We know that the Java running environment for Android devices with lower version (4.X and below, SDK < 21) is Dalvik virtual machine. Compared with the higher version, the biggest problem is that the first cold start takes a long time after installing or upgrading the update. This often takes tens of seconds or even minutes. Users have to face a black screen, and they can use the APP normally after this period of time.

This has a great impact on the user experience. We can also find from the online data that Android 4.X and below also account for a certain proportion of new users, but the number of retained users is much less than that of new users. Especially overseas, such as Southeast Asia and Latin America, there are still a lot of low-end machines. Although the lower version of 4.X is relatively small, there are tens of millions of APP even tiktok and TikTok, which have a billion scale users, even if they account for 10%. Therefore, if you want to get through the sinking market, the use and upgrading experience of these users cannot be ignored.
The root cause of this problem is that it takes too long to install or upgrade MultiDex for the first time. In order to solve this problem, we excavated the underlying system mechanism of Dalvik virtual machine, redesigned the DEX related processing logic, and finally launched the boost MultiDex scheme, which can reduce the waiting time of black screen by more than 80%, and save the upgrade and installation experience of Android users with low version.
Let's take a look at the comparison data of the first cold start loading DEX time after installation:
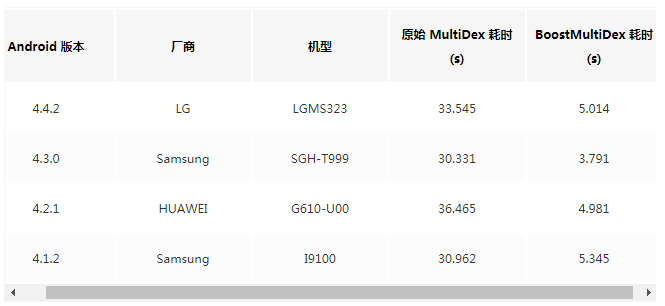
It can be seen that the original MultiDex scheme took more than half a minute to complete the DEX loading, while the boost MultiDex scheme only took less than 5 seconds. The optimization effect is very significant!
Next, we will explain the R & D process and solutions of the whole boost multidex solution in detail.
cause
Let's first look at the root cause of the problem. There are many reasons for this.
First of all, it should be clear that if you want to access a class in Java, you must load them through the ClassLoader to access it. On Android, all classes in APP are loaded by PathClassLoader. The classes are all dependent on the DEX file. Only when the corresponding DEX is loaded, can the classes be used.
In the early days of Android, the instruction format design for DEX was not perfect, and the total number of Java methods referenced in a single DEX file could not exceed 65536.
For the current APP, as long as there is more functional logic, it is easy to reach this limit.
In this way, if the number of Java code methods of an APP exceeds 65536, the APP code cannot be completely installed by a DEX file, then we have to generate multiple DEX files during compilation. We can tiktok the APK and we can see that there are many DEX files inside.
8035972 00-00-1980 00:00 classes.dex 8476188 00-00-1980 00:00 classes2.dex 7882916 00-00-1980 00:00 classes3.dex 9041240 00-00-1980 00:00 classes4.dex 8646596 00-00-1980 00:00 classes5.dex 8644640 00-00-1980 00:00 classes6.dex 5888368 00-00-1980 00:00 classes7.dex
Android 4.4 and below uses Dalvik virtual machine. In general, Dalvik virtual machine can only execute DEX files that have been optimized by OPT, which is often referred to as ODEX files.
When an APK is installed, its classes.dex will automatically do ODEX optimization, and will be directly loaded into the PathClassLoader of the APP by default when the system is started. Therefore, the classes in classes.dex can definitely be accessed directly without our concern.
In addition to its DEX files, which are classes2.dex, classes3.dex, classes4.dex and other DEX files (here we call them Secondary DEX files). These files need to be optimized by ourselves and loaded into ClassLoader to use their classes normally. Otherwise, when accessing these classes, a ClassNotFound exception will be thrown to cause a crash.
As a result, Android officially launched the MultiDex solution. You only need to call MultiDex.install directly in the earliest entry of APP program execution, that is, Application.attachBaseContext. It will unpack APK package, optimize and load the second later DEX file with ODEX. In this way, APK with multiple DEX files can be executed smoothly.
This operation will occur when the APP is cold started for the first time after installation or update. It is because this process takes a long time that we first mentioned the problem of time-consuming black screen.
Original realization
After understanding this background, let's look at the implementation of MultiDex, and the logic will be clear.
First, all the DEX files in APK, such as classes2.dex, classes3.dex, classes4.dex, will be extracted.
