In another article published with this article, BlueDot, a company that uses artificial intelligence to protect people around the world from infectious diseases, warns one week in advance before the epidemic has received strong attention. How valuable is a week's time!
Their AI early warning system uses in-depth learning to process text. This system captures hundreds of thousands of information obtained on the network, such as a large number of news, public statements, and so on, to process natural languages. Today, we talk about in-depth learning how to process text simply.
Text, String or Text, is the sequence of characters or words, most commonly word processing (we do not consider Chinese for the moment, Chinese understanding and processing is much more complex than English).Computers are solidified mathematics, and the processing of text is, in essence, solidified statistics, so that models processed by statistics can solve many simple problems.Let's start now.
Processing Text Data
As before, if the original data to be trained is not a vector, we will vectorize it. There are several ways to vectorize text:
- Split by word
- Divide by character
- n-gram for extracting words
I like to eat fire...Guess what I'm going to say next?What 1-gram says next is OK, this word has nothing to do with the previous text; 2-gram may say "Ba, wood, flame" and so on, forming the word "torch, matches, flame"; 3-gram may say "pot" and "eat hot pot", which is more likely.To begin with, n-gram refers to the first n-1 words.
Today we came to fill a hole we digged before and said we would introduce one-hot later. Now is the time.
one-hot encoding
def one_hot(): samples = ['The cat sat on the mat', 'The dog ate my homework'] token_index = {} # Split into words for sample in samples: for word in sample.split(): if word not in token_index: token_index[word] = len(token_index) + 1 # {'The': 1, 'cat': 2, 'sat': 3, 'on': 4, 'the': 5, 'mat.': 6, 'dog': 7, 'ate': 8, 'my': 9, 'homework.': 10} print(token_index) max_length = 8 results = np.zeros(shape=(len(samples), max_length, max(token_index.values()) + 1)) for i, sample in enumerate(samples): for j, word in list(enumerate(sample.split()))[:max_length]: index = token_index.get(word) results[i, j, index] = 1. print(results)
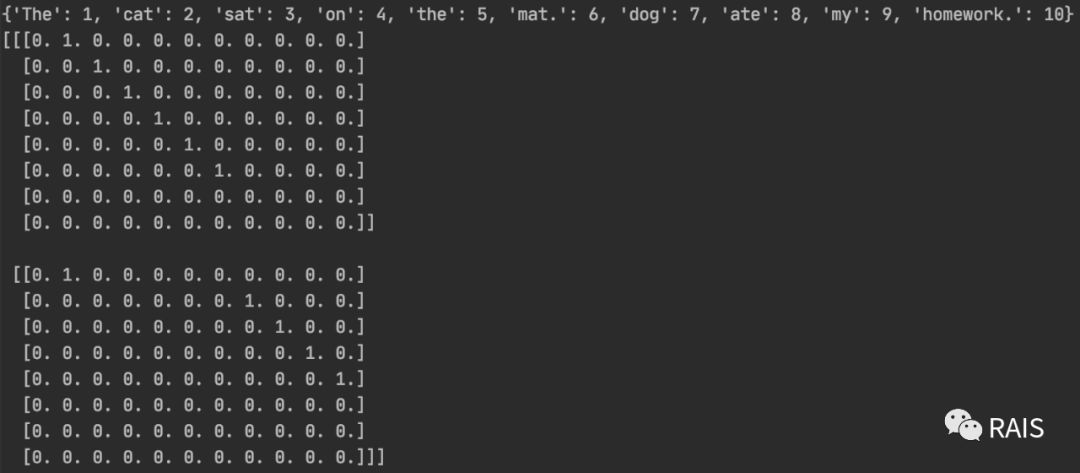
As we can see, this data is not good. mat and homework are followed by an English sentence'.'. Do you want to dazzle off that advanced regular expression to match this strange symbol?Of course not. Yes, Keras has a built-in method.
def keras_one_hot(): samples = ['The cat sat on the mat.', 'The dog ate my homework.'] tokenizer = Tokenizer(num_words=1000) tokenizer.fit_on_texts(samples) sequences = tokenizer.texts_to_sequences(samples) print(sequences) one_hot_results = tokenizer.texts_to_matrix(samples, mode='binary') print(one_hot_results) word_index = tokenizer.word_index print(word_index) print('Found %s unique tokens.' % len(word_index))

num_words here and max_length above are used to indicate how many words are most commonly used. Controlling this will greatly reduce the amount of training time and even improve the accuracy a little bit, in the hope of drawing some attention.We can also see that a large part of the coded vectors are 0, which is not compact enough. This will lead to a large amount of memory consumption, not good, what else can I do?The answer is yes.
