What did you say?
JOIN operator is the core operator of data processing. We introduced UnBounded's two-stream JOIN in Apache Flink Talk Series (09) - JOIN Operator earlier. We introduced single-stream and UDTF JOIN operation in Apache Flink Talk Series (10) - JOIN LATERAL. We also introduced single-stream and version table JOIN in Apache Flink Talk Series (11) - Temporal Table JOIN. This article will introduce single-stream and version table JOIN.JOIN operation - Time Interval(Time-windowed)JOIN, which divides data into time dimensions on an UnBounded data stream, is later called Interval JOIN.
practical problem
In the previous section, we introduced Flink support for various JOINs, so think about whether the JOINs described earlier for the following query requirements can be met?The requirements are described as follows:
For example, there is an order form Orders(orderId, productName, orderTime) and a payment form Payment(orderId, payType, payTime).Suppose we want to count the order information for payment within a single hour.
Traditional Database Solutions
It is very simple to complete the above requirements in the traditional Liu database, and the query sql is as follows:
SELECT o.orderId, o.productName, p.payType, o.orderTime, payTime FROM Orders AS o JOIN Payment AS p ON o.orderId = p.orderId AND p.payTime >= orderTime AND p.payTime < orderTime + 3600 // second
The above queries perfectly fulfill the query requirements, so how do you accomplish them in Apache Flink?
Apache Flink Solution
UnBounded Dual Stream JOIN
The above query requirements make it easy to think that UnBounded's two-stream JOIN is introduced using Apache Flink Talk Series (09) - JOIN Operator, with the following SQL statements:
SELECT
o.orderId,
o.productName,
p.payType,
o.orderTime,
payTime
FROM
Orders AS o JOIN Payment AS p ON
o.orderId = p.orderId AND p.payTime >= orderTime AND p.payTime as timestamp < TIMESTAMPADD(SECOND, 3600, orderTime)UnBounded dual-stream JOIN solves the above problem. What does this example have to do with the Interval JOIN described in this article?
Performance issues
Although we can solve the above problem with UnBounded JOIN, a careful analysis of user requirements reveals that this requirement scenario does not require long-term storage of order information and payment information, for example, orders of 2018-12-27 14:22:22 only need to be maintained for one hour, because orders of more than one hour are invalid if they are not paid.Similarly, payment information does not need to be maintained over time. Order payment information for 2018-12-27 14:22:22 would not need to be saved in State if it arrived after 2018-12-27 15:22:22.For UnBounded's two-stream JOIN, we keep the data in State as follows: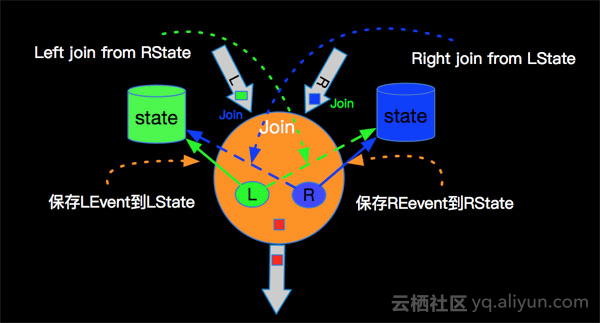
This underlying implementation has an unnecessary performance penalty for current requirements.Therefore, it is necessary to develop a new JOIN (Interval JOIN) method that cleans up State s to fulfill the above query requirements at high performance.
Functional Extensions
Current UnBounded dual-stream JOIN s are followed by Window Aggregate s, which are no longer possible with Event-Time.That is, the following statement is not supported on Apache Flink:
SELECT COUNT(*) FROM (
SELECT
...,
payTime
FROM Orders AS o JOIN Payment AS p ON
o.orderId = p.orderId
) GROUP BY TUMBLE(payTime, INTERVAL '15' MINUTE)Because it is not guaranteed in UnBounded's two-stream JOIN that the payTime value must be greater than WaterMark (WaterMark related can be read <>). Apache Flink's Interval JOIN can be followed by Event-Time's Window Aggregate.
