brief introduction
In the previous article, we found a critical path code for converting logical SQL to real SQL. In this article, we will explore some details of statement parsing generation based on the previous article
Source code analysis
The code generated by the key parsing of the statement is as follows:
@RequiredArgsConstructor
public abstract class AbstractSQLBuilder implements SQLBuilder {
private final SQLRewriteContext context;
@Override
public final String toSQL() {
if (context.getSqlTokens().isEmpty()) {
return context.getSql();
}
Collections.sort(context.getSqlTokens());
StringBuilder result = new StringBuilder();
result.append(context.getSql(), 0, context.getSqlTokens().get(0).getStartIndex());
for (SQLToken each : context.getSqlTokens()) {
result.append(each instanceof ComposableSQLToken ? getComposableSQLTokenText((ComposableSQLToken) each) : getSQLTokenText(each));
result.append(getConjunctionText(each));
}
return result.toString();
}
protected abstract String getSQLTokenText(SQLToken sqlToken);
private String getComposableSQLTokenText(final ComposableSQLToken composableSQLToken) {
StringBuilder result = new StringBuilder();
for (SQLToken each : composableSQLToken.getSqlTokens()) {
result.append(getSQLTokenText(each));
result.append(getConjunctionText(each));
}
return result.toString();
}
private String getConjunctionText(final SQLToken sqlToken) {
return context.getSql().substring(getStartIndex(sqlToken), getStopIndex(sqlToken));
}
private int getStartIndex(final SQLToken sqlToken) {
int startIndex = sqlToken instanceof Substitutable ? ((Substitutable) sqlToken).getStopIndex() + 1 : sqlToken.getStartIndex();
return Math.min(startIndex, context.getSql().length());
}
private int getStopIndex(final SQLToken sqlToken) {
int currentSQLTokenIndex = context.getSqlTokens().indexOf(sqlToken);
return context.getSqlTokens().size() - 1 == currentSQLTokenIndex ? context.getSql().length() : context.getSqlTokens().get(currentSQLTokenIndex + 1).getStartIndex();
}
}
From the toSQL function, we can see that the context variable is basically used to obtain the generated real SQL, and its contents are roughly as follows:
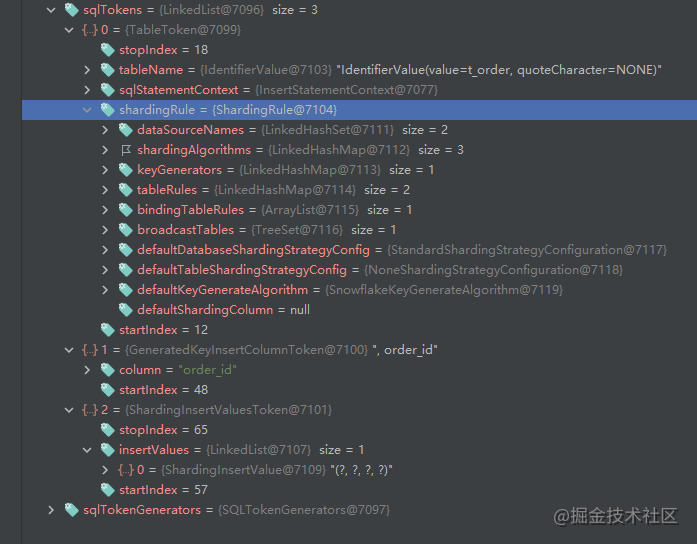
Other tabletokens are rich and contain a lot of information. It may be that the logical table name needs to be converted to the real table name. All of them need so much information
We can see that the length of context.getSqlTokens() is 2, and the result will be added three times:
- Initial addition before loop traversal processing: result.append(context.getSql(), 0, context.getSqlTokens().get(0).getStartIndex());
- Add TableToken in the first cycle
- Second cycle addition:
- Third cycle addition
Let's follow these three additions carefully
Initial addition
result.append(context.getSql(), 0, context.getSqlTokens().get(0).getStartIndex());
The above statement intercepts the substring from the string and adds it. It intercepts it from the original SQL. The starting point is 0 and the ending point is the startIndex of the first sqltoken
The corresponding changes are as follows:
- Original logical SQL: INSERT INTO t_order (user_id, address_id, status) VALUES (?, ?, ?)
