Java mentions the persistence layer framework. I believe no one doesn't know the existence of mybatis. Compared with JDBC, it has a more capable (JDBC workload is large), and compared with Hibernate, it has a more flexible (although HQL is convenient, it is too inflexible). Today we are going into her world together.
1, Simple implementation of mybatis
preparation
1. Create entity class and table mapping
2. Import maven dependency
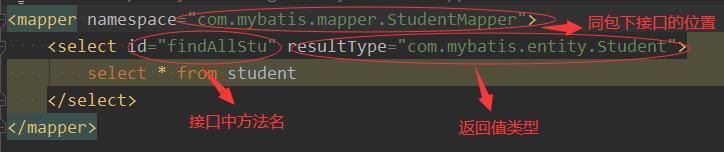
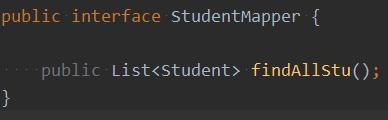
Write interface and mapper as files
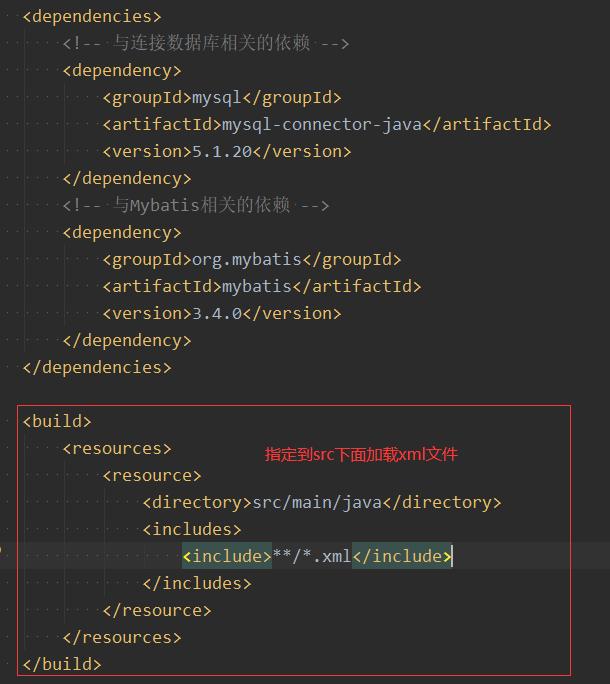
Note: in idea, put the resource file directly under the src folder. If you do not set it, it cannot be found, so you must pom.xml (the first figure) to specify the loading location.
Write profile

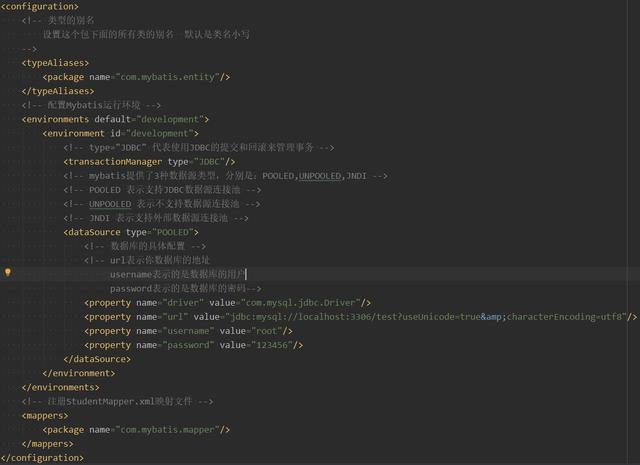
Note: the configuration file should be placed in the resources directory
test
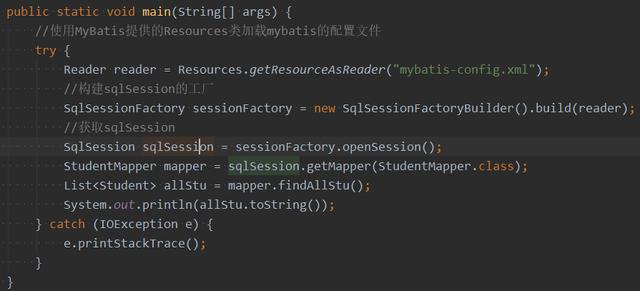
2, Analysis of the implementation principle of mybatis
One of principle analysis: main members of MyBatis
Configuration: all the configuration information of MyBatis is saved in the configuration object, and most of the configuration in the configuration file will be stored in this class.
