Public Number: Madad's Technical Wheel
Sharing mainly uses ANTLR4 to parse SQL. Take mysql as an example, before analyzing the source code, we can first understand the following three points:
- antlr4, how to write.g4 grammar file
- The mysql grammar can be referred to https://dev.mysql.com/doc/refman/8.0/en/sql-syntax-data-manipulation.html
- Writing mysql g4 file can be referred to https://github.com/antlr/grammars-v4/blob/master/mysql
Source code analysis
1. parsing the entry ParsingSQLRouter#parse
/** * Parsing sql * * @param logicSQL Logic sql * @param useCache Is the parsed result cached? * @return */ @Override public SQLStatement parse(final String logicSQL, final boolean useCache) { //Resolve the front hook, such as calling the chain etx parsingHook.start(logicSQL); try { //Parsing SQL SQLStatement result = new ShardingSQLParseEntry(databaseType, shardingMetaData.getTable(), parsingResultCache).parse(logicSQL, useCache); //Analyzing the Hook after Success parsingHook.finishSuccess(result, shardingMetaData.getTable()); return result; // CHECKSTYLE:OFF } catch (final Exception ex) { // CHECKSTYLE:ON //Analytical Failure Hook parsingHook.finishFailure(ex); throw ex; } }
public final class ShardingSQLParseEntry extends SQLParseEntry { private final DatabaseType databaseType; private final ShardingTableMetaData shardingTableMetaData; public ShardingSQLParseEntry(final DatabaseType databaseType, final ShardingTableMetaData shardingTableMetaData, final ParsingResultCache parsingResultCache) { super(parsingResultCache); this.databaseType = databaseType; this.shardingTableMetaData = shardingTableMetaData; } /** * Obtaining parsing engine encapsulation object based on sql */ @Override protected SQLParseEngine getSQLParseEngine(final String sql) { //Parametric 1: Singleton, loading statement, extracting, filtering configuration files //Parametric 2: Database type //Parametric 3: sql needs to be parsed //Parametric 4: Fragmented table metadata return new SQLParseEngine(ShardingParseRuleRegistry.getInstance(), databaseType, sql, shardingTableMetaData); } }
2. Sharding ParseRuleRegistry. getInstance () - > ParseRuleRegistry # initParseRuleDefinition loads statement, extracts and filters configuration files
private void initParseRuleDefinition() { //Loading META-INF/parsing-rule-definition/extractor-rule-definition.xml configuration file with JAXB ExtractorRuleDefinitionEntity generalExtractorRuleEntity = extractorRuleLoader.load(RuleDefinitionFileConstant.getExtractorRuleDefinitionFile()); //META-INF/parsing-rule-definition/filler-rule-definition.xml configuration file loaded with JAXB FillerRuleDefinitionEntity generalFillerRuleEntity = fillerRuleLoader.load(RuleDefinitionFileConstant.getFillerRuleDefinitionFile()); //Add corresponding type (sharding, master slave, encrypt) configuration files //META-INF/parsing-rule-definition/sharding/filler-rule-definition.xml FillerRuleDefinitionEntity featureGeneralFillerRuleEntity = fillerRuleLoader.load(RuleDefinitionFileConstant.getFillerRuleDefinitionFile(getType())); //Load the corresponding configuration file according to the database type for (DatabaseType each : SQLParserFactory.getAddOnDatabaseTypes()) { //META-INF/parsing-rule-definition/sharding.mysql/filler-rule-definition.xml //databaseType:rules<segment,filler> fillerRuleDefinitions.put(each, createFillerRuleDefinition(generalFillerRuleEntity, featureGeneralFillerRuleEntity, each)); //META-INF/parsing-rule-definition/sharding.mysql/extractor-rule-definition.xml //META-INF/parsing-rule-definition/sharding.mysql/sql-statement-rule-definition.xml //databaseType:rules<xxxContext,SQLStatementRule> sqlStatementRuleDefinitions.put(each, createSQLStatementRuleDefinition(generalExtractorRuleEntity, each)); } } private FillerRuleDefinition createFillerRuleDefinition(final FillerRuleDefinitionEntity generalFillerRuleEntity, final FillerRuleDefinitionEntity featureGeneralFillerRuleEntity, final DatabaseType databaseType) { return new FillerRuleDefinition( generalFillerRuleEntity, featureGeneralFillerRuleEntity, fillerRuleLoader.load(RuleDefinitionFileConstant.getFillerRuleDefinitionFile(getType(), databaseType))); } private SQLStatementRuleDefinition createSQLStatementRuleDefinition(final ExtractorRuleDefinitionEntity generalExtractorRuleEntity, final DatabaseType databaseType) { //Encapsulate all extractors together //id:extractor ExtractorRuleDefinition extractorRuleDefinition = new ExtractorRuleDefinition( generalExtractorRuleEntity, extractorRuleLoader.load(RuleDefinitionFileConstant.getExtractorRuleDefinitionFile(getType(), databaseType))); //sql-statement-rule-definition.xml //Context:SQLStatementRule //SQL statement Rule encapsulates the corresponding extractor of state return new SQLStatementRuleDefinition(statementRuleLoader.load(RuleDefinitionFileConstant.getSQLStatementRuleDefinitionFile(getType(), databaseType)), extractorRuleDefinition); }
3.SQLParseEntry#parse, where SQLParseEntry is abstracted, there are mainly different entries (EncryptSQLParseEntry, MasterSlaveSQLParseEntry, ShardingSQLParseEntry).
