Android Malware Detection with Seq2vec
Android malware detection based on Seq2vec, and the data set is taken from CICMalDroid 2020 , and feature extraction is carried out.
introduction
Recently, I have been doing research on static detection of Android malware. Previously, I released two versions, both of which have a high recognition rate of Android malware. Now I try to detect Android Malware with Seq2vec method. I tried to use Bi LSTM and CNN, and found that Bi LSTM training is too slow, while CNN network not only trains fast, but also the accuracy of training set can reach more than 97%, and the accuracy of verification set and test set can reach more than 93%.
Previous versions are as follows:
Android Malware Detection with N-gram
1. Data acquisition
Our Android application data comes from the Canadian Institute of network security CICMalDroid 2020 , the Android application data set includes 4033 Benign software, 1512 Adware, 2467 Banking Malware, 3896 Mobile Riskware and 4809 SMS malware.
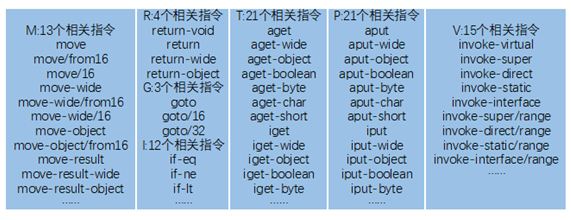
Use Apktool, a decompilation tool provided by Google, to decompile Apk files, and obtain the main source file for running on Dalvik virtual machine - smali files. See the previous version above for batch decompilation and feature extraction script files, which are no longer provided here. smali is an interpretation of Dalvik bytecode. Although it is not an official standard language, all statements follow a set of syntax specifications. Since there are more than 200 Dalvik instructions, we classify and simplify them, remove irrelevant instructions, leave only the instruction set of the seven core classes of M, R, G, I, T, P and V, and only retain the opcode field and remove the parameters. M. The seven instruction sets of R, G, I, T, P and V respectively represent seven types of instructions: move, return, jump, judge, get data, save data and call method. The specific classification is shown in the following figure.
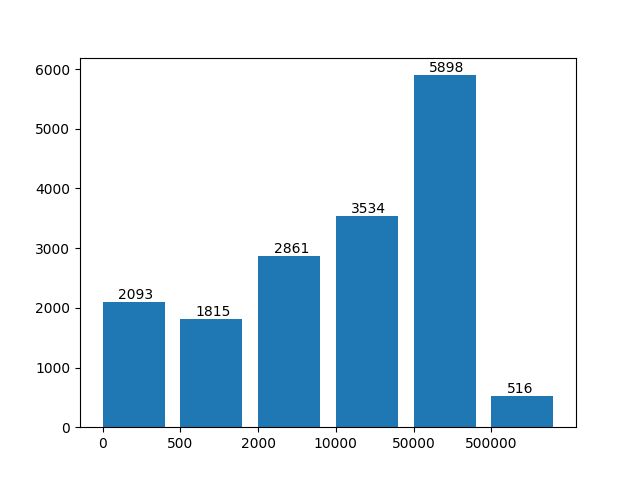
According to the statistics of the data set after feature extraction, it is found that the shortest length of the feature is 10 and the longest can reach 1104801. Its probability distribution is as follows. It can be seen that the distribution is extremely uneven and the unit of data length can be 10000.
# Download paddlenlp #!pip install --upgrade paddlenlp -i https://pypi.org/simple
2. Import the required package
import os import numpy as np import pandas as pd from functools import partial from utils import load_vocab, convert_example from sklearn.model_selection import train_test_split from matplotlib import pyplot as plt import paddle import paddle.nn as nn import paddle.nn.functional as F import paddlenlp as ppnlp from paddlenlp.data import Pad, Stack, Tuple from paddlenlp.datasets import MapDataset from Model import CNNModel import datetime start=datetime.datetime.now()
3 data set and data processing
Custom dataset
In addition to the seven types of instructions, the original data dictionary also includes separator | and filler #. The data reading is also divided into words according to the compression ratio, and the filler # is used to supplement the last word.
