Actual combat of e-commerce offline warehouse project (Part 2)
E-commerce analysis - core transactions
1, Business requirements
Select indicators: order quantity, commodity quantity and payment amount, and analyze these indicators by sales region and commodity type.
2, Business database table structure
1. Relationship between database tables
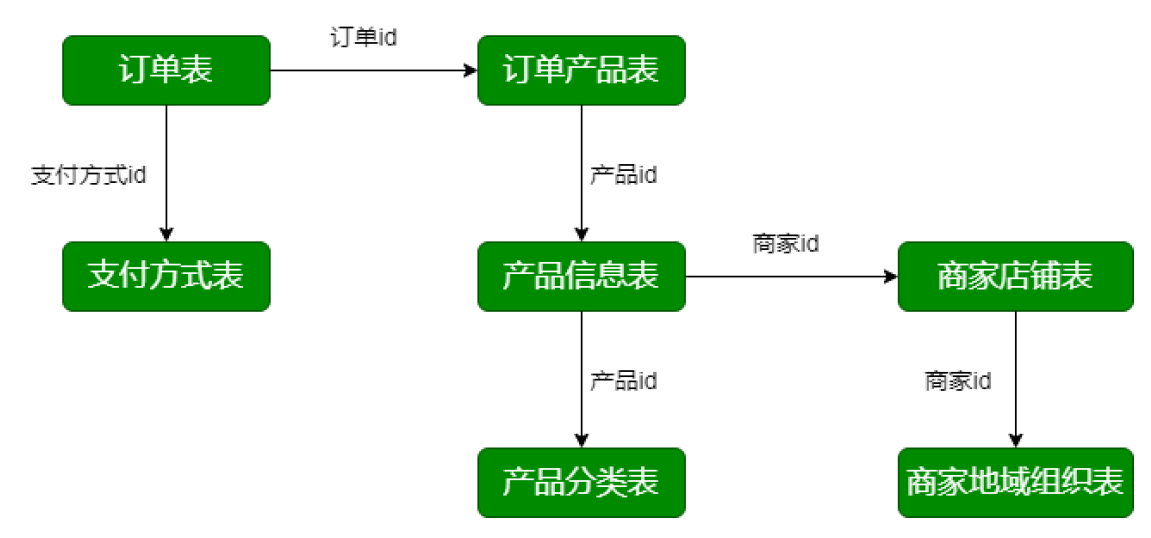
2. Business database - data source
- trade_orders
- order_product table
- product_info
- product_category
- Shop list (shops)
- Regional organization table (shop_admin_org)
- Payment forms
3. Database table structure design
3.1 transaction order form
DROP TABLE IF EXISTS lagou_trade_orders; CREATE TABLE `lagou_trade_orders` ( `orderId` bigint(11) NOT NULL AUTO_INCREMENT COMMENT 'order id', `orderNo` varchar(20) NOT NULL COMMENT 'Order No', `userId` bigint(11) NOT NULL COMMENT 'user id', `status` tinyint(4) NOT NULL DEFAULT '-2' COMMENT 'Order status -3:User Reject -2:Unpaid orders -1: User canceled 0:To be shipped 1:In delivery 2:User confirms receipt', `productMoney` decimal(11, 2) NOT NULL COMMENT 'Commodity amount', `totalMoney` decimal(11, 2) NOT NULL COMMENT 'Order amount (including freight)', `payMethod` tinyint(4) NOT NULL DEFAULT '0' COMMENT 'Payment method,0:unknown;1:Alipay, 2: WeChat;3,Cash; 4. Other', `isPay` tinyint(4) NOT NULL DEFAULT '0' COMMENT 'Pay 0:Unpaid 1:Paid', `areaId` int(11) NOT NULL COMMENT 'Regional lowest level', `tradeSrc` tinyint(4) NOT NULL DEFAULT '0' COMMENT 'Order source 0:Mall 1:Wechat 2:Mobile version 3:Android App 4:Apple App', `tradeType` int(11) DEFAULT '0' COMMENT 'Order type', `isRefund` tinyint(4) NOT NULL DEFAULT '0' COMMENT 'Refund 0:No 1: Yes', `dataFlag` tinyint(4) NOT NULL DEFAULT '1' COMMENT 'Order validity flag -1: Delete 1:Effective', `createTime` varchar(25) NOT NULL COMMENT 'Order time ', `payTime` varchar(25) DEFAULT NULL COMMENT 'Payment time', `modifiedTime` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT 'Order update time', PRIMARY KEY (`orderId`) ) ENGINE = InnoDB AUTO_INCREMENT = 355 CHARSET = utf8;
remarks:
Record order information
Status: order status
createTime,payTime,modifiedTime. Creation time, payment time and modification time
3.2 order product table
DROP TABLE IF EXISTS lagou_order_produc; CREATE TABLE `lagou_order_product` ( `id` bigint(11) NOT NULL AUTO_INCREMENT, `orderId` bigint(11) NOT NULL COMMENT 'order id', `productId` bigint(11) NOT NULL COMMENT 'commodity id', `productNum` bigint(11) NOT NULL DEFAULT '0' COMMENT 'Quantity of goods', `productPrice` decimal(11, 2) NOT NULL DEFAULT '0.00' COMMENT 'commodity price', `money` decimal(11, 2) DEFAULT '0.00' COMMENT 'Payment amount', `extra` text COMMENT 'Additional information', `createTime` varchar(25) DEFAULT NULL COMMENT 'Creation time', PRIMARY KEY (`id`), KEY `orderId` (`orderId`), KEY `goodsId` (`productId`) ) ENGINE = InnoDB AUTO_INCREMENT = 1260 CHARSET = utf8;
remarks:
Record the information of purchased products in the order, including product quantity, unit price, etc
3.3 product information table
DROP TABLE IF EXISTS lagou_product_info;
CREATE TABLE `lagou_product_info` (
`productId` bigint(11) NOT NULL AUTO_INCREMENT COMMENT 'commodity id',
`productName` varchar(200) NOT NULL COMMENT 'Trade name',
`shopId` bigint(11) NOT NULL COMMENT 'store ID',
`price` decimal(11, 2) NOT NULL DEFAULT '0.00' COMMENT 'Store price',
`isSale` tinyint(4) NOT NULL DEFAULT '1' COMMENT 'Whether to put on the shelf 0:No shelf 1:Put on the shelf',
`status` tinyint(4) NOT NULL DEFAULT '0' COMMENT 'New product 0:No 1:yes',
`categoryId` int(11) NOT NULL COMMENT 'goodsCatId Last level commodity classification ID',
`createTime` varchar(25) NOT NULL,
`modifyTime` datetime DEFAULT NULL ON UPDATE CURRENT_TIMESTAMP COMMENT 'Modification time',
PRIMARY KEY (`productId`),
KEY `shopId` USING BTREE (`shopId`),
KEY `goodsStatus` (`isSale`)
) ENGINE = InnoDB AUTO_INCREMENT = 115909 CHARSET = utf8;
remarks:
Record the detailed information of the product, corresponding to the merchant ID and commodity attribute (whether it is new or on the shelf)
3.4 product classification table