@RequiredArgsConstructor public abstract class SQLParseEntry { private final ParsingResultCache parsingResultCache; /** * Parse SQL. * * @param sql SQL * @param useCache use cache or not * @return SQL statement */ public final SQLStatement parse(final String sql, final boolean useCache) { //Get parsed SQL Statement from the cache Optional<SQLStatement> cachedSQLStatement = getSQLStatementFromCache(sql, useCache); if (cachedSQLStatement.isPresent()) { return cachedSQLStatement.get(); } //analysis SQLStatement result = getSQLParseEngine(sql).parse(); //cache if (useCache) { parsingResultCache.put(sql, result); } return result; } private Optional<SQLStatement> getSQLStatementFromCache(final String sql, final boolean useCache) { return useCache ? Optional.fromNullable(parsingResultCache.getSQLStatement(sql)) : Optional.<SQLStatement>absent(); } //Getting SQLParseEngine from getSQLParseEngine of ShardingSQLParseEntry subclass protected abstract SQLParseEngine getSQLParseEngine(String sql); }
4. SQL ParseEngine parse, including parsing, extracting, and filling SQL Statement
public SQLParseEngine(final ParseRuleRegistry parseRuleRegistry, final DatabaseType databaseType, final String sql, final ShardingTableMetaData shardingTableMetaData) { DatabaseType trunkDatabaseType = DatabaseTypes.getTrunkDatabaseType(databaseType.getName()); //sql parsing engine parserEngine = new SQLParserEngine(parseRuleRegistry, trunkDatabaseType, sql); //sql extraction engine extractorEngine = new SQLSegmentsExtractorEngine(); //sql filling engine fillerEngine = new SQLStatementFillerEngine(parseRuleRegistry, trunkDatabaseType, sql, shardingTableMetaData); } /** * Parse SQL. * * @return SQL statement */ public SQLStatement parse() { //Analyzing sql by ANTLR4 SQLAST ast = parserEngine.parse(); //Extract token from ast and encapsulate it into corresponding segment s, such as TableSegment, IndexSegment Collection<SQLSegment> sqlSegments = extractorEngine.extract(ast); Map<ParserRuleContext, Integer> parameterMarkerIndexes = ast.getParameterMarkerIndexes(); //Fill in SQL Statement return fillerEngine.fill(sqlSegments, parameterMarkerIndexes.size(), ast.getSqlStatementRule()); }
5. SQL ParserEngine parse, parse SQL, encapsulate AST(Abstract Syntax Tree abstract syntax tree)
