use specific scenarios to understand the statements supported by the Federation execution engine.
- Cross database association query: when multiple tables in the association query are distributed on different database instances, it is supported by the Federation execution engine.
For example, in the following data slicing configuration, t_order and t_order_ The item table is a fragmented table with multiple data nodes, and the binding table rule is not configured, t_user and t_user_ A role is a single table distributed across different database instances.
rules:
- !SHARDING
tables:
t_order:
actualDataNodes: ds_${0..1}.t_order_${0..1}
tableStrategy:
standard:
shardingColumn: order_id
shardingAlgorithmName: t_order_inline
t_order_item:
actualDataNodes: ds_${0..1}.t_order_item_${0..1}
tableStrategy:
standard:
shardingColumn: order_id
shardingAlgorithmName: t_order_item_inlineBecause it spans multiple database instances, the following common SQL will use the Federation execution engine to perform association queries.
SELECT * FROM t_order o INNER JOIN t_order_item i ON o.order_id = i.order_id WHERE o.order_id = 1; SELECT * FROM t_order o INNER JOIN t_user u ON o.user_id = u.user_id WHERE o.user_id = 1; SELECT * FROM t_order o LEFT JOIN t_user_role r ON o.user_id = r.user_id WHERE o.user_id = 1; SELECT * FROM t_order_item i LEFT JOIN t_user u ON i.user_id = u.user_id WHERE i.user_id = 1; SELECT * FROM t_order_item i RIGHT JOIN t_user_role r ON i.user_id = r.user_id WHERE i.user_id = 1; SELECT * FROM t_user u RIGHT JOIN t_user_role r ON u.user_id = r.user_id WHERE u.user_id = 1;
- Subquery: the Simple Push Down engine of Apache ShardingSphere can support subqueries with consistent fragment conditions and subqueries routed to a single fragment. The Federation execution engine needs to provide support for scenarios where the fragment key is not specified at the same time for the sub query and the outer query, or the values of the fragment key are inconsistent.
Some sub query scenarios supported by the Federation execution engine are shown below:
SELECT * FROM (SELECT * FROM t_order) o; SELECT * FROM (SELECT * FROM t_order) o WHERE o.order_id = 1; SELECT * FROM (SELECT * FROM t_order WHERE order_id = 1) o; SELECT * FROM (SELECT * FROM t_order WHERE order_id = 1) o WHERE o.order_id = 2;
- Aggregate query: for some aggregate queries that are not supported by Apache ShardingSphere Simple Push Down engine, we also provide support through Federation execution engine.
SELECT user_id, SUM(order_id) FROM t_order GROUP BY user_id HAVING SUM(order_id) > 10; SELECT (SELECT MAX(user_id) FROM t_order) a, order_id FROM t_order; SELECT COUNT(DISTINCT user_id), SUM(order_id) FROM t_order;
The emergence of Federation execution engine has significantly enhanced the distributed query capability of Apache ShardingSphere. In the future, Apache ShardingSphere will continue to optimize, effectively reduce the memory occupation of Federation execution engine and continuously improve the distributed query capability. For a detailed list of supported statements of the Federation execution engine, please refer to the experimental supported SQL in the official document:
https://shardingsphere.apache...
Kernel function API tuning
In order to reduce the cost of using kernel functions, version 5.0.0 GA has also been greatly optimized at the API level. Firstly, aiming at the problem that the data slicing API with more feedback from the community is too complex and difficult to understand, after full discussion by the community, a new data slicing API is provided in version 5.0.0 GA. At the same time, with the change of the positioning of Apache ShardingSphere project - from traditional database middleware to distributed database ecosystem, the realization of transparent data fragmentation function has become more and more important. Therefore, version 5.0.0 GA provides an automatic slicing strategy. Users do not need to care about the details of sub database and sub table, and can realize automatic slicing by specifying the number of slices. In addition, due to the proposal of pluggable architecture and the further enhancement of shadow library pressure measurement and other functions, the kernel function API has been optimized and adjusted accordingly. Next, we will introduce the API level adjustment of version 5.0.0 GA in detail from the perspective of different functions.