Then, ZIP each dex. Generate the classesN.zip file.
Next, we do ODEX optimization for each ZIP file to generate the classesN.zip.odex file.
Specifically, we can see these files in the code & cache directory of APP:
com.bytedance.app.boost_multidex-1.apk.classes2.dex com.bytedance.app.boost_multidex-1.apk.classes2.zip com.bytedance.app.boost_multidex-1.apk.classes3.dex com.bytedance.app.boost_multidex-1.apk.classes3.zip com.bytedance.app.boost_multidex-1.apk.classes4.dex com.bytedance.app.boost_multidex-1.apk.classes4.zip
This step is implemented through the DexFile.loadDex method. Only the path of the original ZIP file and the ODEX file needs to be specified, the corresponding ODEX products can be generated according to the DEX in the ZIP. This method will eventually return a DexFile object.
Finally, APP adds these DexFile objects to pathList of PathClassLoader, so that app can load and use the classes in these DEX through ClassLoader during running.
In the whole process, the process of generating ZIP and ODEX files is quite time-consuming. If there are many Secondary DEX files in an APP, this problem will be aggravated. In particular, in the process of generating ODEX, Dalvik virtual opportunity traverses and scans the files in dex format and optimizes the rewriting process, so as to convert them into ODEX files, which is the biggest time-consuming bottleneck.
Commonly used optimization method
At present, the industry has some methods to optimize MultiDex. Let's take a look at how you usually optimize this process.
Asynchronous loading
Package as many classes as possible to be used in the startup phase into the main Dex, and try not to rely on the Secondary DEX to run business code as much as possible. Then call MultiDex.install asynchronously. If the Secondary DEX needs to be used at a later time point, if the MultiDex has not finished executing, stop and wait for it to finish synchronously before continuing to execute the subsequent code.
In this way, you can actually execute part of the code while install ing without being completely blocked. However, in order to do this, we must first sort out the code of the startup logic and know clearly what can be executed in parallel. In addition, due to the limited code that can be put in the main Dex, if there are too many dependencies in the start-up phase of the business, it cannot be completely put in the main Dex, so it is necessary to reasonably split the dependencies.
Therefore, in reality, the effect of this scheme is relatively limited. If too much business logic is involved in the startup phase, it is likely that too much code can not be executed in parallel, and it will be blocked by install again soon.
Module lazy load
This scheme was first seen in the article of meituan, which can be said to be the upgraded version of the previous scheme.
It also does asynchronous DEX loading, but the difference is that DEX needs to be split by module during compilation.
Generally, the codes involved in the activities, services, receivers and providers of the first level interface are put into the first DEX, while the activities of the second and third level pages and the codes of the non high frequency interface are put into the second DEX.
When a module needs to be executed later, first determine whether the Class of the module has been loaded. If not, wait for the install ation to complete before proceeding.
It can be seen that the business transformation degree of this scheme is quite huge, and there are some rudiments of plug-in framework. In addition, if you want to be able to judge the loading status of the module's Class, you need to inject your own Instrumentation by reflecting the ActivityThread, and insert your own judgment logic before executing the Activity. This will also introduce model compatibility issues accordingly.
Multithreaded loading
The native MultiDex optimizes each DEX file in order. The idea of multithreading is to use each DEX thread as OPT.
At first glance, it seems that ODEX can be done in parallel to achieve optimization effect. However, there are six Secondary DEX files in our project. It is found that this method has little optimization effect. The reason may be that ODEX itself is a heavy I/O type operation. For concurrency, simultaneous I/O by multiple threads does not bring obvious benefits, and multi-threaded switching itself will bring some losses.
Background process loading
This scheme is mainly to prevent the main process from doing ODEX for too long leading to ANR. When you click APP, you start a non main process separately to do the ODEX first, and then call the main process after the non main process finishes the ODEX, so that the main process can directly get a good ODEX. However, this only avoids the problem of the main process anr, and the overall waiting time for the first start does not decrease.
A more thorough optimization scheme
All of the above schemes have been optimized at all levels. However, after careful analysis, we can see that they do not touch the root of this problem, that is, the multi DEX. Install operation itself.
The process of generating ODEX file by MultiDex.install. The method called is DexFile.loadDex. It will start a dexopt process to convert the input DEX file to ODEX. So, can this ODEX optimization time be avoided?
Our boost multidex solution starts from this point and optimizes the time consumption of install in essence.
Our approach is to directly load the original DEX that has not been optimized by OPT during the first startup, so that the APP can start normally. Then start a separate process in the background, slowly finish the OPT work of DEX, and try to avoid affecting the normal use of foreground APP.
