1. Job concept
When using fat to start a training model task (Job), two parameter files must be: dsl and conf(Task Submit Runtime Conf);
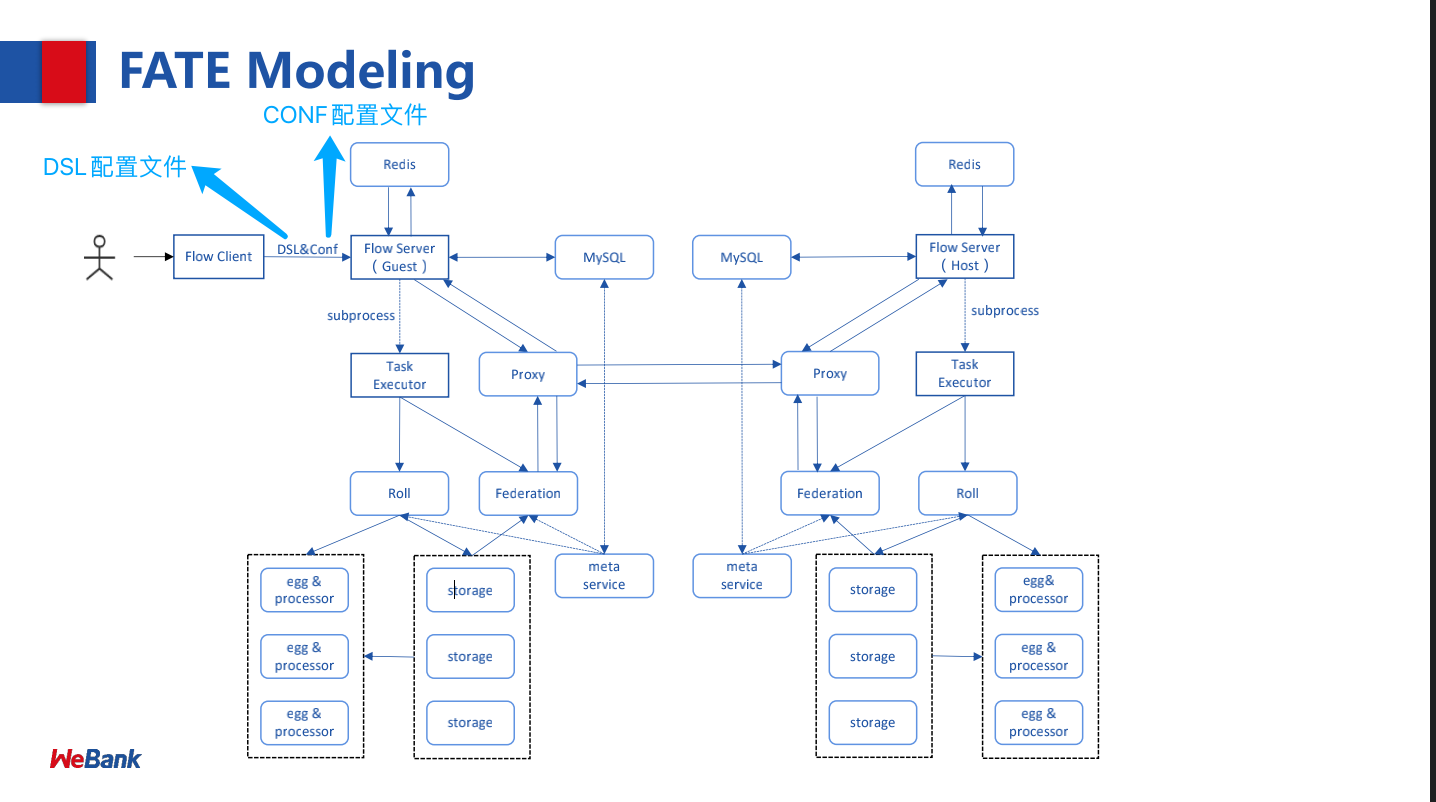
Task startup flowchart:
2. About DSL language
DSL & task submit runtime conf setting V2
In order to make the construction of task model more flexible, fat uses a set of self-defined domain specific language (DSL) to describe tasks. In DSL, various modules (such as data read / write, data_io, feature engineering, regression region, classification) can be organized into a directed acyclic graph (DAG). Through various ways, users can flexibly combine various algorithm modules according to their own needs.