Data slicing API adjustment
In version 4.x, the community often feedback that the API of data fragmentation is too complex and difficult to understand. The following is the data fragmentation configuration in GA version 4.1.1. The fragmentation strategy includes five strategies: standard, complex, inline, hint and none. The parameters of different fragmentation strategies are also very different, which makes it difficult for ordinary users to understand and use.
shardingRule:
tables:
t_order:
databaseStrategy:
standard:
shardingColumn: order_id
preciseAlgorithmClassName: xxx
rangeAlgorithmClassName: xxx
complex:
shardingColumns: year, month
algorithmClassName: xxx
hint:
algorithmClassName: xxx
inline:
shardingColumn: order_id
algorithmExpression: ds_${order_id % 2}
none:
tableStrategy:
...Version 5.0.0 GA simplifies the slicing strategy in the slicing API. Firstly, the original inline strategy is removed and only the four slicing strategies of standard, complex, hint and none are retained. At the same time, the slicing algorithm is extracted from the slicing strategy and placed under the shardingAlgorithms attribute for separate configuration, You can refer to shardingAlgorithmName attribute in the sharding policy.
rules:
- !SHARDING
tables:
t_order:
databaseStrategy:
standard:
shardingColumn: order_id
shardingAlgorithmName: database_inline
complex:
shardingColumns: year, month
shardingAlgorithmName: database_complex
hint:
shardingAlgorithmName: database_hint
none:
tableStrategy:
...
shardingAlgorithms:
database_inline:
type: INLINE
props:
algorithm-expression: ds_${order_id % 2}
database_complex:
type: CLASS_BASED
props:
strategy: COMPLEX
algorithmClassName: xxx
database_hint:
type: CLASS_BASED
props:
strategy: HINT
algorithmClassName: xxxThe above configuration is modified according to the partition configuration of GA version 4.1.1. It can be seen that the new partition API is more concise and clear. At the same time, in order to reduce the amount of configuration, Apache ShardingSphere provides many built-in fragmentation algorithms for users to choose from. Users can also use class_ Customized based segmentation algorithm. For more information about the built-in slicing algorithm, please refer to the official document built-in algorithm - slicing algorithm:
https://shardingsphere.apache...
In addition to optimizing the data slicing API, in order to achieve transparent data slicing, version 5.0.0 GA also provides an automatic slicing strategy. The following shows the difference between automatic partition policy configuration and manual declaration partition policy configuration:
rules:
- !SHARDING
autoTables:
# Automatic slicing strategy
t_order:
actualDataSources: ds_0, ds_1
shardingStrategy:
standard:
shardingColumn: order_id
shardingAlgorithmName: auto_mod
keyGenerateStrategy:
column: order_id
keyGeneratorName: snowflake
shardingAlgorithms:
auto_mod:
type: MOD
props:
sharding-count: 4
tables:
# Manually declare fragmentation policy
t_order:
actualDataNodes: ds_${0..1}.t_order_${0..1}
tableStrategy:
standard:
shardingColumn: order_id
shardingAlgorithmName: table_inline
dataBaseStrategy:
standard:
shardingColumn: user_id
shardingAlgorithmName: database_inlineThe automatic sharding policy needs to be configured under the autoTables attribute. Users only need to specify the data source of data storage and specify the number of shards through the automatic sharding algorithm. There is no need to manually declare the data distribution through the actualdata nodes, and there is no need to specially set the database and table policies. Apache ShardingSphere will automatically realize the data sharding management.
In addition, the defaultDataSourceName configuration in the data slicing API is deleted in version 5.0.0 GA. In version 5.0.0 GA, Apache ShardingSphere is positioned as a distributed database ecosystem. Users can directly use the services provided by Apache ShardingSphere like traditional databases, so users do not need to perceive the underlying database storage. Apache ShardingSphere manages single tables outside of data fragmentation through the built-in SingleTableRule to help users realize the automatic loading and routing of single tables.
In version 5.0.0 GA, in order to further simplify the user configuration and cooperate with the defaultDatabaseStrategy and defaultTableStrategy fragmentation strategies in the data fragmentation API, the defaultShardingColumn configuration is added as the default fragmentation key. When multiple table sharding keys are the same, you can use the default shardingColumn configuration instead of configuring shardingColumn. In the following slice configuration, t_ The default shardingColumn configuration will be used for the sharding strategy of the order table.
rules:
- !SHARDING
tables:
t_order:
actualDataNodes: ds_${0..1}.t_order_${0..1}
tableStrategy:
standard:
shardingAlgorithmName: table_inline
defaultShardingColumn: order_id
defaultDatabaseStrategy:
standard:
shardingAlgorithmName: database_inline
defaultTableStrategy:
none:Read write separation API adjustment
The basic functions of the read-write separation API have not changed much in version 5.0.0 GA, except that MasterSlave is adjusted to ReadWriteSplitting, and other usages are basically the same. The following is a comparison of the read-write separation API between version 4.1.1 GA and version 5.0.0 GA.
