Looking at the Kafka document recently, I found that Kafka has one. Log Compaction Functions we haven't noticed before, but they have high potential practical value.
What is Log Compaction
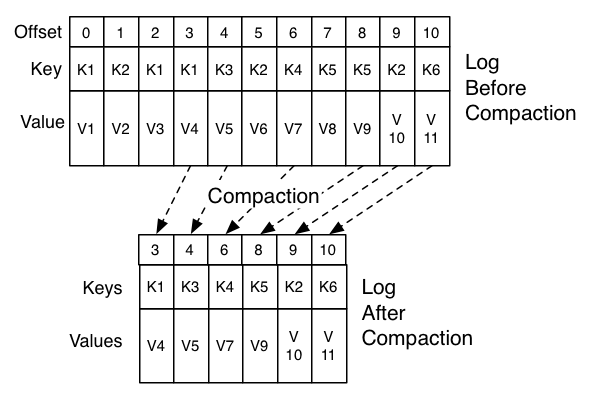
Every piece of data in Kafka has a pair of Keys and Value s, which are stored on disk and will not be preserved permanently, but delete the earliest written data after reaching a certain amount or time. Log Compaction provides another way to delete out-of-date data (or retain valuable data) in addition to the default deletion rules, that is, it does not have the same Key. With the same data, only the last one is retained, and the previous data is deleted under appropriate circumstances.
Application scenarios of Log Compaction
Log Compaction features, as far as real-time computing is concerned, can be well used in disaster recovery scenarios. For example, when we do calculations in Storm, we need to maintain some data in memory for a long time. These data may be obtained by aggregating logs for a day or a week. Once these data collapse due to accidental reasons (disks, networks, etc.), we need to start computing from scratch. It takes a long time. One possible solution is to backup the data in memory to external storage regularly, such as Redis or Mysql, and then read back from external storage to continue computing when a crash occurs.
Using Log Compaction instead of these external storage has the following benefits.
Kafka is both a data source and a storage tool, which can simplify the technology stack and reduce maintenance costs.
When using Mysql or Redis as external storage, we need to record the stored Keys, and then retrieve the data with these Keys when recovering, which has a certain engineering complexity. With Log Compaction feature, we just need to write the data into Kafka one after another, and then read back to memory when disaster recovery occurs.
Kafka has a high order for disk reading and writing. Compared with Mysql, it has no workload such as index query, and can achieve high performance. Compared with Redis, Kafka can make full use of cheap disks and has low memory requirements. It can achieve very high performance-price ratio under near performance (only for disaster recovery scenario).
Brief introduction of implementation mode
When topic's cleanup.policy (default delete) is set to compact, Kafka's background threads periodically traverse the topic twice, saving offsets that appear the last time each key hash value appears for the first time, checking whether each offset's corresponding key has appeared in the later log, and deleting the corresponding log if it appears.
Source code analysis
Most of the functions of Log Compaction are CleanerThread Completion, core logic in Cleaner clean Method
/** * Clean the given log * * @param cleanable The log to be cleaned * * @return The first offset not cleaned and the statistics for this round of cleaning */ private[log] def clean(cleanable: LogToClean): (Long, CleanerStats) = { val stats = new CleanerStats() info("Beginning cleaning of log %s.".format(cleanable.log.name)) val log = cleanable.log // build the offset map info("Building offset map for %s...".format(cleanable.log.name)) val upperBoundOffset = cleanable.firstUncleanableOffset buildOffsetMap(log, cleanable.firstDirtyOffset, upperBoundOffset, offsetMap, stats) // < - - - This is the first time that all offset s are indexed by key. val endOffset = offsetMap.latestOffset + 1 stats.indexDone() // figure out the timestamp below which it is safe to remove delete tombstones // this position is defined to be a configurable time beneath the last modified time of the last clean segment val deleteHorizonMs = log.logSegments(0, cleanable.firstDirtyOffset).lastOption match { case None => 0L case Some(seg) => seg.lastModified - log.config.deleteRetentionMs } // determine the timestamp up to which the log will be cleaned // this is the lower of the last active segment and the compaction lag val cleanableHorizonMs = log.logSegments(0, cleanable.firstUncleanableOffset).lastOption.map(_.lastModified).getOrElse(0L) // group the segments and clean the groups info("Cleaning log %s (cleaning prior to %s, discarding tombstones prior to %s)...".format(log.name, new Date(cleanableHorizonMs), new Date(deleteHorizonMs))) for (group <- groupSegmentsBySize(log.logSegments(0, endOffset), log.config.segmentSize, log.config.maxIndexSize)) cleanSegments(log, group, offsetMap, deleteHorizonMs, stats) // < -- This is the second time to traverse all offset s, delete redundant logs, and merge mu lt iple small segment s into one // record buffer utilization stats.bufferUtilization = offsetMap.utilization stats.allDone() (endOffset, stats) }
log compaction is achieved by traversing all data twice, and the medium of communication between the two traversals is one.