DROP TABLE IF EXISTS lagou_product_category; CREATE TABLE `lagou_product_category` ( `catId` int(11) NOT NULL AUTO_INCREMENT COMMENT 'category ID', `parentId` int(11) NOT NULL COMMENT 'father ID', `catName` varchar(20) NOT NULL COMMENT 'Classification name', `isShow` tinyint(4) NOT NULL DEFAULT '1' COMMENT 'Show 0:Hide 1:display', `sortNum` int(11) NOT NULL DEFAULT '0' COMMENT 'Sort number', `isDel` tinyint(4) NOT NULL DEFAULT '1' COMMENT 'Delete flag 1:Effective -1: delete', `createTime` varchar(25) NOT NULL COMMENT 'Establishment time', `level` tinyint(4) DEFAULT '0' COMMENT 'Classification level of 3', PRIMARY KEY (`catId`), KEY `parentId` (`parentId`, `isShow`, `isDel`) ) ENGINE = InnoDB AUTO_INCREMENT = 10442 CHARSET = utf8;
remarks:
The product classification table is divided into three levels
-- First level product catalog select catName, catid from lagou_product_category where level =1; -- View the subclass of computer and office (view the secondary directory) select catName, catid from lagou_product_category where level =2 and parentId = 32; -- View the subclass of the complete computer (view the three-level directory) select catName, catid from lagou_product_category where level =3 and parentId = 10250;
3.5 list of stores
DROP TABLE IF EXISTS lagou_shops; CREATE TABLE `lagou_shops` ( `shopId` int(11) NOT NULL AUTO_INCREMENT COMMENT 'shops ID,Self increasing', `userId` int(11) NOT NULL COMMENT 'Shop contact ID', `areaId` int(11) DEFAULT '0', `shopName` varchar(100) DEFAULT '' COMMENT 'Shop name', `shopLevel` tinyint(4) NOT NULL DEFAULT '1' COMMENT 'Store level', `status` tinyint(4) NOT NULL DEFAULT '1' COMMENT 'Shop status', `createTime` date DEFAULT NULL, `modifyTime` datetime DEFAULT NULL COMMENT 'Modification time', PRIMARY KEY (`shopId`), KEY `shopStatus` (`status`) ) ENGINE = InnoDB AUTO_INCREMENT = 105317 CHARSET = utf8;
remarks:
Record store details
3.6 regional organization table
DROP TABLE IF EXISTS lagou_shops; CREATE TABLE `lagou_shop_admin_org` ( `id` int(11) NOT NULL AUTO_INCREMENT COMMENT 'organization ID', `parentId` int(11) NOT NULL COMMENT 'father ID', `orgName` varchar(100) NOT NULL COMMENT 'Organization name', `orgLevel` tinyint(4) NOT NULL DEFAULT '1' COMMENT 'Organization level 1;Headquarters and regional departments;2: All departments and basic departments under the headquarters;3:Specific work department', `isDelete` tinyint(4) NOT NULL DEFAULT '0' COMMENT 'Delete flag,1:delete;0:Effective', `createTime` varchar(25) DEFAULT NULL COMMENT 'Creation time', `updateTime` varchar(25) DEFAULT NULL COMMENT 'Last modification time', `isShow` tinyint(4) NOT NULL DEFAULT '1' COMMENT 'Show,0: Yes 1:no', `orgType` tinyint(4) NOT NULL DEFAULT '1' COMMENT 'Organization type,0:President's Office;1:research and development;2:sale;3:operate;4:product', PRIMARY KEY (`id`), KEY `parentId` (`parentId`) ) ENGINE = InnoDB AUTO_INCREMENT = 100332 CHARSET = utf8;
remarks:
Record the area of the store
3.7 payment method table
DROP TABLE IF EXISTS lagou_payments; CREATE TABLE `lagou_payments` ( `id` int(11) NOT NULL, `payMethod` varchar(20) DEFAULT NULL, `payName` varchar(255) DEFAULT NULL, `description` varchar(255) DEFAULT NULL, `payOrder` int(11) DEFAULT '0', `online` tinyint(4) DEFAULT NULL, PRIMARY KEY (`id`), KEY `payCode` (`payMethod`) ) ENGINE = InnoDB CHARSET = utf8;
remarks:
Record payment method
3, Data import
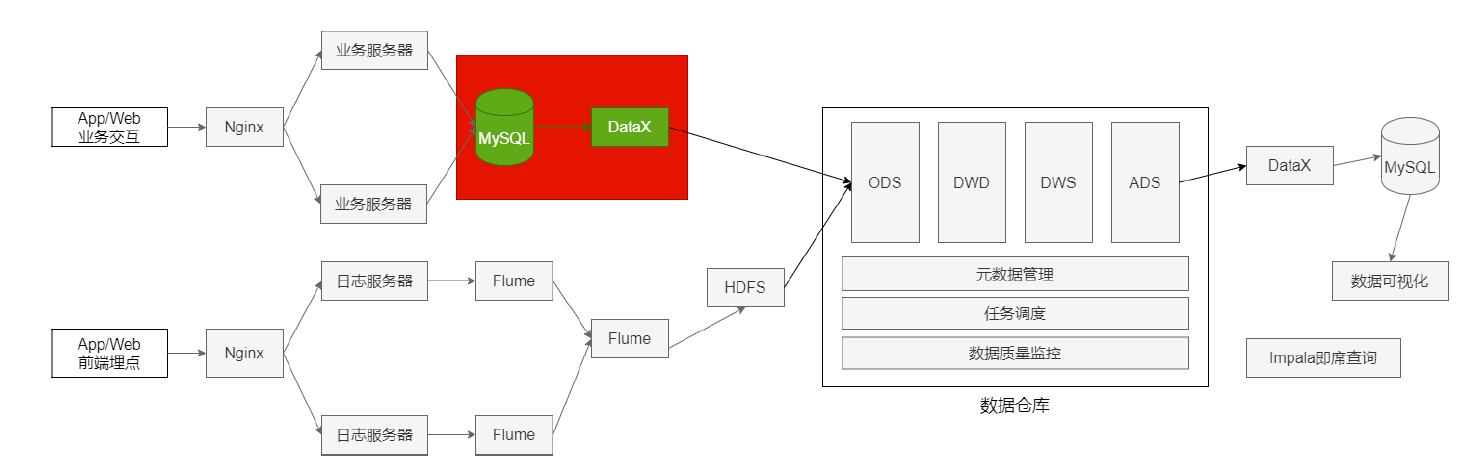
MYSQL export:
- Total quantity export
- Incremental export (export data of the previous day)
The business data is saved in MySQL, and the table data of the previous day is imported every morning.
-
The table has a small amount of data, and the full volume method is adopted to export MySQL
-
The table has a large amount of data, and can distinguish the new data every day according to the fields, and export MySQL in an incremental way.
-
Three incremental tables
- Order form_ trade_ orders
- Order product table_ order_ product
- Product information sheet_ product_ info
-
Four full scale
- Product classification table_ product_ category
- Merchant shop table_ shops
- Regional organization table of merchants_ shop_ admin_ org
- Payment method table_ payment
3.1 full data import
MYSQL => HDFS => Hive
Load the full amount of data every day to form a new partition; (it can guide how to create ODS tables)
MySQLReader =====> HdfsReader
ebiz.lagou_product_category ===> ods.ods_trade_product_category
3.1.1 product classification table
When using DataX export, you need to write json files.
