In the process of using map, two problems are often encountered: read-write conflict and traversal disorder. Why is this so? How is the bottom achieved? With these two problems, I have a simple understanding of the map add-delete check and traversal implementation.
structure
hmap
type hmap struct { // Note: the format of the hmap is also encoded in cmd/compile/internal/gc/reflect.go. // Make sure this stays in sync with the compiler's definition. count int // Length of valid data# live cells = size of map. Must be first (used by Len () builtin) flags uint8 // Used to record the status of hashmap B uint8 // 2 ^ B = the number of buckets log_2 of # of buckets (can hold up to loadFactor * 2^B items) noverflow uint16 // approximate number of overflow buckets; see incrnoverflow for details hash0 uint32 // Random hash seeds buckets unsafe.Pointer // Bukets array of 2^B Buckets. may be nil if count==0. oldbuckets unsafe.Pointer // Old buctedts data, used when map s grow nevacuate uintptr // progress counter for evacuation (buckets less than this have been evacuated) extra *mapextra // Additional bmap array optional fields }
mapextra
type mapextra struct { // If both key and value do not contain pointers and are inline, then we mark bucket // type as containing no pointers. This avoids scanning such maps. // However, bmap.overflow is a pointer. In order to keep overflow buckets // alive, we store pointers to all overflow buckets in hmap.extra.overflow and hmap.extra.oldoverflow. // overflow and oldoverflow are only used if key and value do not contain pointers. // overflow contains overflow buckets for hmap.buckets. // oldoverflow contains overflow buckets for hmap.oldbuckets. // The indirection allows to store a pointer to the slice in hiter. overflow *[]*bmap oldoverflow *[]*bmap // nextOverflow holds a pointer to a free overflow bucket. nextOverflow *bmap }
bmap
type bmap struct { // tophash generally contains the top byte of the hash value // for each key in this bucket. If tophash[0] < minTopHash, // tophash[0] is a bucket evacuation state instead. tophash [bucketCnt]uint8 // Followed by bucketCnt keys and then bucketCnt values. // NOTE: packing all the keys together and then all the values together makes the // code a bit more complicated than alternating key/value/key/value/... but it allows // us to eliminate padding which would be needed for, e.g., map[int64]int8. // Followed by an overflow pointer. }
stringStruct
type stringStruct struct { str unsafe.Pointer len int }
hiter
The structure used in map traversal, startBucket+offset sets the address to start traversal, which ensures the disorder of map traversal.
type hiter struct { // key's pointer key unsafe.Pointer // Must be in first position. Write nil to indicate iteration end (see cmd/internal/gc/range.go). // Current value Guidelines value unsafe.Pointer // Must be in second position (see cmd/internal/gc/range.go). t *maptype // A pointer to map h *hmap // A pointer to buckets buckets unsafe.Pointer // bucket ptr at hash_iter initialization time // A pointer to the current traversal bucket bptr *bmap // current bucket // Point to map.extra.overflow overflow *[]*bmap // keeps overflow buckets of hmap.buckets alive // Point to map.extra.oldoverflow oldoverflow *[]*bmap // keeps overflow buckets of hmap.oldbuckets alive // Index of bucket to start traversal startBucket uintptr // bucket iteration started at // Start traversing the offset on the bucket offset uint8 // intra-bucket offset to start from during iteration (should be big enough to hold bucketCnt-1) wrapped bool // already wrapped around from end of bucket array to beginning B uint8 i uint8 bucket uintptr checkBucket uintptr }
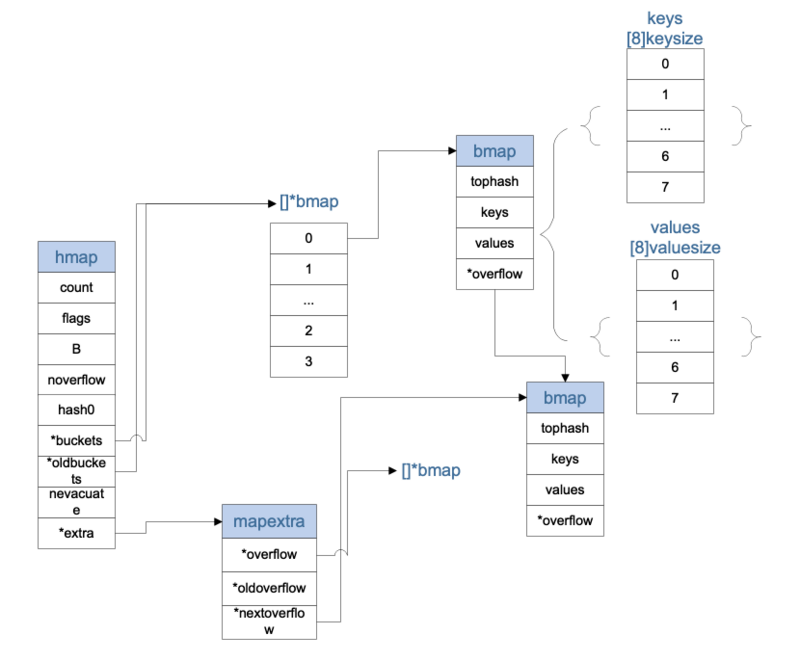
The keys and values and * overflow variables here are not reflected in the structure, but they are always reserved for them in the source code process, so the sketch here shows that keys and values are actually Eight-Length arrays.