Word Embedding
Also called term vector.Word embedding is usually dense and low-dimensional (256, 512, 1024).So what exactly is embedding?
In this paper, our theme is to process text information. Text information is semantical. We can't do anything with text without semantics, but our previous processing method, which is actually probability statistics, is a simple calculation and has no meanings to understand (or very few), but considering the real situation, "very good" and "very good"The first two vectors are small in distance and large in distance when we want to convert them into vectors.So look at the following picture, is it easy to understand?
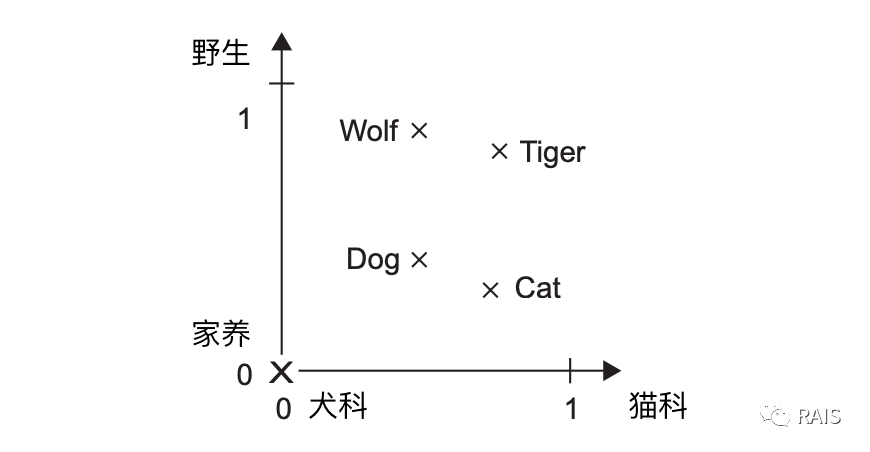
Maybe it's a little hard for you to do this directly, but unfortunately Keras simplifies the problem and Embedding is a built-in network layer that can accomplish this mapping relationship.Now that you understand this concept, let's take a look at the IMDB problem (Movie Review Emotional Prediction), and the code is simple, with 75% accuracy:
def imdb_run(): max_features = 10000 maxlen = 20 (x_train, y_train), (x_test, y_test) = imdb.load_data(num_words=max_features) x_train = preprocessing.sequence.pad_sequences(x_train, maxlen=maxlen) model = Sequential() model.add(Embedding(10000, 8, input_length=maxlen)) model.add(Flatten()) model.add(Dense(1, activation='sigmoid')) model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['acc']) model.summary() history = model.fit(x_train, y_train, epochs=10, batch_size=32, validation_split=0.2)
We have a small amount of data. What can we do?In the previous section, when we were working with images, we used a pre-trained network, where we used a similar method, using pre-trained word embedding.The two most popular word embeddings are GloVe and Word2Vec, which we will describe later when appropriate.Today we're taking the GloVe approach, which I've written in the comments to the code.Let's see the results first, or the code at the end:
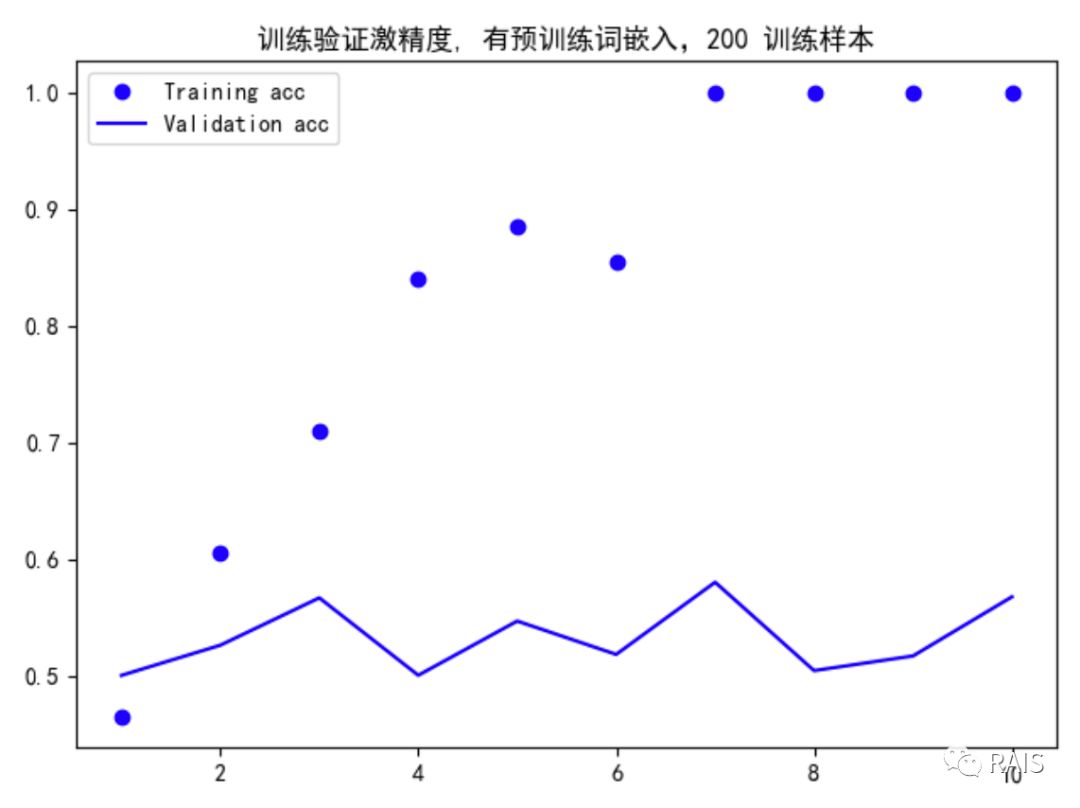
Quickly fitted, you may feel this verification accuracy is close to 60%. Considering that only 200 training samples are available, this result is really good. Of course, you may not believe it. Then I will give two sets of comparison maps, one without words embedded:
