Introduction to character sets and comparison rules
Character set introduction
We know that only binary data can be stored in the computer, so how to store strings? Of course, it is necessary to establish the mapping relationship between characters and binary data. To establish this relationship, at least two things should be clear:
-
What characters do you want to map to binary data?
That is to define the character range clearly.
-
How?
The process of mapping a character to binary data is also called encoding, and the process of mapping a binary data to a character is called decoding.
People abstract the concept of a character set to describe the coding rules of a certain character range. For example, we define a character set named xiaohaizi. Its character range and coding rules are as follows:
-
Contains characters' a ',' B ',' a ',' B '.
-
The coding rules are as follows:
One byte is used to encode one character, and the mapping relationship between character and byte is as follows:
'a' -> 00000001 (Hex: 0 x01) 'b' -> 00000010 (Hex: 0 x02) 'A' -> 00000011 (Hex: 0 x03) 'B' -> 00000100 (Hex: 0 x04)
With the xiaohaizi character set, we can represent some strings in binary form. Below are the binary representations of some strings encoded by the xiaohaizi character set:
'bA' -> 0000001000000011 (Hex: 0 x0203) 'baB' -> 000000100000000100000100 (Hex: 0 x020104) 'cd' -> Cannot represent, character set xiaohaizi Does not contain characters'c'and'd'
Introduction to comparison rules
After we have determined the range of characters represented by xiaohaizi character set and coding rules, how to compare the sizes of two characters? The easiest thing to think of is to directly compare the binary codes corresponding to these two characters. For example, the code of character 'a' is 0x01 and the code of character 'b' is 0x02, so 'a' is less than 'b'. This simple comparison rule can also be called binary comparison rule, which is called binary collation in English.
Binary comparison rules are simple, but sometimes they do not meet practical needs. For example, in many cases, we are case insensitive for English characters, that is, 'a' and 'a' are equal. In this case, we can't simply and roughly use binary comparison rules. At this time, we can specify the comparison rules as follows:
- Converts two characters with different case to uppercase or lowercase.
- Then compare the binary data corresponding to these two characters.
This is a slightly more complex comparison rule, but there are more than English characters in real life. For example, there are tens of thousands of Chinese characters. For a certain character set, there are many rules for comparing the size of two characters, that is, there can be many comparison rules for the same character set, We will introduce various character sets used in real life and some of their comparison rules later.
Some important character sets
Unfortunately, the world is too big. Different people have developed many character sets, which may represent different character ranges and coding rules. Let's take a look at some common character sets:
-
ASCII character set
A total of 128 characters are included, including spaces, punctuation, numbers, uppercase and lowercase letters and some invisible characters. Since there are only 128 characters in total, one byte can be used for encoding. Let's look at the encoding methods of some characters:
'L' -> 01001100(Hex: 0 x4C,Decimal: 76) 'M' -> 01001101(Hex: 0 x4D,Decimal: 77)
-
ISO 8859-1 character set
A total of 256 characters are included. Based on the ASCII character set, 128 common characters in Western Europe (including the letters of Germany and France) are expanded. One byte can also be used for coding. This character set also has an alias latin1.
-
GB2312 character set
It contains Chinese characters, Latin letters, Greek letters, Japanese Hiragana and katakana letters, and Russian Cyrillic letters. Including 6763 Chinese characters and 682 other characters and symbols. At the same time, this character set is compatible with ASCII character set, so it seems strange in coding mode:
- If the character is in the ASCII character set, 1-byte encoding is used.
- Otherwise, use 2-byte encoding.
This encoding method, which may represent the number of bytes required for a character, is called variable length encoding. For example, the string 'love u', in which 'love' needs to be encoded with 2 bytes. The encoded hexadecimal is 0xB0AE, and 'U' needs to be encoded with 1 byte. The encoded hexadecimal is 0x75, so it is 0xB0AE75.
Tips: How can we tell whether a byte represents a single character or a part of a character? Don't forget`ASCII`The character set contains only 128 characters, using 0~127 It can represent all characters, so if a byte is at 0~127 Within, it means that one byte represents a single character, otherwise two bytes represent a single character.
-
GBK character set
The GBK character set only expands the GB2312 character set in the included character range, and the coding method is compatible with GB2312.