/root/data/lagoudw/json/product_category.json
{
"job": {
"setting": {
"speed": {
"channel": 1
}
},
"content": [{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "12345678",
"column": [
"catId",
"parentId",
"catName",
"isShow",
"sortNum",
"isDel",
"createTime",
"level"
],
"connection": [{
"table": [
"lagou_product_category"
],
"jdbcUrl": [
"jdbc:mysql://linux123:3306/ebiz"
]
}]
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"defaultFS": "hdfs://linux121:9000",
"fileType": "text",
"path": "/user/data/trade.db/product_category/dt=$do_date",
"fileName": "product_category_$do_date",
"column": [{
"name": "catId",
"type": "INT"
},
{
"name": "parentId",
"type": "INT"
},
{
"name": "catName",
"type": "STRING"
},
{
"name": "isShow",
"type": "TINYINT"
},
{
"name": "sortNum",
"type": "INT"
},
{
"name": "isDel",
"type": "TINYINT"
},
{
"name": "createTime",
"type": "STRING"
},
{
"name": "level",
"type": "TINYINT"
}
],
"writeMode": "append",
"fieldDelimiter": ","
}
}
}]
}
}
remarks:
-
It is not necessary to use multiple channels for tables with small data volume; Using multiple channels generates multiple small files
-
Before executing the command, create the corresponding directory on HDFS: / user/data/trade.db/product_category/dt=yyyy-mm-dd
-
DATAX is executed on the server on which it is installed
do_date='2020-07-01' # Create directory hdfs dfs -mkdir -p /user/data/trade.db/product_category/dt=$do_date # data migration python $DATAX_HOME/bin/datax.py -p "-Ddo_date=$do_date" /root/data/lagoudw/json/product_category.json # Load data hive -e "alter table ods.ods_trade_product_category add partition(dt='$do_date')"
3.1.2 list of stores
lagou_shops =====> ods.ods_trade_shop
/root/data/lagoudw/json/shops.json
{
"job": {
"setting": {
"speed": {
"channel": 1
},
"errorLimit": {
"record": 0
}
},
"content": [{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "hive",
"password": "12345678",
"column": [
"shopId",
"userId",
"areaId",
"shopName",
"shopLevel",
"status",
"createTime",
"modifyTime"
],
"connection": [{
"table": [
"lagou_shops"
],
"jdbcUrl": [
"jdbc:mysql://linux123:3306/ebiz"
]
}]
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"defaultFS": "hdfs://linux121:9000",
"fileType": "text",
"path": "/user/data/trade.db/shops/dt=$do_date",
"fileName": "shops_$do_date",
"column": [{
"name": "shopId",
"type": "INT"
},
{
"name": "userId",
"type": "INT"
},
{
"name": "areaId",
"type": "INT"
},
{
"name": "shopName",
"type": "STRING"
},
{
"name": "shopLevel",
"type": "TINYINT"
},
{
"name": "status",
"type": "TINYINT"
},
{
"name": "createTime",
"type": "STRING"
},
{
"name": "modifyTime",
"type": "STRING"
}
],
"writeMode": "append",
"fieldDelimiter": ","
}
}
}]
}
}
do_date = '2020-07-01' # Create directory hdfs dfs -mkdir -p /user/data/trade.db/shops/dt=$do_date # data migration python $DATAX_HOME/bin/datax.py -p "-Ddo_date=$do_date" /root/data/lagoudw/json/shops.json # Load data hive -e "alter table ods.ods_trade_shops add partition(dt='$do_date')"
3.1.3 regional organization table of merchants
lagou_shop_admin_org =====> ods.ods_trade_shop_admin_org
/root/data/lagoudw/json/shop_org.json
{
"job": {
"setting": {
"speed": {
"channel": 1
},
"errorLimit": {
"record": 0
}
},
"content": [{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "12345678",
"column": [
"id",
"parentId",
"orgName",
"orgLevel",
"isDelete",
"createTime",
"updateTime",
"isShow",
"orgType"
],
"connection": [{
"table": [
"lagou_shop_admin_org"
],
"jdbcUrl": [
"jdbc:mysql://linux123:3306/ebiz"
]
}]
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"defaultFS": "hdfs://linux121:9000",
"fileType": "text",
"path": "/user/data/trade.db/shop_org/dt=$do_date",
"fileName": "shop_admin_org_$do_date.dat",
"column": [{
"name": "id",
"type": "INT"
},
{
"name": "parentId",
"type": "INT"
},
{
"name": "orgName",
"type": "STRING"
},
{
"name": "orgLevel",
"type": "TINYINT"
},
{
"name": "isDelete",
"type": "TINYINT"
},
{
"name": "createTime",
"type": "STRING"
},
{
"name": "updateTime",
"type": "STRING"
},
{
"name": "isShow",
"type": "TINYINT"
},
{
"name": "orgType",
"type": "TINYINT"
}
],
"writeMode": "append",
"fieldDelimiter": ","
}
}
}]
}
}
do_date='2020-07-01' # Create directory hdfs dfs -mkdir -p /user/data/trade.db/shop_org/dt=$do_date # data migration python $DATAX_HOME/bin/datax.py -p "-Ddo_date=$do_date" /root/data/lagoudw/json/shop_org.json # Load data hive -e "alter table ods.ods_trade_shop_admin_org add partition(dt='$do_date')"
3.1.4 payment method table
lagou_payements ====> ods.ods_trade_payments
/root/data/lagoudw/json/payment.json
{
"job": {
"setting": {
"speed": {
"channel": 1
},
"errorLimit": {
"record": 0
}
},
"content": [{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "12345678",
"column": [
"id",
"payMethod",
"payName",
"description",
"payOrder",
"online"
],
"connection": [{
"table": [
"lagou_payments"
],
"jdbcUrl": [
"jdbc:mysql://linux123:3306/ebiz"
]
}]
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"defaultFS": "hdfs://linux121:9000",
"fileType": "text",
"path": "/user/data/trade.db/trade_payments/dt=$do_date",
"fileName": "payments_$do_date.dat",
"column": [{
"name": "id",
"type": "INT"
},
{
"name": "payMethod",
"type": "STRING"
},
{
"name": "payName",
"type": "STRING"
},
{
"name": "description",
"type": "STRING"
},
{
"name": "payOrder",
"type": "INT"
},
{
"name": "online",
"type": "TINYINT"
}
],
"writeMode": "append",
"fieldDelimiter": ","
}
}
}]
}
}
do_date='2020-07-01' # Create directory hdfs dfs -mkdir -p /user/data/trade.db/trade_payments/dt=$do_date # data migration python $DATAX_HOME/bin/datax.py -p "-Ddo_date=$do_date" /root/data/lagoudw/json/payment.json # Load data hive -e "alter table ods.ods_trade_payments add partition(dt='$do_date')"
3.2 incremental data import
Initialize data loading (only once); The previous full load can be used as the initial load
Load incremental data every day (daily data forms a partition)
3.2.1 order form
lagou_trade_orders =====> ods.ods_trade_orders
/root/data/lagoudw/json/orders.json
Note: for the selection of conditions, select the time period modiriedTime
{
"job": {
"setting": {
"speed": {
"channel": 1
},
"errorLimit": {
"record": 0
}
},
"content": [{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "12345678",
"connection": [{
"querySql": [
"select orderId, orderNo, userId,status, productMoney, totalMoney, payMethod, isPay, areaId,tradeSrc, tradeType, isRefund, dataFlag, createTime, payTime,modifiedTime from lagou_trade_orders where date_format(modifiedTime, '%Y-%m-%d')='$do_date'"
],
"jdbcUrl": [
"jdbc:mysql://linux123:3306/ebiz"
]
}]
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"defaultFS": "hdfs://linux121:9000",
"fileType": "text",
"path": "/user/data/trade.db/orders/dt=$do_date",
"fileName": "orders_$do_date",
"column": [{
"name": "orderId",
"type": "INT"
},
{
"name": "orderNo",
"type": "STRING"
},
{
"name": "userId",
"type": "BIGINT"
},
{
"name": "status",
"type": "TINYINT"
},
{
"name": "productMoney",
"type": "Float"
},
{
"name": "totalMoney",
"type": "Float"
},
{
"name": "payMethod",
"type": "TINYINT"
},
{
"name": "isPay",
"type": "TINYINT"
},
{
"name": "areaId",
"type": "INT"
},
{
"name": "tradeSrc",
"type": "TINYINT"
},
{
"name": "tradeType",
"type": "INT"
},
{
"name": "isRefund",
"type": "TINYINT"
},
{
"name": "dataFlag",
"type": "TINYINT"
},
{
"name": "createTime",
"type": "STRING"
},
{
"name": "payTime",
"type": "STRING"
},
{
"name": "modifiedTime",
"type": "STRING"
}
],
"writeMode": "append",
"fieldDelimiter": ","
}
}
}]
}
}
-- MySQL Time date conversion in select date_format(createTime, '%Y-%m-%d'), count(*) from lagou_trade_orders group by date_format(createTime, '%Y-%m-%d');
do_date='2020-07-12' # Create directory hdfs dfs -mkdir -p /user/data/trade.db/orders/dt=$do_date # data migration python $DATAX_HOME/bin/datax.py -p "-Ddo_date=$do_date" /root/data/lagoudw/json/orders.json # Load data hive -e "alter table ods.ods_trade_orders add partition(dt='$do_date')"
3.2.2 order details
lagou_order_product ====> ods.ods_trade_order_product
/root/data/lagoudw/json/order_product.json
{
"job": {
"setting": {
"speed": {
"channel": 1
},
"errorLimit": {
"record": 0
}
},
"content": [{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "12345678",
"connection": [{
"querySql": [
"select id, orderId, productId,productNum, productPrice, money, extra, createTime from lagou_order_product where date_format(createTime, '%Y-%m-%d')= '$do_date' "
