1, Aggregate query
1. Aggregate function
Common aggregate functions can be used to count the total number and calculate the average value. Common aggregate functions include:
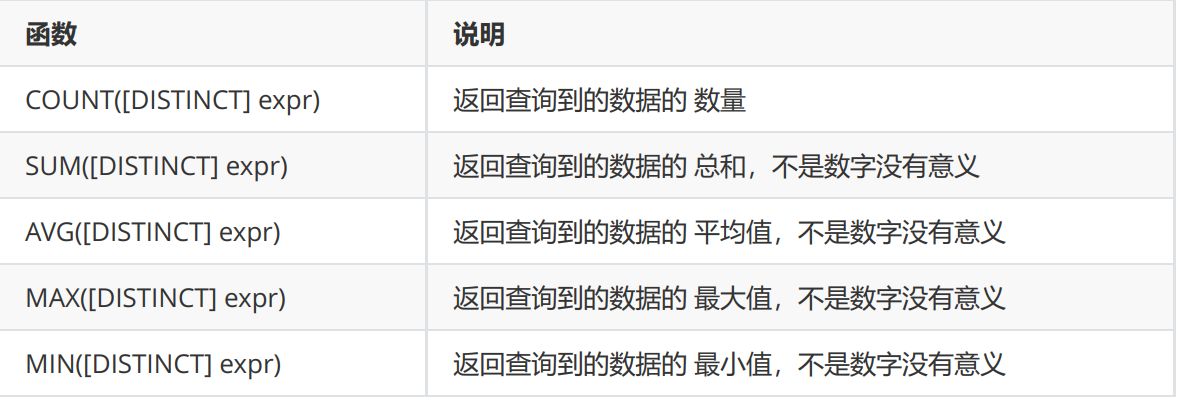
These functions are relatively simple and can be understood through several SQL statements
- count
-- How many students are there in the table select count(*) from student; -- Ask how many schools provide qq mailbox select count(qq_mail) from student;
Note: there must be no spaces between count(), and null will not be recorded in the final result
The count function is equivalent to executing select * first, and then counting the quantity according to the result put back by select *
- sum
-- Total score of Statistical Mathematics SELECT SUM(math) FROM exam_result; -- fail, < 60 Total score of, no result, return NULL SELECT SUM(math) FROM exam_result WHERE math < 60;
- avg
-- Statistical average total score SELECT AVG(chinese + math + english) Average total score FROM exam_result;
- max
-- Return to the highest score in English SELECT MAX(english) FROM exam_result;
- min
-- return > 70 The lowest score in mathematics above SELECT MIN(math) FROM exam_result WHERE math > 70;
2.GROUP BY clause
Use the GROUP BY clause in SELECT to group and query the specified columns. Need to meet: when using GROUP BY for grouping query, the field specified in SELECT must be "grouping by field". If other fields want to appear in SELECT, they must be included in the aggregation function
-- Create table
create table emp (
id int primary key auto_increment,
name varchar(20) not null,
role varchar(20) not null,
salary numeric(11,2)
);
-- insert data
insert into emp(name,role,salary) values
('Sun WuKong','staff',3300.5),
('Zhu Bajie','staff',4000),
('Monk Sha','staff',3700.50),
('Tang Monk','executive director',6000),
('White dragon horse','executive director',5800),
('Lao Wang','boss',10000.88);
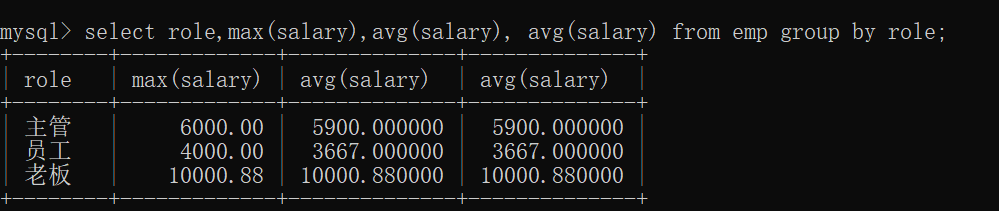
Use group by to group role s and find the maximum wage, minimum wage and average wage of each position
select role,max(salary),avg(salary), avg(salary) from emp group by role;
3.HAVING
After grouping in the GROUP BY clause, you need to filter the grouping results conditionally.