Breakthrough point
The difficulty here, naturally, is how to load the original DEX directly and avoid the time-consuming blocking caused by the ODEX optimization.
If you want to avoid ODEX optimization and the APP to run normally, it means that the Dalvik virtual machine needs to directly execute the original DEX file without OPT. Does the virtual machine support direct execution of DEX files? After all, the Dalvik virtual machine can directly execute the original DEX bytecode. Compared with DEX, ODEX only makes some additional analysis and optimization. So even if DEX does not pass optimization, it should be able to execute normally in theory.
After our exploration, we found this hidden entry in the dalvik source code of the system
/* * private static int openDexFile(byte[] fileContents) throws IOException * * Open a DEX file represented in a byte[], returning a pointer to our * internal data structure. * * The system will only perform "essential" optimizations on the given file. * */ static void Dalvik_dalvik_system_DexFile_openDexFile_bytearray(const u4* args, JValue* pResult) { ArrayObject* fileContentsObj = (ArrayObject*) args[0]; u4 length; u1* pBytes; RawDexFile* pRawDexFile; DexOrJar* pDexOrJar = NULL; if (fileContentsObj == NULL) { dvmThrowNullPointerException("fileContents == null"); RETURN_VOID(); } /* TODO: Avoid making a copy of the array. (note array *is* modified) */ length = fileContentsObj->length; pBytes = (u1*) malloc(length); if (pBytes == NULL) { dvmThrowRuntimeException("unable to allocate DEX memory"); RETURN_VOID(); } memcpy(pBytes, fileContentsObj->contents, length); if (dvmRawDexFileOpenArray(pBytes, length, &pRawDexFile) != 0) { ALOGV("Unable to open in-memory DEX file"); free(pBytes); dvmThrowRuntimeException("unable to open in-memory DEX file"); RETURN_VOID(); } ALOGV("Opening in-memory DEX"); pDexOrJar = (DexOrJar*) malloc(sizeof(DexOrJar)); pDexOrJar->isDex = true; pDexOrJar->pRawDexFile = pRawDexFile; pDexOrJar->pDexMemory = pBytes; pDexOrJar->fileName = strdup("<memory>"); // Needs to be free()able. addToDexFileTable(pDexOrJar); RETURN_PTR(pDexOrJar); }
This method can load the original DEX file without relying on the ODEX file. In fact, it does the following:
Accept a byte [] parameter, which is the bytecode of the original DEX file.
Call dvmRawDexFileOpenArray function to process byte [], and generate RawDexFile object
Generate a DexOrJar from the RawDexFile object and add it to the virtual machine through addToDexFileTable, so that it can be used normally in the future
Return the address of DexOrJar to the upper layer, and let the upper layer use it as a cookie to construct a legal DexFile object
In this way, after the upper layer obtains all the DexFile objects of the secondary DEX, it calls makeDexElements to insert them into ClassLoader, and the install operation is completed. In this way, we can avoid the ODEX optimization perfectly and let the APP run normally.
Search for entrance
It seems to be going well, but we have an unexpected situation.
From the name of the function Dalvik ﹣ Dalvik ﹣ system ﹣ dexfile ﹣ opendexfile ﹣ bytearray, we can see that this is a JNI method, and its Java prototype can be found from version 4.0 to 4.3:
/* * Open a DEX file based on a {@code byte[]}. The value returned * is a magic VM cookie. On failure, a RuntimeException is thrown. */ native private static int openDexFile(byte[] fileContents);
However, on version 4.4, the Java layer does not have a corresponding native method. So we can't call it directly at the upper level.
Of course, it's easy to think that dlsym can be used to directly search for the symbols of this function. But unfortunately, Dalvik? Dalvik? System? Dexfile? Opendexfile? Bytearray is static, so it has not been exported. When we actually parse libdvm.so, we did not find the symbol Dalvik ﹣ Dalvik ﹣ system ﹣ dexfile ﹣ opendexfile ﹣ bytearray.