-
data_split: divide data according to rate, train_size=origin_size*(1-rate)*(1-rate) test_size=origin_size*rate eval_size=origin_size*(1-rate)*rate
-
vocab_compress: vocab compression. Dict increases exponentially with rate, that is, dict_size=vocab_dict_size^rate, where rate is set to 6
#Data set partition
def data_split(input_file, output_path, rate=0.2):
if not os.path.exists(output_path):
os.makedirs(output_path)
origin_dataset = pd.read_csv(input_file, header=None)[[1,2]] # Add parameters
train_data, test_data = train_test_split(origin_dataset, test_size=rate)
train_data, eval_data = train_test_split(train_data, test_size=rate)
train_filename = os.path.join(output_path, 'train.txt')
test_filename = os.path.join(output_path, 'test.txt')
eval_filename = os.path.join(output_path, 'eval.txt')
train_data.to_csv(train_filename, index=False, sep="\t", header=None)
test_data.to_csv(test_filename, index=False, sep="\t", header=None)
eval_data.to_csv(eval_filename, index=False, sep="\t", header=None)
if not os.path.exists('dataset'):
os.mkdir('dataset')
#You can use data here_ The split function divides the data set again, or copies the data set I have divided to the dataset folder through cp. please choose one of the two methods
#data_split(input_file='data/data86222/mydata.csv',output_path='dataset', rate=0.2)
!cp data/data86222/train.txt dataset/ && cp data/data86222/eval.txt dataset/ && cp data/data86222/test.txt dataset/
vocab_dict={0:'#',1:'|',2:'M',3:'R',4:'G',5:'I',6:'T',7:'P',8:'V'}
#Vocab compression, dict increases exponentially with rate, that is, len(dict)=len(vocab_dict)^rate
#The default rate is 4. It is recommended to set it to 2, 4, 6 and 8, of which 8 is easy to explode the video memory
def vocab_compress(vocab_dict,rate=4):
if rate<=0:
return
with open('dict.txt','w',encoding='utf-8') as fp:
arr=np.zeros(rate,int)
while True:
pos=rate-1
for i in range(rate):
fp.write(vocab_dict[arr[i]])
fp.write('\n')
arr[pos]+=1
while True:
if arr[pos]>=len(vocab_dict):
arr[pos]=0
pos-=1
if pos<0:
return
arr[pos]+=1
else:
break
rate=6
pad=''
unk=''
for i in range(rate):
pad+='#'
unk+='|'
#vocab_compress(vocab_dict,rate)
Load Thesaurus
from paddlenlp.datasets import load_dataset
def read(data_path):
with open(data_path, 'r', encoding='utf-8') as f:
for line in f:
l = line.strip('\n').split('\t')
if len(l) != 2:
print (len(l), line)
words, labels = line.strip('\n').split('\t')
if len(words)==0:
continue
yield {'tokens': words, 'labels': labels}
# data_path is the parameter of the read() method
train_ds = load_dataset(read, data_path='dataset/train.txt',lazy=False)
dev_ds = load_dataset(read, data_path='dataset/eval.txt',lazy=True)
test_ds = load_dataset(read, data_path='dataset/test.txt',lazy=True)
# Load Thesaurus
vocab = load_vocab('dict.txt')
#print(vocab)
In order to process the original data into a format that can be read into the model, the project will process the data as follows:
-
First, use word segmentation to cut into one word every compression ratio rate, and then map the cut word to the word id in the thesaurus.
-
Use the paddle.io.DataLoader interface to load data asynchronously through multiple threads.
The API for data processing in PaddleNLP is used. PaddleNLP provides many common APIs for building effective data pipeline s in NLP tasks
| API | brief introduction |
|---|---|
| paddlenlp.data.Stack | Stack N input data with the same shape to build a batch. Its input must have the same shape, and the output is the batch data composed of the stack of these inputs. |
| paddlenlp.data.Pad | Stack n input data to build a batch. Each input data will be padded to the maximum length of N input data |
| paddlenlp.data.Tuple | Wrap the functions of multiple groups of batch together |
For more data processing operations, see: https://github.com/PaddlePaddle/PaddleNLP/blob/develop/docs/data.md
Construct dataloder
Create below_ data_ The loader function is used to create the DataLoader object required for running and forecasting.
-
The pad.io.dataloader returns an iterator based on batch_ The sampler returns dataset data by iterating in the order specified. Load data asynchronously.
-
batch_sampler: DataLoader through batch_ The mini batch index list generated by the sampler is used to index samples in the dataset and form a mini batch
-
collate_fn: specifies how to combine sample lists into mini batch data. The parameter passed to it needs to be a callable object. It needs to implement the processing logic of the built batch and return the data of each batch. What is passed in here is prepare_input function, pad the generated data and return the actual length, etc.