# 4.1.1 GA read write separation API
masterSlaveRule:
name: ms_ds
masterDataSourceName: master_ds
slaveDataSourceNames:
- slave_ds_0
- slave_ds_1
# 5.0.0 GA read write separation API
rules:
- !READWRITE_SPLITTING
dataSources:
pr_ds:
writeDataSourceName: write_ds
readDataSourceNames:
- read_ds_0
- read_ds_1In addition, in version 5.0.0 GA, the high availability function is developed based on the pluggable architecture. The read-write separation can cooperate with the high availability function to provide the high availability version read-write separation that can automatically switch the master and slave. You are welcome to pay attention to the subsequent official documents and technical sharing of the high availability function.
Encryption and decryption API adjustment
The encryption and decryption API is slightly optimized in version 5.0.0 GA, and the queryWithCipherColumn attribute at the table level is added to facilitate users to control the plaintext and ciphertext switching of encryption and decryption fields at the table level. Other configurations are basically the same as those in version 4.1.1 GA.
rules:
- !ENCRYPT
encryptors:
aes_encryptor:
type: AES
props:
aes-key-value: 123456abc
md5_encryptor:
type: MD5
tables:
t_encrypt:
columns:
user_id:
plainColumn: user_plain
cipherColumn: user_cipher
encryptorName: aes_encryptor
order_id:
cipherColumn: order_cipher
encryptorName: md5_encryptor
queryWithCipherColumn: true
queryWithCipherColumn: falseShadow reservoir pressure measurement API adjustment
The shadow database pressure test API has been comprehensively adjusted in version 5.0.0 GA. firstly, the logical columns in the shadow database are deleted, and a powerful shadow database matching algorithm is added to help users realize more flexible routing control. The following is the API of shadow library pressure measurement in version 4.1.1 GA. generally, the function is relatively simple. Judge whether to start shadow library pressure measurement according to the corresponding value of logic column.
shadowRule:
column: shadow
shadowMappings:
ds: shadow_dsIn version 5.0.0 GA, the shadow database pressure measurement API is more powerful. Users can control whether to enable shadow database pressure measurement through the enable attribute. At the same time, they can fine-grained control the production table that needs shadow database pressure measurement according to the table dimension, and support a variety of different matching algorithms, such as column value matching algorithm, column regular expression matching algorithm and SQL annotation matching algorithm.
rules:
- !SHADOW
enable: true
dataSources:
shadowDataSource:
sourceDataSourceName: ds
shadowDataSourceName: shadow_ds
tables:
t_order:
dataSourceNames:
- shadowDataSource
shadowAlgorithmNames:
- user-id-insert-match-algorithm
- simple-hint-algorithm
shadowAlgorithms:
user-id-insert-match-algorithm:
type: COLUMN_REGEX_MATCH
props:
operation: insert
column: user_id
regex: "[1]"
simple-hint-algorithm:
type: SIMPLE_NOTE
props:
shadow: true
foo: barIn subsequent technical sharing articles, we will introduce the shadow database pressure measurement function in detail, which will not be described here. For more shadow database matching algorithms, please refer to the official document shadow algorithm: https://shardingsphere.apache...
5.0.0 GA upgrade Guide
The major optimization of GA version 5.0.0 kernel was introduced in detail from three aspects: pluggable kernel architecture, Federation execution engine and kernel function API adjustment. Faced with many differences between the two versions, what we are most concerned about is how to upgrade from 4.1.1 GA to 5.0.0 Ga? Next, based on a typical scenario of data fragmentation, read-write separation and encryption / decryption integration, we will introduce in detail what problems need to be paid attention to in upgrading the 5.0.0 GA version.