Note: conditional filtering in where is used to filter the original data (data before aggregation) in the current table, but now we expect to filter the aggregated data
For filtering the aggregated data, the having clause should be used, and the syntax is similar to where.
Code example:
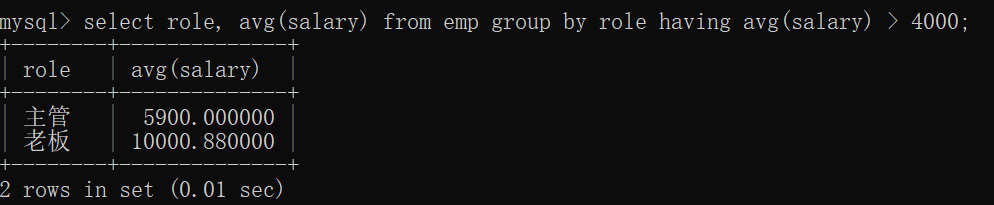
We want to query a position with an average salary greater than 4000 and group it by position.
select role, avg(salary) from emp group by role having avg(salary) > 4000;
where can also be matched with group by, but the matching is determined according to the needs
If the condition in the requirement is to filter the data before aggregation, use where
If the condition in the requirement is to filter the aggregated data, use having
Code example:
We need to query a position with an average salary of more than 4000 and exclude Tang monk. If we use the where condition to filter Tang monk, Tang monk will not be divided into any group
select role, avg (salary) from emp where name != 'Tang Monk' group by role having avg(salary) > 4000;

2, Joint query
In actual development, data often comes from different tables, so multi table joint query is required. Multi table query is to take the Cartesian product of the data of multiple tables, that is, to obtain the arrangement and combination of two tables and list all the possible data combinations in the two tables. But a lot of data is meaningless.
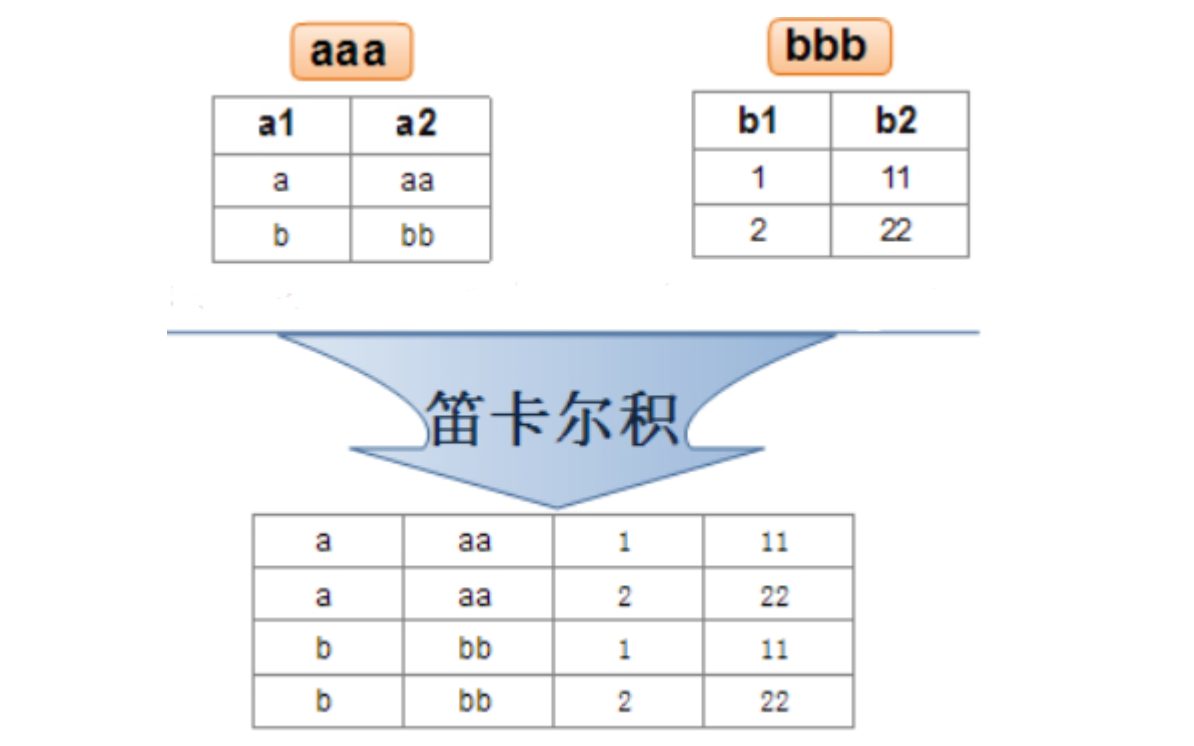
There are two main ways to calculate Cartesian product (multi table query) in SQL
1. Directly select from table 1, table 2
2.select from table 1 join table 2 on condition... Join table 3 on condition
Note: in SQL, if the field names of two tables conflict, you can specify the fields of a table by clicking, which is similar to the member access operator in Java.
Table name. Field name,
The same can be done
Database name. Table name. Field name
Code example:
Create a class table, student table, curriculum, and score table.
drop table if exists classes;
drop table if exists student;