demo
Let's simply write a demo and go tool to analyze the underlying functions.
func main() { m := make(map[interface{}]interface{}, 16) m["111"] = 1 m["222"] = 2 m["444"] = 4 _ = m["444"] _, _ = m["444"] delete(m, "444") for range m { } }
▶ go tool objdump -s "main.main" main | grep CALL main.go:4 0x455c74 e8f761fbff CALL runtime.makemap(SB) main.go:5 0x455ce1 e8da6dfbff CALL runtime.mapassign(SB) main.go:6 0x455d7b e8406dfbff CALL runtime.mapassign(SB) main.go:7 0x455e15 e8a66cfbff CALL runtime.mapassign(SB) main.go:8 0x455e88 e89363fbff CALL runtime.mapaccess1(SB) main.go:9 0x455ec4 e84766fbff CALL runtime.mapaccess2(SB) main.go:10 0x455f00 e85b72fbff CALL runtime.mapdelete(SB) main.go:12 0x455f28 e804a7ffff CALL 0x450631 main.go:12 0x455f53 e8b875fbff CALL runtime.mapiterinit(SB) main.go:12 0x455f75 e88677fbff CALL runtime.mapiternext(SB) main.go:7 0x455f8f e81c9cffff CALL runtime.gcWriteBarrier(SB) main.go:6 0x455f9c e80f9cffff CALL runtime.gcWriteBarrier(SB) main.go:5 0x455fa9 e8029cffff CALL runtime.gcWriteBarrier(SB) main.go:3 0x455fb3 e8f87dffff CALL runtime.morestack_noctxt(SB)
Initialization
makemap
makemap creates an hmap structure and gives the variable some initial attributes
func makemap(t *maptype, hint int, h *hmap) *hmap { // First, determine whether the map size is appropriate if hint < 0 || hint > int(maxSliceCap(t.bucket.size)) { hint = 0 } // initialize Hmap // Initialize the hmap structure if h == nil { h = new(hmap) } // Generate a random hash seed h.hash0 = fastrand() // find size parameter which will hold the requested # of elements // Determine the size of B according to hint, which is the preset length of map, so that the loading coefficient of map can be within the normal range, and expand that block. B := uint8(0) for overLoadFactor(hint, B) { B++ } h.B = B // allocate initial hash table // if B == 0, the buckets field is allocated lazily later (in mapassign) // If hint is large zeroing this memory could take a while. // If B==0, then the assignment of inert allocation, if B! = 0, then allocate the corresponding number of buckets if h.B != 0 { var nextOverflow *bmap h.buckets, nextOverflow = makeBucketArray(t, h.B, nil) if nextOverflow != nil { h.extra = new(mapextra) h.extra.nextOverflow = nextOverflow } } return h }
makeBucketArray
makeBucketArray initializes the buckets required by the map, allocating at least 2^b buckets
func makeBucketArray(t *maptype, b uint8, dirtyalloc unsafe.Pointer) (buckets unsafe.Pointer, nextOverflow *bmap) { base := bucketShift(b) nbuckets := base // If b, that is, if the map is large, then multiple allocation point arrays are used for next Overflow if b >= 4 { // Calculate the number of buckets that should be allocated more nbuckets += bucketShift(b - 4) sz := t.bucket.size * nbuckets up := roundupsize(sz) if up != sz { nbuckets = up / t.bucket.size } } // If it is not dirtyalloc, when the map space is newly allocated, dirtyalloc is nil if dirtyalloc == nil { // Application buckets array buckets = newarray(t.bucket, int(nbuckets)) } else { // dirtyalloc was previously generated by // the above newarray(t.bucket, int(nbuckets)) // but may not be empty. buckets = dirtyalloc size := t.bucket.size * nbuckets if t.bucket.kind&kindNoPointers == 0 { memclrHasPointers(buckets, size) } else { memclrNoHeapPointers(buckets, size) } } // To determine whether more buckets have been applied for, the more buckets have been placed in the next Overflow for backup. if base != nbuckets { nextOverflow = (*bmap)(add(buckets, base*uintptr(t.bucketsize))) last := (*bmap)(add(buckets, (nbuckets-1)*uintptr(t.bucketsize))) last.setoverflow(t, (*bmap)(buckets)) } return buckets, nextOverflow }
This is the end of the initialization process, which is relatively simple, that is, according to the size of the initialization, determine the number of buckets, and allocate memory, etc.