Interval JOIN
To meet these requirements and address performance and functionality extensions, Apache Flink started developing Time-windowed Join, which is the Interval JOIN described in this article, at 1.4.Next we describe the syntax, semantics and implementation of Interval JOIN in detail.
What is Interval JOIN
Interval JOIN is a Bounded JOIN relative to UnBounded's two-stream JOIN.It is the JOIN of each data in each stream and in a different time zone on another stream.Time-windowed JOIN corresponding to the official Apache Flink document (previously called Time-Windowed JOIN until release-1.7).
Interval JOIN Syntax
SELECT ... FROM t1 JOIN t2 ON t1.key = t2.key AND TIMEBOUND_EXPRESSION
TIMEBOUND_EXPRESSION has two ways of writing, as follows:
- L.time between LowerBound(R.time) and UpperBound(R.time)
- R.time between LowerBound(L.time) and UpperBound(L.time)
- A comparison expression with a time attribute (L.time/R.time).
Interval JOIN Semantics
The semantics of an Interval JOIN is that each data corresponds to an Interval data range, such as an order form Orders(orderId, productName, orderTime) and a payment form Payment(orderId, payType, payTime).Suppose we want to count the order information for payment within the next hour.The SQL query is as follows:
SELECT o.orderId, o.productName, p.payType, o.orderTime, cast(payTime as timestamp) as payTime FROM Orders AS o JOIN Payment AS p ON o.orderId = p.orderId AND p.payTime BETWEEN orderTime AND orderTime + INTERVAL '1' HOUR
- Orders Order Data
| orderId | productName | orderTime |
|---|---|---|
| 001 | iphone | 2018-12-26 04:53:22.0 |
| 002 | mac | 2018-12-26 04:53:23.0 |
| 003 | book | 2018-12-26 04:53:24.0 |
| 004 | cup | 2018-12-26 04:53:38.0 |
- Payment data
| orderId | payType | payTime |
|---|---|---|
| 001 | alipay | 2018-12-26 05:51:41.0 |
| 002 | card | 2018-12-26 05:53:22.0 |
| 003 | card | 2018-12-26 05:53:30.0 |
| 004 | alipay | 2018-12-26 05:53:31.0 |
The semantically expected result is that information with order id 003 does not appear in the result table because the order time 2018-12-26 04:53:24.0 and the payment time 2018-12-26 05:53:30.0 exceed one hour of payment.
Then the expected result information is as follows:
| orderId | productName | payType | orderTime | payTime |
|---|---|---|---|---|
| 001 | iphone | alipay | 2018-12-26 04:53:22.0 | 2018-12-26 05:51:41.0 |
| 002 | mac | card | 2018-12-26 04:53:23.0 | 2018-12-26 05:53:22.0 |
| 004 | cup | alipay | 2018-12-26 04:53:38.0 | 2018-12-26 05:53:31.0 |
This makes the Id 003 order invalid and allows you to update your inventory to continue selling.