drop table if exists course;
drop table if exists score;
create table classes (id int primary key auto_increment, name varchar(20), `desc` varchar(100));
create table student (id int primary key auto_increment, sn varchar(20), name varchar(20), qq_mail varchar(20) ,
classes_id int);
create table course(id int primary key auto_increment, name varchar(20));
create table score(score decimal(3, 1), student_id int, course_id int);
insert into classes(name, `desc`) values
('Class 1, grade 2019, computer department', 'Learned the principle of computer C and Java Language, data structure and algorithm'),
('Class 3, grade 2019, Chinese Department','I studied Chinese traditional literature'),
('Class 5, automation level 2019','Learned mechanical automation');
insert into student(sn, name, qq_mail, classes_id) values
('09982','Black Whirlwind Li Kui','xuanfeng@qq.com',1),
('00835','Song Jiang',null,1),
('00391','Guan Yu',null,1),
('00031','Xu Xian','xuxian@qq.com',1),
('00054','Fei Zhang',null,1),
('51234','Sun WuKong','say@qq.com',2),
('83223','Cao Cao',null,2),
('09527','Monk Sha','foreigner@qq.com',2);
insert into course(name) values
('Java'),('Chinese traditional culture'),('Computer principle'),('language'),('Higher order mathematics'),('english');
insert into score(score, student_id, course_id) values
-- Li Kui
(70.5, 1, 1),(98.5, 1, 3),(33, 1, 5),(98, 1, 6),
-- Song Jiang
(60, 2, 1),(59.5, 2, 5),
-- Guan Yu
(33, 3, 1),(68, 3, 3),(99, 3, 5),
-- Xu Xian
(67, 4, 1),(23, 4, 3),(56, 4, 5),(72, 4, 6),
-- Fei Zhang
(81, 5, 1),(37, 5, 5),
-- Sun WuKong
(56, 6, 2),(43, 6, 4),(79, 6, 6),
-- Cao Cao
(80, 7, 2),(92, 7, 6);
A total of 4 tables were created
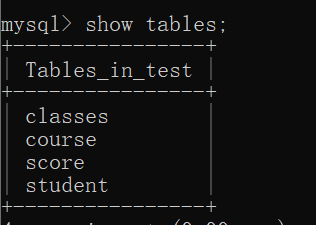
The score table is the middle table between the curriculum table and the student table
Then perform Cartesian product (multi table query)
select * from classes,course,score,student;
More than 2000 lines of data are obtained, but the Cartesian product is a brainless arrangement and combination, and most of the data here is meaningless.