Search (mapaccess)
It can be found in the go tool analysis above.
- _= m["444"] corresponds to mapaccess1
- = m["444"] corresponds to mapaccess2
The logic of the two functions is roughly the same. Let's take mapaccess1 as an example.
mapaccess
func mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer { // If h is not instantiated or has no value, return zero if h == nil || h.count == 0 { return unsafe.Pointer(&zeroVal[0]) } // Judging whether the current map is in the process of writing, read-write conflict if h.flags&hashWriting != 0 { throw("concurrent map read and map write") } // The hash value of key is calculated according to hash random seed hash 0 of initial production. alg := t.key.alg hash := alg.hash(key, uintptr(h.hash0)) m := bucketMask(h.B) // According to the hash value of key, the position of the corresponding bucket is calculated, which is illustrated later in the calculation process. b := (*bmap)(add(h.buckets, (hash&m)*uintptr(t.bucketsize))) // In the process of expansion, old buckets are not empty, so at this time, it is necessary to judge whether the target bucket has been migrated or not. if c := h.oldbuckets; c != nil { if !h.sameSizeGrow() { // There used to be half as many buckets; mask down one more power of two. m >>= 1 } // If the target bucket has not been migrated in the expansion, go to oldbuckets to find the target bucket oldb := (*bmap)(add(c, (hash&m)*uintptr(t.bucketsize))) if !evacuated(oldb) { b = oldb } } // Calculate tophash of key for comparison top := tophash(hash) for ; b != nil; b = b.overflow(t) { for i := uintptr(0); i < bucketCnt; i++ { // If the tophash is inconsistent, the key must be different. Keep looking for the next one. if b.tophash[i] != top { continue } // tophash has always needed to determine whether key s are consistent k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize)) if t.indirectkey { k = *((*unsafe.Pointer)(k)) } // If the key is the same, the corresponding value is returned. if alg.equal(key, k) { v := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize)) if t.indirectvalue { v = *((*unsafe.Pointer)(v)) } return v } } } return unsafe.Pointer(&zeroVal[0]) }
overflow
This function is to find the address of the overflow of bmap. It can be seen from the structure diagram that the memory unit occupied by the last pointer of the BMAP structure is the address of the next BMAP pointed to by the overflow.
func (b *bmap) overflow(t *maptype) *bmap { return *(**bmap)(add(unsafe.Pointer(b), uintptr(t.bucketsize)-sys.PtrSize)) }
The above logic is relatively simple, but there are several problems to be solved here.
- How bucket (bmap structure) is determined
- How does tophash determine
- Why are the addresses of key and value calculated by migration
Let's start with the enlargement of buckets and bmap

-
How bucket (bmap structure) is determined
bucket := hash & bucketMask(h.B) b := (*bmap)(unsafe.Pointer(uintptr(h.buckets) + bucket*uintptr(t.bucketsize)))Adding B=5 indicates that the number of buckets is 2 ^ 5 = 32, then the last five bits of hash are taken to calculate the index of the target bucket. The index is calculated as 6 in the figure. Therefore, by offset the address of six buckets on the buckets, the corresponding bucket can be found.
-
How does tophash determine
func tophash(hash uintptr) uint8 { top := uint8(hash >> (sys.PtrSize*8 - 8)) if top < minTopHash { top += minTopHash } return top }The length of each bucket's tophash array is 8, so the first eight bits of the hash value are directly computed here as tophash.
-
Why are the addresses of key and value calculated by migration
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize)) val = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize))According to the initial data structure analysis and the bmap diagram above, it can be seen that all keys in bmap are put together, all values are put together, and data offset is the size occupied by tophash[8]. Therefore, the address of key is the offset of b address + data Offset + the size of the corresponding index i*key, which is the same as the value arranged behind the key.
