What is kafka?
Apache Kafka is a distributed message queue based on publish / subscribe mode. It is an open source message system written by Scala. It is mainly used in the field of big data real-time processing and used to process streaming data. It is a very classic message engine and is famous for its high performance and high availability. It was first developed by LinkedIn and later became part of the Apache project.
So here comes the question...,
- Why do I need a message engine? Why kafka? Why can't you just go to rpc?
- How does the message engine work?
- How does kafka achieve high performance and high availability?
- In what form does kafka's message persist?
- Since I wrote the disk, why is it so fast?
- How does kafka ensure that messages are not lost?
A1: why do you need a message engine? Why kafka? Why can't you just go to rpc?
Take an order system as an example:
When we place an order, we should first reduce the commodity inventory, then the user pays the deduction, and the merchant account adds money... Finally, we may also send a push or text message to tell the user that the order is successful and the merchant has come to the order.
If the whole order placing process is blocked synchronously, the time will increase, the user waiting time will increase, and the experience will certainly be bad. At the same time, the longer the link the order placing process depends on, the greater the risk will be.
In order to speed up response and reduce risk, we can disassemble some businesses that are not necessarily stuck in the main chain and decouple them from the main business.
The key to placing an order is to ensure the consistency of inventory, user payment and merchant payment, and the notification of messages can be asynchronous, so that the whole order placing process will not be blocked by notifying the merchant or notifying the user, nor will it prompt the order failure because they fail.
The message notification contains the operations of notifying the merchant and notifying the user.
A2: how does the message engine work?
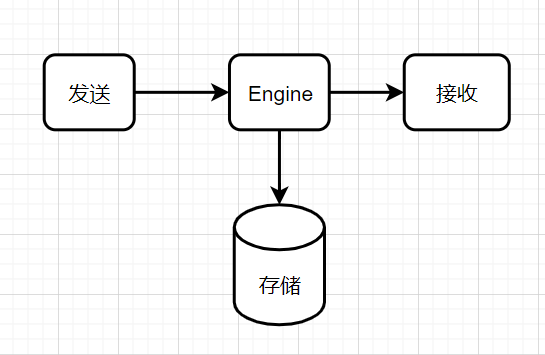
As shown in the figure above, a message engine supports sending, storing and receiving.
The Engine stores the sender's message. When the receiver comes to the Engine for data, the Engine responds to the receiver from the storage.
However, the above figure also has the following problems:
1. Since persistent storage is involved, how to solve the problem of slow disk IO? 2. There may be more than one receiver Take the above order as an example. After the order is completed, the completion event is sent through a message. At this time, the development responsible for the user side push needs to consume this message, and the development responsible for the merchant side push also needs to consume this message. The simplest way to think of is copy Two sets of news, but isn't it a bit wasteful? 3. How to ensure high availability? I.e. if engine What if the node hangs up? 4. The sender may also be multiple If all senders type data to one Leader On node,How to solve the problem of too much pressure on a single node? If you simply create a replica, let the receiver read the message directly from the replica, and the replica is replicated Leader What if your message is delayed? If you can't read the message, read it again Leader?If so, the design of the engine seems more complex and unreasonable.
kafka has solutions to the above problems.
A3: how does Kafka achieve high performance and high availability?
What is high availability?
It refers to the ability of the system to perform its functions without interruption, and represents the availability of the system.
How does kafka ensure high availability?
kafka High Availability Mechanism: Kafka From 0.8 The version provides a high availability mechanism to protect one or more users Broker After downtime, other Broker Can continue to provide services.
kafka's basic architecture:
Multiple broker form. One broker Is a node; Create a topic,this topic Multiple can exist partition On, each partition Can exist in different broker Above, each partition Store some data. This is a natural distributed message queue. kafka At 0.8 Not before HA Mechanism, that is, any one broker It's down, that broker Upper partition It's lost. I can't read or write. There's nothing highly available. kafka At 0.8 After that, I mentioned it HA Mechanism, that is replica Replication mechanism. each partition All data will be synchronized to other machines to form their own replica Copy. be-all replica The copy will elect one leader Come out, then producers and consumers are related to this leader Dealing with others replica namely follower. When writing, leader Will synchronize data to all follower Go up and read directly from leader Just read it above.
Why can only read and write leader s:
Because if you can read and write everything at will follower,Then we should pay attention to the problem of data consistency. The system complexity is too high and it is easy to cause problems. kafka Will evenly partition All data for replica Distributed on different machines, which can improve fault tolerance.
To sum up, high availability can be achieved. If a broker goes down, it's OK. The broker's partition has a copy on other machines. If the broker goes down has a partition leader, a new leader will be re elected and continue to read and write the new leader.
How does kafka guarantee high performance?