However, because it is a JNI function, it is also registered in the virtual machine in the normal way. Therefore, we can find its corresponding function registry:
const DalvikNativeMethod dvm_dalvik_system_DexFile[] = { { "openDexFileNative", "(Ljava/lang/String;Ljava/lang/String;I)I", Dalvik_dalvik_system_DexFile_openDexFileNative }, { "openDexFile", "([B)I", Dalvik_dalvik_system_DexFile_openDexFile_bytearray }, { "closeDexFile", "(I)V", Dalvik_dalvik_system_DexFile_closeDexFile }, { "defineClassNative", "(Ljava/lang/String;Ljava/lang/ClassLoader;I)Ljava/lang/Class;", Dalvik_dalvik_system_DexFile_defineClassNative }, { "getClassNameList", "(I)[Ljava/lang/String;", Dalvik_dalvik_system_DexFile_getClassNameList }, { "isDexOptNeeded", "(Ljava/lang/String;)Z", Dalvik_dalvik_system_DexFile_isDexOptNeeded }, { NULL, NULL, NULL }, };
DVM? Dalvik? System? Dexfile is an array that needs to be registered dynamically by the virtual machine at runtime. Therefore, this symbol must be exported.
In this way, we can get this array through dlsym, and search for the corresponding Dalvik ﹣ Dalvik ﹣ system ﹣ dexfile ﹣ openDexFile ﹣ bytearray method of openDexFile according to the element string matching method.
The specific code is as follows:
const char *name = "openDexFile"; JNINativeMethod* func = (JNINativeMethod*) dlsym(handler, "dvm_dalvik_system_DexFile");; size_t len_name = strlen(name); while (func->name != nullptr) { if ((strncmp(name, func->name, len_name) == 0) && (strncmp("([B)I", func->signature, len_name) == 0)) { return reinterpret_cast<func_openDexFileBytes>(func->fnPtr); } func++; }
Smoothing steps
To summarize, there are the following steps to bypass the ODEX to load DEX directly:
Extract the bytecode of the original Secondary DEX file from APK
Get DVM? Dalvik? System? Dexfile array through dlsym
Query the array to get the Dalvik? Dalvik? System? Dexfile? Opendexfile? Bytearray function
Call this function, pass in the DEX bytecode obtained from APK one by one, complete the DEX loading, and get the legal DexFile object
Add the DexFile object to the pathList of the PathClassLoader of the APP
After completing the above steps, we can normally access the classes in the Secondary DEX
getDex problem
However, when we successfully injected the original DEX and executed it down, we immediately encountered a necessary crash on the 4.4 model:
JNI WARNING: JNI function NewGlobalRef called with exception pending in Ljava/lang/Class;.getDex:()Lcom/android/dex/Dex; (NewGlobalRef) Pending exception is: java.lang.IndexOutOfBoundsException: index=0, limit=0 at java.nio.Buffer.checkIndex(Buffer.java:156) at java.nio.DirectByteBuffer.get(DirectByteBuffer.java:157) at com.android.dex.Dex.create(Dex.java:129) at java.lang.Class.getDex(Native Method) at libcore.reflect.AnnotationAccess.getSignature(AnnotationAccess.java:447) at java.lang.Class.getGenericSuperclass(Class.java:824) at com.google.gson.reflect.TypeToken.getSuperclassTypeParameter(TypeToken.java:82) at com.google.gson.reflect.TypeToken.<init>(TypeToken.java:62) at com.google.gson.Gson$1.<init>(Gson.java:112) at com.google.gson.Gson.<clinit>(Gson.java:112) ... ...
As you can see, the Class.getGenericSuperclass method is used in Gson, and it finally calls Class.getDex, which is a native method. The corresponding implementation is as follows:
JNIEXPORT jobject JNICALL Java_java_lang_Class_getDex(JNIEnv* env, jclass javaClass) { Thread* self = dvmThreadSelf(); ClassObject* c = (ClassObject*) dvmDecodeIndirectRef(self, javaClass); DvmDex* dvm_dex = c->pDvmDex; if (dvm_dex == NULL) { return NULL; } // Already cached? if (dvm_dex->dex_object != NULL) { return dvm_dex->dex_object; } jobject byte_buffer = env->NewDirectByteBuffer(dvm_dex->memMap.addr, dvm_dex->memMap.length); if (byte_buffer == NULL) { return NULL; } jclass com_android_dex_Dex = env->FindClass("com/android/dex/Dex"); if (com_android_dex_Dex == NULL) { return NULL; } jmethodID com_android_dex_Dex_create = env->GetStaticMethodID(com_android_dex_Dex, "create", "(Ljava/nio/ByteBuffer;)Lcom/android/dex/Dex;"); if (com_android_dex_Dex_create == NULL) { return NULL; } jvalue args[1]; args[0].l = byte_buffer; jobject local_ref = env->CallStaticObjectMethodA(com_android_dex_Dex, com_android_dex_Dex_create, args); if (local_ref == NULL) { return NULL; } // Check another thread didn't cache an object, if we've won install the object. ScopedPthreadMutexLock lock(&dvm_dex->modLock); if (dvm_dex->dex_object == NULL) { dvm_dex->dex_object = env->NewGlobalRef(local_ref); } return dvm_dex->dex_object; }
In terms of stack and code, the point of crash is when com.android.dex.Dex.create is executed in JNI:
jobject local_ref = env->CallStaticObjectMethodA(com_android_dex_Dex, com_android_dex_Dex_create, args);
Because it is a JNI method, if there is no check after the exception occurs in this call, the previous exception will be detected and thrown when the subsequent call to Env - > newglobalref is executed.