],
"jdbcUrl": [
"jdbc:mysql://linux123:3306/ebiz"
]
}]
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"defaultFS": "hdfs://linux121:9000",
"fileType": "text",
"path": "/user/data/trade.db/order_product/dt=$do_date",
"fileName": "order_product_$do_date.dat",
"column": [{
"name": "id",
"type": "INT"
},
{
"name": "orderId",
"type": "INT"
},
{
"name": "productId",
"type": "INT"
},
{
"name": "productNum",
"type": "INT"
},
{
"name": "productPrice",
"type": "Float"
},
{
"name": "money",
"type": "Float"
},
{
"name": "extra",
"type": "STRING"
},
{
"name": "createTime",
"type": "STRING"
}
],
"writeMode": "append",
"fieldDelimiter": ","
}
}
}]
}
}
do_date='2020-07-12' # Create directory hdfs dfs -mkdir -p /user/data/trade.db/order_product/dt=$do_date # data migration python $DATAX_HOME/bin/datax.py -p "-Ddo_date=$do_date" /root/data/lagoudw/json/order_product.json # Load data hive -e "alter table ods.ods_trade_order_product add partition(dt='$do_date')"
3.2.3 product information table
lagou_product_info =====> ods.ods_trade_product_info
/root/data/lagoudw/json/product_info.json
{
"job": {
"setting": {
"speed": {
"channel": 1
},
"errorLimit": {
"record": 0
}
},
"content": [{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "12345678",
"connection": [{
"querySql": [
"select productid, productname,shopid, price, issale, status, categoryid, createtime,modifytime from lagou_product_info where date_format(modifyTime, '%Y-%m-%d') = '$do_date' "
],
"jdbcUrl": [
"jdbc:mysql://linux123:3306/ebiz"
]
}]
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"defaultFS": "hdfs://linux121:9000",
"fileType": "text",
"path": "/user/data/trade.db/product_info/dt=$do_date",
"fileName": "product_info_$do_date.dat",
"column": [{
"name": "productid",
"type": "BIGINT"
},
{
"name": "productname",
"type": "STRING"
},
{
"name": "shopid",
"type": "STRING"
},
{
"name": "price",
"type": "FLOAT"
},
{
"name": "issale",
"type": "TINYINT"
},
{
"name": "status",
"type": "TINYINT"
},
{
"name": "categoryid",
"type": "STRING"
},
{
"name": "createTime",
"type": "STRING"
},
{
"name": "modifytime",
"type": "STRING"
}
],
"writeMode": "append",
"fieldDelimiter": ","
}
}
}]
}
}
do_date='2020-07-12' # Create directory hdfs dfs -mkdir -p /user/data/trade.db/product_info/dt=$do_date # data migration python $DATAX_HOME/bin/datax.py -p "-Ddo_date=$do_date" /root/data/lagoudw/json/product_info.json # Load data hive -e "alter table ods.ods_trade_product_info add partition(dt='$do_date')"
4, ODS layer building table and data loading
ODS floor construction table
- The ODS layered table structure is basically similar to the data source (column name and data type)
- The table names of ODS layer follow the unified specification
4.1 ODS floor construction table
All tables are partitioned tables; The separator between fields is', '; A location is specified for the table's data file
DROP TABLE IF EXISTS `ods.ods_trade_orders`; CREATE EXTERNAL TABLE `ods.ods_trade_orders`( `orderid` int, `orderno` string, `userid` bigint, `status` tinyint, `productmoney` decimal(10, 0), `totalmoney` decimal(10, 0), `paymethod` tinyint, `ispay` tinyint, `areaid` int, `tradesrc` tinyint, `tradetype` int, `isrefund` tinyint, `dataflag` tinyint, `createtime` string, `paytime` string, `modifiedtime` string) COMMENT 'Order form' PARTITIONED BY (`dt` string) row format delimited fields terminated by ',' location '/user/data/trade.db/orders/'; DROP TABLE IF EXISTS `ods.ods_trade_order_product`; CREATE EXTERNAL TABLE `ods.ods_trade_order_product`( `id` string, `orderid` decimal(10,2), `productid` string, `productnum` string, `productprice` string, `money` string, `extra` string, `createtime` string) COMMENT 'Order Details ' PARTITIONED BY (`dt` string) row format delimited fields terminated by ',' location '/user/data/trade.db/order_product/'; DROP TABLE IF EXISTS `ods.ods_trade_product_info`; CREATE EXTERNAL TABLE `ods.ods_trade_product_info`( `productid` bigint, `productname` string, `shopid` string, `price` decimal(10,0), `issale` tinyint, `status` tinyint, `categoryid` string, `createtime` string, `modifytime` string) COMMENT 'Product information sheet' PARTITIONED BY (`dt` string) row format delimited fields terminated by ',' location '/user/data/trade.db/product_info/'; DROP TABLE IF EXISTS `ods.ods_trade_product_category`; CREATE EXTERNAL TABLE `ods.ods_trade_product_category`( `catid` int, `parentid` int, `catname` string, `isshow` tinyint, `sortnum` int, `isdel` tinyint, `createtime` string, `level` tinyint) COMMENT 'Product classification table' PARTITIONED BY (`dt` string) row format delimited fields terminated by ',' location '/user/data/trade.db/product_category'; DROP TABLE IF EXISTS `ods.ods_trade_shops`; CREATE EXTERNAL TABLE `ods.ods_trade_shops`( `shopid` int, `userid` int, `areaid` int, `shopname` string, `shoplevel` tinyint, `status` tinyint, `createtime` string, `modifytime` string) COMMENT 'Merchant store list' PARTITIONED BY (`dt` string) row format delimited fields terminated by ',' location '/user/data/trade.db/shops'; DROP TABLE IF EXISTS `ods.ods_trade_shop_admin_org`; CREATE EXTERNAL TABLE `ods.ods_trade_shop_admin_org`( `id` int, `parentid` int, `orgname` string, `orglevel` tinyint, `isdelete` tinyint, `createtime` string, `updatetime` string, `isshow` tinyint, `orgType` tinyint) COMMENT 'Merchant regional organization table' PARTITIONED BY (`dt` string) row format delimited fields terminated by ',' location '/user/data/trade.db/shop_org/'; DROP TABLE IF EXISTS `ods.ods_trade_payments`; CREATE EXTERNAL TABLE `ods.ods_trade_payments`( `id` string, `paymethod` string, `payname` string, `description` string, `payorder` int, `online` tinyint) COMMENT 'Payment method table' PARTITIONED BY (`dt` string) row format delimited fields terminated by ',' location '/user/data/trade.db/payments/';
4.2 ODS layer data loading
DataX just imports the data into HDFS, and the data is not associated with Hive table.
Script tasks: data migration, data loading to ODS layer;
For incremental data loading: for initial data loading, the task is executed only once and is not in the script.
/root/data/lagoudw/script/core_trade/ods_load_trade.sh
#!/bin/bash source /etc/profile if [ -n "$1" ] ;then do_date=$1 else do_date=`date -d "-1 day" +%F` fi # Create directory hdfs dfs -mkdir -p /user/data/trade.db/product_category/dt=$do_date hdfs dfs -mkdir -p /user/data/trade.db/shops/dt=$do_date hdfs dfs -mkdir -p /user/data/trade.db/shop_org/dt=$do_date hdfs dfs -mkdir -p /user/data/trade.db/payments/dt=$do_date hdfs dfs -mkdir -p /user/data/trade.db/orders/dt=$do_date hdfs dfs -mkdir -p /user/data/trade.db/order_product/dt=$do_date hdfs dfs -mkdir -p /user/data/trade.db/product_info/dt=$do_date # data migration python $DATAX_HOME/bin/datax.py -p "-Ddo_date=$do_date" /root/data/lagoudw/json/product_category.json python $DATAX_HOME/bin/datax.py -p "-Ddo_date=$do_date" /root/data/lagoudw/json/shops.json python $DATAX_HOME/bin/datax.py -p "-Ddo_date=$do_date" /root/data/lagoudw/json/shop_org.json python $DATAX_HOME/bin/datax.py -p "-Ddo_date=$do_date" /root/data/lagoudw/json/payments.json python $DATAX_HOME/bin/datax.py -p "-Ddo_date=$do_date" /root/data/lagoudw/json/orders.json python $DATAX_HOME/bin/datax.py -p "-Ddo_date=$do_date" /root/data/lagoudw/json/order_product.json python $DATAX_HOME/bin/datax.py -p "-Ddo_date=$do_date" /root/data/lagoudw/json/product_info.json # Loading ODS layer data sql=" alter table ods.ods_trade_orders add partition(dt='$do_date'); alter table ods.ods_trade_order_product add partition(dt='$do_date'); alter table ods.ods_trade_product_info add partition(dt='$do_date'); alter table ods.ods_trade_product_category add partition(dt='$do_date'); alter table ods.ods_trade_shops add partition(dt='$do_date'); alter table ods.ods_trade_shop_admin_org add partition(dt='$do_date'); alter table ods.ods_trade_payments add partition(dt='$do_date'); " hive -e "$sql"
characteristic:
Heavy workload, cumbersome and error prone; Work with data acquisition;
5, Slow change dimension and periodic fact table
5.1 slow change dimension
Slow changing dimensions (SCD): in the real world, the attributes of dimensions change slowly with the passage of time (slow is relative to the fact table, and the data in the fact table changes faster than the dimension table).