In 4.1.1 GA, when multiple functions are combined, they must be based on data fragmentation, and then superimposed read-write separation, encryption and decryption. Therefore, the configuration in 4.1.1 GA is usually as follows:
shardingRule:
tables:
t_order:
actualDataNodes: ms_ds_${0..1}.t_order_${0..1}
tableStrategy:
inline:
shardingColumn: order_id
algorithmExpression: t_order_${order_id % 2}
t_order_item:
actualDataNodes: ms_ds_${0..1}.t_order_item_${0..1}
tableStrategy:
inline:
shardingColumn: order_id
algorithmExpression: t_order_item_${order_id % 2}
bindingTables:
- t_order,t_order_item
broadcastTables:
- t_config
defaultDataSourceName: ds_0
defaultDatabaseStrategy:
inline:
shardingColumn: user_id
algorithmExpression: ms_ds_${user_id % 2}
defaultTableStrategy:
none:
masterSlaveRules:
ms_ds_0:
masterDataSourceName: ds_0
slaveDataSourceNames:
- ds_0_slave_0
- ds_0_slave_1
loadBalanceAlgorithmType: ROUND_ROBIN
ms_ds_1:
masterDataSourceName: ds_1
slaveDataSourceNames:
- ds_1_slave_0
- ds_1_slave_1
loadBalanceAlgorithmType: ROUND_ROBIN
encryptRule:
encryptors:
aes_encryptor:
type: aes
props:
aes.key.value: 123456abc
tables:
t_order:
columns:
content:
plainColumn: content_plain
cipherColumn: content_cipher
encryptor: aes_encryptor
t_user:
columns:
telephone:
plainColumn: telephone_plain
cipherColumn: telephone_cipher
encryptor: aes_encryptorAs can be seen from the above configuration file, t_order and t_order_item is configured with fragmentation rules, and t_ The content field of the order table also sets encryption and decryption rules and uses AES algorithm for encryption and decryption. t_user is an ordinary table without fragmentation, and the telephone field is also configured with encryption and decryption rules. In addition, it should be noted that the read-write separation rules and encryption and decryption rules are configured in the fragmentation rules in the form of attributes, which is also the specific embodiment of the function dependence in 4.1.1 GA. other functions must be based on data fragmentation.
After the configuration is completed, we start the Proxy access terminal of version 4.1.1 GA to t_order,t_order_item and t_ Initialize the user table. The execution result of initialization statement is as follows:
CREATE TABLE t_order(order_id INT(11) PRIMARY KEY, user_id INT(11), content VARCHAR(100)); # Logic SQL: CREATE TABLE t_order(order_id INT(11) PRIMARY KEY, user_id INT(11), content VARCHAR(100)) # Actual SQL: ds_0 ::: CREATE TABLE t_order_0(order_id INT(11) PRIMARY KEY, user_id INT(11), content VARCHAR(100)) # Actual SQL: ds_0 ::: CREATE TABLE t_order_1(order_id INT(11) PRIMARY KEY, user_id INT(11), content VARCHAR(100)) # Actual SQL: ds_1 ::: CREATE TABLE t_order_0(order_id INT(11) PRIMARY KEY, user_id INT(11), content VARCHAR(100)) # Actual SQL: ds_1 ::: CREATE TABLE t_order_1(order_id INT(11) PRIMARY KEY, user_id INT(11), content VARCHAR(100)) CREATE TABLE t_order_item(item_id INT(11) PRIMARY KEY, order_id INT(11), user_id INT(11), content VARCHAR(100)); # Logic SQL: CREATE TABLE t_order_item(item_id INT(11) PRIMARY KEY, order_id INT(11), user_id INT(11), content VARCHAR(100)) # Actual SQL: ds_0 ::: CREATE TABLE t_order_item_0(item_id INT(11) PRIMARY KEY, order_id INT(11), user_id INT(11), content VARCHAR(100)) # Actual SQL: ds_0 ::: CREATE TABLE t_order_item_1(item_id INT(11) PRIMARY KEY, order_id INT(11), user_id INT(11), content VARCHAR(100)) # Actual SQL: ds_1 ::: CREATE TABLE t_order_item_0(item_id INT(11) PRIMARY KEY, order_id INT(11), user_id INT(11), content VARCHAR(100)) # Actual SQL: ds_1 ::: CREATE TABLE t_order_item_1(item_id INT(11) PRIMARY KEY, order_id INT(11), user_id INT(11), content VARCHAR(100)) CREATE TABLE t_user(user_id INT(11) PRIMARY KEY, telephone VARCHAR(100)); # Logic SQL: CREATE TABLE t_user(user_id INT(11) PRIMARY KEY, telephone VARCHAR(100)) # Actual SQL: ds_0 ::: CREATE TABLE t_user(user_id INT(11) PRIMARY KEY, telephone VARCHAR(100))
t_ The routing rewriting of the order table fragmentation function is normal, but the rewriting corresponding to the encryption and decryption function is not supported, because version 4.1.1 GA does not support the rewriting of DDL statements in the encryption and decryption scenario. Therefore, the user needs to create the corresponding encryption and decryption table on the underlying database in advance. The DDL statements support encryption and decryption rewriting, which is perfectly supported in version 5.0.0 GA, The unnecessary operation of users is reduced.
t_ order_ Since the item table does not involve encryption and decryption, the result of route rewriting is normal. t_ The user table also has the problem of rewriting encryption and decryption DDL statements, and t_ The user table was routed to ds_0 data source, because we have configured defaultdatasourcename: DS in the fragmentation rule_ 0, so for non fragmented tables, this rule will be used for routing.