Next, we illustrate the semantics of Interval JOIN visually, and we need to make a slight change to the sample requirements above: An order can be prepaid (whether reasonable or not, we are just explaining the semantics) that is, an hour's payment before and after the order is valid.The SQL statement is as follows:
SELECT ... FROM Orders AS o JOIN Payment AS p ON o.orderId = p.orderId AND p.payTime BETWEEN orderTime - INTERVAL '1' HOUR AND orderTime + INTERVAL '1' HOUR
Such a query semantics diagram is as follows: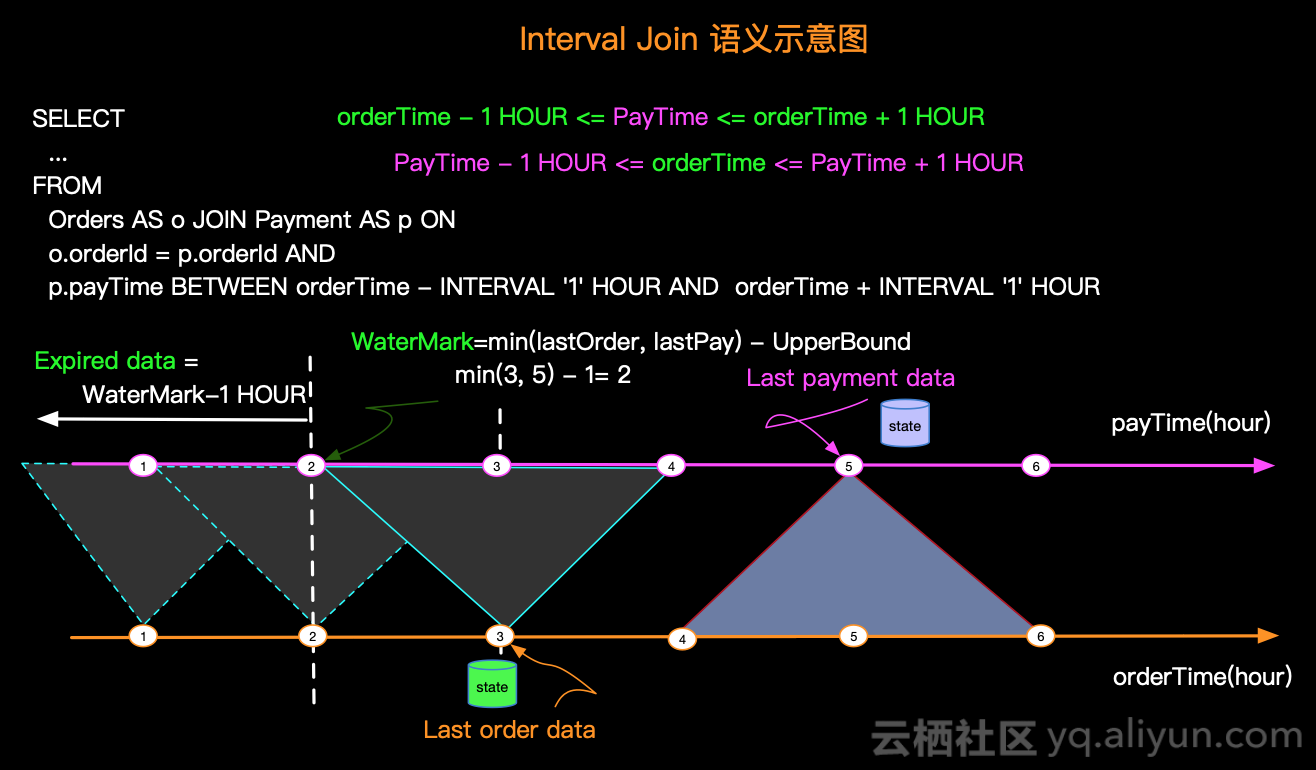
There are several key points in the figure above, as follows:
- The interval of the data JOIN - e.g. orders with Order time 3 will have JOIN in the payment time [2,4] interval.
- WaterMark - For example, if the illustration Order last data time is 3 and Payment last data time is 5, then WaterMark is generated by subtracting UpperBound from the actual minimum, that is, Min(3,5)-1 = 2
- Expired data - For performance and storage reasons, to clear expired data, such as when WaterMark is 2 and data before 2 expires, it can be cleared.