-
utf8 character set
It contains all the characters that can be thought of on earth, and it is still expanding. This character set is compatible with ASCII character set and adopts variable length encoding. Encoding a character requires 1 ~ 4 bytes, for example:
'L' -> 01001100(Hex: 0 x4C) 'ah' -> 111001011001010110001010(Hex: 0 xE5958A)
Tips: Actually, to be exact, utf8 just Unicode A coding scheme for character sets, Unicode The character set can take utf8,utf16,utf32 These coding schemes, utf8 Use 1~4 One byte encodes one character, utf16 Encode a character with 2 or 4 bytes, utf32 Encode a character with 4 bytes. More detailed Unicode And the knowledge of its coding scheme is not the focus of this book. Please check it online~ MySQL Does not distinguish between the concept of character set and coding scheme, so when you nag later utf8,utf16,utf32 Are treated as a character set.
For the same character, different character sets may have different encoding methods. For example, for the Chinese character "I", this character is not included in the ASCII character set at all. The coding method for Chinese characters in utf8 and gb2312 character sets is as follows:
utf8 Code: 1110011010001 (3 Bytes, hexadecimal: 0 xE68891) gb2312 Code: 1011000010101110 (2 Bytes, hexadecimal: 0 xB0AE)
Character sets and collations supported in MySQL
utf8 and utf8mb4 in MySQL
We said above that the utf8 character set needs 1 ~ 4 bytes to represent a character, but some of our commonly used characters can be represented by 1 ~ 3 bytes. In mysql, the character set represents the maximum byte length of a character, which will affect the storage and performance of the system in some aspects. Therefore, the uncle who designed MySQL secretly defined two concepts:
-
utf8mb3: castrated utf8 character set. Only 1 ~ 3 bytes are used to represent characters.
-
utf8mb4: the authentic utf8 character set, which uses 1-4 bytes to represent characters.
It should be noted that utf8 is the alias of utf8mb3 in MySQL. Therefore, when utf8 is mentioned later in mysql, it means that 1 ~ 3 bytes are used to represent a character. If you use 4 bytes to encode a character, such as storing some emoji expressions, please use utf8mb4.
View of character set
MySQL supports many character sets. To view the character sets currently supported in mysql, use the following statement:
SHOW (CHARACTER SET|CHARSET) [LIKE Matching pattern];
Among them, CHARACTER SET and character are synonyms, and any one can be used. Let's check (there are too many character sets supported, and we omit some):
mysql> SHOW CHARSET; +----------+---------------------------------+---------------------+--------+ | Charset | Description | Default collation | Maxlen | +----------+---------------------------------+---------------------+--------+ | big5 | Big5 Traditional Chinese | big5_chinese_ci | 2 | ... | latin1 | cp1252 West European | latin1_swedish_ci | 1 | | latin2 | ISO 8859-2 Central European | latin2_general_ci | 1 | ... | ascii | US ASCII | ascii_general_ci | 1 | ... | gb2312 | GB2312 Simplified Chinese | gb2312_chinese_ci | 2 | ... | gbk | GBK Simplified Chinese | gbk_chinese_ci | 2 | | latin5 | ISO 8859-9 Turkish | latin5_turkish_ci | 1 | ... | utf8 | UTF-8 Unicode | utf8_general_ci | 3 | | ucs2 | UCS-2 Unicode | ucs2_general_ci | 2 | ... | latin7 | ISO 8859-13 Baltic | latin7_general_ci | 1 | | utf8mb4 | UTF-8 Unicode | utf8mb4_general_ci | 4 | | utf16 | UTF-16 Unicode | utf16_general_ci | 4 | | utf16le | UTF-16LE Unicode | utf16le_general_ci | 4 | ... | utf32 | UTF-32 Unicode | utf32_general_ci | 4 | | binary | Binary pseudo charset | binary | 1 | ... | gb18030 | China National Standard GB18030 | gb18030_chinese_ci | 4 | +----------+---------------------------------+---------------------+--------+ 41 rows in set (0.01 sec)
You can see that the MySQL version I use supports a total of 41 character sets, and the Default collation column represents a default comparison rule in this character set. You should pay attention to the last column Maxlen in the returned result, which represents this kind of character set and indicates that a character needs at most a few bytes. In order to impress you more, I'll extract the Maxlen column of several commonly used character sets. You must remember:
| Character set name | Maxlen |
|---|---|
| ascii | 1 |
| latin1 | 1 |
| gb2312 | 2 |
| gbk | 2 |
| utf8 | 3 |
| utf8mb4 | 4 |
View of comparison rules
The commands to view the comparison rules supported in MySQL are as follows:
SHOW COLLATION [LIKE Matching pattern];