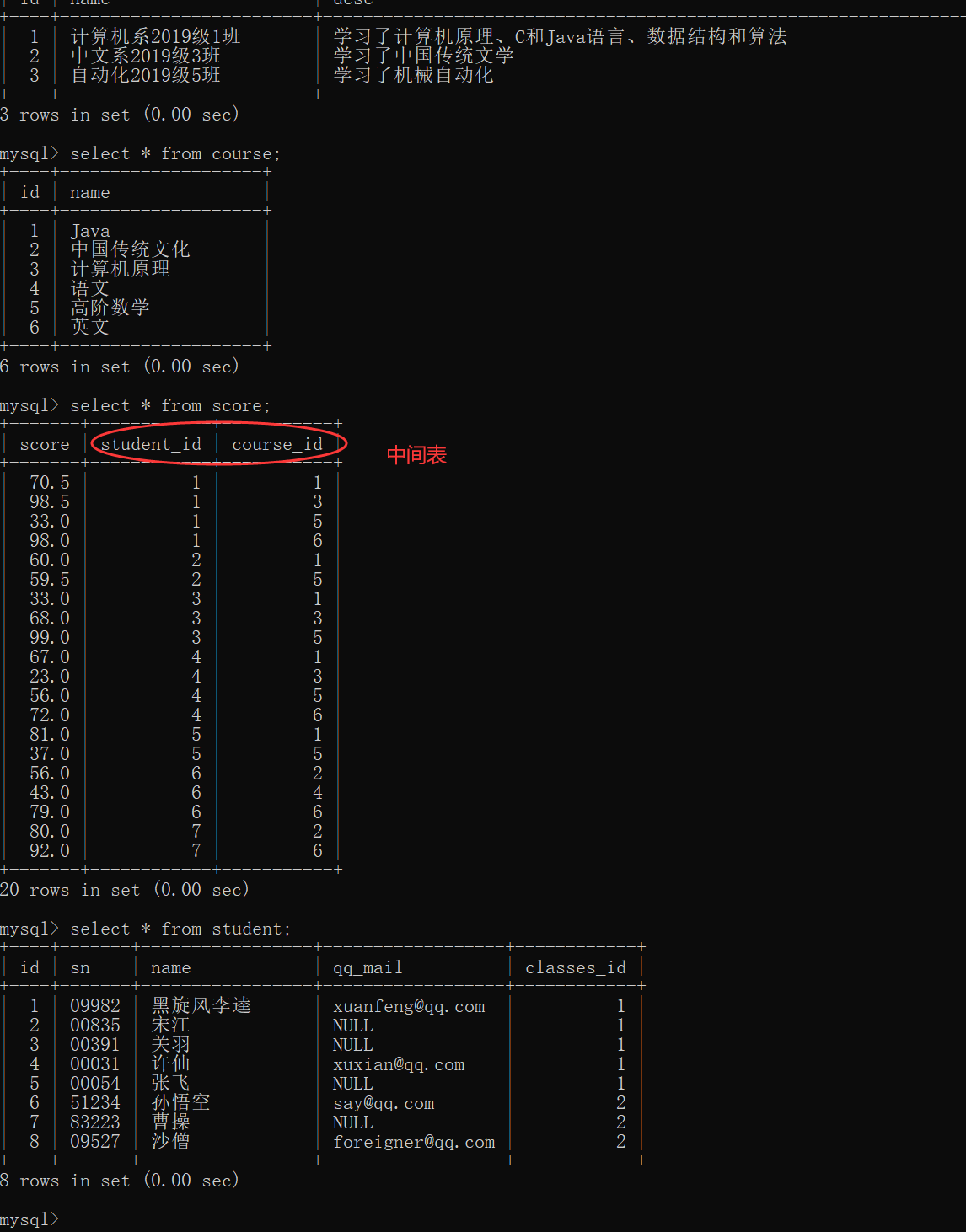
We need to filter the data to select the students in the score table_ Data whose id is equal to the id in the student table
select * from student, score where student.id = score.student_id;
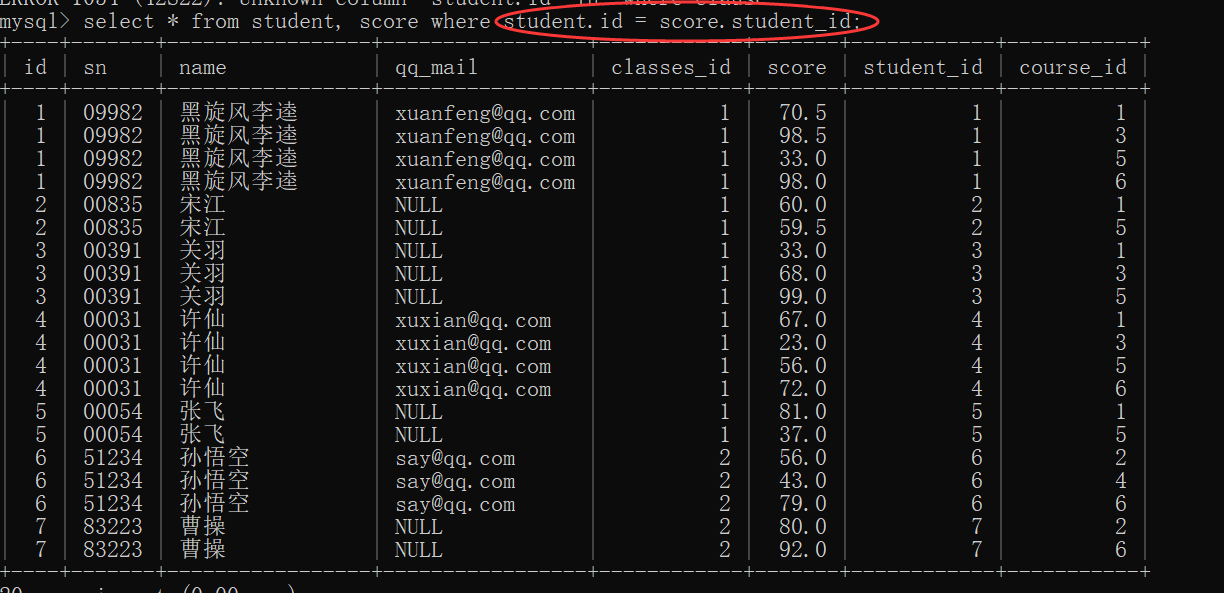
Suppose we want to check the scores of each student
It is filtered by the student id and the student id in the score table plus the course id and the course id in the score table are equal.
select student.name,course.name,score.score from student, course,score where student.id = score.student_id and course.id = score.course_id;
join on
Suppose we want to inquire about Xu Xian's grades
select student.name,score.score,score.course_id from student,score where student.id = score.student_id and name = 'Xu Xian';
We can also achieve the same effect through join on
select student.name,score.score,score.course_id from student join score on student.id = score.student_id and name = 'Xu Xian'
Since there is no essential difference between the two writing methods, why are there two writing methods?
It's just that there's no difference in the current list
However, in other scenarios, join on may be essentially different from the writing of multiple tables from where.