1.Sequential read-write solves the problem of slow disk; 2.Zero copy optimizes the efficiency of message interaction on the network When there is no zero copy, the message interaction mode is as follows: 1. Switch to kernel state: the kernel transfers the disk data copy To kernel buffer 2. Switch to user mode: transfer kernel data copy To user program 3. Switch to kernel state: user data copy To kernel socket buffer 4. socket Put data copy To network card As shown below:
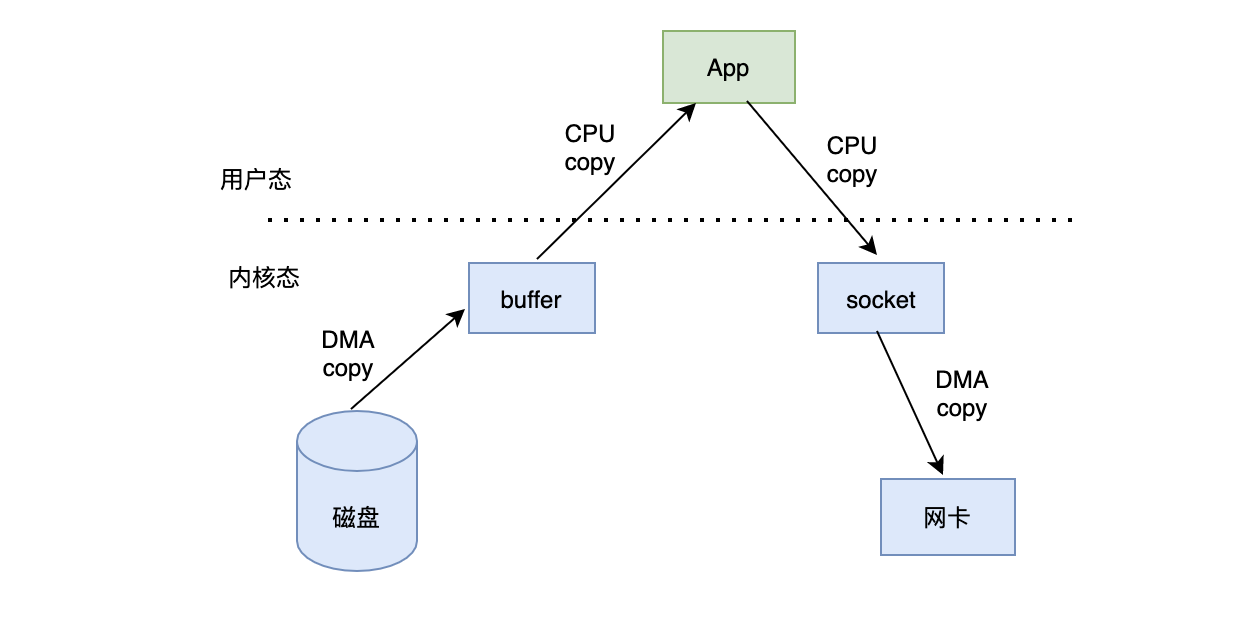
It can be found that a piece of data has been processed many times copy,Finally, it goes back to the kernel state, which is a waste. When zero copy is available:
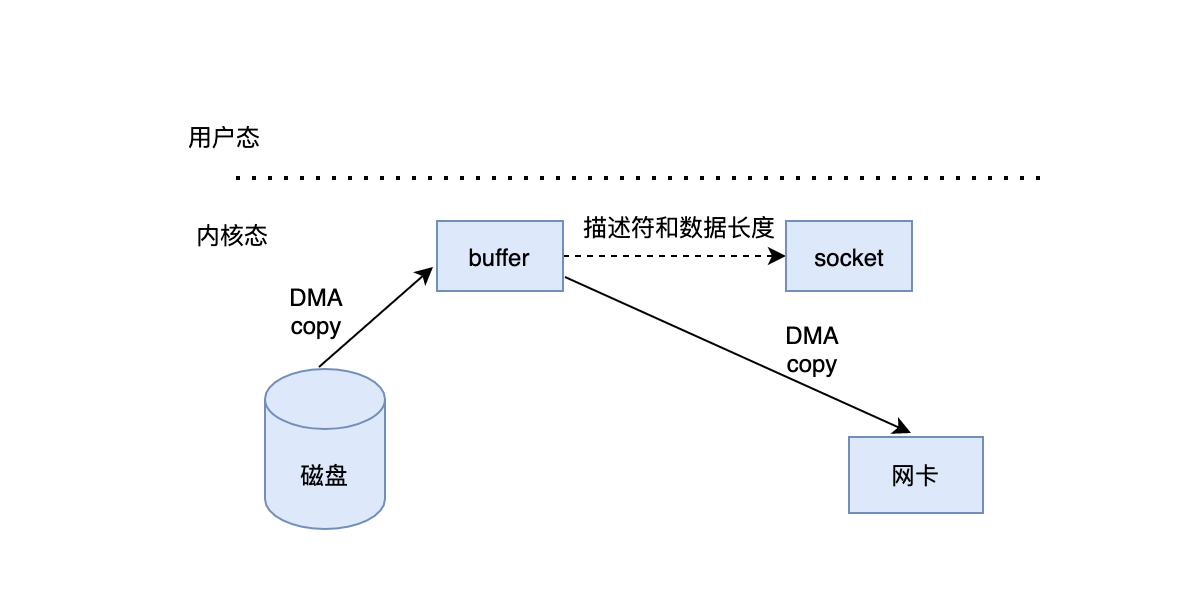
1. Disk data copy To kernel buffer 2. The kernel buffer sends the descriptor and length to socket,At the same time, send the data directly to the network card It can be found that through zero copy, it is reduced twice copy Process, greatly reducing the overhead
A4: in what form does Kafka's message persist?