[External chain picture transfer failed, source station may have anti-theft chain mechanism, it is recommended to save the picture and upload it directly (img-Uem4R2hO-1583414769394).) https://upload-images.jianshu.io/upload_images/2023569-23b0d32d9d3db11d?imageMogr2/auto-orient/strip%7CimageView2/2/w/1240)]
Validation accuracy is significantly low, giving data for 2000 training sets:
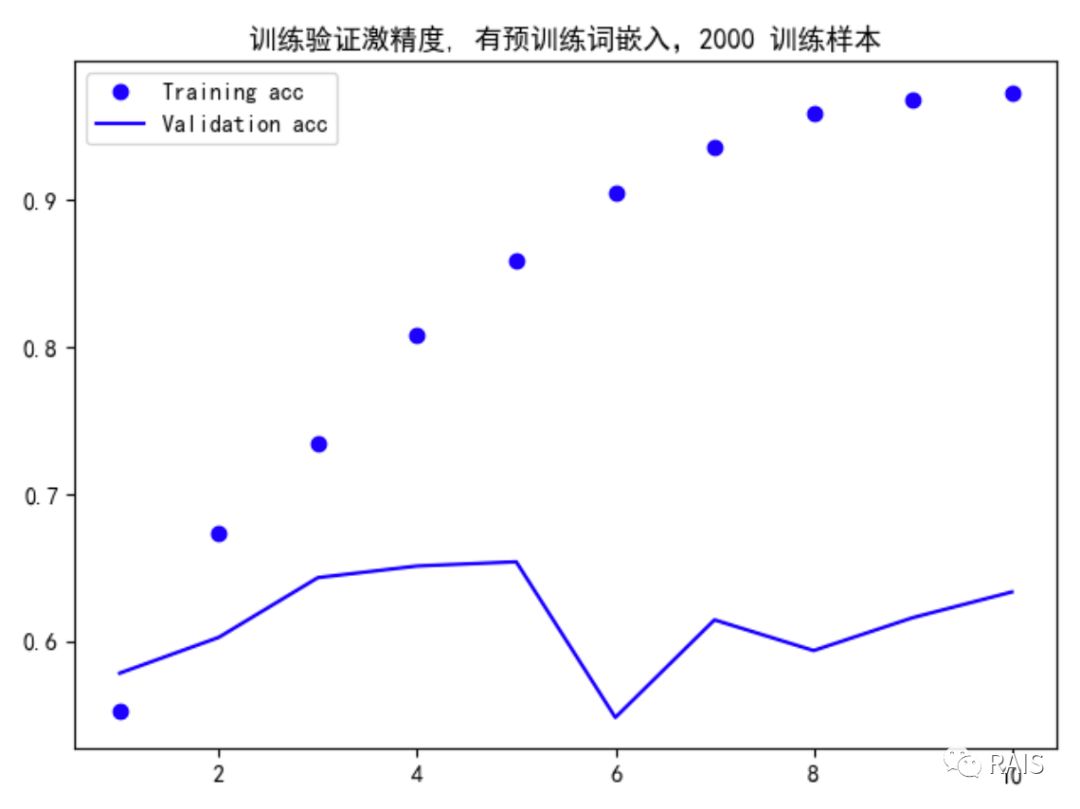
This accuracy is much higher. Pursuing this level is not our goal. Our goal is to show that word embedding is effective. We have achieved this goal. Okay, let's take a look at the code next:
#!/usr/bin/env python3 import os import time import matplotlib.pyplot as plt import numpy as np from keras.layers import Embedding, Flatten, Dense from keras.models import Sequential from keras.preprocessing.sequence import pad_sequences from keras.preprocessing.text import Tokenizer def deal(): # http://mng.bz/0tIo imdb_dir = '/Users/renyuzhuo/Documents/PycharmProjects/Data/aclImdb' train_dir = os.path.join(imdb_dir, 'train') labels = [] texts = [] # Read out all the data for label_type in ['neg', 'pos']: dir_name = os.path.join(train_dir, label_type) for fname in os.listdir(dir_name): if fname[-4:] == '.txt': f = open(os.path.join(dir_name, fname)) texts.append(f.read()) f.close() if label_type == 'neg': labels.append(0) else: labels.append(1) # Segmentation of all data # Up to 100 words per comment maxlen = 100 # Number of training samples training_samples = 200 # Verify number of samples validation_samples = 10000 # Take only the 10,000 most common words max_words = 10000 # Participle, as described earlier tokenizer = Tokenizer(num_words=max_words) tokenizer.fit_on_texts(texts) sequences = tokenizer.texts_to_sequences(texts) word_index = tokenizer.word_index print('Found %s unique tokens.' % len(word_index)) # Converting a list of integers to a tensor data = pad_sequences(sequences, maxlen=maxlen) labels = np.asarray(labels) print('Shape of data tensor:', data.shape) print('Shape of label tensor:', labels.shape) # Disrupt data indices = np.arange(data.shape[0]) np.random.shuffle(indices) data = data[indices] labels = labels[indices] # Cut into training and validation sets x_train = data[:training_samples] y_train = labels[:training_samples] x_val = data[training_samples: training_samples + validation_samples] y_val = labels[training_samples: training_samples + validation_samples] # Download Word Embedded Data at https: //nlp.stanford.edu/projects/glove glove_dir = '/Users/renyuzhuo/Documents/PycharmProjects/Data/glove.6B' embeddings_index = {} f = open(os.path.join(glove_dir, 'glove.6B.100d.txt')) # Building an index of a word and its x-vector representation for line in f: values = line.split() word = values[0] coefs = np.asarray(values[1:], dtype='float32') embeddings_index[word] = coefs f.close() print('Found %s word vectors.' % len(embeddings_index)) # Building Embedded Matrix embedding_dim = 100 embedding_matrix = np.zeros((max_words, embedding_dim)) for word, i in word_index.items(): if i < max_words: embedding_vector = embeddings_index.get(word) if embedding_vector is not None: embedding_matrix[i] = embedding_vector # Building models model = Sequential() model.add(Embedding(max_words, embedding_dim, input_length=maxlen)) model.add(Flatten()) model.add(Dense(32, activation='relu')) model.add(Dense(1, activation='sigmoid')) model.summary() # Load GloVe into the Embedding layer and make it untrainable model.layers[0].set_weights([embedding_matrix]) model.layers[0].trainable = False # Training model model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['acc']) history = model.fit(x_train, y_train, epochs=10, batch_size=32, validation_data=(x_val, y_val)) model.save_weights('pre_trained_glove_model.h5') # Drawing acc = history.history['acc'] val_acc = history.history['val_acc'] loss = history.history['loss'] val_loss = history.history['val_loss'] epochs = range(1, len(acc) + 1) plt.plot(epochs, acc, 'bo', label='Training acc') plt.plot(epochs, val_acc, 'b', label='Validation acc') plt.title('Training and validation accuracy') plt.legend() plt.show() plt.figure() plt.plot(epochs, loss, 'bo', label='Training loss') plt.plot(epochs, val_loss, 'b', label='Validation loss') plt.title('Training and validation loss') plt.legend() plt.show() if __name__ == "__main__": time_start = time.time() deal() time_end = time.time() print('Time Used: ', time_end - time_start)
>This article was first published under the Public Number: RAIS