insert
mapassign
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer { if h == nil { panic(plainError("assignment to entry in nil map")) } // map concurrent read and write processing, throw exception directly if h.flags&hashWriting != 0 { throw("concurrent map writes") } // According to hash seed hash 0 of map, hash value of key is calculated. alg := t.key.alg hash := alg.hash(key, uintptr(h.hash0)) // Set hashWriting after calling alg.hash, since alg.hash may panic, // in which case we have not actually done a write. h.flags |= hashWriting // If map does not have buckets, make(map) lazily allocates buckets when map length is not specified if h.buckets == nil { h.buckets = newobject(t.bucket) // newarray(t.bucket, 1) } again: // According to the calculated hash value, the index of the bucket that should be inserted in the buckets is determined. bucket := hash & bucketMask(h.B) // growWork is to complete the expansion operation to determine whether or not the expansion map is being expanded. if h.growing() { growWork(t, h, bucket) } // Confirm the address of the bucket b := (*bmap)(unsafe.Pointer(uintptr(h.buckets) + bucket*uintptr(t.bucketsize))) // The first eight bits of hash binary are calculated and used as tophash. top := tophash(hash) var inserti *uint8 var insertk unsafe.Pointer var val unsafe.Pointer for { for i := uintptr(0); i < bucketCnt; i++ { // Loop through the tophash array. If the index position of the array is empty, take it over and use it first. if b.tophash[i] != top { if b.tophash[i] == empty && inserti == nil { inserti = &b.tophash[i] insertk = add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize)) val = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize)) } continue } // Find the tophash consistency of the current key in the tophash array k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize)) // If key is a pointer, get the data corresponding to the pointer if t.indirectkey { k = *((*unsafe.Pointer)(k)) } // Determine whether the two keys are the same, and continue to look for different keys if !alg.equal(key, k) { continue } // already have a mapping for key. Update it. if t.needkeyupdate { typedmemmove(t.key, k, key) } // Finding the location where value should be stored according to i can be understood in combination with the data structure of bmap in the structure diagram val = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize)) goto done } // If no spare location or the same key is found in buckets, look in overflow ovf := b.overflow(t) if ovf == nil { break } b = ovf } // Did not find mapping for key. Allocate new cell & add entry. // If we hit the max load factor or we have too many overflow buckets, // and we're not already in the middle of growing, start growing. // Judging whether expansion is needed if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) { hashGrow(t, h) goto again // Growing the table invalidates everything, so try again } // inerti==nil, which means that the buckets of the map are full, you need to add an overflow to mount the map and the corresponding bmap if inserti == nil { // all current buckets are full, allocate a new one. newb := h.newoverflow(t, b) inserti = &newb.tophash[0] insertk = add(unsafe.Pointer(newb), dataOffset) val = add(insertk, bucketCnt*uintptr(t.keysize)) } // store new key/value at insert position // Store key value to the specified location if t.indirectkey { kmem := newobject(t.key) *(*unsafe.Pointer)(insertk) = kmem insertk = kmem } if t.indirectvalue { vmem := newobject(t.elem) *(*unsafe.Pointer)(val) = vmem } typedmemmove(t.key, insertk, key) *inserti = top h.count++ done: if h.flags&hashWriting == 0 { throw("concurrent map writes") } // flags to modify map h.flags &^= hashWriting if t.indirectvalue { val = *((*unsafe.Pointer)(val)) } return val }
setoverflow
func (h *hmap) newoverflow(t *maptype, b *bmap) *bmap { var ovf *bmap // Find out if there is any residual overflow pre-allocated. if h.extra != nil && h.extra.nextOverflow != nil { // We have preallocated overflow buckets available. // See makeBucketArray for more details. // Pre-allocated, directly using pre-allocated, and then update the next one with overflow => nextOverflow ovf = h.extra.nextOverflow if ovf.overflow(t) == nil { // We're not at the end of the preallocated overflow buckets. Bump the pointer. h.extra.nextOverflow = (*bmap)(add(unsafe.Pointer(ovf), uintptr(t.bucketsize))) } else { // This is the last preallocated overflow bucket. // Reset the overflow pointer on this bucket, // which was set to a non-nil sentinel value. ovf.setoverflow(t, nil) h.extra.nextOverflow = nil } } else { ovf = (*bmap)(newobject(t.bucket)) } // Increase noverflow h.incrnoverflow() if t.bucket.kind&kindNoPointers != 0 { h.createOverflow() *h.extra.overflow = append(*h.extra.overflow, ovf) } // Mount the current overflow behind the overflow list of bmap b.setoverflow(t, ovf) return ovf }
Overflow refers to a BMAP structure, and the last address of the BMAP structure, which stores the address of overflow, can connect all overflows of BMAP through bmap.overflow is the same logic as hmap.extra.nextOverflow.