The problem of dealing with the historical change information of the dimension table is called the problem of dealing with the slow change dimension, or SCD problem for short. There are several ways to deal with slow change dimensions:
- Keep original value (not commonly used)
- Direct coverage (not commonly used)
- Add new attribute column (not commonly used)
- Snapshot table
- Zipper Watch
5.1.1 retain original value
The dimension attribute value will not be changed and the original value will be retained.
For example, the time of goods on the shelves: after a commodity is on the shelves for sale, it is off the shelves for other reasons, and then it is on the shelves again. This situation produces multiple times of goods on the shelves for sale. This method is adopted if the business focuses on the time when the goods are first put on the shelves.
5.1.2 direct coverage
Modify the dimension attribute to the latest value and overwrite it directly without retaining historical information.
For example, the category to which the commodity belongs, when the commodity category changes, it is directly rewritten as a new category.
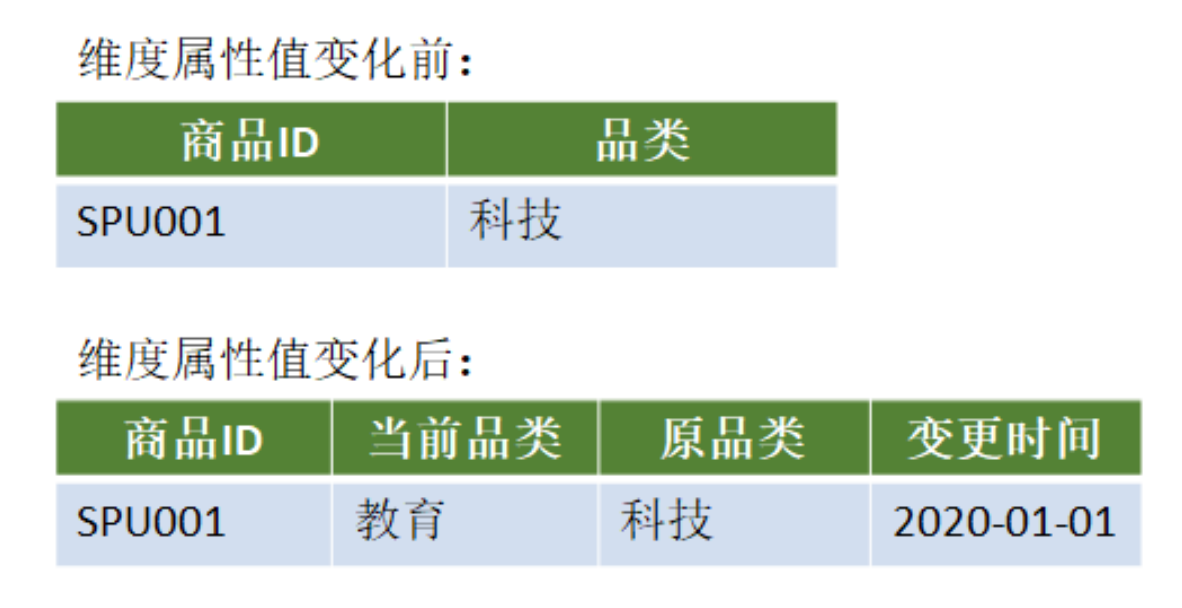
5.1.3 add new attribute column
Add a new column in the dimension table. The original attribute column stores the attribute value of the previous version, and the current attribute column stores the attribute value of the current version. You can also add a column to record the change time.
Disadvantages: only the last change information can be recorded
5.1.4 snapshot table
Keep a full copy of the data every day.
Simple and efficient. The disadvantage is that the information is repeated, wasting disk space
Usage range: dimension cannot be too large
There are many use scenarios and a wide range; Generally speaking, dimension tables are not large.
5.1.1 zipper table
Zipper table is suitable for: the table has a large amount of data, and the data will be added and changed, but most of them are unchanged (the percentage of data change is small) and change slowly (for example, some basic user attributes in the user information table in e-commerce cannot change every day). The main purpose is to save storage space.
Applicable scenarios:
- The table has a large amount of data
- Some fields in the table will be updated
- The proportion of changes recorded in the table is not high
- Historical information needs to be retained
5.2 application cases of dimension table
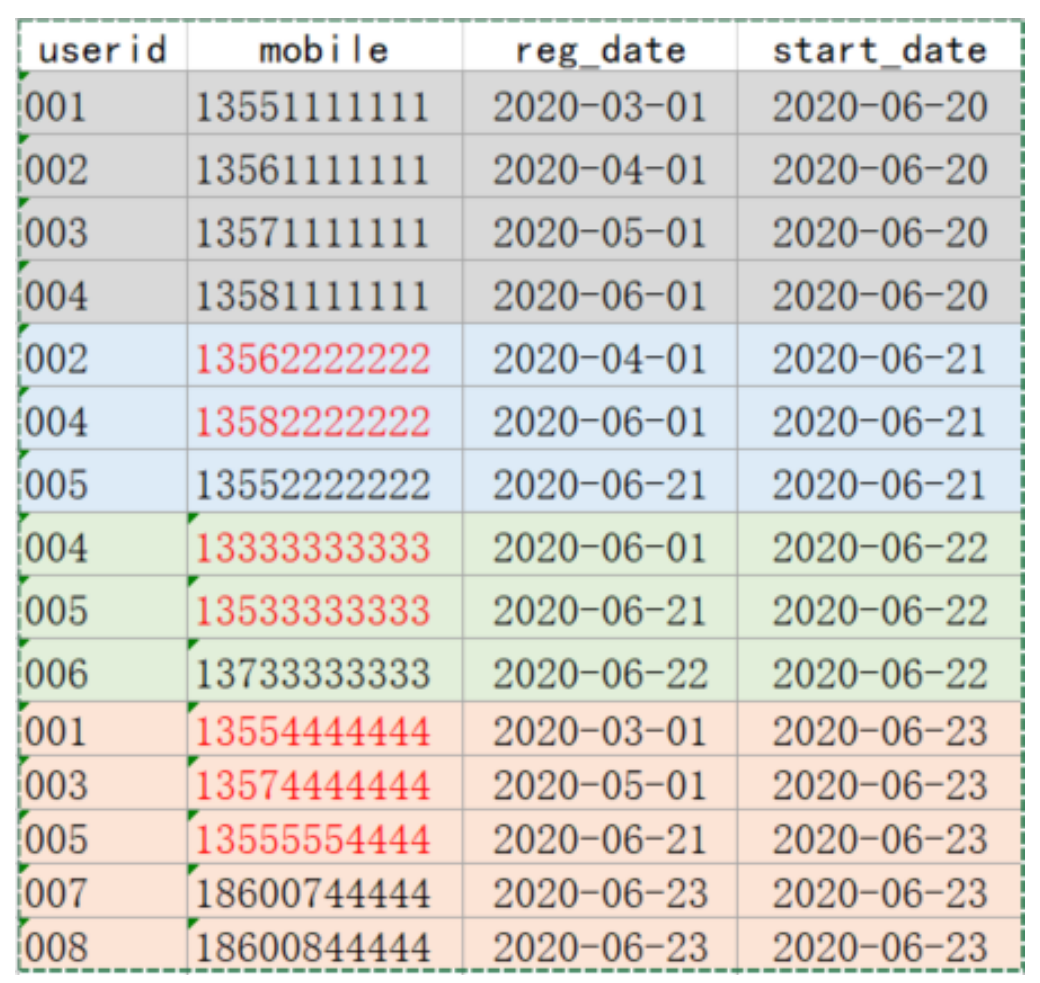
5.2.1 create table and load data (preparation)
-- User information DROP TABLE IF EXISTS test.userinfo; CREATE TABLE test.userinfo( userid STRING COMMENT 'User number', mobile STRING COMMENT 'phone number', regdate STRING COMMENT 'Date of registration') COMMENT 'User information' PARTITIONED BY (dt string) row format delimited fields terminated by ','; -- Zipper table (storing user history information) -- Zipper table is not a partition table; Two more fields start_date,end_date DROP TABLE IF EXISTS test.userhis; CREATE TABLE test.userhis( userid STRING COMMENT 'User number', mobile STRING COMMENT 'phone number', regdate STRING COMMENT 'Date of registration', start_date STRING, end_date STRING) COMMENT 'User information zipper table' row format delimited fields terminated by ',';
-- data(/root/data/lagoudw/data/userinfo.dat) 001,13551111111,2020-03-01,2020-06-20 002,13561111111,2020-04-01,2020-06-20 003,13571111111,2020-05-01,2020-06-20 004,13581111111,2020-06-01,2020-06-20 002,13562222222,2020-04-01,2020-06-21 004,13582222222,2020-06-01,2020-06-21 005,13552222222,2020-06-21,2020-06-21 004,13333333333,2020-06-01,2020-06-22 005,13533333333,2020-06-21,2020-06-22 006,13733333333,2020-06-22,2020-06-22 001,13554444444,2020-03-01,2020-06-23 003,13574444444,2020-05-01,2020-06-23 005,13555554444,2020-06-21,2020-06-23 007,18600744444,2020-06-23,2020-06-23 008,18600844444,2020-06-23,2020-06-23 -- Static partition data loading (omitted) /root/data/lagoudw/data/userinfo0620.dat 001,13551111111,2020-03-01 002,13561111111,2020-04-01 003,13571111111,2020-05-01 004,13581111111,2020-06-01 load data local inpath '/root/data/lagoudw/data/userinfo0620.dat' into table test.userinfo partition(dt='2020-06-20');
