Introduction to Apscheduler
Apscheduler is a relatively easy-to-use timing task framework in python. You can refer to the introduction and api Official documents
Concept description
- Job task: defines the functions executed by scheduled tasks, function parameters, and task execution related configurations.
- Trigger: defines the trigger method of task execution, including cron, date, interval and mixed methods.
- JobStore task warehouse: saves scheduled tasks. The default memory supports mongodb, redis, sqlalchemy, etc
- Executor executor: it is responsible for executing tasks. The default thread pool supports process pool, gevent, tornado, asyncio, etc
- Scheduler scheduler: responsible for scheduling tasks, combining other modules and providing convenient APIs.
- Listener event listener: used to listen to various events in the scheduler. Four events are officially provided: scheduler event, task event, task submission event and task execution event.
Scheduler structure diagram
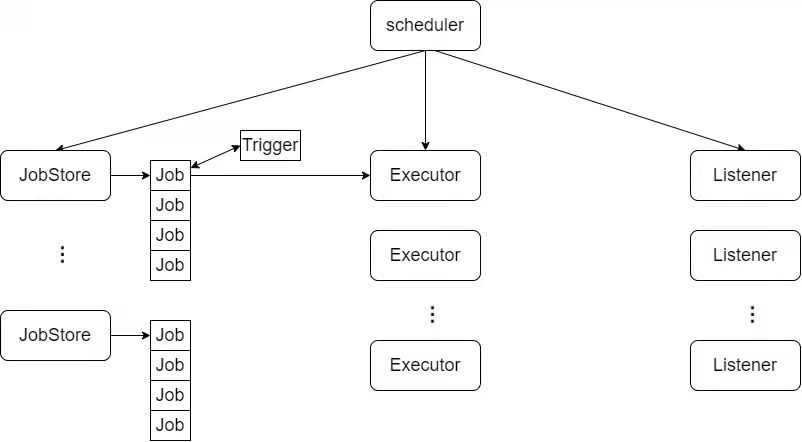
Module definition
scheduler base class definition
A scheduler can contain multiple jobstores, multiple executors, and multiple listeners.
The scheduler also maintains a variable to record the status of the current scheduler.
class BaseScheduler(six.with_metaclass(ABCMeta)):
def __init__(self, gconfig={}, **options):
super(BaseScheduler, self).__init__()
self._executors = {} # executors alias and instance mapping
self._executors_lock = self._create_lock()
self._jobstores = {} # Mapping of jobstores alias to instance
self._jobstores_lock = self._create_lock()
self._listeners = [] # Event listener list
self._listeners_lock = self._create_lock()
self._pending_jobs = [] # List of tasks to be added to the task warehouse
self.state = STATE_STOPPED # scheduler state variable
self.configure(gconfig, **options) # Configure scheduler
JobStore definition
JobStore will maintain a task list, which can be regarded as a list in ascending order according to task execution time. The ordered list of the memory JobStore is maintained in memory, while the database JobStore such as mongodb and redis maintains a sequence table through the database engine. As a JobStore, the database can support persistent saving of tasks.
Job definition
class Job(object):
__slots__ = (
'_scheduler', # Task corresponding scheduler
'_jobstore_alias', # Alias of the JobStore where this task is stored
'id', # Task id
'trigger', # Trigger corresponding to task
'executor', # Alias of the actuator corresponding to the task
'func', # Function corresponding to task
'func_ref', # Serialized tasks
'args',
'kwargs',
'name', # Task description
'misfire_grace_time', # the time (in seconds) how much this job's execution is allowed to be late (None means "allow the job to run no matter how late it is")
'coalesce', # whether to only run the job once when several run times are due
'max_instances', # the maximum number of concurrently executing instances allowed for this job
'next_run_time', # the next scheduled run time of this job
'__weakref__'
)
def __init__(self, scheduler, id=None, **kwargs):
super(Job, self).__init__()
self._scheduler = scheduler
self._jobstore_alias = None
self._modify(id=id or uuid4().hex, **kwargs)
Workflow
Take the combination of BlockingScheduler, MemoryJobStore and ThreadPoolExecutor as an example.