- result changed from an empty string to: INSERT INTO
It seems that this step is indeed common to all SQL statements. The previous statements should not be parsed and transformed (how to obtain the end point of interception, this is the generation part of SQLToken. Don't look at it this time, follow the processing flow first)
Add TableToken in the first cycle
for (SQLToken each : context.getSqlTokens()) {
result.append(each instanceof ComposableSQLToken ? getComposableSQLTokenText((ComposableSQLToken) each) : getSQLTokenText(each));
result.append(getConjunctionText(each));
}
As can be seen from the above statement, there are two processing methods:
- Processing of combined SQLToken: getcomposablesqltoken text
- Processing of non combined SQLToken: getsqltoken text
We can track it directly: getSQLTokenText
The trace enters the following function. If it is RouteUnitAware, it needs to be processed
public final class RouteSQLBuilder extends AbstractSQLBuilder {
@Override
protected String getSQLTokenText(final SQLToken sqlToken) {
if (sqlToken instanceof RouteUnitAware) {
return ((RouteUnitAware) sqlToken).toString(routeUnit);
}
return sqlToken.toString();
}
}
Take a look at how a TableToken ToString. The relevant details are as follows
public final class TableToken extends SQLToken implements Substitutable, RouteUnitAware {
@Override
public String toString(final RouteUnit routeUnit) {
// The real table name is obtained. The real table name is obtained from the transformation Map from logical table to real table
String actualTableName = getLogicAndActualTables(routeUnit).get(tableName.getValue().toLowerCase());
// If the real table name is null, get the value of tableName (it can also be written as a sentence, learned)
// tableName is value and the value is t of the original SQL_ order
actualTableName = null == actualTableName ? tableName.getValue().toLowerCase() : actualTableName;
return tableName.getQuoteCharacter().wrap(actualTableName);
}
// From the main idea of the following function, we can see that it is to build the mapping transformation Map from the logical table name to the real table
private Map<String, String> getLogicAndActualTables(final RouteUnit routeUnit) {
Collection<String> tableNames = sqlStatementContext.getTablesContext().getTableNames();
Map<String, String> result = new HashMap<>(tableNames.size(), 1);
for (RouteMapper each : routeUnit.getTableMappers()) {
result.put(each.getLogicName().toLowerCase(), each.getActualName());
// Why do you have to add it again? It's not understood here
result.putAll(shardingRule.getLogicAndActualTablesFromBindingTable(routeUnit.getDataSourceMapper().getLogicName(), each.getLogicName(), each.getActualName(), tableNames));
}
return result;
}
}
Return tablename. Getquotecharacter(). Wrap (actual tablename) the core code is roughly as follows. Add some additional things (keyword reservation, field processing, etc.)
@Getter
public enum QuoteCharacter {
BACK_QUOTE("`", "`"),
SINGLE_QUOTE("'", "'"),
QUOTE("\"", "\""),
BRACKETS("[", "]"),
NONE("", "");
private final String startDelimiter;
private final String endDelimiter;
/**
* Wrap value with quote character.
*
* @param value value to be wrapped
* @return wrapped value
*/
public String wrap(final String value) {
return startDelimiter + value + endDelimiter;
}
}
The corresponding changes are as follows:
- Original logical SQL: INSERT INTO t_order (user_id, address_id, status) VALUES (?, ?, ?)
- result changed from an empty string to: insert into_ order_ 0
Let's go to: result. Append (getconflictiontext (each));
public abstract class AbstractSQLBuilder implements SQLBuilder {
private String getConjunctionText(final SQLToken sqlToken) {
return context.getSql().substring(getStartIndex(sqlToken), getStopIndex(sqlToken));
}
private int getStartIndex(final SQLToken sqlToken) {
int startIndex = sqlToken instanceof Substitutable ? ((Substitutable) sqlToken).getStopIndex() + 1 : sqlToken.getStartIndex();
return Math.min(startIndex, context.getSql().length());
}
private int getStopIndex(final SQLToken sqlToken) {
int currentSQLTokenIndex = context.getSqlTokens().indexOf(sqlToken);
return context.getSqlTokens().size() - 1 == currentSQLTokenIndex ? context.getSql().length() : context.getSqlTokens().get(currentSQLTokenIndex + 1).getStartIndex();
}
}
The main idea is to get the start and end intercept points. The algorithm has not yet understood... But it has a lot to do with SQLToken. See if you can get an answer when you look at SQLToken later
The corresponding changes are as follows:
- Original logical SQL: INSERT INTO t_order (user_id, address_id, status) VALUES (?, ?, ?)