SqlSession: as the main top-level API of MyBatis, it represents the session when interacting with the database and completes the functions of adding, deleting, modifying and querying the necessary database.
Executor: MyBatis executor, which is the core of MyBatis scheduling, is responsible for the generation of SQL statements and the maintenance of query cache.
StatementHandler: encapsulates the JDBC Statement operation and is responsible for the operation of JDBC Statement, such as setting parameters.
ParameterHandler: responsible for converting the parameters passed by the user to the data type corresponding to JDBC Statement.
ResultSetHandler: responsible for converting the ResultSet result set object returned by JDBC to a List type collection.
TypeHandler: responsible for mapping and conversion between java data types and jdbc data types (also known as data table column types).
Mappedstatement: mappedstatement maintains a package of < select|update|delete|insert > nodes.
SqlSource: it is responsible for dynamically generating SQL statements according to the parameterObject passed by the user, encapsulating the information into the BoundSql object, and returning.
BoundSql: represents the dynamically generated SQL statement and the corresponding parameter information.
Principle analysis II: execution process of Mybatis
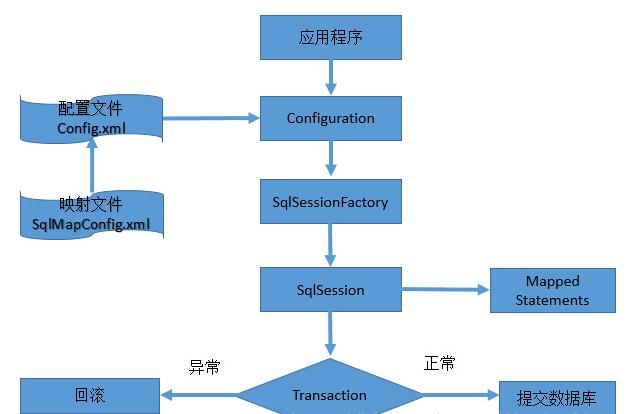
Principle analysis 3: initialization (configuration file reading and parsing)
1. Preparation
Write test code (refer to the example of getting started with Mybatis for details), set breakpoints, and run in Debug mode. The specific code is as follows:
Java code
String resource = "mybatis.cfg.xml"; Reader reader = Resources.getResourceAsReader(resource); SqlSessionFactory ssf = new SqlSessionFactoryBuilder().build(reader); SqlSession session = ssf.openSession();
Let's trace and analyze the above code, let's go.
First, let's look at the first and second lines of code in order to see what it does:
Java code
String resource = "mybatis.cfg.xml"; Reader reader = Resources.getResourceAsReader(resource);
Read the main configuration file of Mybaits and return the input stream of the file. We know that all the SQL statements of Mybatis are written in the XML configuration file, so the first step is to read these XML configuration files, which is not difficult to understand. The key is how to store the files after reading.
Let's look at the third line of code (below), which reads the Configuration file stream and stores the Configuration information in the Configuration class.