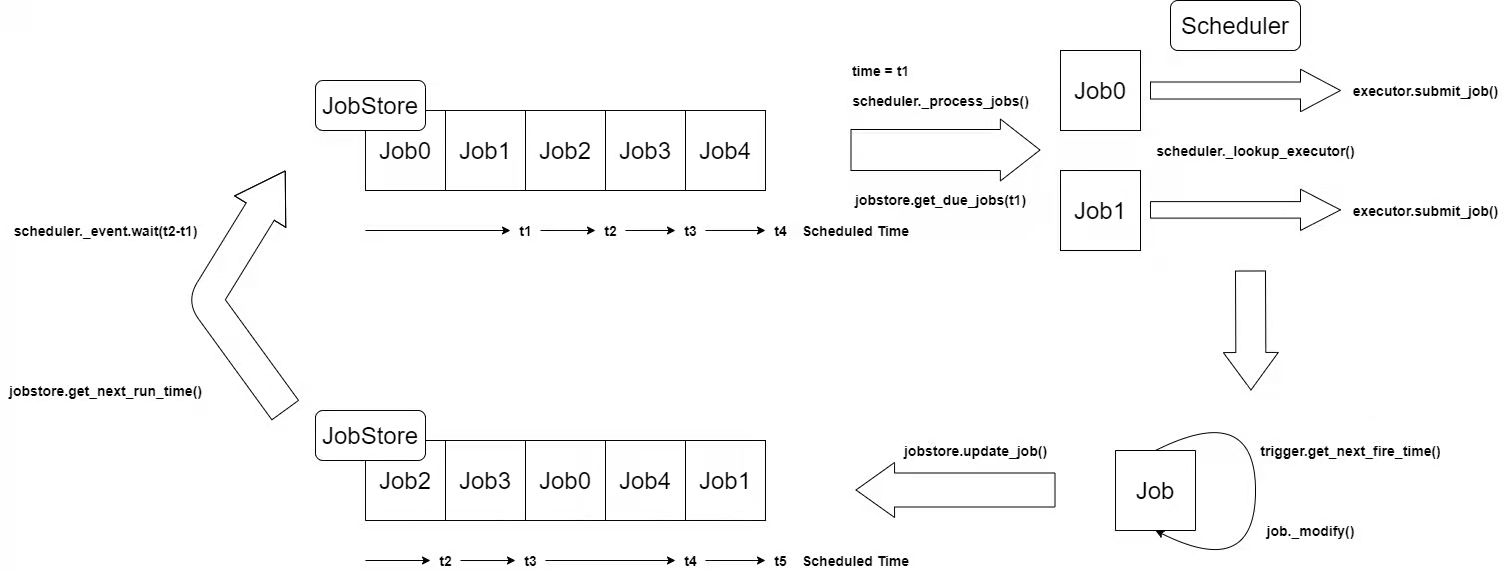
- When the time is t1, call jobstore.get_due_jobs() gets all the expired tasks of the jobstore
- Get the executor alias of the expired task through scheduler_ lookup_ Executor() found executor instance
- Call executor.submit_job() sends the task to the executor for execution
- After successful execution, call trigger.get corresponding to the task_ next_ fire_ Time() gets the next execution time of the task, and then executes the job_ Modify() update task
- By calling jobstore.update_job() updates the updated task back to the jobstore
- Call jobstore.get_next_run_time() gets the latest task execution time of the jobstore
- The scheduler obtains the latest job store task execution time through the scheduler_ Event. Wait () sleep to the latest task execution time and enter the next cycle
Scheduler main loop
# BlockingScheduler._main_loop()
def _main_loop(self):
wait_seconds = TIMEOUT_MAX
while self.state != STATE_STOPPED:
self._event.wait(wait_seconds)
self._event.clear()
wait_seconds = self._process_jobs()
# scheduler._process_jobs()
def _process_jobs(self):
if self.state == STATE_PAUSED:
self._logger.debug('Scheduler is paused -- not processing jobs')
return None
self._logger.debug('Looking for jobs to run')
now = datetime.now(self.timezone)
next_wakeup_time = None
events = []
with self._jobstores_lock:
# Traverse each jobstore to get all expired jobs
for jobstore_alias, jobstore in six.iteritems(self._jobstores):
try:
due_jobs = jobstore.get_due_jobs(now)
except Exception as e:
# Schedule a wakeup at least in jobstore_retry_interval seconds
self._logger.warning('Error getting due jobs from job store %r: %s',
jobstore_alias, e)
retry_wakeup_time = now + timedelta(seconds=self.jobstore_retry_interval)
if not next_wakeup_time or next_wakeup_time > retry_wakeup_time:
next_wakeup_time = retry_wakeup_time
continue
for job in due_jobs:
# Look up the job's executor
try:
executor = self._lookup_executor(job.executor) # Find the executor instance corresponding to each task
except BaseException:
self._logger.error(
'Executor lookup ("%s") failed for job "%s" -- removing it from the '
'job store', job.executor, job)
self.remove_job(job.id, jobstore_alias)
continue
run_times = job._get_run_times(now)
run_times = run_times[-1:] if run_times and job.coalesce else run_times
if run_times:
try:
executor.submit_job(job, run_times) # The executor executes the task
except MaxInstancesReachedError:
self._logger.warning(