public SQLAST parse() { //SPI uses ANTLR4 parsing to get the execution of SQL Parser (MySQL Parser Entry) and the parsing tree. ParseTree parseTree = SQLParserFactory.newInstance(databaseType, sql).execute().getChild(0); if (parseTree instanceof ErrorNode) { throw new SQLParsingException(String.format("Unsupported SQL of `%s`", sql)); } //Get Statement Context in the configuration file, such as CreateTableContext, SelectContext SQLStatementRule sqlStatementRule = parseRuleRegistry.getSQLStatementRule(databaseType, parseTree.getClass().getSimpleName()); if (null == sqlStatementRule) { throw new SQLParsingException(String.format("Unsupported SQL of `%s`", sql)); } //Encapsulating ast(Abstract Syntax Tree abstract syntax tree) return new SQLAST((ParserRuleContext) parseTree, getParameterMarkerIndexes((ParserRuleContext) parseTree), sqlStatementRule); } /** * Recursively retrieve all parameter placeholders * * @param rootNode Root node * @return */ private Map<ParserRuleContext, Integer> getParameterMarkerIndexes(final ParserRuleContext rootNode) { Collection<ParserRuleContext> placeholderNodes = ExtractorUtils.getAllDescendantNodes(rootNode, RuleName.PARAMETER_MARKER); Map<ParserRuleContext, Integer> result = new HashMap<>(placeholderNodes.size(), 1); int index = 0; for (ParserRuleContext each : placeholderNodes) { result.put(each, index++); } return result; }
6. Create SQL Parser with SQL ParserFactory# new Instance
/** * New instance of SQL parser. * * @param databaseType database type * @param sql SQL * @return SQL parser */ public static SQLParser newInstance(final DatabaseType databaseType, final String sql) { //SPI load all extensions for (SQLParserEntry each : NewInstanceServiceLoader.newServiceInstances(SQLParserEntry.class)) { //Judging database type if (DatabaseTypes.getActualDatabaseType(each.getDatabaseType()) == databaseType) { //Parsing sql return createSQLParser(sql, each); } } throw new UnsupportedOperationException(String.format("Cannot support database type '%s'", databaseType)); } @SneakyThrows private static SQLParser createSQLParser(final String sql, final SQLParserEntry parserEntry) { //Lexical analyzer Lexer lexer = parserEntry.getLexerClass().getConstructor(CharStream.class).newInstance(CharStreams.fromString(sql)); //Parser return parserEntry.getParserClass().getConstructor(TokenStream.class).newInstance(new CommonTokenStream(lexer)); }
7. Take select as an example to analyze the QL parsing, extraction and filling process of the fourth step.
Using idea's antlr4 plug-in, parse the SQL using Sharing's mysql.g4 file; as shown in Figure:
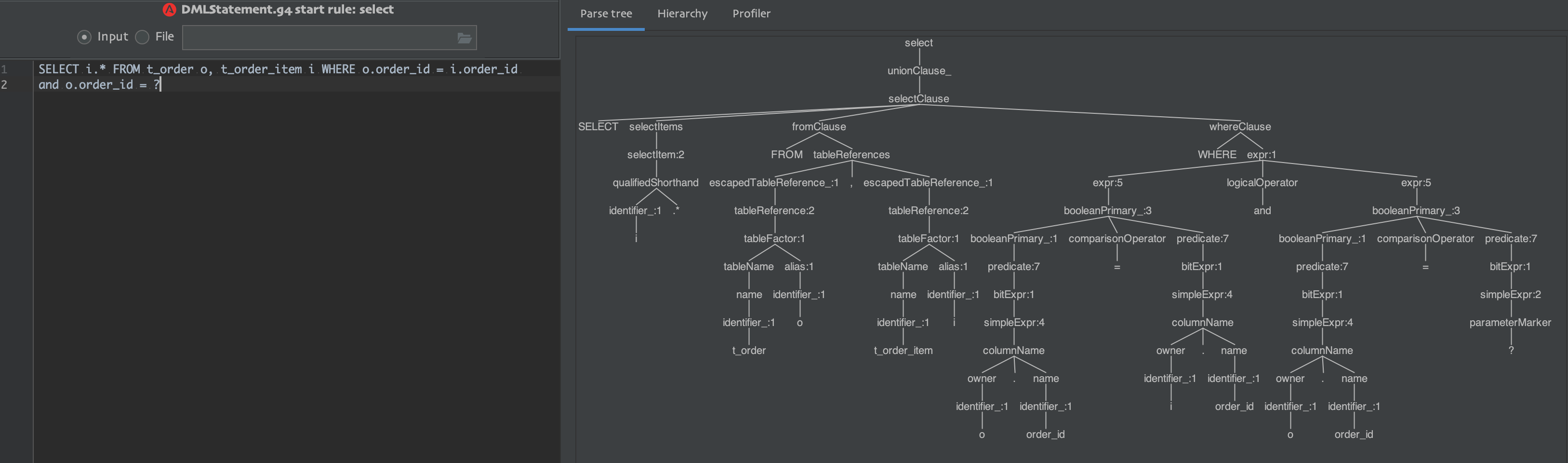
Referring to the above figure, the parameters corresponding to Parser RuleContext are extracted and encapsulated into Segment s using the sharding parse parsing module.