In addition, each module has different parameters to be configured, and different parties may have different parameters for the same module. In order to simplify this situation, for each module, fat will save different parameters of all parties to the same Submit Runtime Conf, and all parties will share this configuration file. This guide will show you how to create a DSL configuration file. V2 configuration official website reference
3. DSL configuration description
3.1. Summary
The configuration file of DSL adopts json format. In fact, the whole configuration file is a json object (dict). It is usually used to define the model training plan. It is also used to arrange the implemented components of fat, and the training plan is executed in this order;
3.2. Components
The first level of this dict is "components", which is used to represent each module that will be used in this task. Each independent module is defined under "components". All data needs to be taken from the data store through the Reader module. Note that the Reader module only output s
3.3. module
Used to specify the module to use. Refer to fat ML algorithm list for module name , and / fat / Python / federatedml / conf / setting_ The file names of all modules under conf are consistent (excluding the. json suffix).
3.4. input
There are two input types: Data and Model.
Data input, divided into three input types:
1. data: Generally used for data_io modular, feature_engineering Module or evaluation modular;
2. train_data: Generally used for homo_lr, hetero_lr and secure_boost modular. If it does train_data
Field, then the task will be recognized as a fit task;
4. validate_data: If present train_data Field, this field is optional. If you choose to keep this field, the
Data sent to will be used as validation set
5. test_data: Used as forecast data, if provided, it shall be provided at the same time model Input.
Model input is divided into two types:
1. model: Model input for components of the same type. 2. isometric_model: Specifies the model input that inherits upstream components
3.5. output
Data output is divided into four output types:
1. data: General module data output; 2. train_data: Only for Data Split; 3. validate_data: Only for Data Split; 4. test_data: Only for Data Split;
Model output
1. Use only model;
3.6. DSL configuration example
In the training mode, users can use other algorithm modules to replace heterosecurebost. Note the module name hetero_secureboost_0 should also be changed together;
{
"components": {
"reader_0": {
"module": "Reader",
"output": {
"data": [
"data"
]
}
},
"dataio_0": {
"module": "DataIO",
"input": {
"data": {
"data": [
"reader_0.data"
]
}
},
"output": {
"data": [
"data"
],
"model": [
"model"
]
}
},
"intersection_0": {
"module": "Intersection",
"input": {
"data": {
"data": [
"dataio_0.data"
]
}
},
"output": {
"data": [
"data"
]
}
},
"hetero_secureboost_0": {
"module": "HeteroSecureBoost",
"input": {
"data": {
"train_data": [
"intersection_0.data"
]
}
},
"output": {
"data": [
"data"
],
"model": [
"model"
]
}
},
"evaluation_0": {
"module": "Evaluation",
"input": {
"data": {
"data": [
"hetero_secureboost_0.data"
]
}
},
"output": {
"data": [
"data"
]
}
}
}
}
4. Submit Runtime Conf
dslV2 version this file is an operation configuration file, which is mainly composed of the following four main parts:
- dsl version:{}
- initiator:{}
- role:{}
- job parameters:{}
- component_parameters:{}
4.1. dsl version:
The configuration version is 1 by default and 2 is recommended;
"dsl_version": "2"
4.2. initiator:
The user needs to define the initiator.