- result changed from an empty string to: insert into_ order_ 0 (user_ id, address_ id, status
Second cycle addition:
Let's look at the second loop add: GeneratedKeyInsertColumnToken
@Override
protected String getSQLTokenText(final SQLToken sqlToken) {
if (sqlToken instanceof RouteUnitAware) {
return ((RouteUnitAware) sqlToken).toString(routeUnit);
}
// Go straight here
return sqlToken.toString();
}
}
public final class extends SQLToken implements Attachable {
@Override
public String toString() {
// Simply and rudely insert a column name directly
return String.format(", %s", column);
}
}
It can be seen from the above general idea that a column name is inserted, and the corresponding changes are as follows:
- Original logical SQL: INSERT INTO t_order (user_id, address_id, status) VALUES (?, ?, ?)
- result changed from an empty string to: insert into_ order_ 0 (user_ id, address_ id, status, order_ id
Then: result. Append (getconflictiontext (each)), which becomes:
- Original logical SQL: INSERT INTO t_order (user_id, address_id, status) VALUES (?, ?, ?)
- result changed from an empty string to: insert into_ order_ 0 (user_ id, address_ id, status, order_ id) VALUES
Add in the third cycle:
Let's move on to the third loop addition: ShardingInsertValuesToken
public final class RouteSQLBuilder extends AbstractSQLBuilder {
@Override
protected String getSQLTokenText(final SQLToken sqlToken) {
if (sqlToken instanceof RouteUnitAware) {
// Here we go
return ((RouteUnitAware) sqlToken).toString(routeUnit);
}
return sqlToken.toString();
}
}
public final class ShardingInsertValuesToken extends InsertValuesToken implements RouteUnitAware {
public ShardingInsertValuesToken(final int startIndex, final int stopIndex) {
super(startIndex, stopIndex);
}
@Override
public String toString(final RouteUnit routeUnit) {
StringBuilder result = new StringBuilder();
// Here we get: (?,?,?,?),
appendInsertValue(routeUnit, result);
// Then it becomes: (?,?,?,?,?)
result.delete(result.length() - 2, result.length());
return result.toString();
}
private void appendInsertValue(final RouteUnit routeUnit, final StringBuilder stringBuilder) {
for (InsertValue each : getInsertValues()) {
if (isAppend(routeUnit, (ShardingInsertValue) each)) {
stringBuilder.append(each).append(", ");
}
}
}
private boolean isAppend(final RouteUnit routeUnit, final ShardingInsertValue insertValueToken) {
if (insertValueToken.getDataNodes().isEmpty() || null == routeUnit) {
return true;
}
for (DataNode each : insertValueToken.getDataNodes()) {
if (routeUnit.findTableMapper(each.getDataSourceName(), each.getTableName()).isPresent()) {
return true;
}
}
return false;
}
}
I don't understand this at present. Why should I go through this process and what are the application scenarios?
- Original logical SQL: INSERT INTO t_order (user_id, address_id, status) VALUES (?, ?, ?)
- result changed from an empty string to: insert into_ order_ 0 (user_ id, address_ id, status, order_ id) VALUES (?, ?, ?, ?)
Then: result. Append (getconflictiontext (each)), which becomes:
- Original logical SQL: INSERT INTO t_order (user_id, address_id, status) VALUES (?, ?, ?)
- result changed from an empty string to: insert into_ order_ 0 (user_ id, address_ id, status, order_ id) VALUES (?, ?, ?, ?)
At this point, the parsing generation is completed
summary
In this chapter, the processing process of converting logical SQL to real SQL is reviewed in detail:
- Original logical SQL: INSERT INTO t_order (user_id, address_id, status) VALUES (?, ?, ?)
- result changed from an empty string to: insert into_ order_ 0 (user_ id, address_ id, status, order_ id) VALUES (?, ?, ?, ?)
In the transformation, the corresponding Token class is used for corresponding processing and assembled into real SQL
But I still don't know much about algorithms. Look for official data later. Is there any information in this regard
Next, we should take a look at the generation of SQLToken. Through the above tracking, it is found that the generation of real SQL is closely related to SQLToken