We said earlier that a character set may correspond to several comparison rules. MySQL already supports many character sets, so it supports more comparison rules. Let's just check the comparison rules under the utf8 character set:
mysql> SHOW COLLATION LIKE 'utf8\_%'; +--------------------------+---------+-----+---------+----------+---------+ | Collation | Charset | Id | Default | Compiled | Sortlen | +--------------------------+---------+-----+---------+----------+---------+ | utf8_general_ci | utf8 | 33 | Yes | Yes | 1 | | utf8_bin | utf8 | 83 | | Yes | 1 | | utf8_unicode_ci | utf8 | 192 | | Yes | 8 | | utf8_icelandic_ci | utf8 | 193 | | Yes | 8 | | utf8_latvian_ci | utf8 | 194 | | Yes | 8 | | utf8_romanian_ci | utf8 | 195 | | Yes | 8 | | utf8_slovenian_ci | utf8 | 196 | | Yes | 8 | | utf8_polish_ci | utf8 | 197 | | Yes | 8 | | utf8_estonian_ci | utf8 | 198 | | Yes | 8 | | utf8_spanish_ci | utf8 | 199 | | Yes | 8 | | utf8_swedish_ci | utf8 | 200 | | Yes | 8 | | utf8_turkish_ci | utf8 | 201 | | Yes | 8 | | utf8_czech_ci | utf8 | 202 | | Yes | 8 | | utf8_danish_ci | utf8 | 203 | | Yes | 8 | | utf8_lithuanian_ci | utf8 | 204 | | Yes | 8 | | utf8_slovak_ci | utf8 | 205 | | Yes | 8 | | utf8_spanish2_ci | utf8 | 206 | | Yes | 8 | | utf8_roman_ci | utf8 | 207 | | Yes | 8 | | utf8_persian_ci | utf8 | 208 | | Yes | 8 | | utf8_esperanto_ci | utf8 | 209 | | Yes | 8 | | utf8_hungarian_ci | utf8 | 210 | | Yes | 8 | | utf8_sinhala_ci | utf8 | 211 | | Yes | 8 | | utf8_german2_ci | utf8 | 212 | | Yes | 8 | | utf8_croatian_ci | utf8 | 213 | | Yes | 8 | | utf8_unicode_520_ci | utf8 | 214 | | Yes | 8 | | utf8_vietnamese_ci | utf8 | 215 | | Yes | 8 | | utf8_general_mysql500_ci | utf8 | 223 | | Yes | 1 | +--------------------------+---------+-----+---------+----------+---------+ 27 rows in set (0.00 sec)
The naming of these comparison rules is quite regular. The specific rules are as follows:
-
The comparison rule name begins with the name of the character set associated with it. As shown in the figure above, the comparison rule names of query results start with utf8.
-
This is followed by the language in which the comparison rule mainly applies, such as utf8_polish_ci stands for rule comparison in Polish, utf8_spanish_ci is a rule comparison in Spanish, utf8_general_ci is a general comparison rule.
-
The name suffix means whether the comparison rule is accent sensitive and case sensitive. The specific values are as follows:
suffix transitive verb describe _ai accent insensitive Accent insensitive _as accent sensitive Accent sensitive _ci case insensitive Case insensitive _cs case sensitive Case sensitive _bin binary Compare in binary Like utf8_general_ci this comparison rule ends with ci, indicating that it is not case sensitive.
Each character set corresponds to several comparison rules. Each character set has a Default comparison rule. If the value of the Default column in the return result of show collection is YES, it is the Default comparison rule of the character set. For example, the Default comparison rule of utf8 character set is utf8_general_ci.
Application of character sets and comparison rules
Character sets and comparison rules at all levels
MySQL has four levels of character sets and comparison rules:
- Server level
- Database level
- Table level
- Column level
Let's take a closer look at how to set and view these levels of character sets and comparison rules.
Server level
MySQL provides two system variables to represent the character set and comparison rules at the server level:
| System variable | describe |
|---|---|
| character_set_server | Server level character set |
| collation_server | Server level comparison rules |
Let's look at the values of these two system variables:
mysql> SHOW VARIABLES LIKE 'character_set_server'; +----------------------+-------+ | Variable_name | Value | +----------------------+-------+ | character_set_server | utf8 | +----------------------+-------+ 1 row in set (0.00 sec) mysql> SHOW VARIABLES LIKE 'collation_server'; +------------------+-----------------+ | Variable_name | Value | +------------------+-----------------+ | collation_server | utf8_general_ci | +------------------+-----------------+ 1 row in set (0.00 sec)
You can see that in my computer, the server level default character set is utf8, and the default comparison rule is utf8_general_ci.
We can modify the values of these two variables through the startup option when starting the server program or using the SET statement when the server program is running. For example, we can write this in the configuration file:
[server] character_set_server=gbk collation_server=gbk_chinese_ci
After reading the configuration file when the server starts, the values of the two system variables are modified.