# Reads data and generates mini-batches.
def create_dataloader(dataset,
trans_function=None,
mode='train',
batch_size=1,
pad_token_id=0,
batchify_fn=None):
if trans_function:
dataset_map = dataset.map(trans_function)
# return_ Whether the list data is returned as a list
# collate_fn specifies how to combine sample lists into mini batch data. The parameter passed to it needs to be a callable object. It needs to implement the processing logic of the built batch and return the data of each batch. 'prepare' is passed in here_ Input ` function, pad the generated data and return the actual length, etc.
dataloader = paddle.io.DataLoader(
dataset_map,
return_list=True,
batch_size=batch_size,
collate_fn=batchify_fn)
return dataloader
# The partial function in python fixes some parameters of a function (that is, sets the default value) and returns a new function. It will be easier to call this new function.
trans_function = partial(
convert_example,
vocab=vocab,
rate=rate,
unk_token_id=vocab.get(unk),
is_test=False)
# Batch the read data to facilitate the batch operation of the model.
# Each sentence in the batch will be padded to the maximum length of the text in the batch_max_seq_len.
# When the text length is greater than batch_ max_ During SEQ, it will be truncated to batch_max_seq_len; When the text length is less than batch_ max_ During SEQ, padding will be added to batch_max_seq_len.
batchify_fn = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=vocab[pad]), # input_ids
Stack(dtype="int64"), # seq len
Stack(dtype="int64") # label
): [data for data in fn(samples)]
train_loader = create_dataloader(
train_ds,
trans_function=trans_function,
batch_size=4,
mode='train',
batchify_fn=batchify_fn)
dev_loader = create_dataloader(
dev_ds,
trans_function=trans_function,
batch_size=4,
mode='validation',
batchify_fn=batchify_fn)
test_loader = create_dataloader(
test_ds,
trans_function=trans_function,
batch_size=4,
mode='test',
batchify_fn=batchify_fn)
4 model construction
Use CNNEncoder to build a CNN model for sentence modeling to obtain the vector representation of sentences.
Then a linear transformation layer is connected to complete the binary classification task.
- Pad.nn.embedding build the word embedding layer
- ppnlp.seq2vec.CNNEncoder constructs sentence modeling layer
- Multiple classifiers constructed by pad.nn.linear
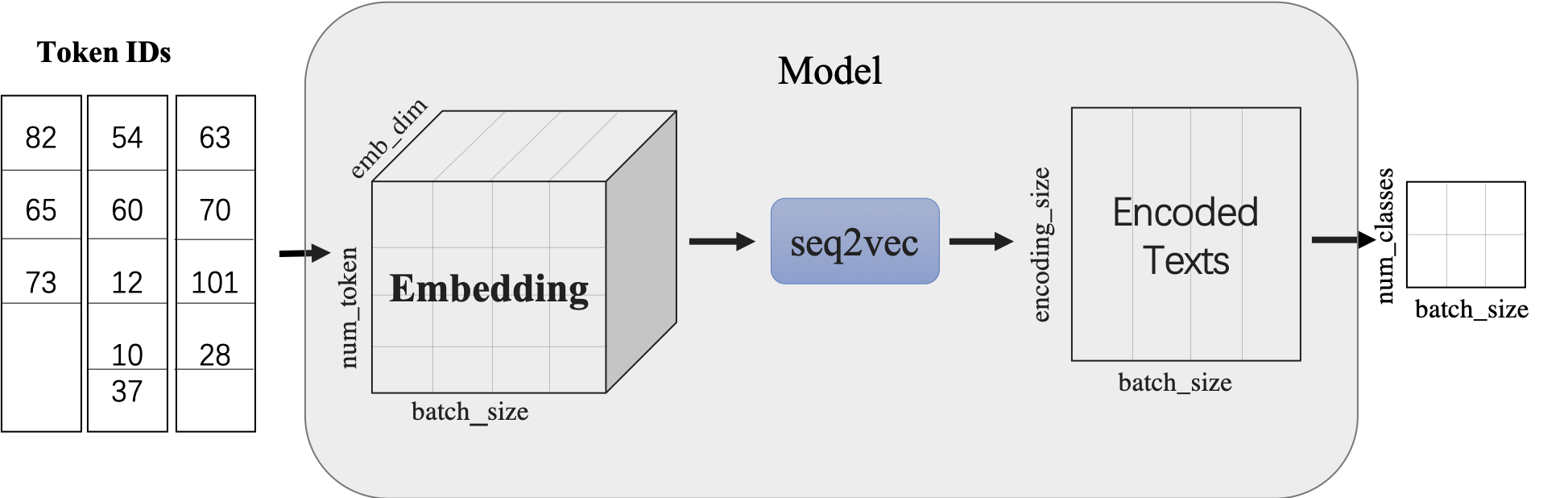
Figure 1: seq2vec schematic diagram
- In addition to CNNEncoder, seq2vec also provides many semantic representation methods. For details, please refer to: seq2vec introduction