The main reason why com.android.dex.Dex.create fails to execute is that there is a problem with the input parameter. The parameter here is a map memory obtained by DVM ﹣ DEX - > memmap. DVM? DEX is obtained from this Class. In the virtual machine code, each Class corresponds to the structure of ClassObject, including this field:
struct ClassObject : Object { ... ... /* DexFile from which we came; needed to resolve constant pool entries */ /* (will be NULL for VM-generated, e.g. arrays and primitive classes) */ DvmDex* pDvmDex; ... ...
Here, pDvmDex is assigned during class loading:
static void Dalvik_dalvik_system_DexFile_defineClassNative(const u4* args, JValue* pResult) { ... ... if (pDexOrJar->isDex) pDvmDex = dvmGetRawDexFileDex(pDexOrJar->pRawDexFile); else pDvmDex = dvmGetJarFileDex(pDexOrJar->pJarFile); ... ...
pDvmDex is obtained from the dvmGetRawDexFileDex method, and the parameter pDexOrJar - > prawdexfile is created in opendexfile ﹐ bytearray, and pDexOrJar is the cookie returned to the upper layer.
According to dvmGetRawDexFileDex:
INLINE DvmDex* dvmGetRawDexFileDex(RawDexFile* pRawDexFile) { return pRawDexFile->pDvmDex; }
It can be concluded that DVM ﹣ DEX - > memMap corresponds to the pdexorjar - > prawdexfile - > pdvmdex - > memMap obtained in opendexfile ﹣ bytearray. When we loaded the DEX byte array, did we miss the assignment of memMap?
By analyzing the code, we find that this is true. The field memMap is assigned only in the case of ODEX:
/* * Given an open optimized DEX file, map it into read-only shared memory and * parse the contents. * * Returns nonzero on error. */ int dvmDexFileOpenFromFd(int fd, DvmDex** ppDvmDex) { ... ... // Construction of memMap if (sysMapFileInShmemWritableReadOnly(fd, &memMap) != 0) { ALOGE("Unable to map file"); goto bail; } ... ... // Assignment memMap /* tuck this into the DexFile so it gets released later */ sysCopyMap(&pDvmDex->memMap, &memMap); ... ... }
This method is not used when loading only the DEX byte array, so there is no way to assign a value to memMap. It seems that Android official did not support opendexfile ﹣ bytearray well from the beginning, and there is no place to use it in the system code, so this problem will be exposed when we force to use this method.
Although this is an official pit, since we need to use it, we have to find a way to fill it.
Once again, we analyze the Java? Java? Lang? Class? Getdex method, and notice this:
if (dvm_dex->dex_object != NULL) { return dvm_dex->dex_object; }
If DVM > DEX > DEX object is not empty, it will be returned directly, and will not be executed to the place where memMap is taken, so no exception will be thrown. In this way, the solution is very clear. After loading the DEX array, we immediately generate a DEX object object and inject it into the pDvmDex.
The detailed code is as follows:
jclass clazz = env->FindClass("com/android/dex/Dex"); jobject dex_object = env->NewGlobalRef( env->NewObject(clazz), env->GetMethodID(clazz, "<init>", "([B)V"), bytes)); dexOrJar->pRawDexFile->pDvmDex->dex_object = dex_object;
After setting in this way, the getDex exception does not appear again.
Summary
So far, the direct DEX loading scheme without waiting for ODEX optimization has been fully opened, and the first start-up time of APP can be greatly reduced.
We still have a short way to go to the ultimate complete solution, however, it is this short way that is the most difficult and severe. The bigger challenge is still to come. We will break it down in detail in the next article, and at the same time, we will show the benefits brought by the final plan in detail. You can also think about what other problems are not considered here.
Recommended reading: 2017-2020 byte beat Android interview real question analysis (download 10.82 million times in total, continuous update)
Author: byte skipping technology team
Links: https://juejin.im/post/5e5b9466518825494b3cd5aa
Source: Nuggets