Database level
When creating and modifying a database, we can specify the character set and comparison rules of the database. The specific syntax is as follows:
CREATE DATABASE Database name
[[DEFAULT] CHARACTER SET Character set name]
[[DEFAULT] COLLATE Comparison rule name];
ALTER DATABASE Database name
[[DEFAULT] CHARACTER SET Character set name]
[[DEFAULT] COLLATE Comparison rule name];
The DEFAULT can be omitted without affecting the semantics of the statement. For example, let's create a new one called charset_demo_db database. When it is created, it is specified that the character set it uses is gb2312 and the comparison rule is gb2312_chinese_ci:
mysql> CREATE DATABASE charset_demo_db
-> CHARACTER SET gb2312
-> COLLATE gb2312_chinese_ci;
Query OK, 1 row affected (0.01 sec)
If you want to view the character set and comparison rules used by the current database, you can view the values of the following two system variables (provided that you USE the USE statement to select the current default database. If there is no default database, the variables have the same values as the corresponding server level system variables):
| System variable | describe |
|---|---|
| character_set_database | The character set of the current database |
| collation_database | Comparison rules for the current database |
Let's take a look at the charset we just created_ demo_ Character set and comparison rules for DB database:
mysql> USE charset_demo_db; Database changed mysql> SHOW VARIABLES LIKE 'character_set_database'; +------------------------+--------+ | Variable_name | Value | +------------------------+--------+ | character_set_database | gb2312 | +------------------------+--------+ 1 row in set (0.00 sec) mysql> SHOW VARIABLES LIKE 'collation_database'; +--------------------+-------------------+ | Variable_name | Value | +--------------------+-------------------+ | collation_database | gb2312_chinese_ci | +--------------------+-------------------+ 1 row in set (0.00 sec) mysql>
You can see this charset_ demo_ The character set and comparison rules of DB database are specified in the creation statement. It should be noted that: character_set_database and collation_database These two system variables are read-only. We cannot change the character set and comparison rules of the current database by modifying the values of these two variables.
Character sets and comparison rules may not be specified in the database creation statement, for example:
CREATE DATABASE Database name;
In this case, the server level character set and comparison rule will be used as the character set and comparison rule of the database.
Table level
We can also specify the character set and comparison rules of the table when creating and modifying the table. The syntax is as follows:
CREATE TABLE Table name (Column information)
[[DEFAULT] CHARACTER SET Character set name]
[COLLATE Comparison rule name]]
ALTER TABLE Table name
[[DEFAULT] CHARACTER SET Character set name]
[COLLATE Comparison rule name]
For example, in the charset we just created_ demo_ Create a table named t in DB database, and specify the character set and comparison rules of this table:
mysql> CREATE TABLE t(
-> col VARCHAR(10)
-> ) CHARACTER SET utf8 COLLATE utf8_general_ci;
Query OK, 0 rows affected (0.03 sec)
If the character set and comparison rule are not specified in the statement creating and modifying a table, the character set and comparison rule of the database where the table is located will be used as the character set and comparison rule of the table. Suppose our statement to create table t is written as follows:
CREATE TABLE t(
col VARCHAR(10)
);
Because the character set and comparison rule are not explicitly specified in the table creation statement of table t, the character set and comparison rule of table T will inherit the charset of the database_ demo_ DB character set and comparison rules, that is gb2312 and gb2312_chinese_ci.
Column level
It should be noted that for columns storing strings, different columns in the same table can also have different character sets and comparison rules. When creating and modifying a column definition, we can specify the character set and comparison rules of the column. The syntax is as follows:
CREATE TABLE Table name(
Column name string type [CHARACTER SET Character set name] [COLLATE Comparison rule name],
Other columns...
);
ALTER TABLE Table name MODIFY Column name string type [CHARACTER SET Character set name] [COLLATE Comparison rule name];
For example, we can modify the character set and comparison rules of col in table t as follows:
mysql> ALTER TABLE t MODIFY col VARCHAR(10) CHARACTER SET gbk COLLATE gbk_chinese_ci; Query OK, 0 rows affected (0.04 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql>
For a column, if the character set and comparison rule are not specified in the statement created or modified, the character set and comparison rule of the table where the column is located will be used as the character set and comparison rule of the column. For example, the character set of table t is utf8, and the comparison rule is utf8_general_ci, the statement to modify column col is written as follows:
ALTER TABLE t MODIFY col VARCHAR(10);
The character set and encoding of that col column will use the character set and comparison rules of table t, that is, utf8 and utf8_general_ci.
