MongoDB Index
Why use index?
Assuming there is a book, you want to see what Chapter 6, Section 6, says, and what you will do, the average person must go to the catalogue, find the corresponding pages of this section, and then turn to this page. This is the catalog index, which helps readers quickly find the chapters they want. In databases, we also have indexes, which, of course, can help us improve the efficiency of our queries just as we do in turning over books. Indexing, like catalog, reduces the workload of computer, is very practical for databases with more table records, and can greatly improve the speed of query. Otherwise, if there is no index, the computer will scan one by one, scanning all records every time, wasting a lot of cpu time.
For query convenience, we create a collection of 500,000 pieces of data.
> for(var i=0;i<500000;i++){db.nums.insert({name:"name"+i,age:i})} WriteResult({ "nInserted" : 1 })
createIndex() method: MongoDB uses the createIndex() method to create an index.
Note that the index method created before version 3.0.0 is db.collection.ensureIndex(), and later versions use the db.collection.createIndex() method. GuaranteeIndex () is also available, but only the alias of createIndex().
Syntax: The basic grammatical format of the createIndex() method is as follows:
>db.collection.createIndex(keys, options)
The Key value in the grammar is the index field you want to create, 1 is to create the index in ascending order, if you want to create the index in descending order, you can specify - 1.
Example:
1. First, before creating the index, we need to find the nums collection with age 39999.
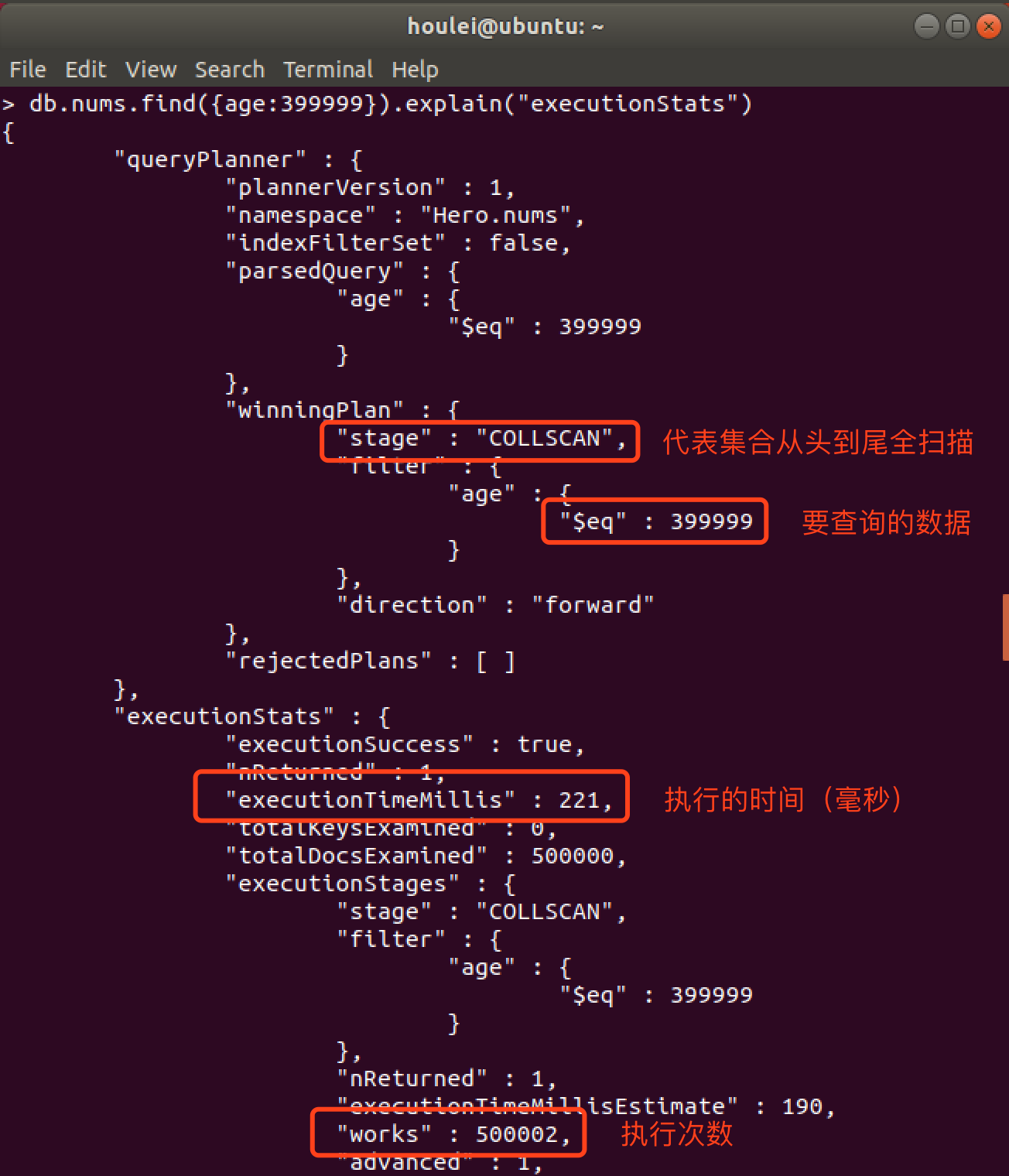
2. Query age 39999 after index creation
Create an index
> db.nums.createIndex({age:1})
{
"createdCollectionAutomatically" : false,
"numIndexesBefore" : 1,
"numIndexesAfter" : 2,
"ok" : 1
}
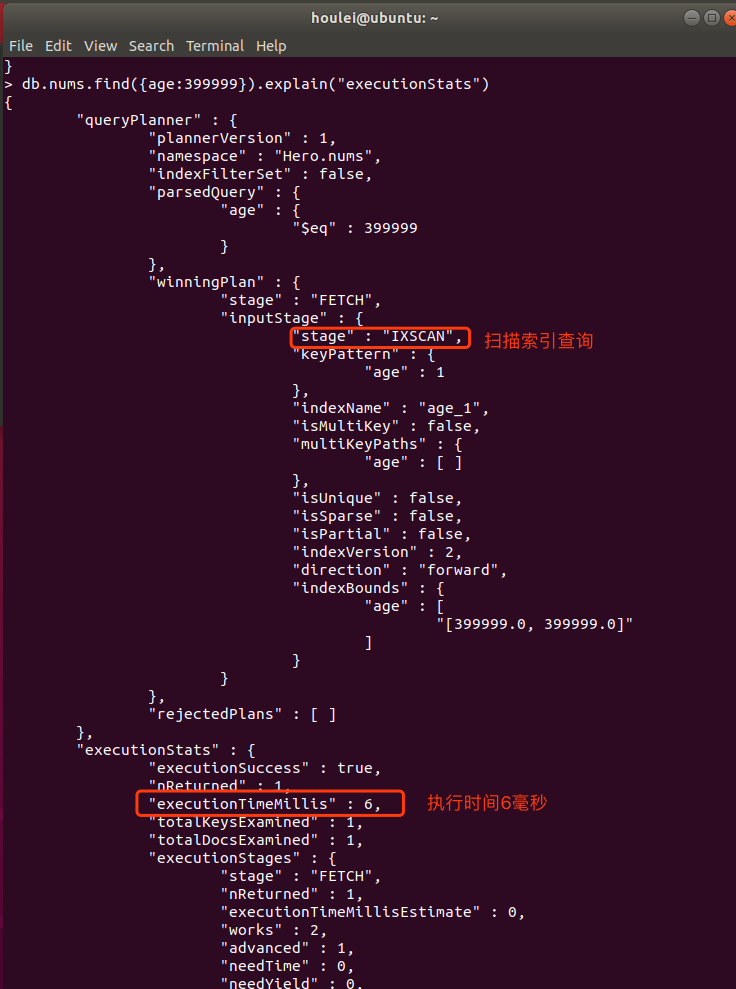
By comparing the two execution times, we can clearly see that the query is faster, the more data, the more obvious it is.
createIndex() receives the optional parameters. The list of optional parameters is as follows:

MongoDB aggregation
Aggregate in MongoDB is mainly used to process data (such as statistical average, sum, etc.) and return the calculated data results. It's a bit like count(*) in sql statements.
aggregate() method: aggregate() is used for aggregate() in MongoDB.