Expansion
As you can see from the mapassign function, there are two kinds of expansion.
overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)
- Over the set load value
- There are too many overflow s
Let's look at these two functions first.
overLoadFactor
func overLoadFactor(count int, B uint8) bool { // loadFactorNum = 13; loadFactorDen = 2 return count > bucketCnt && uintptr(count) > loadFactorNum*(bucketShift(B)/loadFactorDen) }
Uintptr (count) > loadFactorNum* (bucketShift (B) / loadFactorDen) can be simplified to count / 2 ^ B > 6.5, which represents the load factor of loadFactor.
tooManyOverflowBuckets
func tooManyOverflowBuckets(noverflow uint16, B uint8) bool { // If the threshold is too low, we do extraneous work. // If the threshold is too high, maps that grow and shrink can hold on to lots of unused memory. // "too many" means (approximately) as many overflow buckets as regular buckets. // See incrnoverflow for more details. if B > 15 { B = 15 } // The compiler doesn't see here that B < 16; mask B to generate shorter shift code. return noverflow >= uint16(1)<<(B&15) }
Judging whether there are too many overflows by judging the number of noverflow s
Let's understand the reasons for the expansion of these two situations.
- Over the set load value
In the process of key searching, bucket is determined according to the last B bit and tophash is determined by 8 bits. But in the process of searching tophash, the whole bucket needs to be traversed. Therefore, the optimal situation is that each bucket stores only one key, which achieves the O(1) searching efficiency of hash, but the space is wasted greatly; if all keys are stored in a bucket, When the load factor is too large, it needs to increase the bucket to improve the search efficiency, that is, incremental capacity expansion.
- There are too many overflow s
When the bucket's empty space is filled up, the loading factor reaches 8. Why can there be a judgment of tooManyOverflow Buckets? map not only has the operation of adding but also deleting. When a bucket's empty space is filled up, it starts filling in overflow. At this time, it deletes the data in bucket. In fact, the whole process may not trigger the overflow expander. System (because there are more buckets), but to find overflow data, first of all, we need to traverse the bucket data, which is useless, the search efficiency is low, at this time we need not increase the number of buckets expansion, that is, equal capacity expansion.
The expansion work started with hashGroup, but the real migration work is evacuation, which is called d by growWork. Whether the map is expanding or not is judged at each time of the map assignment and map delete, and if so, the current bucket is migrated. Therefore, the expansion of map is not a one-step process, but a step-by-step process.
hashGrow
func hashGrow(t *maptype, h *hmap) { // If we've hit the load factor, get bigger. // Otherwise, there are too many overflow buckets, // so keep the same number of buckets and "grow" laterally. // Judging whether the capacity expansion is equal or incremental bigger := uint8(1) if !overLoadFactor(h.count+1, h.B) { bigger = 0 h.flags |= sameSizeGrow } // Reallocate new buckets and overflow for map based on new B (h.B+bigger for new h.B) oldbuckets := h.buckets newbuckets, nextOverflow := makeBucketArray(t, h.B+bigger, nil) flags := h.flags &^ (iterator | oldIterator) if h.flags&iterator != 0 { flags |= oldIterator } // commit the grow (atomic wrt gc) // Update hmap-related properties h.B += bigger h.flags = flags h.oldbuckets = oldbuckets h.buckets = newbuckets h.nevacuate = 0 h.noverflow = 0 // Update the old map's extra and nextOverflow to the new map structure if h.extra != nil && h.extra.overflow != nil { // Promote current overflow buckets to the old generation. if h.extra.oldoverflow != nil { throw("oldoverflow is not nil") } h.extra.oldoverflow = h.extra.overflow h.extra.overflow = nil } if nextOverflow != nil { if h.extra == nil { h.extra = new(mapextra) } h.extra.nextOverflow = nextOverflow } // the actual copying of the hash table data is done incrementally // by growWork() and evacuate(). }
hashGrow is ready for the first dish. Next, it is handed over to growWork and evacuate functions.
growWork
func growWork(t *maptype, h *hmap, bucket uintptr) { // make sure we evacuate the oldbucket corresponding // to the bucket we're about to use evacuate(t, h, bucket&h.oldbucketmask()) // evacuate one more oldbucket to make progress on growing if h.growing() { evacuate(t, h, h.nevacuate) } }
evacuate
In this paper, a bucket in hmap is moved to a new buckets, and the corresponding position between the old bucket key and the new buckets is also referred to the search process of map.
How to judge whether the bucket has been moved or not is mainly based on the evacuated function.
func evacuated(b *bmap) bool { h := b.tophash[0] return h > empty && h < minTopHash }
Look at the source code and find that the principle is very simple, that is, to judge the value of tophash[0], then it must be set after the removal of this value, we through the evacuation function l hey to explore it.