Tips: When converting the character set of a column, it should be noted that if the data stored in the front row of conversion cannot be represented by the converted character set, an error will occur. For example, the character set used by the original column is utf8,Some Chinese characters are stored in the column. Now convert the character set of the column to ascii If you don't, you'll make mistakes because ascii Character sets cannot represent Chinese characters.
Modify character sets only or compare rules only
Because character sets and comparison rules are interrelated, if we only modify the character set, the comparison rules will change. If we only modify the comparison rules, the character set will also change. The specific rules are as follows:
- If only the character set is modified, the comparison rule will become the default comparison rule of the modified character set.
- If only the comparison rule is modified, the character set will become the character set corresponding to the modified comparison rule.
No matter which level of character set and comparison rule, these two rules apply. Let's take the server level character set and comparison rule as an example to see the detailed process:
-
If only the character set is modified, the comparison rule will become the default comparison rule of the modified character set.
mysql> SET character_set_server = gb2312; Query OK, 0 rows affected (0.00 sec) mysql> SHOW VARIABLES LIKE 'character_set_server'; +----------------------+--------+ | Variable_name | Value | +----------------------+--------+ | character_set_server | gb2312 | +----------------------+--------+ 1 row in set (0.00 sec) mysql> SHOW VARIABLES LIKE 'collation_server'; +------------------+-------------------+ | Variable_name | Value | +------------------+-------------------+ | collation_server | gb2312_chinese_ci | +------------------+-------------------+ 1 row in set (0.00 sec)
We only modified character_ set_ The value of server is gb2312, collection_ The value of server automatically changes to gb2312_chinese_ci.
-
If only the comparison rule is modified, the character set will become the character set corresponding to the modified comparison rule.
mysql> SET collation_server = utf8_general_ci; Query OK, 0 rows affected (0.00 sec) mysql> SHOW VARIABLES LIKE 'character_set_server'; +----------------------+-------+ | Variable_name | Value | +----------------------+-------+ | character_set_server | utf8 | +----------------------+-------+ 1 row in set (0.00 sec) mysql> SHOW VARIABLES LIKE 'collation_server'; +------------------+-----------------+ | Variable_name | Value | +------------------+-----------------+ | collation_server | utf8_general_ci | +------------------+-----------------+ 1 row in set (0.00 sec) mysql>
We only modified the collation_ The value of server is utf8_general_ci,character_ set_ The value of server automatically changes to utf8.
Summary of character sets and comparison rules at all levels
The relationship between the four level character sets and the comparison rules is as follows:
- If there is no explicit character set and comparison rule specified when creating or modifying a column, the column defaults to the character set and comparison rule of the table
- If there is no explicit character set and comparison rule specified when creating a table, the table defaults to the character set and comparison rule of the database
- If there is no explicit character set and comparison rule specified when creating a database, the database defaults to the server's character set and comparison rule
After knowing these rules, for a given table, we should know the character set and comparison rules of each column, so as to determine the storage space occupied by the actual data of each column when storing data according to the type of this column. For example, let's insert a record into table t:
mysql> INSERT INTO t(col) VALUES('I, I');
Query OK, 1 row affected (0.00 sec)
mysql> SELECT * FROM t;
+--------+
| s |
+--------+
| I, I |
+--------+
1 row in set (0.00 sec)
First, the character set used in column col is gbk. The encoding of a character 'I' in gbk is 0xCED2, which takes two bytes, and the actual data of two characters takes four bytes. If you change the character set of this column to utf8, these two characters actually occupy 6 bytes ~
Character set in client server communication
Consequences of inconsistent character sets used for encoding and decoding
In the final analysis, the embodiment of a string on the computer is a byte string. If you use different character sets to decode this byte string, the final result may scratch your head.
We know that the byte string length of the character 'I' encoded in the utf8 character set is 0xE68891. If one program sends the byte string to another program, the other program decodes the byte string with a different character set. Assuming that the gbk character set is used to interpret the string of bytes, the decoding process is as follows:
-
First, look at the first byte 0xE6, whose value is greater than 0x7F (decimal: 127), indicating that it is two byte encoding. After reading one byte, it is 0xE688. Then, look up the character corresponding to byte 0xE688 from the gbk encoding table and find that it is the character 'or'
-
Continue to read a byte 0x91, and its value is also greater than 0x7F. Read another byte later and find that there is no wood, so this is half a character.
-
Therefore, 0xE68891 is interpreted by gbk character set as one character 'or' and half a character.
Suppose that the string of bytes is interpreted with iso-8859-1, that is, the latin1 character set, and the decoding process is as follows:
-
First read the first byte 0xE6, and its corresponding latin1 character is æ.