Java code
SqlSessionFactory ssf = new SqlSessionFactoryBuilder().build(reader);
The method of building SqlSessionFactoryBuilder is as follows:
Java code
public SqlSessionFactory build(Reader reader) { return build(reader, null, null); }In fact, it is executed by calling another build method of this class. The specific code is as follows:
Java code
public SqlSessionFactory build(Reader reader, String environment, Properties properties) { try { XMLConfigBuilder parser = new XMLConfigBuilder(reader, environment, properties); return build(parser.parse()); } catch (Exception e) { throw ExceptionFactory.wrapException("Error building SqlSession.", e); } finally { ErrorContext.instance().reset(); try { reader.close(); } catch (IOException e) { // Intentionally ignore. Prefer previous error. } } }Let's focus on the two lines:
Java code
//Create a Configuration file stream parsing object XMLConfigBuilder. In fact, this is to assign the environment and Configuration file stream to the parsing class XMLConfigBuilder parser = new XMLConfigBuilder(reader, environment, properties); / / the parsing class parses the Configuration file and stores the parsed content in the Configuration object, And return SqlSessionFactory return build( parser.parse ());
Here, XMLConfigBuilder initializes the calling code as follows:
Java code
private XMLConfigBuilder(XPathParser parser, String environment, Properties props) { super(new Configuration()); ErrorContext.instance().resource("SQL Mapper Configuration"); this.configuration.setVariables(props); this.parsed = false; this.environment = environment; this.parser = parser; }The parse method execution code of XMLConfigBuilder is as follows:
Java code
public Configuration parse() { if (parsed) { throw new BuilderException("Each MapperConfigParser can only be used once."); } parsed = true; parseConfiguration(parser.evalNode("/configuration")); return configuration; }The parsing content is mainly in the parseConfiguration method. Its main task is to read each node of the Configuration file, and then map these data to the memory Configuration object Configuration. Let's take a look at the contents of the parseConfiguration method:
Java code
private void parseConfiguration(XNode root) { try { typeAliasesElement(root.evalNode("typeAliases")); pluginElement(root.evalNode("plugins")); objectFactoryElement(root.evalNode("objectFactory")); objectWrapperFactoryElement(root.evalNode("objectWrapperFactory")); propertiesElement(root.evalNode("properties")); settingsElement(root.evalNode("settings")); environmentsElement(root.evalNode("environments")); typeHandlerElement(root.evalNode("typeHandlers")); mapperElement(root.evalNode("mappers")); }catch (Exception e) { throw new BuilderException("Error parsing SQL Mapper Configuration. Cause: " + e, e); } }The final build method is actually to pass in the configuration object and create an instance of DefaultSqlSessionFactory. DefaultSqlSessionFactory is the default implementation of SqlSessionFactory
Java code
public SqlSessionFactory build(Configuration config) { return new DefaultSqlSessionFactory(config); }Finally, let's look at the fourth line of code:
Java code
SqlSession session = ssf.openSession();
Call the openSession method of DefaultSqlSessionFactory to return a SqlSession instance. Let's see how to get a SqlSession instance. Call the openSessionFromDataSource method first.
Java code
public SqlSession openSession() { return openSessionFromDataSource(configuration.getDefaultExecutorType(), null, false); }Let's take a look at the logic of the openSessionFromDataSource method:
Java code
private SqlSession openSessionFromDataSource(ExecutorType execType, TransactionIsolationLevel level, boolean autoCommit) { Connection connection = null; try { //Obtain the environment information in the configuration information, including which database to use, the information to connect to the database, and the transaction final environment environment = configuration.getEnvironment(); / / obtain the data source according to the configuration of the environment information about the database. Final datasource datasource = getDataSourceFromEnvironment(environment); / / get transaction factory transactionfactory transactionfactory = gettransactionfactory from environment (environment); connection = dataSource.getConnection(); if (level! = null) {/ / sets the transaction isolation level of the connection connection.setTransactionIsolation(level.getLevel()); } / / wrap the connection so that the connection can be logged. Here, the agent is used. Connection = wrapConnection(connection); / / get a transaction instance from the transaction factory. Transaction TX = transactionFactory.newTransaction(connection, autoCommit); / / obtain an executor instance from the configuration information. Executor executor = configuration.newExecutor(tx, execType); / / returns a default instance of SqlSession. return new DefaultSqlSession(configuration, executor, autoCommit);} catch (Exception) e {closeConnection(connection); throw ExceptionFactory.wrapException("Error opening session. Cause: " + e, e); } finally { ErrorContext.instance().reset(); } }Incoming Parameter Description:
(1) ExecutorType: execution type. There are three types of ExecutorType: SIMPLE, REUSE, BATCH. The default is SIMPLE, all of which are in the enumeration class ExecutorType.
(2) TransactionIsolationLevel: transaction isolation level, all defined in enumeration class TransactionIsolationLevel.
(3) autoCommit: whether to commit automatically is mainly the setting of transaction commit.
DefaultSqlSession is the implementation class of SqlSession, which mainly provides methods for operating database for developers.
Here is a summary of the above process, which consists of three steps:
Step 1: read the main configuration file of Ibatis, and read the file as input stream.
Step 2: read each node information of the file from the main Configuration file stream and store it in the Configuration object. Read the reference files of mappers node, and store the node information of these files to Configuration object.