For t_order table and t_user table, we manually create the encryption and decryption table on the underlying database corresponding to the routing result through the following SQL.
# ds_0 create t_order_0,t_order_1 and t_user CREATE TABLE t_order_0(order_id INT(11) PRIMARY KEY, user_id INT(11), content_plain VARCHAR(100), content_cipher VARCHAR(100)) CREATE TABLE t_order_1(order_id INT(11) PRIMARY KEY, user_id INT(11), content_plain VARCHAR(100), content_cipher VARCHAR(100)) CREATE TABLE t_user(user_id INT(11) PRIMARY KEY, telephone_plain VARCHAR(100), telephone_cipher VARCHAR(100)) # ds_1 create t_order_0 and t_ order_ one CREATE TABLE t_order_0(order_id INT(11) PRIMARY KEY, user_id INT(11), content_plain VARCHAR(100), content_cipher VARCHAR(100)) CREATE TABLE t_order_1(order_id INT(11) PRIMARY KEY, user_id INT(11), content_plain VARCHAR(100), content_cipher VARCHAR(100))
We restart the Proxy and report to t_order,t_order_item and t_ Add data to the user table. t_order and t_order_ In the process of inserting data into the item table, it will be routed to the corresponding data node according to the fragmentation key and the configured fragmentation strategy. t_ The user table routes to DS according to the defaultDataSourceName configuration_ 0 data source.
INSERT INTO t_order(order_id, user_id, content) VALUES(1, 1, 'TEST11'), (2, 2, 'TEST22'), (3, 3, 'TEST33'); # Logic SQL: INSERT INTO t_order(order_id, user_id, content) VALUES(1, 1, 'TEST11'), (2, 2, 'TEST22'), (3, 3, 'TEST33') # Actual SQL: ds_0 ::: INSERT INTO t_order_0(order_id, user_id, content_cipher, content_plain) VALUES(2, 2, 'mzIhTs2MD3dI4fqCc5nF/Q==', 'TEST22') # Actual SQL: ds_1 ::: INSERT INTO t_order_1(order_id, user_id, content_cipher, content_plain) VALUES(1, 1, '3qpLpG5z6AWjRX2sRKjW2g==', 'TEST11'), (3, 3, 'oVkQieUbS3l/85axrf5img==', 'TEST33') INSERT INTO t_order_item(item_id, order_id, user_id, content) VALUES(1, 1, 1, 'TEST11'), (2, 2, 2, 'TEST22'), (3, 3, 3, 'TEST33'); # Logic SQL: INSERT INTO t_order_item(item_id, order_id, user_id, content) VALUES(1, 1, 1, 'TEST11'), (2, 2, 2, 'TEST22'), (3, 3, 3, 'TEST33') # Actual SQL: ds_0 ::: INSERT INTO t_order_item_0(item_id, order_id, user_id, content) VALUES(2, 2, 2, 'TEST22') # Actual SQL: ds_1 ::: INSERT INTO t_order_item_1(item_id, order_id, user_id, content) VALUES(1, 1, 1, 'TEST11'), (3, 3, 3, 'TEST33') INSERT INTO t_user(user_id, telephone) VALUES(1, '11111111111'), (2, '22222222222'), (3, '33333333333'); # Logic SQL: INSERT INTO t_user(user_id, telephone) VALUES(1, '11111111111'), (2, '22222222222'), (3, '33333333333') # Actual SQL: ds_0 ::: INSERT INTO t_user(user_id, telephone_cipher, telephone_plain) VALUES(1, 'jFZBCI7G9ggRktThmMlClQ==', '11111111111'), (2, 'lWrg5gaes8eptaQkUM2wtA==', '22222222222'), (3, 'jeCwC7gXus4/1OflXeGW/w==', '33333333333')
Then execute several simple query statements to see whether the read-write separation takes effect. According to the log, t_order and t_order_ The item table is encrypted, decrypted and rewritten, and correctly routed to the slave library. And t_ The user table is still routed to ds_0 is executed on the data source, and the read-write separation rule configured in the rule does not work. This is because in version 4.1.1 GA, read-write separation and encryption and decryption are integrated based on fragmentation functions. This scheme naturally limits the cooperation of functions other than fragmentation.