from multiple tables, where, is just an internal connection
join on can represent not only inner connection, but also left outer connection and right outer connection
1. Internal connection
Syntax:
select field from Table 1 alias 1 [inner] join Table 2 alias 2 on Connection conditions and Other conditions; select field from Table 1 alias 1,Table 2 alias 2 where Connection conditions and Other conditions
We create student tables and score tables
create table student (
id int primary key auto_increment,
name varchar(20));
create table score (
studentId int,
score int);
insert into student values
(null,'Zhang San'),
(null,'Li Si'),
(null,'Wang Wu');
insert into score values(1,90);
insert into score values(2,80);
insert into score values(4,70);

Query students' grades
select student.name,score.score from student join score on student.id = score.studentId;
Inner join is actually taking out the intersection of data in two tables

2. External connection
The external connection is divided into left external connection and right external connection. If the table on the left is completely displayed in the joint query, we say it is a left outer connection; The table on the right shows the right outer connection completely
Syntax:
-- Left outer connection, fully shown in Table 1 select Field name from Table name 1 left join Table name 2 on Connection conditions; -- Right outer connection, fully shown in Table 2 select field from Table name 1 right join Table name 2 on Connection conditions;
Left outer connection: the final query result is dominated by the table on the left of the join, and all the information of the table on the left will be reflected as much as possible
select student.name,score.score from student left join score on student.id = score.studentId;

Right outer connection: and left outer connection types, which are mainly based on the table on the join side, and reflect every information on the right as much as possible
select student.name,score.score from student right join score on student.id = score.studentId;

Global external connection: MySQL does not support global external connection
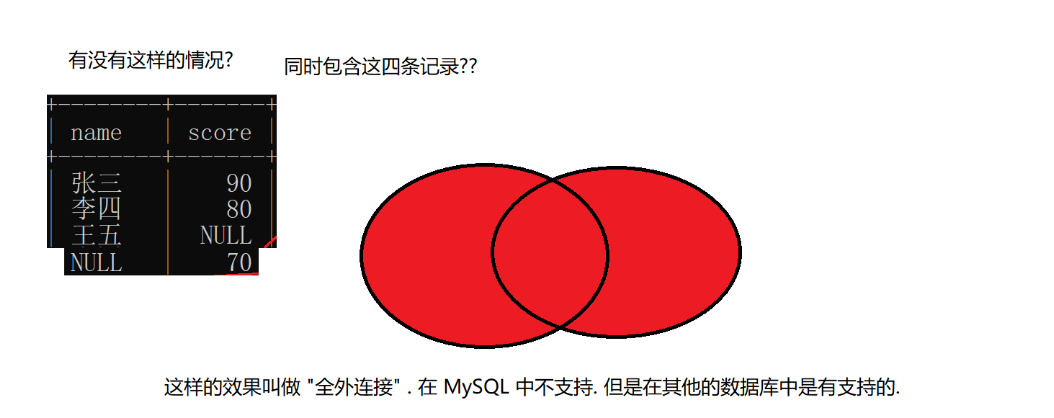
3. Self connection
Self connection is a table, and you do Cartesian product with yourself.
SQL is convenient for column to column comparison, but it is not convenient for row to row comparison.
For example, in the example of the score table above, the scores of different subjects are displayed in rows
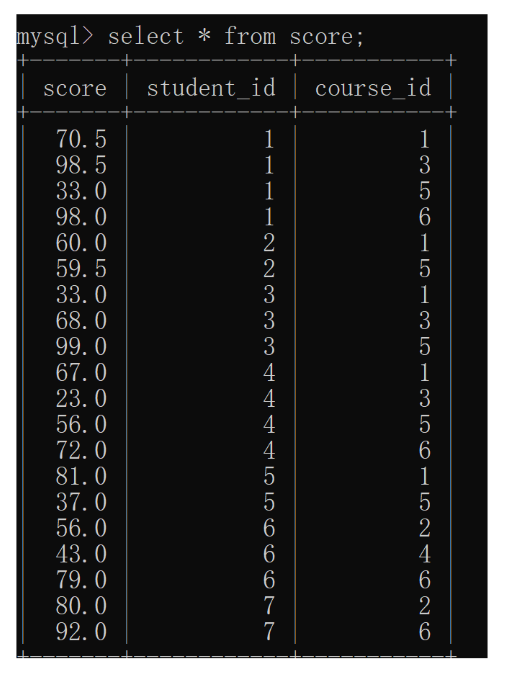
Show all "computer theory" scores higher than "Java" scores
For this row and row comparison, it is difficult for us to convert it into column and column comparison, which is to use self connection for conversion.