Interval JOIN Implementation Principles
Because both Interval JOIN s and dual-stream JOINs store data on the left and right sides, State is still used for data storage in the underlying implementation.Stream computing is characterized by the constant inflow of data, we can do incremental calculation, that is, we can do JOIN calculation for each data inflow.We also illustrate the internal computing logic with specific examples and illustrations as follows:
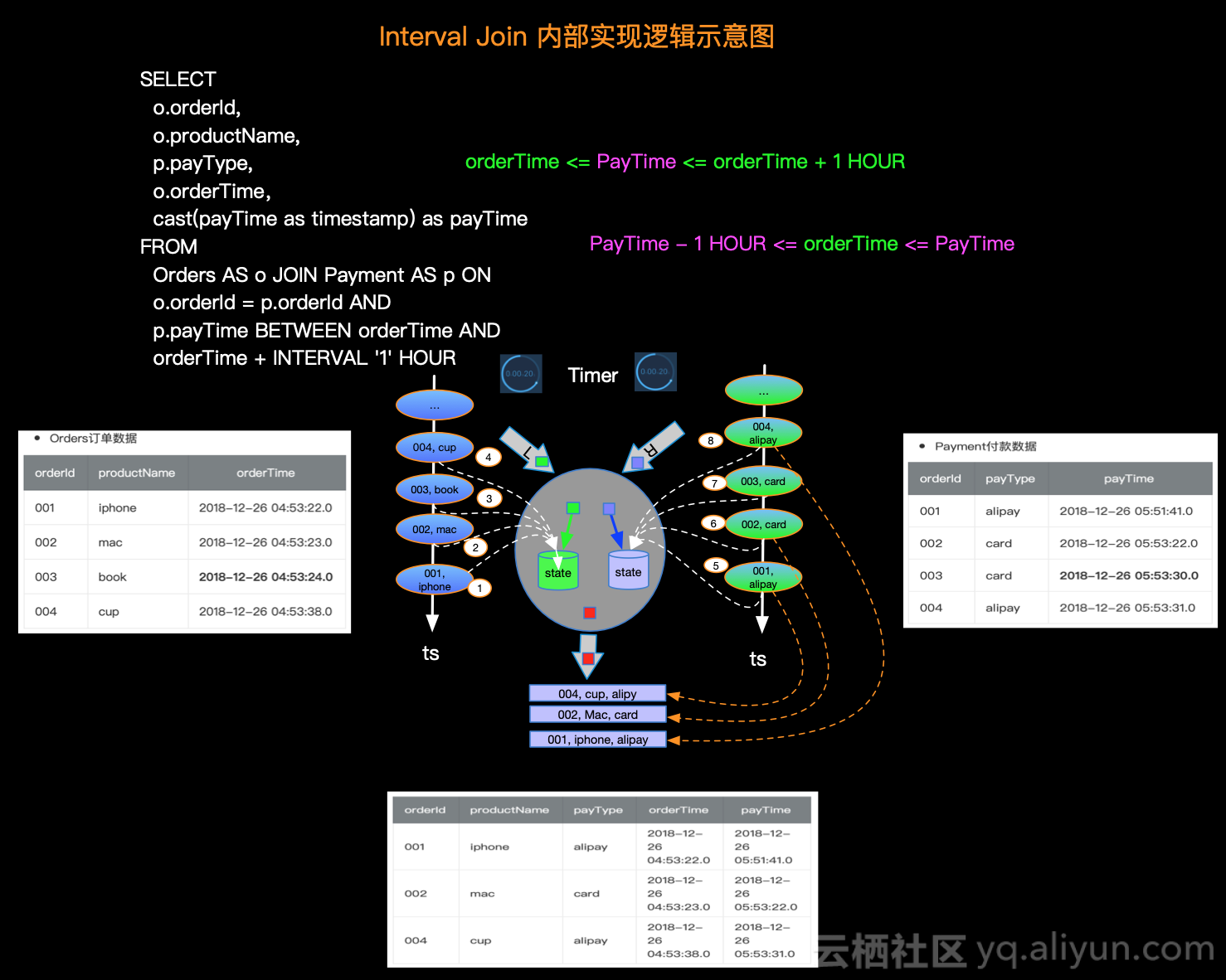
A brief explanation of the processing logic for each record is as follows:
The actual internal logic will be more complex than the description, and you can understand the internal principles as outlined above.