SELECT * FROM t_order WHERE user_id = 1 AND order_id = 1; # Logic SQL: SELECT * FROM t_order WHERE user_id = 1 AND order_id = 1 # Actual SQL: ds_1_slave_0 ::: SELECT order_id, user_id, content_plain, content_cipher FROM t_order_1 WHERE user_id = 1 AND order_id = 1 SELECT * FROM t_order_item WHERE user_id = 1 AND order_id = 1; # Logic SQL: SELECT * FROM t_order_item WHERE user_id = 1 AND order_id = 1 # Actual SQL: ds_1_slave_1 ::: SELECT * FROM t_order_item_1 WHERE user_id = 1 AND order_id = 1 SELECT * FROM t_user WHERE user_id = 1; # Logic SQL: SELECT * FROM t_user WHERE user_id = 1 # Actual SQL: ds_0 ::: SELECT user_id, telephone_plain, telephone_cipher FROM t_user WHERE user_id = 1
Based on the pluggable architecture, version 5.0.0 GA comprehensively upgrades the kernel, and all functions in the kernel can be used in any combination. Meanwhile, in version 5.0.0 GA, the defaultDataSourceName that needs to be additionally configured by the user is deleted. By default, the metadata loading and routing of a single table are realized through SingleTableRule. Let's take a look at how the same functions are configured and used in version 5.0.0 GA. The specific configuration is as follows:
rules:
- !SHARDING
tables:
t_order:
actualDataNodes: ms_ds_${0..1}.t_order_${0..1}
tableStrategy:
standard:
shardingColumn: order_id
shardingAlgorithmName: t_order_inline
t_order_item:
actualDataNodes: ms_ds_${0..1}.t_order_item_${0..1}
tableStrategy:
standard:
shardingColumn: order_id
shardingAlgorithmName: t_order_item_inline
bindingTables:
- t_order,t_order_item
broadcastTables:
- t_config
defaultDatabaseStrategy:
standard:
shardingColumn: user_id
shardingAlgorithmName: database_inline
defaultTableStrategy:
none:
shardingAlgorithms:
database_inline:
type: INLINE
props:
algorithm-expression: ms_ds_${user_id % 2}
t_order_inline:
type: INLINE
props:
algorithm-expression: t_order_${order_id % 2}
t_order_item_inline:
type: INLINE
props:
algorithm-expression: t_order_item_${order_id % 2}
- !READWRITE_SPLITTING
dataSources:
ms_ds_0:
writeDataSourceName: ds_0
readDataSourceNames:
- ds_0_slave_0
- ds_0_slave_1
loadBalancerName: ROUND_ROBIN
ms_ds_1:
writeDataSourceName: ds_1
readDataSourceNames:
- ds_1_slave_0
- ds_1_slave_1
loadBalancerName: ROUND_ROBIN
- !ENCRYPT
encryptors:
aes_encryptor:
type: AES
props:
aes-key-value: 123456abc
tables:
t_order:
columns:
content:
plainColumn: content_plain
cipherColumn: content_cipher
encryptor: aes_encryptor
t_user:
columns:
telephone:
plainColumn: telephone_plain
cipherColumn: telephone_cipher
encryptor: aes_encryptorFirstly, from the perspective of configuration, the biggest difference between version 5.0.0 GA and version 4.1.1 GA lies in the relationship between different functions. They are a horizontal relationship, and there is no function dependency in 4.1.1 GA. each function can be loaded and unloaded flexibly through pluggable mode. Secondly, when these functions are integrated, they use a transmission method similar to the pipeline. For example, the read-write separation rule aggregates two logical data sources based on two groups of master-slave relationships, namely ms_ds_0 and ms_ds_1. Data fragmentation rules configure data fragmentation rules based on the logical data source aggregated by read-write separation, so as to aggregate the logical table t_order. The encryption and decryption function focuses on rewriting columns and values, and configures encryption and decryption rules for the logical table aggregated by the data fragmentation function. The functions of read-write separation, data fragmentation and encryption and decryption are transmitted layer by layer, and the functions are continuously increased through the decoration mode.