1. Initiator, including the role and Party of the task initiator_ ID, for example:
"initiator": {
"role": "guest",
"party_id": 9999
}
4.3 role:
All participants: contains the information of each participant. In the role field, each element represents a role and the party undertaking the role_ id. Party for each role_ ID exists as a list, because a task may involve multiple parties playing the same role. For example:
"role": {
"guest": [9999],
"host": [10000],
"arbiter": [10000]
}
4.4. job parameters:
Configure the main system parameters during job operation; Parameter application range policy settings:
1. Apply to all participants, using common scope identifier ; 2. Apply only to a party, using role Range identifier, using role:party_index Locate the specified party, and the directly specified parameter takes precedence over common parameter
Example:
"common": {
}
"role": {
"guest": {
"0": {
}
}
}
The parameters under common are applied to all participants, and the parameters under role-guest-0 configuration are applied to participants with subscript 0 of guest role;
Note that the system operation parameters in the current version are not strictly tested and are only applied to a participant, so it is recommended to choose common first;
Detailed description of job parameters:
| Configuration item | Default value | Support value | explain |
|---|---|---|---|
| job_type | train | train, predict | Task type |
| work_mode | 0 | 0, 1 | 0 represents single party stand-alone version and 1 represents multi-party distributed version |
| backend | 0 | 0, 1, 2 | 0 represents EGGROLL, 1 represents SPARK plus rabbit MQ, and 2 represents SPARK plus Pulsar |
| model_id | - | - | Model id, which needs to be filled in for prediction task |
| model_version | - | - | Model version, the forecast task needs to be filled in |
| task_cores | 4 | positive integer | Total cpu cores for job requests |
| task_parallelism | 1 | positive integer | task parallelism |
| computing_partitions | Number of cpu cores allocated to task | positive integer | The number of partitions in the data table at the time of calculation |
| eggroll_run | nothing | processors_per_node et al | The configuration parameters related to the eggroll computing engine generally do not need to be configured and are controlled by task_ The cores are calculated automatically. If configured, the task_ The cores parameter does not take effect |
| spark_run | nothing | Num executors, executor cores, etc | The related configuration parameters of spark computing engine generally do not need to be configured and are determined by task_ The cores are calculated automatically. If configured, the task_ The cores parameter does not take effect |
| rabbitmq_run | nothing | queue, exchange, etc | rabbitmq creates the relevant configuration parameters of queue and exchange. Generally, it does not need to be configured, and the system default value is adopted |
| pulsar_run | nothing | producer, consumer, etc | pulsar is configured when creating producer and consumer. Generally, it does not need to be configured. |
| federated_status_collect_type | PUSH | PUSH, PULL | Multi party operation status collection mode, PUSH means that each participant actively reports to the initiator, and PULL means that the initiator regularly pulls from each participant |
| timeout | 259200 (3 days) | positive integer | Task timeout in seconds |
The following common parameters are explained in detail:
4.4.1. backend parameter:
1. The three types of engines have certain support dependencies, such as Spark The computing engine currently only supports HDFS As an intermediate data storage engine; 2. work_mode + backend It will automatically generate the corresponding three engine configurations according to the support dependencies computing,storage,federation; 3. Developers can implement the adaptive engine and runtime config Configuration engine;
There are four reference configurations:
1. use eggroll As backend,Take default cpu Configuration when assigning calculation policies; 2. use eggroll As backend,Take direct designation cpu Configuration with equal parameters 3. use spark plus rabbitMQ As backend,Take direct designation cpu Configuration with equal parameters 4. use spark plus pulsar As backend;
Example:
"job_parameters": {
"common": {
"job_type": "train",
"work_mode": 1,
"backend": 1,
"spark_run": {
"num-executors": 1,
"executor-cores": 2
},
"task_parallelism": 2,
"computing_partitions": 8,
"timeout": 36000,
"rabbitmq_run": {
"queue": {
"durable": true
},
"connection": {
"heartbeat": 10000
}
}
}
}
4.4.2. Detailed description of resource management
Since version 1.5.0, in order to further manage resources, fateflow enables a finer grained cpu cores management policy, removing the policy of limiting the number of jobs running at the same time in the previous version.