-
Read the second byte 0x88 again, and its corresponding latin1 character is ˆ.
-
Read the third byte 0x91 again, and its corresponding latin1 character is' '.
-
Therefore, the whole string of bytes 0xE68891 interpreted by the latin1 character set is' æ ˆ‘'
It can be seen that if the character set used for encoding and decoding the same string is different, it will produce unexpected results. As human beings, we seem to have generated garbled code.
Concept of character set conversion
If the program receiving the byte string 0xE68891 decodes it according to the utf8 character set, and then encodes it according to the gbk character set, the last encoded byte string is 0xCED2. We call this process the conversion of the character set, that is, the conversion of the string 'I' from the utf8 character set to the gbk character set.
Character set conversion in MySQL
We know that the request from the client to the server is essentially a string, and the result returned by the server to the client is essentially a string, and the string is actually binary data encoded by some character set. This string does not use a character set encoding method. It goes black all the way. The process from sending the request to returning the result is accompanied by multiple character set conversions. In this process, three system variables will be used. Let's write them first:
| System variable | describe |
|---|---|
| character_set_client | The character set used by the server to decode the request |
| character_set_connection | When the server processes the request, it will remove the request string from character_set_client to character_set_connection |
| character_set_results | The character set used when the server returns data to the client |
The default values of these system variables on my computer are as follows (the default values of different operating systems may be different):
mysql> SHOW VARIABLES LIKE 'character_set_client'; +----------------------+-------+ | Variable_name | Value | +----------------------+-------+ | character_set_client | utf8 | +----------------------+-------+ 1 row in set (0.00 sec) mysql> SHOW VARIABLES LIKE 'character_set_connection'; +--------------------------+-------+ | Variable_name | Value | +--------------------------+-------+ | character_set_connection | utf8 | +--------------------------+-------+ 1 row in set (0.01 sec) mysql> SHOW VARIABLES LIKE 'character_set_results'; +-----------------------+-------+ | Variable_name | Value | +-----------------------+-------+ | character_set_results | utf8 | +-----------------------+-------+ 1 row in set (0.00 sec)
You can see that the values of these system variables are utf8. In order to reflect the changes of character set during request processing, we specially modify the value of a system variable:
mysql> set character_set_connection = gbk; Query OK, 0 rows affected (0.00 sec)
So now the system variable character_set_client and character_ set_ The value of results is still utf8, while character_ set_ The value of connection is gbk. Now suppose that the request sent by our client is the following string:
SELECT * FROM t WHERE s = 'I';
In order to facilitate you to understand this process, we only analyze the character 'I' in the process of character set conversion.
Now let's look at the changes in the character set during the process from sending the request to returning the result:
-
The character set used by the client to send the request
Generally, the character set used by the client is the same as that of the current operating system. Different operating systems may use different character sets, as follows:
- Unix like systems use utf8
- Windows uses gbk
For example, when I use the Mac OS operating system, the client uses the utf8 character set. So the byte form of the character 'I' in the request sent to the server is 0xE68891
Tips: If you use visualization tools, such as navicat For example, these tools may use a custom character set to encode the string sent to the server instead of the default character set of the operating system (so try to use black boxes when learning).
-
The request received by the server from the client is actually a string of binary bytes. It will think that the character set used by this string of bytes is character_set_client, and then convert this string of bytes into character_ set_ The character encoded by the connection character set.
Because character on my computer_ set_ The value of client is utf8. Firstly, the byte string 0xE68891 will be decoded according to the utf8 character set, and the resulting string is' I ', and then according to character_ set_ The character set represented by connection, that is, gbk, is encoded, and the result is the byte string 0xCED2.
-
Because the column col of table t adopts gbk character set, which is different from character_ set_ The connection is consistent, so go directly to the column to find the record with byte value 0xCED2, and finally find a record.
Tips: If a column uses the character set and character_set_connection If the character sets represented are inconsistent, another character set conversion is required.
-
The col column in the record found in the previous step is actually a byte string 0xCED2. The col column is encoded in gbk, so first decode the byte string in gbk to get the string 'I', and then use character_ set_ The character set represented by results, that is, utf8, is encoded to get a new byte string: 0xE68891, and then sent to the client.
-
Because the character set used by the client is utf8, 0xE68891 can be smoothly interpreted into characters and displayed on our display, so we humans can also understand the returned results.