Dynamic partition data loading
-- Dynamic partition data loading: the partition value is not fixed and is determined by the input data
-- Create intermediate table(Non partitioned table)
drop table if exists test.tmp1;
create table test.tmp1 as
select * from test.userinfo;
-- tmp1 Non partitioned table, using the system default field delimiter'\001'
alter table test.tmp1 set serdeproperties('field.delim'=',');
-- Load data to intermediate table
load data local inpath '/root/data/lagoudw/data/userinfo.dat' into table test.tmp1;
-- Load data from intermediate table to partitioned table
-- Direct to userinfo The following error occurs when inserting data into the table
FAILED: SemanticException [Error 10096]: Dynamic partition strict mode requires at least one static partition column. To turn this off set hive.exec.dynamic.partition.mode=nonstrict
-- The solution is to change the partition mode to non strict mode
set hive.exec.dynamic.partition.mode=nonstrict;
insert into table test.userinfo partition(dt) select * from test.tmp1;
Parameters related to dynamic partitioning
-
hive.exec.dynamic.partition
- Default Value: false prior to Hive 0.9.0; true in Hive 0.9.0 and later
- Added In: Hive 0.6.0
- Whether or not to allow dynamic partitions in DML/DDL indicates whether the dynamic partitions function is enabled
-
hive.exec.dynamic.partition.mode
-
Default Value: strict
-
Added In: Hive 0.6.0
-
In strict mode, the user must specify at least one static partition in case the user accidentally overwrites all partitions. In nonstrict mode all partitions are allowed to be dynamic.
-
Set to nonstrict to support INSERT ... VALUES, UPDATE, and DELETE transactions (Hive 0.14.0 and later).
-
strict requires at least one static partition
-
nonstrict can be all dynamic partitions
-
-
hive.exec.max.dynamic.partitions
-
Default Value: 1000
-
Added In: Hive 0.6.0
-
Maximum number of dynamic partitions allowed to be created in total
Indicates the maximum number of dynamic partitions that can be created by a dynamic partition statement, exceeding which an error is reported
-
-
hive.exec.max.dynamic.partitions.pernode
-
Default Value: 100
-
Added In: Hive 0.6.0
-
Maximum number of dynamic partitions allowed to be created in each mapper/reducer node
Indicates the maximum number of dynamic partitions that can be created by each mapper / reducer. The default is 100. If it exceeds 100, an error will be reported.
-
-
hive.exec.max.created.files
-
Default Value: 100000
-
Added In: Hive 0.7.0
-
Maximum number of HDFS files created by all mappers/reducers in a MapReduce job.
Indicates the maximum number of files that can be created by an MR job, exceeding which an error is reported.
-
5.2.2 realization of zipper Watch
userinfo (partition table) = > userid, mobile, regdate = > daily changed data (modified + new) / historical data (the first day)
userhis (zipper table) = > two more fields start_date / end_date
-- step
-- 1. userinfo Initialization (2020)-06-20) Get historical data
001,13551111111,2020-03-01,2020-06-20
002,13561111111,2020-04-01,2020-06-20
003,13571111111,2020-05-01,2020-06-20
004,13581111111,2020-06-01,2020-06-20
-- 2. Initialize zipper table (2020)-06-20) userinfo => userhis
insert overwrite table test.userhis
select userid,mobile,regdate,dt as start_date,'9999-12-31' as end_date
from test.userinfo where dt='2020-06-20'
-- 3. New data (2020)-06-21) Get new data
002,13562222222,2020-04-01,2020-06-21
004,13582222222,2020-06-01,2020-06-21
005,13552222222,2020-06-21,2020-06-21
-- 4. Build zipper table( userhis)(2020-06-21)[[core] userinfo(2020-06-21) + userhis => userhis
-- userinf New data
-- userhis historical data
-- Step 1: process new data[ userinfo](Processing logic (similar to loading historical data)
select userid,mobile,regdate,dt as start_date,'9999-12-31' as end_date
from test.userinfo where dt='2020-06-21'
-- Step 2: process historical data[ userhis](Historical data includes two parts: changed and unchanged)