'Execution of job "%s" skipped: maximum number of running '
'instances reached (%d)', job, job.max_instances)
event = JobSubmissionEvent(EVENT_JOB_MAX_INSTANCES, job.id,
jobstore_alias, run_times)
events.append(event)
except BaseException:
self._logger.exception('Error submitting job "%s" to executor "%s"',
job, job.executor)
else:
event = JobSubmissionEvent(EVENT_JOB_SUBMITTED, job.id, jobstore_alias,
run_times)
events.append(event)
# Update the job if it has a next execution time.
# Otherwise remove it from the job store.
job_next_run = job.trigger.get_next_fire_time(run_times[-1], now)
if job_next_run:
job._modify(next_run_time=job_next_run)
jobstore.update_job(job)
else:
self.remove_job(job.id, jobstore_alias)
# Set a new next wakeup time if there isn't one yet or
# the jobstore has an even earlier one
jobstore_next_run_time = jobstore.get_next_run_time()
if jobstore_next_run_time and (next_wakeup_time is None or
jobstore_next_run_time < next_wakeup_time):
next_wakeup_time = jobstore_next_run_time.astimezone(self.timezone)
# Dispatch collected events
for event in events:
self._dispatch_event(event)
# Determine the delay until this method should be called again
if self.state == STATE_PAUSED:
wait_seconds = None
self._logger.debug('Scheduler is paused; waiting until resume() is called')
elif next_wakeup_time is None:
wait_seconds = None
self._logger.debug('No jobs; waiting until a job is added')
else:
wait_seconds = min(max(timedelta_seconds(next_wakeup_time - now), 0), TIMEOUT_MAX)
self._logger.debug('Next wakeup is due at %s (in %f seconds)', next_wakeup_time,
wait_seconds)
return wait_seconds
Apscheduler and distributed
When scheduled tasks need to be executed in a general production environment, multi instance deployment is required to avoid that all scheduled tasks cannot be executed due to a single point of failure. However, the same scheduled task does not want to be executed once on each apscheduler instance. Therefore, it is necessary to discuss the distributed implementation of apscheduler. Although the task storage of apscheduler supports distributed storage such as mongodb and redis, apscheduler does not lock the task when obtaining it from the jobstore, so it does not support distributed execution of scheduled tasks. To realize distributed execution, you need to introduce additional distributed locks. Lock the task when each apscheduler instance obtains a task from the jobstore, so as to avoid the same task being executed in all apscheduler instances.