OffsetMap The following is the signature of OffsetMap
trait OffsetMap { def slots: Int def put(key: ByteBuffer, offset: Long) def get(key: ByteBuffer): Long def clear() def size: Int def utilization: Double = size.toDouble / slots def latestOffset: Long }
This is basically a mutable map. In the Kafka project, there is only one implementation, called a mutable map. SkimpyOffsetMap
put method
The put method generates a summary for each key. By default, the md5 method generates a 16 byte summary. According to this summary, the bytes hash to a subscript. If the subscript has been occupied by another digest, the next free subscript is found linearly, and then the offset corresponding to the key is inserted at the corresponding position.
/** * Associate this offset to the given key. * @param key The key * @param offset The offset */ override def put(key: ByteBuffer, offset: Long) { require(entries < slots, "Attempt to add a new entry to a full offset map.") lookups += 1 hashInto(key, hash1) // probe until we find the first empty slot var attempt = 0 var pos = positionOf(hash1, attempt) while(!isEmpty(pos)) { bytes.position(pos) bytes.get(hash2) if(Arrays.equals(hash1, hash2)) { // we found an existing entry, overwrite it and return (size does not change) bytes.putLong(offset) lastOffset = offset return } attempt += 1 pos = positionOf(hash1, attempt) } // found an empty slot, update it--size grows by 1 bytes.position(pos) bytes.put(hash1) bytes.putLong(offset) lastOffset = offset entries += 1 }
get method
The get method uses the same digest algorithm as put to get the digest of key, and gets the storage location of offset by digest.
/** * Get the offset associated with this key. * @param key The key * @return The offset associated with this key or -1 if the key is not found */ override def get(key: ByteBuffer): Long = { lookups += 1 hashInto(key, hash1) // search for the hash of this key by repeated probing until we find the hash we are looking for or we find an empty slot var attempt = 0 var pos = 0 //we need to guard against attempt integer overflow if the map is full //limit attempt to number of slots once positionOf(..) enters linear search mode val maxAttempts = slots + hashSize - 4 do { if(attempt >= maxAttempts) return -1L pos = positionOf(hash1, attempt) bytes.position(pos) if(isEmpty(pos)) return -1L bytes.get(hash2) attempt += 1 } while(!Arrays.equals(hash1, hash2)) bytes.getLong() }
Probable space problem performance problem conflict problem
Space problem
By default, Kafka uses 16 bytes to store abstracts of keys, 8 bytes to store offsets corresponding to abstracts, and 1 GB of space to store 1024*1024*1024/24=44,739,242.666 key data.
Performance problems
The principle of log compaction is very simple, that is to read and write all logs twice on a regular basis. It is not a problem that the speed of cpu exceeds that of disk at all. As long as the time of reading and writing logs twice corresponds to the amount of time in an acceptable range, its performance is acceptable.
Conflict problem
Now the only implementation of OffsetMap is called Skimpy OffsetMap. I believe you can see from this name that the original author thought the implementation was not rigorous enough. This algorithm judges that the keys are the same when the md5 values of the two keys are the same. If the keys are different and the md5 values are the same, one of the two keys will get the message. It's lost. Although the probability of the same md5 value is very low, if it really happens, it's 100%. It's useless to have a lower probability, and from the reflection on the Internet, it seems that conflicts are not uncommon.
The solution I'm thinking about now is that most of the keys are not very long in total length. You can look at all the possible situations of these keys in md5 once to see if there is any conflict. If not, you can rest assured.