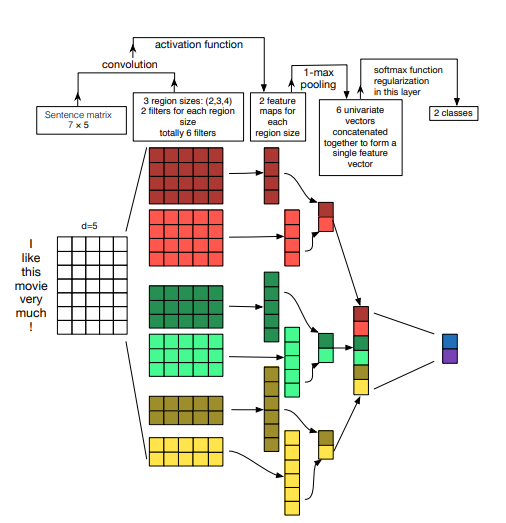
Used here CNNEncoer Based on the paper "A Sensitivity Analysis of (and Practitioners' Guide to) revolutionary neural networks for sensitivity classification", the principle is as follows:
model= CNNModel(
len(vocab),
num_classes=5,
padding_idx=vocab[pad])
model = paddle.Model(model)
# Loading model
#model.load('./checkpoints/final')
5 model configuration and training
Model configuration
optimizer = paddle.optimizer.Adam(
parameters=model.parameters(), learning_rate=1e-5)
loss = paddle.nn.loss.CrossEntropyLoss()
metric = paddle.metric.Accuracy()
model.prepare(optimizer, loss, metric)
# Set visual DL path log_dir = './visualdl' callback = paddle.callbacks.VisualDL(log_dir=log_dir)
model training
loss, acc and other information will be output during training. Ten epoch s are set here, and the accuracy is about 97% in the training set.

model.fit(train_loader, dev_loader, epochs=50, log_freq=50, save_dir='./checkpoints', save_freq=1, eval_freq=1, callbacks=callback)
end=datetime.datetime.now()
print('Running time: %s Seconds'%(end-start))
Calculation model accuracy
results = model.evaluate(train_loader)
print("Finally train acc: %.5f" % results['acc'])
results = model.evaluate(dev_loader)
print("Finally eval acc: %.5f" % results['acc'])
results = model.evaluate(test_loader)
print("Finally test acc: %.5f" % results['acc'])
6 view final forecast
label_map = {0: 'benign', 1: 'adware', 2:'banking', 3:'riskware', 4:'sms'}
results = model.predict(test_loader, batch_size=128)
predictions = []
for batch_probs in results:
# Mapping classification label
idx = np.argmax(batch_probs, axis=-1)
idx = [idx.tolist()]
labels = label_map[i] for i in idx
predictions.extend(labels)
# Take a look at the classification results of the first five samples of forecast data
for i in test_ds:
print(i)
break
for idx, data in enumerate(test_ds):
if idx < 10:
print(type(data))
abels)
# Take a look at the classification results of the first five samples of forecast data
for i in test_ds:
print(i)
break
for idx, data in enumerate(test_ds):
if idx < 10:
print(type(data))
print('Data: {} \t Label: {}'.format(data[0], predictions[idx]))
7 Summary
CNNEncoder is too strong. This time, 50 epoch was trained with 1e-5 lr, and then changed to 1e-6 lr for 10 epochs, which achieved the above effect. Among them, CNNEncoder's ngram_filter_sizes=(1, 2, 3, 4),num_filter=12 is enough. If you are interested, you can try more num_filter to improve accuracy
Please click here View the basic usage of this environment
Please click here for more detailed instructions.