If you are a little dizzy when reading the above text, you can refer to this figure to carefully analyze these steps:
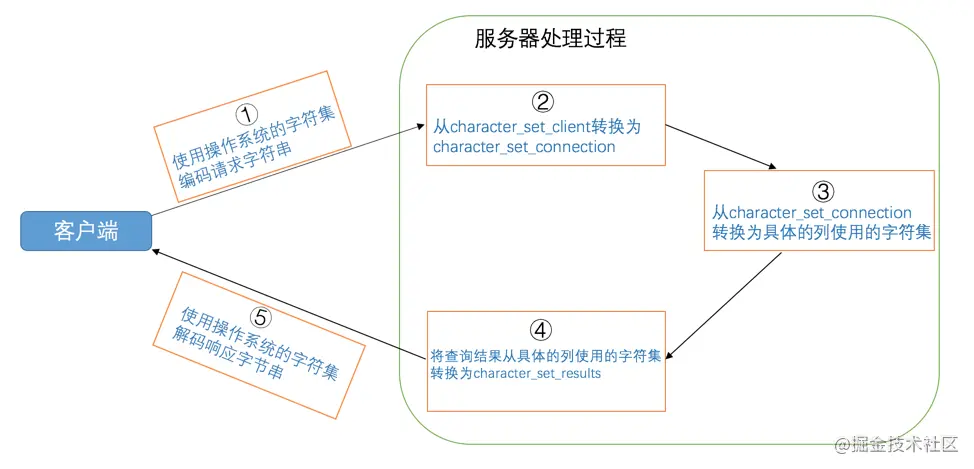
From this analysis, we can draw the following points to pay attention to:
-
The server thinks that the request sent by the client is in character_set_client encoded.
Suppose your client uses the character set and character_set_client If it's different, something unexpected will happen. For example, my client uses the utf8 character set. If the system variable character_ set_ If the value of client is set to ascii, the server may not understand the request we sent, let alone handle it.
-
The server will use character for the resulting result set_ set_ Results is encoded and sent to the client.
Suppose your client uses the character set and character_set_results Otherwise, the client may not be able to decode the result set, and the result is garbled code on your screen. For example, my client uses the utf8 character set. If the system variable character_ set_ If the value of results is set to ascii, garbled code may be generated.
-
character_set_connection is just that the server is removing the requested byte string from character_ set_ Convert client to character_ set_ It doesn't really matter what it is when using connection, but it must be noted that the character range contained in the character set must cover the characters in the request, otherwise some characters will not be able to use character_ set_ The character set represented by connection is encoded. For example, you put character_ set_ Set client to utf8 and set character_ set_ If the connection is set to ascii, then if you send a Chinese character from the client to the server, the server will send a warning to the user if it cannot use the ascii character set to encode the Chinese character.
I know all kinds of character set conversion in MySQL from sending requests to returning results, but why do I have to turn around? Aren't you dizzy?
A: Yes, it's dizzy, so we usually put character_set_client , character_set_connection,character_set_results These three system variables are set to be consistent with the character set used by the client, which reduces a lot of unnecessary character set conversion. To facilitate our settings, MySQL provides a very simple statement:
SET NAMES Character set name;
The effect of this statement is the same as that of executing these three statements:
SET character_set_client = Character set name; SET character_set_connection = Character set name; SET character_set_results = Character set name;
For example, my client uses the utf8 character set, so I need to set the values of these system variables to utf8:
mysql> SET NAMES utf8; Query OK, 0 rows affected (0.00 sec) mysql> SHOW VARIABLES LIKE 'character_set_client'; +----------------------+-------+ | Variable_name | Value | +----------------------+-------+ | character_set_client | utf8 | +----------------------+-------+ 1 row in set (0.00 sec) mysql> SHOW VARIABLES LIKE 'character_set_connection'; +--------------------------+-------+ | Variable_name | Value | +--------------------------+-------+ | character_set_connection | utf8 | +--------------------------+-------+ 1 row in set (0.00 sec) mysql> SHOW VARIABLES LIKE 'character_set_results'; +-----------------------+-------+ | Variable_name | Value | +-----------------------+-------+ | character_set_results | utf8 | +-----------------------+-------+ 1 row in set (0.00 sec) mysql>
Tips: If you use Windows System, that should be set to gbk.
In addition, if you want to start the client, put character_set_client,character_set_connection,character_ set_ If the values of the three system variables results are set to the same, we can specify a startup option called default character set when starting the client. For example, it can be written in the configuration file:
[client] default-character-set=utf8
The effect is the same as that of executing SET NAMES utf8. The values of the three system variables will be set to utf8.