Syntax: The basic grammatical format of the aggregate() method is as follows:
db. Collection name. aggregate([{pipe: {expression}])
The Conduit
- Pipelines are commonly used in Unix and Linux to input the output of the current command as the next command
ps ajx | grep mongo
- In mongodb, the pipeline has the same function. After the document is processed, the pipeline is used for the next processing.
- Common Pipeline
- $group: Grouping documents in a collection for statistical results
- match: filter data and output only qualified documents
- $project: Modify the structure of the input document, such as renaming, adding, deleting fields, and creating calculation results
- sort: sort the input documents and output them
- $limit: Limit the number of documents returned by the aggregation pipeline
- Skip: skip a specified number of documents and return the remaining documents
- unwind: Split fields of array type
- $geoNear: Outputs ordered documents close to a geographic location.
Expressions: Processing input documents and outputting them
Expression:'$column name'
Common expressions
- $sum: Calculates the total, $sum:1 and count represent counts
- $avg: calculated average
- $min: Get the minimum
- $max: Get the maximum
- $push: Insert values into an array in the result document
- $first: Get the first document data according to the order of resource documents
- Last: Get the last document data according to the order of resource documents
3. $group
- Grouping documents in a collection for statistical results
- _ id represents the basis for grouping, using a field format of'$field'
For example, the data in the heros table is as follows
> db.heros.find().pretty() { "_id" : ObjectId("5d2e0647614bec7ca4687792"), "h_name" : "Offspring", "h_skill" : "The sword of punishment", "h_attack" : 1000, "h_blood" : 800, "h_type" : "Shooter" } { "_id" : ObjectId("5d2e0685614bec7ca4687793"), "h_name" : "Li Bai", "h_skill" : "Qinglian Jianxian", "h_attack" : 1400, "h_blood" : 900, "h_type" : "Assassin" } { "_id" : ObjectId("5d2e06d6614bec7ca4687794"), "h_name" : "Hanxin", "h_skill" : "A state scholar of no equal", "h_attack" : 1300, "h_blood" : 850, "h_type" : "Assassin" } { "_id" : ObjectId("5d2e0720614bec7ca4687795"), "h_name" : "Da Ji", "h_skill" : "Queen worship", "h_attack" : 1200, "h_blood" : 750, "h_type" : "Master" }
For example, according to the type of hero grouping, the number of Statistics
> db.heros.aggregate([{$group:{_id:"$h_type",counter:{$sum:1}}}])
{ "_id" : "Assassin", "counter" : 2 }
{ "_id" : "Master", "counter" : 1 }
{ "_id" : "Shooter", "counter" : 1 }
>
Group by null: Divide all documents in a collection into a group
For example, seek hero's attack power and average blood volume
> db.heros.aggregate([{$group:{_id:null,h_attacks:{$sum:"$h_attack"},avgh_blood:{$avg:"$h_blood"}}}])
{ "_id" : null, "h_attacks" : 4900, "avgh_blood" : 825 }
>
Perspective data
Query only hero types and names
> db.heros.aggregate([{$group:{_id:"$h_type",name:{$push:"$h_name"}}}])
{ "_id" : "Assassin", "name" : [ "Li Bai", "Hanxin" ] }
{ "_id" : "Master", "name" : [ "Da Ji" ] }
{ "_id" : "Shooter", "name" : [ "Offspring" ] }
>
- Document content can be added to an array of result sets using $$ROOT, as follows
> db.heros.aggregate([{$group:{_id:"h_type",name:{$push:"$$ROOT"}}}]).pretty()
{
"_id" : "h_type",
"name" : [
{
"_id" : ObjectId("5d2e0647614bec7ca4687792"),
"h_name" : "Offspring",
"h_skill" : "The sword of punishment",