-- Changing: start_date unchanged end_date Incoming date -1
-- Unchanged: no treatment
-- Observation data
select A.userid, B.userid, B.mobile, B.regdate, B.start_Date,
B.end_date from
(select * from test.userinfo where dt='2020-06-21') A
right join test.userhis B
on A.userid=B.userid;
-- =========================================================================================
a.userid b.userid b.mobile b.regdate b.start_date b.end_date
NULL 001 13551111111 2020-03-01 2020-06-20 9999-12-31
002 002 13561111111 2020-04-01 2020-06-20 9999-12-31
NULL 003 13571111111 2020-05-01 2020-06-20 9999-12-31
004 004 13581111111 2020-06-01 2020-06-20 9999-12-31
-- =========================================================================================
-- to write SQL,Process historical data
select B.userid, B.mobile, B.regdate, B.start_Date,
CASE WHEN B.end_date ='9999-12-31' AND A.userid is not null
then date_add('2020-06-21',-1) else B.end_date end as end_date
from (select * from test.userinfo where dt='2020-06-21') A
right join test.userhis B
on A.userid=B.userid;
-- =========================================================================
b.userid b.mobile b.regdate b.start_date end_date
001 13551111111 2020-03-01 2020-06-20 9999-12-31
002 13561111111 2020-04-01 2020-06-20 2020-06-20
003 13571111111 2020-05-01 2020-06-20 9999-12-31
004 13581111111 2020-06-01 2020-06-20 2020-06-20
-- =========================================================================
-- Step 3: final processing (add)+(historical data)
insert overwrite table test.userhis
select userid,mobile,regdate,dt as start_date,'9999-12-31' as end_date
from test.userinfo where dt='2020-06-21'
union all
select B.userid, B.mobile, B.regdate, B.start_Date,
CASE WHEN B.end_date ='9999-12-31' AND A.userid is not null
then date_add('2020-06-21',-1) else B.end_date end as end_date
from (select * from test.userinfo where dt='2020-06-21') A
right join test.userhis B
on A.userid=B.userid;
-- 5. New data on the third day (2020)-06-22): Get new data
004,13333333333,2020-06-01,2020-06-22
005,13533333333,2020-06-21,2020-06-22
006,13733333333,2020-06-22,2020-06-22
-- 6,Build zipper table (2020)-06-22) userinfo(2020-06-22) + userhis =>
userhis
-- 7,New data on the fourth day (2020)-06-23)
001,13554444444,2020-03-01,2020-06-23
003,13574444444,2020-05-01,2020-06-23
005,13555554444,2020-06-21,2020-06-23
007,18600744444,2020-06-23,2020-06-23
008,18600844444,2020-06-23,2020-06-23
-- 8,Build zipper table(2020-06-23)
Script for processing zipper table (test script): (/ root/data/lagoudw/data/userzipper.sh)
#!/bin/bash
source /etc/profile
if [ -n "$1" ] ;then
do_date=$1
else
do_date=`date -d "-1 day" +%F`
fi
sql="insert overwrite table test.userhis
select userid, mobile, regdate, dt as start_date, '9999-12-
31' as end_date
from test.userinfo
where dt='$do_date'
union all
select B.userid,
B.mobile,
B.regdate,
B.start_Date,
case when B.end_date='9999-12-31' and A.userid is not
null
then date_add('$do_date', -1)
else B.end_date
end as end_date
from (select * from test.userinfo where dt='$do_date') A
right join test.userhis B
on A.userid=B.userid;
"
hive -e "$sql"
Use of zipper Watch
-- View the latest data in the zipper table(2020-06-23 Future data)
select * from userhis where end_date='9999-12-31';
-- View the date data given in the zipper table("2020-06-22")
select * from userhis where start_date <= '2020-06-22' and end_date >= '2020-06-22';
-- View the date data given in the zipper table("2020-06-21")
select * from userhis where start_date <= '2020-06-21' and end_date >= '2020-06-21';
-- View the date data given in the zipper table("2020-06-20")
select * from userhis where start_date <= '2020-06-20' and end_date >= '2020-06-20';
5.2.3 rollback of zipper table
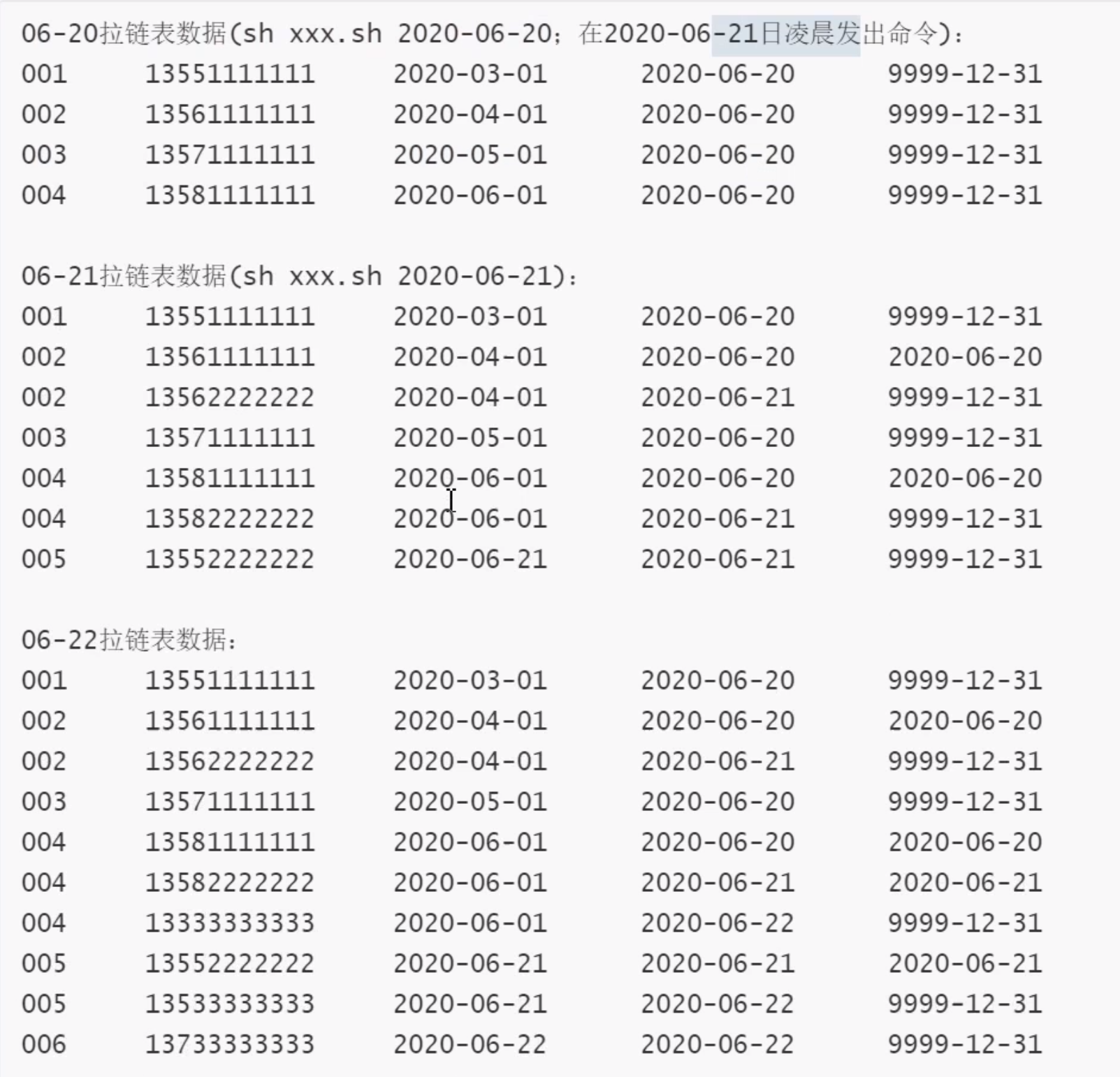
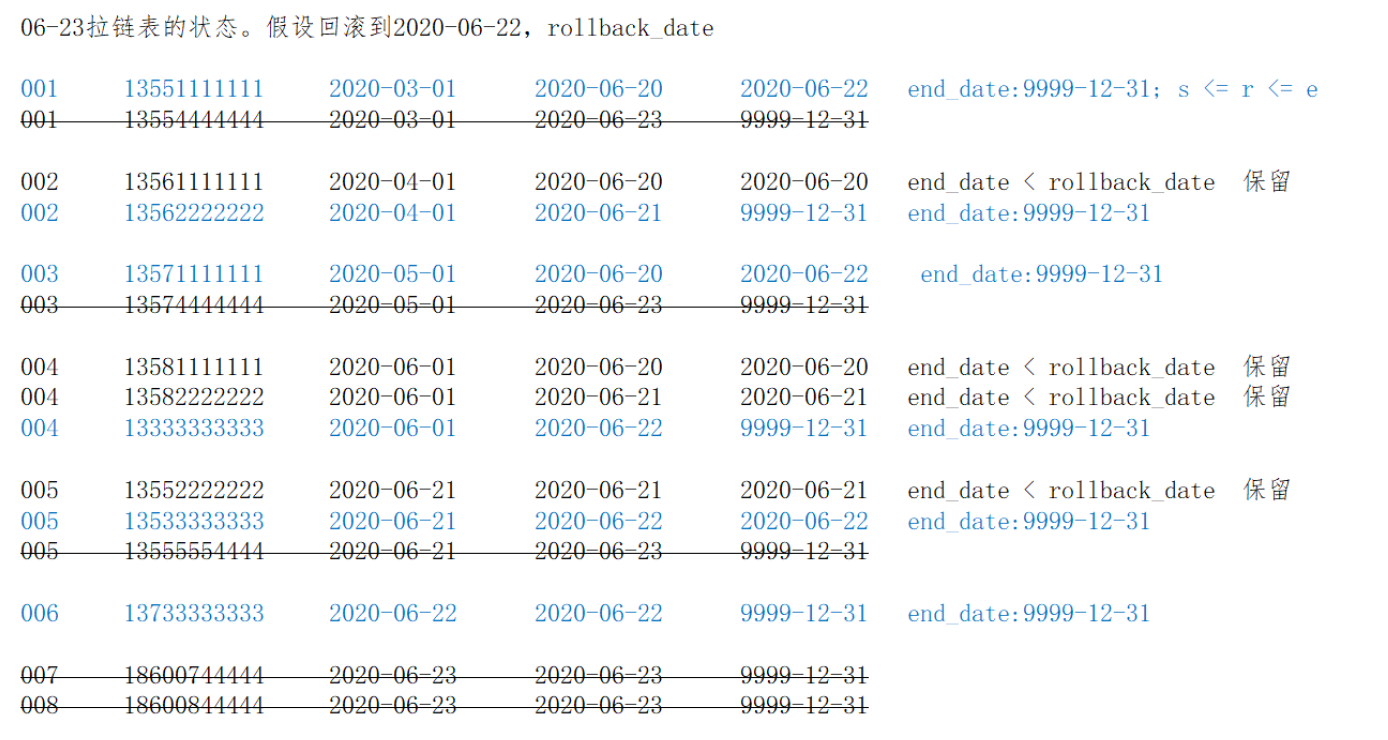
For various reasons, it is necessary to restore the zipper table to the data of rollback_date. At this time:
End_date < rollback_date, i.e. end date < rollback date. It means that the data in this row is generated before rollback_date and needs to be retained as is.