During self connection, you need to alias the table first, otherwise an error will be reported. as can be omitted
select * from score as s1,score as s2;
Plus student_id conditions, filter the data, and expect to put the information of the same student on the left and right sides respectively
select * from score as s1, score as s2 where s1.student_id = s2.student_id and s1.course_id = 1 and s2.course_id = 3;
last
select * from score as s1, score as s2 where s1.student_id = s2.student_id and s1.course_id = 1 and s2.course_id = 3
and s1.score < s2.score;

3, Subquery
Subquery refers to the select statement embedded in other sql statements, also known as nested query
- Single line sub query: first execute a query, which returns a record, and use the returned result as the condition of another query for the final query.
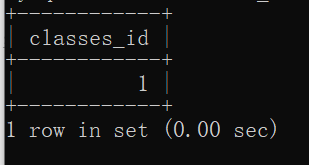
Code example: query Zhang Fei's classmates
If sub query is not used
select classes_id from student where name = 'Fei Zhang';
select name from student where classes_id = 1;
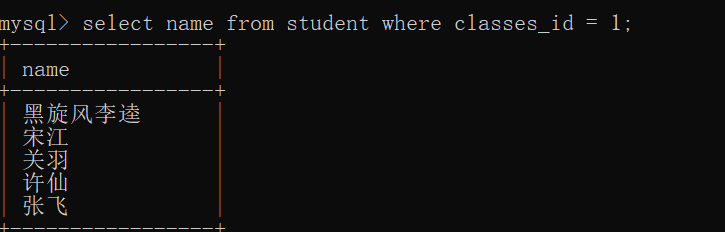
If a subquery is used, only one code is required
select name,classes_id from student where classes_id=(select classes_id from student where name = 'Fei Zhang');

- Multi row sub query: the data returned by the sub query is not only one, but also multiple records
When we want to query the course information of Chinese or Java, if we use multiple SQL
select id from course where name = 'language' or name = 'Java';
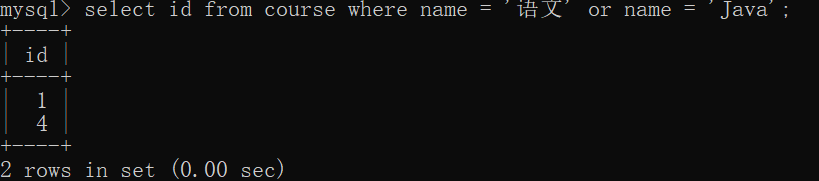
select * from score where course_id = 1 or course_id = 4;
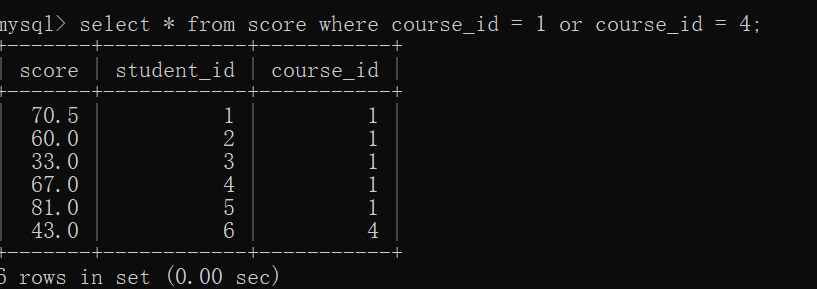
The same effect can be achieved using subqueries
select * from score where course_id in (
select id from course where name = 'language' or name = 'Java');
EXISTS keyword
You can also use the exists keyword to perform a sub query, which is also the case where multiple records are returned by the corresponding sub query
select * from score where exists (
select score.course_id from course where
(name = 'language' or name = 'Java') and
course.id = score.course_id);
The same effect can be achieved
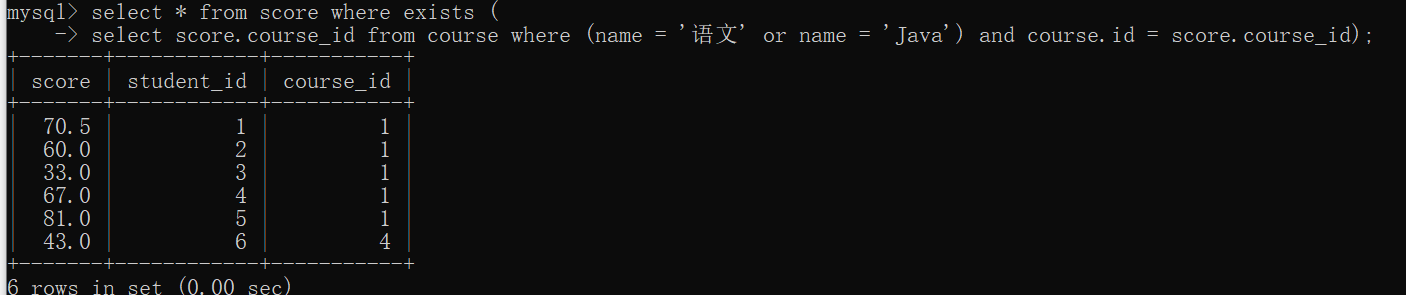
exists working process:
To execute the outer query first, you need to traverse each record in the table (traverse each record in the score table)