Step 3: obtain the database connection according to the information of Configuration object, and set the transaction isolation level of the connection, and return it through the SqlSession interface of the wrapped database connection object. DefaultSqlSession is the implementation class of SqlSession, so DefaultSqlSession is returned here, and various database operations are provided externally in the SqlSession interface.
Principle analysis 4: source code analysis of an SQL query
Last time we talked about Mybatis loading related configuration files for initialization. This time we talked about how to perform a SQL query.
preparation
The code to complete a SQL query for Mybatis is as follows:
Java code
String resource = "mybatis.cfg.xml"; Reader reader = Resources.getResourceAsReader(resource); SqlSessionFactory ssf = new SqlSessionFactoryBuilder().build(reader); <strong> </strong>SqlSession session = ssf.openSession(); try { UserInfo user = (UserInfo) session.selectOne("User.selectUser", "1"); System.out.println(user); } catch (Exception e) { e.printStackTrace(); } finally { session.close(); }We need to conduct in-depth tracking analysis this time:
Java code
SqlSession session = ssf.openSession(); UserInfo user = (UserInfo) session.selectOne("User.selectUser", "1");Step 1: open a conversation, let's see what has been done in it.
Java code
SqlSession session = ssf.openSession();
The openSession() method of DefaultSqlSessionFactory is as follows:
Java code
public SqlSession openSession() { return openSessionFromDataSource(configuration.getDefaultExecutorType(), null, false); }Let's see what the openSessionFromDataSource method has done
Java code
private SqlSession openSessionFromDataSource(ExecutorType execType, TransactionIsolationLevel level, boolean autoCommit) { Connection connection = null; try { final Environment environment = configuration.getEnvironment(); final DataSource dataSource = getDataSourceFromEnvironment(environment); TransactionFactory transactionFactory = getTransactionFactoryFromEnvironment(environment); connection = dataSource.getConnection(); if (level != null) { connection.setTransactionIsolation(level.getLevel()); }connection = wrapConnection(connection); Transaction tx = transactionFactory.newTransaction(connection, autoCommit); Executor executor = configuration.newExecutor(tx, execType); return new DefaultSqlSession(configuration, executor, autoCommit); } catch(Exception e) { closeConnection(connection); throw ExceptionFactory.wrapException("Error opening session. Cause: " + e, e); } finally { ErrorContext.instance().reset();} }Let's analyze the steps involved here:
(1) Get the environment information of the configuration file we loaded earlier, and get the data source configured in the environment information.
(2) Obtain a connection through the data source, and wrap the connection with the agent (implement the logging function through the agent of JDK).
(3) Set the transaction information (auto commit, transaction level) of the connection, get the transaction factory from the configuration environment, and get a new transaction from the transaction factory.
(4) The incoming transaction object obtains a new executor, and the incoming executor, configuration information, etc. obtains an execution session object.
From the above code, we can see that a configuration load can only have and correspond to one data source. It's not hard for us to understand the above steps. Let's focus on the new executor and DefaultSqlSession.
First, let's see what the new executor has done?
Java code
public Executor newExecutor(Transaction transaction, ExecutorType executorType) {executorType = executorType == null ? defaultExecutorType : executorType; executorType = executorType == null ? ExecutorType.SIMPLE : executorType; Executor executor; if (ExecutorType.BATCH == executorType) { executor = new BatchExecutor(this, transaction); } else if (ExecutorType.REUSE == executorType) { executor = new ReuseExecutor(this, transaction); } else { executor = new SimpleExecutor(this, transaction); } if (cacheEnabled) { executor = new CachingExecutor(executor); } executor = (Executor) interceptorChain.pluginAll(executor); return executor; }The execution steps of the above code are as follows:
(1) Determine the actuator type. If the actuator type is not configured in the configuration file, the default execution type is used ExecutorType.SIMPLE .
(2) Different types of executors are returned according to the type of executor (there are three types of executors, namely BatchExecutor, simpleexector and cachenexecutor, which we will see in detail later).
(3) Bind the interceptor plug-in to the executor (in this case, the agent is also used).
What is DefaultSqlSession for?
DefaultSqlSession implements the SqlSession interface, which has a variety of SQL execution methods. It is mainly used for the external interface of SQL operations. It will call the executor to execute the actual SQL statements.