Sample Code
We'll also share the full code with you, using the example of orders and payments, as follows (code based on flink-1.7.0):
import java.sql.Timestamp
import org.apache.flink.api.scala._
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.table.api.TableEnvironment
import org.apache.flink.table.api.scala._
import org.apache.flink.types.Row
import scala.collection.mutable
object SimpleTimeIntervalJoin {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
val tEnv = TableEnvironment.getTableEnvironment(env)
env.setParallelism(1)
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
// Construct order data
val ordersData = new mutable.MutableList[(String, String, Timestamp)]
ordersData.+=(("001", "iphone", new Timestamp(1545800002000L)))
ordersData.+=(("002", "mac", new Timestamp(1545800003000L)))
ordersData.+=(("003", "book", new Timestamp(1545800004000L)))
ordersData.+=(("004", "cup", new Timestamp(1545800018000L)))
// Construct payment form
val paymentData = new mutable.MutableList[(String, String, Timestamp)]
paymentData.+=(("001", "alipay", new Timestamp(1545803501000L)))
paymentData.+=(("002", "card", new Timestamp(1545803602000L)))
paymentData.+=(("003", "card", new Timestamp(1545803610000L)))
paymentData.+=(("004", "alipay", new Timestamp(1545803611000L)))
val orders = env
.fromCollection(ordersData)
.assignTimestampsAndWatermarks(new TimestampExtractor[String, String]())
.toTable(tEnv, 'orderId, 'productName, 'orderTime.rowtime)
val ratesHistory = env
.fromCollection(paymentData)
.assignTimestampsAndWatermarks(new TimestampExtractor[String, String]())
.toTable(tEnv, 'orderId, 'payType, 'payTime.rowtime)
tEnv.registerTable("Orders", orders)
tEnv.registerTable("Payment", ratesHistory)
var sqlQuery =
"""
|SELECT
| o.orderId,
| o.productName,
| p.payType,
| o.orderTime,
| cast(payTime as timestamp) as payTime