Including: total resource allocation, operation resource calculation, resource scheduling, Refer to for details
4.5. component_parameters: component running parameters
Parameter application range policy settings:
1. Apply to all participants, using common scope identifier ;
2. Apply only to a party, using role Range identifier, using role:party_index Locate the designated party,
Directly specified parameters take precedence over common parameter;
- Example 1:
"commom": {
}
"role": {
"guest": {
"0": {}
}
"host":{
"0": {}
}
}
The parameters under the common configuration are applied to all participants, and the parameters under the role-guest-0 configuration are applied to the participants under the subscript 0 of the guest role. Note that the component operation parameters of the current version support two application range policies;
- Example 2:
"component_parameters": {
"common": {
"intersection_0": {
"intersect_method": "raw",
"sync_intersect_ids": true,
"only_output_key": false
},
"hetero_lr_0": {
"penalty": "L2",
"optimizer": "rmsprop",
"alpha": 0.01,
"max_iter": 3,
"batch_size": 320,
"learning_rate": 0.15,
"init_param": {
"init_method": "random_uniform"
}
}
},
"role": {
"guest": {
"0": {
"reader_0": {
"table": {"name": "breast_hetero_guest", "namespace": "experiment"}
},
"dataio_0":{
"with_label": true,
"label_name": "y",
"label_type": "int",
"output_format": "dense"
}
}
},
"host": {
"0": {
"reader_0": {
"table": {"name": "breast_hetero_host", "namespace": "experiment"}
},
"dataio_0":{
"with_label": false,
"output_format": "dense"
}
}
}
}
}
Example Parameter Description:
- The above example component name is defined in the DSL configuration file, which corresponds to it;
- intersection_0 and hetero_lr_0 the operating parameters of the two components are placed in the common range and applied to all participants;
- For reader_0 and dataio_0 the operating parameters of the two components are configured according to different participants, because the input parameters of different participants are usually inconsistent, and all the two components are generally set according to the participants;
4.5.1 configuration of multiple host s
Including multi host tasks, all host information shall be listed under the role, and different configurations of each host shall be listed under their corresponding modules; todo=??
===================================================================================
The above is the composition of a complete Submit Runtime Conf configuration file. The following is an example of Submit Runtime Conf configuration:
{
"dsl_version": "2",
"initiator": {
"role": "guest",
"party_id": 9999
},
"role": {
"host": [
10000
],
"guest": [
9999
]
},
"job_parameters": {
"job_type": "train",
"work_mode": 0,
"backend": 0,
"computing_engine": "STANDALONE",
"federation_engine": "STANDALONE",
"storage_engine": "STANDALONE",
"engines_address": {
"computing": {
"nodes": 1,
"cores_per_node": 20
},
"federation": {
"nodes": 1,
"cores_per_node": 20
},
"storage": {
"nodes": 1,
"cores_per_node": 20
}
},
"federated_mode": "SINGLE",
"task_parallelism": 1,
"computing_partitions": 4,
"federated_status_collect_type": "PULL",
"model_id": "guest-9999#host-10000#model",
"model_version": "202108310831349550536",
"eggroll_run": {
"eggroll.session.processors.per.node": 4
},
"spark_run": {},
"rabbitmq_run": {},
"pulsar_run": {},
"adaptation_parameters": {
"task_nodes": 1,
"task_cores_per_node": 4,
"task_memory_per_node": 0,
"request_task_cores": 4,
"if_initiator_baseline": false
}
},
"component_parameters": {
"role": {
"guest": {
"0": {
"reader_0": {
"table": {
"name": "breast_hetero_guest",
"namespace": "experiment"
}
}
}
},
"host": {
"0": {
"reader_0": {
"table": {
"name": "breast_hetero_host",
"namespace": "experiment"
}
},
"dataio_0": {
"with_label": false
}
}
}
},
"common": {
"dataio_0": {
"with_label": true
},
"hetero_secureboost_0": {
"task_type": "classification",
"objective_param": {
"objective": "cross_entropy"
},
"num_trees": 5,
"bin_num": 16,
"encrypt_param": {
"method": "iterativeAffine"
},
"tree_param": {
"max_depth": 3
}
},
"evaluation_0": {
"eval_type": "binary"
}
}
}
}
5. Principle of fat-flow operation job process
- After submitting the job, fast flow obtains the job dsl configuration file and job config configuration file (Submit Runtime Conf) and stores them in the database t_ Corresponding fields of the job table and / fat / jobs / $jobid / directory;
- Parse the job dsl and job config, generate fine-grained parameters according to the merged parameters (three engine parameters will be generated corresponding to the backend & work_mode mentioned above), and process the default values of the parameters;
- Distribute and store the common configuration to all participants, and generate a job according to the actual information of the participants_ runtime_ on_ party_ conf;
- When each participant receives a task, it is based on the job_runtime_on_party_conf execution;
The $job id directory includes the following files:
1. job_dsl.json 2. job_runtime_conf.json 3. local pipeline_dsl.json 4. train_runtime_conf.json