Next, let's see how SQL query works
Java code
UserInfo user = (UserInfo) session.selectOne("User.selectUser", "1");The selectOne method of DefaultSqlSession class is actually called. The code of the method is as follows:
Java code
public Object selectOne(String statement, Object parameter) { // Popular vote was to return null on 0 results and throw exception on too many. List list = selectList(statement, parameter); if (list.size() == 1) { return list.get(0); } else if (list.size() > 1) { throw new TooManyResultsException("Expected one result (or null) to be returned by selectOne(), but found: " + list.size()); } else { return null; } }Let's take a look at the selectList method (in fact, it is implemented by calling another selectList method of the class):
Java code
public List selectList(String statement, Object parameter) { return selectList(statement, parameter, RowBounds.DEFAULT); } public List selectList(String statement, Object parameter, RowBounds rowBounds) { try { MappedStatement ms = configuration.getMappedStatement(statement); return executor.query(ms, wrapCollection(parameter), rowBounds, Executor.NO_RESULT_HANDLER); } catch (Exception e) { throw ExceptionFactory.wrapException("Error querying database. Cause: " + e, e); } finally { ErrorContext.instance().reset(); } }The execution steps of the second selectList are as follows:
(1) Find the corresponding MappedStatement in the configuration information according to the SQL ID. when the previous configuration was loaded and initialized, we saw that the system would parse the SQL block in the configuration file and put it into a MappedStatement, and put the MappedStatement object into a Map for storage. The key value of the Map is the ID of the SQL block.
(2) Call the query method of the executor and pass in MappedStatement object, SQL parameter object, scope object (empty here) and result processing method.
Now, there's only one question left. How does the executor execute SQL?
As we know above, simpleexecutior is used by default. Let's look at the doQuery method of this class:
Java code
public List doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException { Statement stmt = null; try { Configuration configuration = ms.getConfiguration(); StatementHandler handler = configuration.newStatementHandler(this, ms, parameter, rowBounds, resultHandler); stmt = prepareStatement(handler); return handler.query(stmt, resultHandler); } finally { closeStatement(stmt); } }Internal execution steps of doQuery method:
(1) Gets the configuration information object.
(2) Get a new StatementHandler through the configuration object, which is mainly used to handle a SQL operation.
(3) Preprocess StatementHandler object to get Statement object.
(4) The Statement and result processing objects are passed in, the SQL is executed through the query method of StatementHandler, and the execution results are processed.
Let's see what the new statementhandler has done?
Java code
public StatementHandler newStatementHandler(Executor executor, MappedStatement mappedStatement, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler) { StatementHandler statementHandler = new RoutingStatementHandler(executor, mappedStatement, parameterObject, rowBounds, resultHandler); statementHandler = (StatementHandler) interceptorChain.pluginAll(statementHandler); return statementHandler; }Execution steps of the above code:
(1) Get the corresponding StatementHandler object according to the relevant parameters.
(2) Bind the interceptor plug-in for the StatementHandler object.
The construction method of RoutingStatementHandler class RoutingStatementHandler is as follows:
Java code
public RoutingStatementHandler(Executor executor, MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler) { switch (ms.getStatementType()) { case STATEMENT: delegate = new SimpleStatementHandler(executor, ms, parameter, rowBounds, resultHandler); break; case PREPARED: delegate = new PreparedStatementHandler(executor, ms, parameter, rowBounds, resultHandler); break; case CALLABLE: delegate = new CallableStatementHandler(executor, ms, parameter, rowBounds, resultHandler); break; default: throw new ExecutorException("Unknown statement type: " + ms.getStatementType()); } }Create different statementhandlers according to the StatementType of MappedStatement object, which is similar to the way of previous executors. StatementType has three types of statement, PREPARED and CALLABLE, which correspond to the statement type in JDBC one by one.
Let's take a look at the specific contents of the prepareStatement method:
Java code
private Statement prepareStatement(StatementHandler handler) throws SQLException {Statement stmt; Connection connection = transaction.getConnection(); //Get Statement object from connection stmt = handler.prepare(connection); / / process precompiled incoming parameters handler.parameterize(stmt); return stmt; }