|FROM
| Orders AS o JOIN Payment AS p ON o.orderId = p.orderId AND
| p.payTime BETWEEN orderTime AND orderTime + INTERVAL '1' HOUR
|""".stripMargin
tEnv.registerTable("TemporalJoinResult", tEnv.sqlQuery(sqlQuery))
val result = tEnv.scan("TemporalJoinResult").toAppendStream[Row]
result.print()
env.execute()
}
}
class TimestampExtractor[T1, T2]
extends BoundedOutOfOrdernessTimestampExtractor[(T1, T2, Timestamp)](Time.seconds(10)) {
override def extractTimestamp(element: (T1, T2, Timestamp)): Long = {
element._3.getTime
}
}
The results are as follows: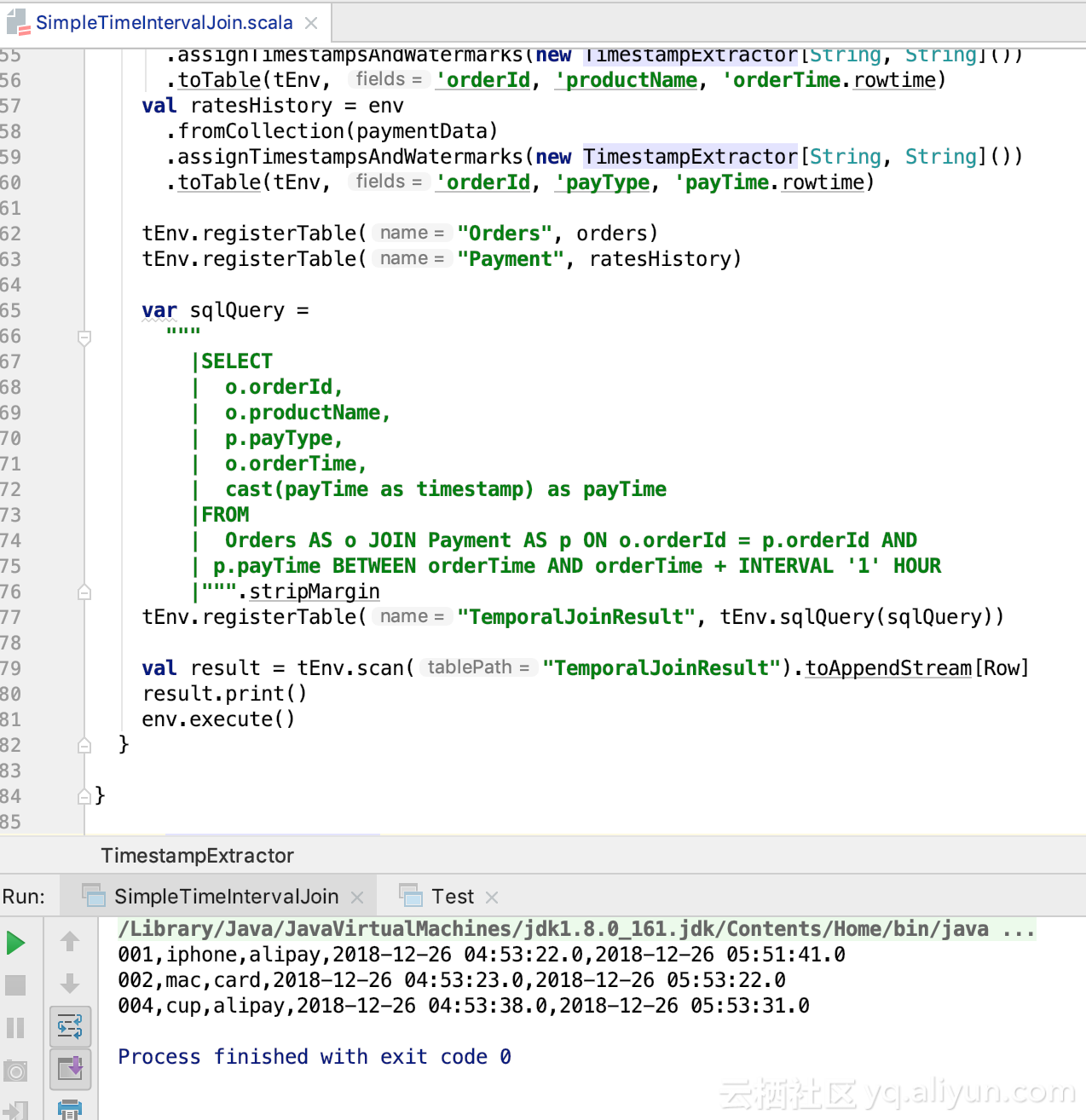
Subsection
Starting from the actual business requirements scenario, this article describes that the same business requirements can be implemented either by using UnBounded dual-stream JOIN or Time Interval JOIN. Time Interval JOIN has better performance than UnBounded dual-stream JOIN and can be computed by Window Aggregate operator after Interval JOIN.Then the syntax, semantics and implementation principle of Interval JOIN are introduced. Finally, the complete sample code of order and payment is shared.I hope this article will give you a specific understanding of Apache Flink Time Interval JOIN!
Author: Golden Bamboo
Source: Ali Yunqi Community
Source link: https://yq.aliyun.com/articles/686809
1. You need to find an organization and learn to communicate with others.Interested students can add QQ group: 732021751.
2. Through reading and learning, unfortunately, Flink is not a systematic and practical book yet, and we expect to wait a few more times.
3. Watch the sharing video of Flink Old Birds. This is really an option for students who want to learn Flink quickly and have some project experience.At present, the most popular IT learning platforms should be "Flink Big Data Project Actual" set of videos, interesting - >. Stamp this link.