Take the current record and execute the sub query.
In this method, the number of sub queries executed is the same as the number of rows in the outer table (the execution efficiency is quite low, and the number of SQL executions is too many)
In the previous in writing method, the sub query is executed only once (the execution efficiency is high, but it takes more memory, and the results of the sub query will be put into memory)
If the outer layer query table is large and the inner layer query table is small, it is suitable to use in (if the inner layer table is small, the memory consumption is less)
If the outer layer query table is very small and the inner layer query table is very large, it is suitable to use exists (there are too many results from the inner layer query and there is no memory, so in cannot be used at this time)
Of course, if the inner and outer layers are large, don't use them. Honestly split them into multiple sentences
4, Joint query
In practical application, in order to merge the execution results of multiple select ions, you can use the set operators UNION, UNION all. When using UNION and UNION all, the fields in the result set of the previous and subsequent queries need to be consistent
union: duplicate rows will be de duplicated
union all: duplicate rows will not be de duplicated
- union
Query courses with id less than 3 or name "English"
select * from course where id<3 union select * from course where name='english'; -- Or use or To achieve select * from course where id<3 or name='english';
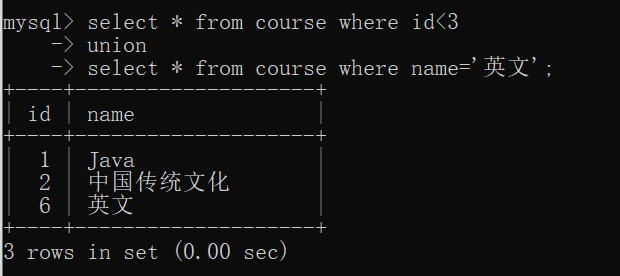
- union all
If the query id is less than 3 or the course name is "Java", the repetition in the result set will not be removed
select * from course where id<3
union all
select * from course where name='Java';
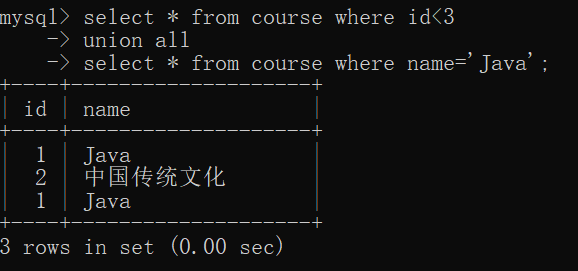
The main advantage of union over or is that it can merge data across multiple tables
summary
- When writing complex SQL, try not to put one in place. It's best to split it into multiple SQL
- In actual development, sub queries shall be used as little as possible. Too many dolls will have poor readability
- The efficiency of multi table query is low. If there are too many tables, the efficiency is very low.