8. SQL Segments Extractor Engine#extract, referring to the seventh graph, according to the corresponding extractors of SQL Statement Rule - > table References, columns, selectItems, where, predicate, groupBy, orderBy, limit, subquery Predicate, generate the corresponding types of Segments.
public final class SQLSegmentsExtractorEngine { /** * Extract SQL segments. * * @param ast SQL AST * @return SQL segments */ public Collection<SQLSegment> extract(final SQLAST ast) { Collection<SQLSegment> result = new LinkedList<>(); //Traversing the Context corresponding extractor, encapsulating the corresponding types of Segments, such as TableSegment, IndexSegment //Take SELECT i.* FROM t_order o, t_order_item i WHERE o.order_id = i.order_id and o.order_id = for example? //SelectContext->SQLStatementRule //SQLStatementRule->tableReferences, columns, selectItems, where, predicate, groupBy, orderBy, limit, subqueryPredicate //Analysis of nine extractors for (SQLSegmentExtractor each : ast.getSqlStatementRule().getExtractors()) { //There are two types //1. Single tree, directly extracting token under single RuleName; see the parsed grammar tree of sql, the contrast is clear. if (each instanceof OptionalSQLSegmentExtractor) { Optional<? extends SQLSegment> sqlSegment = ((OptionalSQLSegmentExtractor) each).extract(ast.getParserRuleContext(), ast.getParameterMarkerIndexes()); if (sqlSegment.isPresent()) { result.add(sqlSegment.get()); } //2. Bifurcated trees need to traverse all Token s extracted under RuleName; see the parsed grammar tree of sql for a clearer comparison. } else if (each instanceof CollectionSQLSegmentExtractor) { result.addAll(((CollectionSQLSegmentExtractor) each).extract(ast.getParserRuleContext(), ast.getParameterMarkerIndexes())); } } return result; } }
9. SQL Statement Filler Engine fill, encapsulate SQL Statement, fill Segment
@RequiredArgsConstructor public final class SQLStatementFillerEngine { private final ParseRuleRegistry parseRuleRegistry; private final DatabaseType databaseType; private final String sql; private final ShardingTableMetaData shardingTableMetaData; /** * Fill SQL statement. * * @param sqlSegments SQL segments * @param parameterMarkerCount parameter marker count * @param rule SQL statement rule * @return SQL statement */ @SneakyThrows public SQLStatement fill(final Collection<SQLSegment> sqlSegments, final int parameterMarkerCount, final SQLStatementRule rule) { //For example, SelectStatement SQLStatement result = rule.getSqlStatementClass().newInstance(); //Logic sql result.setLogicSQL(sql); //Number of parameters result.setParametersCount(parameterMarkerCount); //segment result.getSQLSegments().addAll(sqlSegments); //Traversal fills in the corresponding type of Segment for (SQLSegment each : sqlSegments) { //Find the corresponding filler according to the database type and segment to fill the corresponding segment. //For example: TableSegment - > TableFiller Optional<SQLSegmentFiller> filler = parseRuleRegistry.findSQLSegmentFiller(databaseType, each.getClass()); if (filler.isPresent()) { doFill(each, result, filler.get()); } } return result; } @SuppressWarnings("unchecked") private void doFill(final SQLSegment sqlSegment, final SQLStatement sqlStatement, final SQLSegmentFiller filler) { //Adding fields, field constraints, modifying fields, field commands, these four fillers need to set fragmented table metadata //Fill in the corresponding SQL Statement mainly through fragmented table metadata if (filler instanceof ShardingTableMetaDataAware) { ((ShardingTableMetaDataAware) filler).setShardingTableMetaData(shardingTableMetaData); } //Such as: //Fill SelectStatement tables with TableFill filler.fill(sqlSegment, sqlStatement); } }
The above process of Sharding's SQL parsing, parsing ParserRuleContext to extract the encapsulated Segment, and finally encapsulating the SQL Statement, and filling the SQL Statement according to the Filler corresponding to the Segment; how to extract and fill the SQL Statement can be seen in the following three files
extractor-rule-definition.xml
filler-rule-definition.xml
sql-statement-rule-definition.xml