In order to compare the functions of version 4.1.1 GA, we execute the same initialization statement, insert statement and query statement to test version 5.0.0 GA.
CREATE TABLE t_order(order_id INT(11) PRIMARY KEY, user_id INT(11), content VARCHAR(100)); # Logic SQL: CREATE TABLE t_order(order_id INT(11) PRIMARY KEY, user_id INT(11), content VARCHAR(100)) # Actual SQL: ds_1 ::: CREATE TABLE t_order_0(order_id INT(11) PRIMARY KEY, user_id INT(11), content_cipher VARCHAR(100), content_plain VARCHAR(100)) # Actual SQL: ds_1 ::: CREATE TABLE t_order_1(order_id INT(11) PRIMARY KEY, user_id INT(11), content_cipher VARCHAR(100), content_plain VARCHAR(100)) # Actual SQL: ds_0 ::: CREATE TABLE t_order_0(order_id INT(11) PRIMARY KEY, user_id INT(11), content_cipher VARCHAR(100), content_plain VARCHAR(100)) # Actual SQL: ds_0 ::: CREATE TABLE t_order_1(order_id INT(11) PRIMARY KEY, user_id INT(11), content_cipher VARCHAR(100), content_plain VARCHAR(100)) CREATE TABLE t_order_item(item_id INT(11) PRIMARY KEY, order_id INT(11), user_id INT(11), content VARCHAR(100)); # Logic SQL: CREATE TABLE t_order_item(item_id INT(11) PRIMARY KEY, order_id INT(11), user_id INT(11), content VARCHAR(100)) # Actual SQL: ds_1 ::: CREATE TABLE t_order_item_0(item_id INT(11) PRIMARY KEY, order_id INT(11), user_id INT(11), content VARCHAR(100)) # Actual SQL: ds_1 ::: CREATE TABLE t_order_item_1(item_id INT(11) PRIMARY KEY, order_id INT(11), user_id INT(11), content VARCHAR(100)) # Actual SQL: ds_0 ::: CREATE TABLE t_order_item_0(item_id INT(11) PRIMARY KEY, order_id INT(11), user_id INT(11), content VARCHAR(100)) # Actual SQL: ds_0 ::: CREATE TABLE t_order_item_1(item_id INT(11) PRIMARY KEY, order_id INT(11), user_id INT(11), content VARCHAR(100)) CREATE TABLE t_user(user_id INT(11) PRIMARY KEY, telephone VARCHAR(100)); # Logic SQL: CREATE TABLE t_user(user_id INT(11) PRIMARY KEY, telephone VARCHAR(100)) # Actual SQL: ds_1 ::: CREATE TABLE t_user(user_id INT(11) PRIMARY KEY, telephone_cipher VARCHAR(100), telephone_plain VARCHAR(100))
In version 5.0.0 GA, support for rewriting of encryption and decryption DDL statements is added, so t_ During the order process, routing and rewriting can be performed normally, whether it is data fragmentation, read-write separation or encryption and decryption. t_ From the log, the user table is routed to ds_1 data source execution, in version 5.0.0 GA, t_user belongs to a single table and does not need to configure the data source. When executing the table creation statement, a data source will be randomly selected for routing. For a single table, we need to ensure that it is unique in the logical database, so as to ensure the accuracy of routing results.