Application of comparison rules
After roaming the character set, we focus on comparison rules again. The role of comparison rules is usually reflected in the expression of comparing the size of strings and sorting a character string, so they are sometimes called sorting rules. For example, the character set used by column col of table t is gbk, and the comparison rule used is gbk_chinese_ci, let's insert a few records into it:
mysql> INSERT INTO t(col) VALUES('a'), ('b'), ('A'), ('B');
Query OK, 4 rows affected (0.00 sec)
Records: 4 Duplicates: 0 Warnings: 0
mysql>
When we query, we sort by t column:
mysql> SELECT * FROM t ORDER BY col; +------+ | col | +------+ | a | | A | | b | | B | | I | +------+ 5 rows in set (0.00 sec)
You can see in the default comparison rule gbk_chinese_ci is case insensitive. Now we change the comparison rule of col column to gbk_bin:
mysql> ALTER TABLE t MODIFY col VARCHAR(10) COLLATE gbk_bin; Query OK, 5 rows affected (0.02 sec) Records: 5 Duplicates: 0 Warnings: 0
Due to gbk_bin is the code for directly comparing characters, so it is case sensitive. Let's take a look at the sorted query results:
mysql> SELECT * FROM t ORDER BY s; +------+ | s | +------+ | A | | B | | a | | b | | I | +------+ 5 rows in set (0.00 sec) mysql>
Therefore, if you don't get the expected results when comparing strings or sorting a string of characters in the future, you need to think about whether it is a regular comparison
Tips: column`col`The characters in the are in use gbk The corresponding numbers after character set encoding are as follows: 'A' -> 65 ((decimal) 'B' -> 66 ((decimal) 'a' -> 97 ((decimal) 'b' -> 98 ((decimal) 'I' -> 25105 ((decimal)
summary
-
Character set refers to the coding rule of a character range.
-
Comparison rule is a rule to compare the size of characters in a character set.
-
In MySQL, a character set can have several comparison rules, including a default comparison rule. A comparison rule must correspond to a character set.
-
The statements for viewing supported character sets and comparison rules in MySQL are as follows:
SHOW (CHARACTER SET|CHARSET) [LIKE Matching pattern]; SHOW COLLATION [LIKE Matching pattern];
-
MySQL has four levels of character sets and comparison rules
-
Server level
character_set_server represents the character set at the server level_ Server represents a server level comparison rule.
-
Database level
When creating and modifying databases, you can specify character sets and comparison rules:
CREATE DATABASE Database name [[DEFAULT] CHARACTER SET Character set name] [[DEFAULT] COLLATE Comparison rule name]; ALTER DATABASE Database name [[DEFAULT] CHARACTER SET Character set name] [[DEFAULT] COLLATE Comparison rule name];character_set_database represents the character set of the current database_ Database represents the comparison rules of the current default database. These two system variables are read-only and cannot be modified. If the current default database is not specified, the variable has the same value as the corresponding server level system variable.
-
Table level
Specify the character set and comparison rules of the table when creating and modifying the table:
CREATE TABLE Table name (Column information) [[DEFAULT] CHARACTER SET Character set name] [COLLATE Comparison rule name]]; ALTER TABLE Table name [[DEFAULT] CHARACTER SET Character set name] [COLLATE Comparison rule name]; -
Column level
When creating and modifying a column definition, you can specify the character set and comparison rules of the column:
CREATE TABLE Table name( Column name string type [CHARACTER SET Character set name] [COLLATE Comparison rule name], Other columns... ); ALTER TABLE Table name MODIFY Column name string type [CHARACTER SET Character set name] [COLLATE Comparison rule name];
-
Character set conversion from sending request to receiving result:
-
The client uses the character set of the operating system to encode the request string, and sends an encoded byte string to the server.
-
The server uses character as the byte string sent by the client_ set_ Decode the character set represented by client, and then decode the decoded string according to character_ set_ The character set represented by connection is encoded.
-
If character_ set_ If the character set represented by connection is consistent with the character set used by the column of the specific operation, the corresponding operation shall be carried out directly. Otherwise, the string in the request shall be removed from character_ set_ The character set represented by connection is converted to the character set used by the column of specific operation before operation.
-
Converts the byte string obtained from a column from the character set used by the column to character_set_results represents the character set and is sent to the client.
-
The client parses the byte string of the received result set using the character set of the operating system.
In this process, the meanings of each system variable are as follows:
System variable describe character_set_client The character set used by the server to decode the request character_set_connection When the server processes the request, it will remove the request string from character_set_client to character_set_connection character_set_results The character set used when the server returns data to the client In general, keep the values of these three variables the same as the character set used by the client.
-
-
The role of comparison rules is usually reflected in expressions that compare the size of strings and sort a character string column.