func evacuate(t *maptype, h *hmap, oldbucket uintptr) { b := (*bmap)(add(h.oldbuckets, oldbucket*uintptr(t.bucketsize))) newbit := h.noldbuckets() // Judging whether or not to move if !evacuated(b) { // TODO: reuse overflow buckets instead of using new ones, if there // is no iterator using the old buckets. (If !oldIterator.) // xy contains the x and y (low and high) evacuation destinations. // Let's assign the original index of bucket to x. var xy [2]evacDst x := &xy[0] x.b = (*bmap)(add(h.buckets, oldbucket*uintptr(t.bucketsize))) x.k = add(unsafe.Pointer(x.b), dataOffset) x.v = add(x.k, bucketCnt*uintptr(t.keysize)) // If it is incremental expansion, the expanded bucket will change. If B=5 is taken as an example, B+1= 6 is used to calculate the index of the bucket in the penultimate 6 bits, but the penultimate 6 bits can only be 0 or 1, that is to say, the index can only be X or Y (x+newbit). Here, y is calculated for backup. if !h.sameSizeGrow() { // Only calculate y pointers if we're growing bigger. // Otherwise GC can see bad pointers. y := &xy[1] y.b = (*bmap)(add(h.buckets, (oldbucket+newbit)*uintptr(t.bucketsize))) y.k = add(unsafe.Pointer(y.b), dataOffset) y.v = add(y.k, bucketCnt*uintptr(t.keysize)) } // Moving for ; b != nil; b = b.overflow(t) { k := add(unsafe.Pointer(b), dataOffset) v := add(k, bucketCnt*uintptr(t.keysize)) for i := 0; i < bucketCnt; i, k, v = i+1, add(k, uintptr(t.keysize)), add(v, uintptr(t.valuesize)) { top := b.tophash[i] // Skipping empty if top == empty { b.tophash[i] = evacuatedEmpty continue } if top < minTopHash { throw("bad map state") } k2 := k if t.indirectkey { k2 = *((*unsafe.Pointer)(k2)) } var useY uint8 if !h.sameSizeGrow() { // Compute hash to make our evacuation decision (whether we need // to send this key/value to bucket x or bucket y). // Judging whether hash calculates whether X or y is used and whether x is used for equal expansion hash := t.key.alg.hash(k2, uintptr(h.hash0)) if h.flags&iterator != 0 && !t.reflexivekey && !t.key.alg.equal(k2, k2) { // If key != key (NaNs), then the hash could be (and probably // will be) entirely different from the old hash. Moreover, // it isn't reproducible. Reproducibility is required in the // presence of iterators, as our evacuation decision must // match whatever decision the iterator made. // Fortunately, we have the freedom to send these keys either // way. Also, tophash is meaningless for these kinds of keys. // We let the low bit of tophash drive the evacuation decision. // We recompute a new random tophash for the next level so // these keys will get evenly distributed across all buckets // after multiple grows. useY = top & 1 top = tophash(hash) } else { if hash&newbit != 0 { useY = 1 } } } if evacuatedX+1 != evacuatedY { throw("bad evacuatedN") } b.tophash[i] = evacuatedX + useY // evacuatedX + 1 == evacuatedY dst := &xy[useY] // evacuation destination // If the target bucket is full, create a new overflow, mount it on the bucket, and use the overflow if dst.i == bucketCnt { dst.b = h.newoverflow(t, dst.b) dst.i = 0 dst.k = add(unsafe.Pointer(dst.b), dataOffset) dst.v = add(dst.k, bucketCnt*uintptr(t.keysize)) } // Copy key value to set the value of the corresponding index of the tophash array dst.b.tophash[dst.i&(bucketCnt-1)] = top // mask dst.i as an optimization, to avoid a bounds check if t.indirectkey { *(*unsafe.Pointer)(dst.k) = k2 // copy pointer } else { typedmemmove(t.key, dst.k, k) // copy value } if t.indirectvalue { *(*unsafe.Pointer)(dst.v) = *(*unsafe.Pointer)(v) } else { typedmemmove(t.elem, dst.v, v) } dst.i++ // These updates might push these pointers past the end of the // key or value arrays. That's ok, as we have the overflow pointer // at the end of the bucket to protect against pointing past the // end of the bucket. dst.k = add(dst.k, uintptr(t.keysize)) dst.v = add(dst.v, uintptr(t.valuesize)) } } // Unlink the overflow buckets & clear key/value to help GC. if h.flags&oldIterator == 0 && t.bucket.kind&kindNoPointers == 0 { b := add(h.oldbuckets, oldbucket*uintptr(t.bucketsize)) // Preserve b.tophash because the evacuation // state is maintained there. ptr := add(b, dataOffset) n := uintptr(t.bucketsize) - dataOffset memclrHasPointers(ptr, n) } } if oldbucket == h.nevacuate { advanceEvacuationMark(h, t, newbit) } }
Expansion is gradual, one bucket at a time.
Let's take the original B=5 as an example. Now, after incremental expansion, B=6, but the penultimate sixth bit of hash can only be 0 or 1. That is to say, if the original calculated bucket index is 6, that is, 00110, then the new bucket index can only be 100110 (6 + 2 ^ 5) or 000110 (6), x corresponds to 6, y corresponds to (6 + 2 ^ 5); if the volume expansion is equal, then the index is willing. It must be unchanged, then you don't need y.