INSERT INTO t_order(order_id, user_id, content) VALUES(1, 1, 'TEST11'), (2, 2, 'TEST22'), (3, 3, 'TEST33'); # Logic SQL: INSERT INTO t_order(order_id, user_id, content) VALUES(1, 1, 'TEST11'), (2, 2, 'TEST22'), (3, 3, 'TEST33') # Actual SQL: ds_1 ::: INSERT INTO t_order_1(order_id, user_id, content_cipher, content_plain) VALUES(1, 1, '3qpLpG5z6AWjRX2sRKjW2g==', 'TEST11'), (3, 3, 'oVkQieUbS3l/85axrf5img==', 'TEST33') # Actual SQL: ds_0 ::: INSERT INTO t_order_0(order_id, user_id, content_cipher, content_plain) VALUES(2, 2, 'mzIhTs2MD3dI4fqCc5nF/Q==', 'TEST22') INSERT INTO t_order_item(item_id, order_id, user_id, content) VALUES(1, 1, 1, 'TEST11'), (2, 2, 2, 'TEST22'), (3, 3, 3, 'TEST33'); # Logic SQL: INSERT INTO t_order_item(item_id, order_id, user_id, content) VALUES(1, 1, 1, 'TEST11'), (2, 2, 2, 'TEST22'), (3, 3, 3, 'TEST33') # Actual SQL: ds_1 ::: INSERT INTO t_order_item_1(item_id, order_id, user_id, content) VALUES(1, 1, 1, 'TEST11'), (3, 3, 3, 'TEST33') # Actual SQL: ds_0 ::: INSERT INTO t_order_item_0(item_id, order_id, user_id, content) VALUES(2, 2, 2, 'TEST22') INSERT INTO t_user(user_id, telephone) VALUES(1, '11111111111'), (2, '22222222222'), (3, '33333333333'); # Logic SQL: INSERT INTO t_user(user_id, telephone) VALUES(1, '11111111111'), (2, '22222222222'), (3, '33333333333') # Actual SQL: ds_1 ::: INSERT INTO t_user(user_id, telephone_cipher, telephone_plain) VALUES(1, 'jFZBCI7G9ggRktThmMlClQ==', '11111111111'), (2, 'lWrg5gaes8eptaQkUM2wtA==', '22222222222'), (3, 'jeCwC7gXus4/1OflXeGW/w==', '33333333333')
On t_ When the user table performs data insertion, it will automatically route according to the information stored in the metadata, because t in the previous step_ User routed to ds_1 data source, so other statements will be based on t_user: ds_1 such metadata for routing processing.
SELECT * FROM t_order WHERE user_id = 1 AND order_id = 1; # Logic SQL: SELECT * FROM t_order WHERE user_id = 1 AND order_id = 1 # Actual SQL: ds_1_slave_0 ::: SELECT `t_order_1`.`order_id`, `t_order_1`.`user_id`, `t_order_1`.`content_cipher` AS `content` FROM t_order_1 WHERE user_id = 1 AND order_id = 1 SELECT * FROM t_order_item WHERE user_id = 1 AND order_id = 1; # Logic SQL: SELECT * FROM t_order_item WHERE user_id = 1 AND order_id = 1 # Actual SQL: ds_1_slave_1 ::: SELECT * FROM t_order_item_1 WHERE user_id = 1 AND order_id = 1 SELECT * FROM t_user WHERE user_id = 1; # Logic SQL: SELECT * FROM t_user WHERE user_id = 1 # Actual SQL: ds_1_slave_0 ::: SELECT `t_user`.`user_id`, `t_user`.`telephone_cipher` AS `telephone` FROM t_user WHERE user_id = 1
When executing the query statement, we can find that T_ The user table was routed to ds_1_slave_0 data source, which realizes the read-write separation of single table. In version 5.0.0 GA, the Apache ShardingSphere kernel loads through metadata, internally maintains the data distribution information of a single table, and fully considers the scenarios of different function combinations, so that a single table can also be perfectly supported.
There are many new functions in GA version 5.0.0. The case in the upgrade guide only selects some functions that can be supported in both GA versions for comparison. It is expected to help you understand the new functions and realize the function upgrade smoothly. If you are interested in pluggable architecture, Federation execution engine or other new functions, please refer to the official documents for testing.
epilogue
After two years of polishing, Apache ShardingSphere is presented to you with a new attitude. The pluggable architecture kernel provides unlimited possibilities for all developers. In the future, we will continue to develop new functions and enrich the Apache ShardingSphere ecosystem based on the pluggable architecture kernel. The Federation execution engine opens the door to distributed query. In the future, we will focus on memory and performance optimization to provide you with more reliable and efficient distributed query capabilities. Finally, you are also welcome to actively participate in and jointly promote the development of Apache ShardingSphere.
Reference documents
1️⃣ Apache ShardingSphere Release Note: https://github.com/apache/sha...
2️⃣ Brand new sharding configuration API of Release 5.x: https://github.com/apache/sha...
3️⃣ Automatic Sharding Strategies for Databases and Tables: https://github.com/apache/sha...
4️⃣ From middleware to distributed database ecology, ShardingSphere 5.x is changing
5️⃣ What kind of chemical reaction will occur in ShardingSphere X openGauss
six ️⃣ Contribution Guide: https://shardingsphere.apache...
seven ️⃣ Chinese community: https://community.sphere-ex.com/
Welcome to add the community manager wechat (ss_assistant_1), reply to the "communication group" and join the group to communicate and discuss with many ShardingSphere lovers!