"h_attack" : 1000,
"h_blood" : 800,
"h_type" : "Shooter"
},
{
"_id" : ObjectId("5d2e0685614bec7ca4687793"),
"h_name" : "Li Bai",
"h_skill" : "Qinglian Jianxian",
"h_attack" : 1400,
"h_blood" : 900,
"h_type" : "Assassin"
},
{
"_id" : ObjectId("5d2e06d6614bec7ca4687794"),
"h_name" : "Hanxin",
"h_skill" : "A state scholar of no equal",
"h_attack" : 1300,
"h_blood" : 850,
"h_type" : "Assassin"
},
{
"_id" : ObjectId("5d2e0720614bec7ca4687795"),
"h_name" : "Da Ji",
"h_skill" : "Queen worship",
"h_attack" : 1200,
"h_blood" : 750,
"h_type" : "Master"
}
]
}
>
4. $match
- Used to filter data and output only qualified documents
- Standard query operations using MongoDB
For example, query attack power is greater than 1200
> db.heros.aggregate([{$match:{"h_attack":{$gt:1200}}}])
{ "_id" : ObjectId("5d2e0685614bec7ca4687793"), "h_name" : "Li Bai", "h_skill" : "Qinglian Jianxian", "h_attack" : 1400, "h_blood" : 900, "h_type" : "Assassin" }
{ "_id" : ObjectId("5d2e06d6614bec7ca4687794"), "h_name" : "Hanxin", "h_skill" : "A state scholar of no equal", "h_attack" : 1300, "h_blood" : 850, "h_type" : "Assassin" }
>
V. $project
- Modify the structure of the input document, such as renaming, adding, deleting fields, and creating calculation results
- The output is similar to the projection effect.
> db.heros.aggregate([{$project:{_id:0,h_name:1,h_skill:1}}])
{ "h_name" : "Offspring", "h_skill" : "The sword of punishment" }
{ "h_name" : "Li Bai", "h_skill" : "Qinglian Jianxian" }
{ "h_name" : "Hanxin", "h_skill" : "A state scholar of no equal" }
{ "h_name" : "Da Ji", "h_skill" : "Queen worship" }
>
6. $unwind
- Divide an array type field in a document into multiple fields, each containing a value in the array
Grammar 1
Split a field value
db. Collection name. aggregate([{$unwind:'$field name'}])
For example:
db.t2.insert({_id:1,item:'t-shirt',size:['S','M','L']})
Query:
> db.t2.aggregate([{$unwind:'$size'}])
{ "_id" : 1, "item" : "t-shirt", "size" : "S" }
{ "_id" : 1, "item" : "t-shirt", "size" : "M" }
{ "_id" : 1, "item" : "t-shirt", "size" : "L" }
>
Grammar 2
- Split a field value
- Handling empty arrays, non-arrays, no fields, null cases
db.inventory.aggregate([{ $unwind:{ path:'$Field name', preserveNullAndEmptyArrays:<boolean>#Prevent data loss } }])
- Constructing data
db.t3.insert([ { "_id" : 1, "item" : "a", "size": [ "S", "M", "L"] }, { "_id" : 2, "item" : "b", "size" : [ ] }, { "_id" : 3, "item" : "c", "size": "M" }, { "_id" : 4, "item" : "d" }, { "_id" : 5, "item" : "e", "size" : null } ])
- Use grammar 1 to query
> db.t3.find().pretty() { "_id" : 1, "item" : "a", "size" : [ "S", "M", "L" ] } { "_id" : 2, "item" : "b", "size" : [ ] } { "_id" : 3, "item" : "c", "size" : "M" } { "_id" : 4, "item" : "d" } { "_id" : 5, "item" : "e", "size" : null } > db.t3.aggregate([{$unwind:'$size'}]) { "_id" : 1, "item" : "a", "size" : "S" } { "_id" : 1, "item" : "a", "size" : "M" } { "_id" : 1, "item" : "a", "size" : "L" } { "_id" : 3, "item" : "c", "size" : "M" } >
- Looking at the query results, we found that documents with empty arrays, no fields and null were discarded.
Using Syntax 2 queries does not discard empty arrays, no fields, null documents
> db.t3.aggregate([{$unwind:{path:'$sizes',preserveNullAndEmptyArrays:true}}])
{ "_id" : 1, "item" : "a", "size" : [ "S", "M", "L" ] }
{ "_id" : 2, "item" : "b", "size" : [ ] }
{ "_id" : 3, "item" : "c", "size" : "M" }
{ "_id" : 4, "item" : "d" }
{ "_id" : 5, "item" : "e", "size" : null }
>