1. First show the answer:
Kafka largely relies on the file system to store and cache messages. It stores them on disk through the file system and directly writes the data to the log of the file system.
2. Reasons:
Kafka is JVM based, but JVM based memory storage has the following disadvantages:
1,Java The memory overhead of objects is very high, which usually doubles (or more) the size of stored data; 2,With the increase of in pile data, GC The speed of will be slower and slower, and may lead to errors and serious problems GC Performance impact
Therefore, instead of storing the data in the cache, kafka chooses to write it to disk.

A5: since the disk is written, why is the speed so fast?
There is a general understanding of disk storage:
The disk is slow. This makes people doubt the performance of using disk as persistence, But in fact, whether the disk is fast or slow depends entirely on how we use it. For now, a $6 7200 rpm SATA RAID-5 Disk linear (sequential) write performance can reach 600 MB/sec,The performance of write anywhere (address and write again) is only 100 k/sec. These linear reads and writes are the most predictable of all usage modes and are heavily optimized by the operating system--Current operating systems provide pre read and post write technologies.
Therefore, in fact, you will find that sequential disk reads and writes are faster than arbitrary memory reads and writes.
Operating system based file system design has the following benefits:
1,You can use the pagecache To effectively use the main memory space. Due to the compact data, it can cache A lot of data, and no gc Pressure of 2,Even if the service is restarted, the data in the cache is hot (no preheating is required). The process based cache requires the program to warm up and takes a long time. 3,Greatly simplifies the code. Because all the logic for consistency between the cache and the file system OS Yes. The above design makes the implementation of the code very simple. There is no need to find a way to maintain the data in the memory, and the data will be written to the disk immediately. This method is based on page caching( pagecache)Centered design style in an article about Varnish The design is described in detail in the article. in general: Kafka Instead of keeping as much content in memory space as possible, write the content directly to disk as much as possible. All data is written to the file system in the form of persistent log in time, without refreshing the contents of memory to disk.**
3. Log data persistence:
1,Write operation: by appending data to a file 2,Read operation: just read from the file when reading
4. Advantages:
1,Read operations do not block write and other operations: Because both reading and writing are in the form of addition, they are sequential and will not be disordered, so blocking will not occur, and the data size will not affect the performance; 2,Since the message system is built with hard disk space with almost no capacity limit (relative to memory), it can provide some features that the general message system does not have without performance loss. For example:①General message systems delete messages immediately after they are consumed, Kafka You can save the message for a period of time (such as a week); ②Linear access to disk, fast Here you are consumer It provides good mobility and flexibility.
A6: how does Kafka ensure that messages are not lost?
As for the problem of message loss, kafka producers provide three strategies for users to choose. Each strategy has its own advantages and disadvantages and needs to be selected in combination with the actual situation of the business.
From the producer's point of view: kafka of ACK Mechanism, 0,1,-1 The first is that the producer does not care about messages and is only responsible for sending them. This mode is undoubtedly the fastest and the throughput is the best, but it may cause a lot of data loss, such as in borker When there is a problem, the producer still keeps sending, then broker Data will be lost during recovery. The second is that the producer needs all copies to be written successfully, whether or not Leader Copy or Follower Copy, then when Follower The more copies, the worse the throughput theory, but in this mode, the message is the most secure. The third is that producers only need to receive Leader Duplicate ack OK, don't care Follower It is a compromise to ensure a certain degree of security without affecting the throughput.
If you don't care about your data loss and pursue throughput, such as log, you can use the first one;
If you are very concerned about your data security, choose the second;
If you want the throughput to be slightly better and the data to be safer, the third one is recommended, but the third one is imperceptible to the producer when there are problems with the Follower replica.
For further details on kafka message non loss and de duplication, see the next blog post.