After you find the corresponding new bucket, store it in sequence.
delete
mapdelete
The deletion logic is relatively simple, according to the key search, find and empty the key and value and tophash
func mapdelete(t *maptype, h *hmap, key unsafe.Pointer) { if h == nil || h.count == 0 { return } // Read-write conflict if h.flags&hashWriting != 0 { throw("concurrent map writes") } // Here's a big calculation hash, look up the bucket, look up the key inside the bucket, and the logic is the same, so don't repeat it. alg := t.key.alg hash := alg.hash(key, uintptr(h.hash0)) // Set hashWriting after calling alg.hash, since alg.hash may panic, // in which case we have not actually done a write (delete). h.flags |= hashWriting bucket := hash & bucketMask(h.B) if h.growing() { growWork(t, h, bucket) } b := (*bmap)(add(h.buckets, bucket*uintptr(t.bucketsize))) top := tophash(hash) search: for ; b != nil; b = b.overflow(t) { for i := uintptr(0); i < bucketCnt; i++ { if b.tophash[i] != top { continue } k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize)) k2 := k if t.indirectkey { k2 = *((*unsafe.Pointer)(k2)) } if !alg.equal(key, k2) { continue } // Only clear key if there are pointers in it. // Here we find the key. If the key is a pointer, set it to nil, otherwise we empty the data corresponding to the key in memory. if t.indirectkey { *(*unsafe.Pointer)(k) = nil } else if t.key.kind&kindNoPointers == 0 { memclrHasPointers(k, t.key.size) } // Similarly delete v v := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize)) if t.indirectvalue { *(*unsafe.Pointer)(v) = nil } else if t.elem.kind&kindNoPointers == 0 { memclrHasPointers(v, t.elem.size) } else { memclrNoHeapPointers(v, t.elem.size) } // Set tophash to 0 and update count attribute b.tophash[i] = empty h.count-- break search } } if h.flags&hashWriting == 0 { throw("concurrent map writes") } h.flags &^= hashWriting }
ergodic
In general, traversal values need to traverse every bucket in the buckets array and the overflow list hanging under the bucket, but there is an expansion of map, which will make traversal more difficult. Let's see how go is implemented.
Based on the analysis of go tool, we can take a brief look at the process information during traversal

mapiterinit
func mapiterinit(t *maptype, h *hmap, it *hiter) { if h == nil || h.count == 0 { return } if unsafe.Sizeof(hiter{})/sys.PtrSize != 12 { throw("hash_iter size incorrect") // see cmd/compile/internal/gc/reflect.go } // Setting the properties of iter it.t = t it.h = h // grab snapshot of bucket state it.B = h.B it.buckets = h.buckets if t.bucket.kind&kindNoPointers != 0 { // Allocate the current slice and remember pointers to both current and old. // This preserves all relevant overflow buckets alive even if // the table grows and/or overflow buckets are added to the table // while we are iterating. h.createOverflow() it.overflow = h.extra.overflow it.oldoverflow = h.extra.oldoverflow } // decide where to start // Random generation of a seed and calculation of startBucket and offset based on the random seed ensures the randomness of traversal. r := uintptr(fastrand()) if h.B > 31-bucketCntBits { r += uintptr(fastrand()) << 31 } it.startBucket = r & bucketMask(h.B) it.offset = uint8(r >> h.B & (bucketCnt - 1)) // iterator state it.bucket = it.startBucket // Remember we have an iterator. // Can run concurrently with another mapiterinit(). if old := h.flags; old&(iterator|oldIterator) != iterator|oldIterator { atomic.Or8(&h.flags, iterator|oldIterator) } // Start traversing mapiternext(it) }
mapiternext
func mapiternext(it *hiter) { h := it.h if raceenabled { callerpc := getcallerpc() racereadpc(unsafe.Pointer(h), callerpc, funcPC(mapiternext)) } if h.flags&hashWriting != 0 { throw("concurrent map iteration and map write") } t := it.t bucket := it.bucket b := it.bptr i := it.i checkBucket := it.checkBucket alg := t.key.alg next: // b==nil indicates that the bucket.overflow list has been traversed, traversing the next bucket if b == nil { // Traversing through the initial bucket, and the startBucket has been traversed, indicates that the entire map traversal is complete. if bucket == it.startBucket && it.wrapped { // end of iteration it.key = nil it.value = nil return } // If the hmap is expanding, determine whether the currently traversing bucket has been moved out, moved out, and used the new bucket, or used the old bucket. if h.growing() && it.B == h.B { // Iterator was started in the middle of a grow, and the grow isn't done yet. // If the bucket we're looking at hasn't been filled in yet (i.e. the old // bucket hasn't been evacuated) then we need to iterate through the old // bucket and only return the ones that will be migrated to this bucket. oldbucket := bucket & it.h.oldbucketmask() b = (*bmap)(add(h.oldbuckets, oldbucket*uintptr(t.bucketsize))) if !evacuated(b) { checkBucket = bucket } else { b = (*bmap)(add(it.buckets, bucket*uintptr(t.bucketsize))) checkBucket = noCheck } } else { b = (*bmap)(add(it.buckets, bucket*uintptr(t.bucketsize))) checkBucket = noCheck } bucket++ // Traverse to the end of the array, continue from the beginning of the array if bucket == bucketShift(it.B) { bucket = 0 it.wrapped = true } i = 0 } // Traverse the data in the current bucket or bucket.overflow for ; i < bucketCnt; i++ { // Determine the tophash index of the traversing bucket by offset and i offi := (i + it.offset) & (bucketCnt - 1) if b.tophash[offi] == empty || b.tophash[offi] == evacuatedEmpty { continue } // Determine the address of key and value based on offset i k := add(unsafe.Pointer(b), dataOffset+uintptr(offi)*uintptr(t.keysize)) if t.indirectkey { k = *((*unsafe.Pointer)(k)) } v := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+uintptr(offi)*uintptr(t.valuesize)) if checkBucket != noCheck && !h.sameSizeGrow() { // It shows that further judgment is needed in incremental capacity expansion. // Special case: iterator was started during a grow to a larger size // and the grow is not done yet. We're working on a bucket whose // oldbucket has not been evacuated yet. Or at least, it wasn't // evacuated when we started the bucket. So we're iterating // through the oldbucket, skipping any keys that will go // to the other new bucket (each oldbucket expands to two // buckets during a grow). if t.reflexivekey || alg.equal(k, k) { // Data has not yet been migrated from oldbucket to the new bucket. Judging whether the key after recalculation is consistent with the index of oldbucket, inconsistencies are skipped // If the item in the oldbucket is not destined for // the current new bucket in the iteration, skip it. hash := alg.hash(k, uintptr(h.hash0)) if hash&bucketMask(it.B) != checkBucket { continue } } else { // Hash isn't repeatable if k != k (NaNs). We need a // repeatable and randomish choice of which direction // to send NaNs during evacuation. We'll use the low // bit of tophash to decide which way NaNs go. // NOTE: this case is why we need two evacuate tophash // values, evacuatedX and evacuatedY, that differ in // their low bit. if checkBucket>>(it.B-1) != uintptr(b.tophash[offi]&1) { continue } } } if (b.tophash[offi] != evacuatedX && b.tophash[offi] != evacuatedY) || !(t.reflexivekey || alg.equal(k, k)) { // The data here is not expanding data and can be used directly. // This is the golden data, we can return it. // OR // key!=key, so the entry can't be deleted or updated, so we can just return it. // That's lucky for us because when key!=key we can't look it up successfully. it.key = k if t.indirectvalue { v = *((*unsafe.Pointer)(v)) } it.value = v } else { // The hash table has grown since the iterator was started. // The golden data for this key is now somewhere else. // Check the current hash table for the data. // This code handles the case where the key // has been deleted, updated, or deleted and reinserted. // NOTE: we need to regrab the key as it has potentially been // updated to an equal() but not identical key (e.g. +0.0 vs -0.0). // After the traversal begins, the map is expanded and the data may be incorrect. Look it up again and get it. rk, rv := mapaccessK(t, h, k) if rk == nil { continue // key has been deleted } it.key = rk it.value = rv } it.bucket = bucket if it.bptr != b { // avoid unnecessary write barrier; see issue 14921 it.bptr = b } it.i = i + 1 it.checkBucket = checkBucket return } // Traversing bucket.overflow list b = b.overflow(t) i = 0 goto next }
The overall idea is as follows:
- Firstly, an index is randomly determined from the buckets array as the startBucket, and then offset offset is determined as the address of the starting key.
- Traverse the current bucket and bucket.overflow to determine whether the current bucket is expanding, if so, jump to 3, otherwise jump to 4
- Adding the original buckets is 0,1, then the new expanded buckets are 0,1,2,3. At this time, we traverse the buckets[0], and find that the bucket is expanding. Then we find the old buckets[0], which corresponds to the bucket[0], and traverse the key inside. Is it time to traverse all of them? Of course not, but just traversing those keys through hash can be scattered into the bucket[0]; similarly, when traversing the bucket[2], it is found that the bucket is expanding, old buckets[0], and then traversing those keys that can be scattered into the bucket[2].
- Traverse through the current bucket
- Continue traversing the overflow list under the bucket
- If you traverse the startBucket, it means that the traversal is over and the traversal is over.