Start_date < = rollback_date < = end_date, i.e. start date < = rollback date < = end date. These data are generated after the rollback date, but need to be modified. Change the end_)date to 9999-12-31
Don't worry about other data
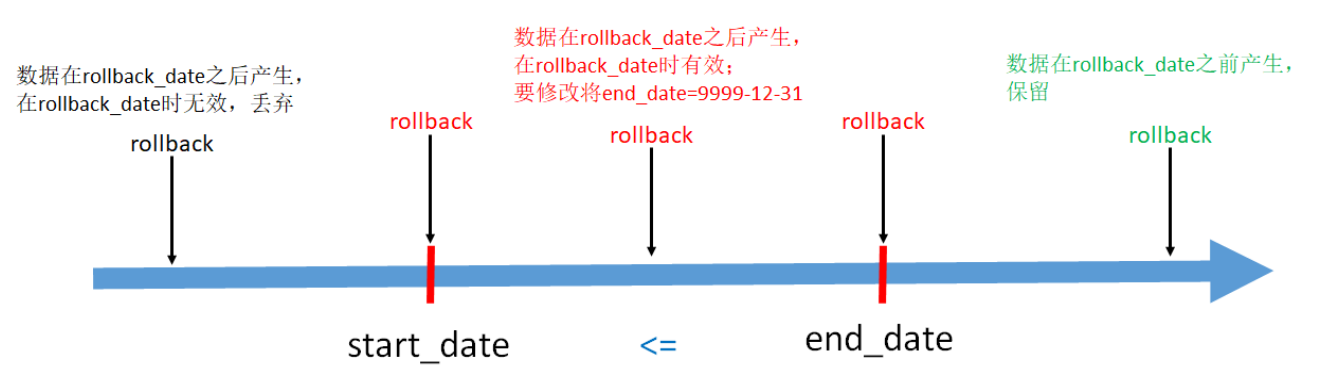
Code according to the above scheme:
- Process the data with end_date < rollback_date and keep it
select userid, mobile, regdate, start_date, end_date, '1' as tag from test.userhis where end_date < '2020-06-22';
- Process the data of start_date < = rollback_date < = end_date, and set end_date = 9999-12-31
select userid, mobile, regdate, start_date, '9999-12-31' as end_date, '2' as tag from test.userhis where start_date <= '2020-06-22' and end_date >= '2020-06-22';
- Write the data of the previous two steps into the temporary table tmp (zipper table)
drop table test.tmp; create table test.tmp as select userid, mobile, regdate, start_date, end_date, '1' as tag from test.userhis where end_date < '2020-06-22' union all select userid, mobile, regdate, start_date, '9999-12-31' as end_date, '2' as tag from test.userhis where start_date <= '2020-06-22' and end_date >= '2020-06-22'; -- Query results select * from test.tmp cluster by userid, start_date;
5.2.4 simulation script
/root/data/lagoudw/data/zippertmp.sh
#!/bin/bash source /etc/profile if [ -n "$1" ] ;then do_date=$1 else do_date=`date -d "-1 day" +%F` fi sql=" drop table test.tmp; create table test.tmp as select userid, mobile, regdate, start_date, end_date, '1' as tag from test.userhis where end_date < '$do_date' union all select userid, mobile, regdate, start_date, '9999-12-31' as end_date, '2' as tag from test.userhis where start_date <= '$do_date' and end_date >= '$do_date'; " hive -e "$sql"
Rollback day by day, check data
Scheme 2: save the incremental data (userinfo) for a period of time, and back up the zipper table regularly (for example, once a month); if you need to roll back, run the incremental data directly on the zipper table of Beifen. The processing is simple
5.3 periodic fact sheet
There is the following order form, and there are three records (001 / 002 / 003) on June 20:
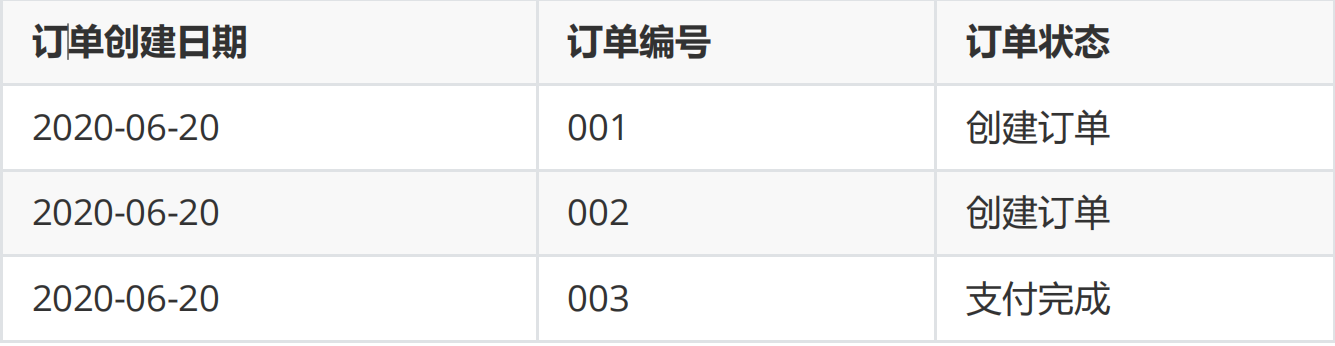
There were 5 records on June 21, including 2 new records (004 / 005) and 1 modified record (001)
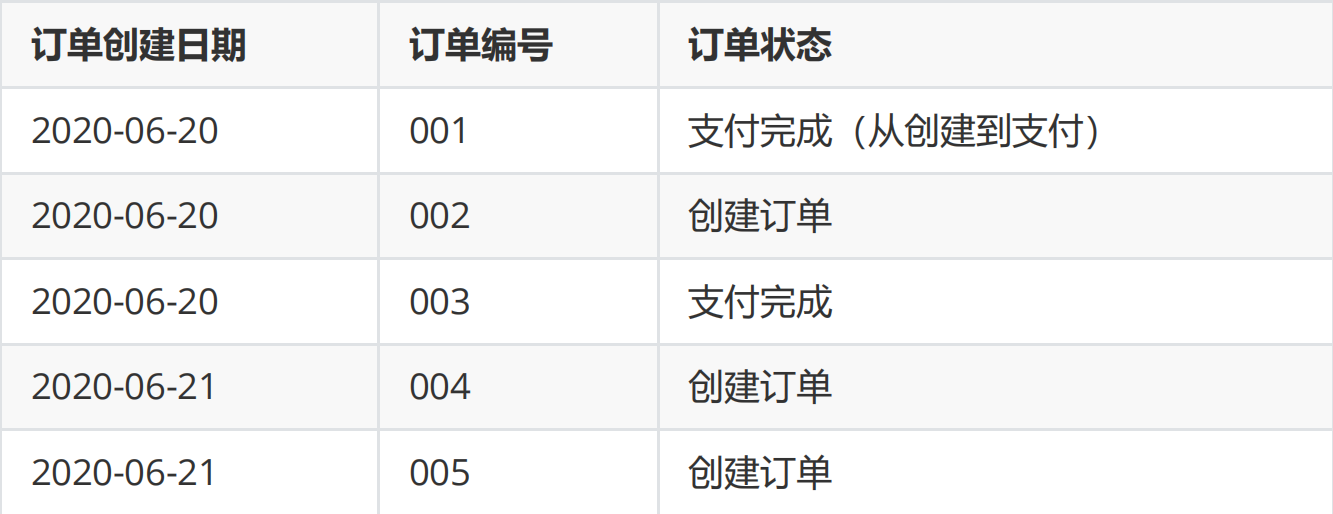
On June 22, there were 6 records in the table, including 1 new record (006) and 2 modified records (003 / 005):
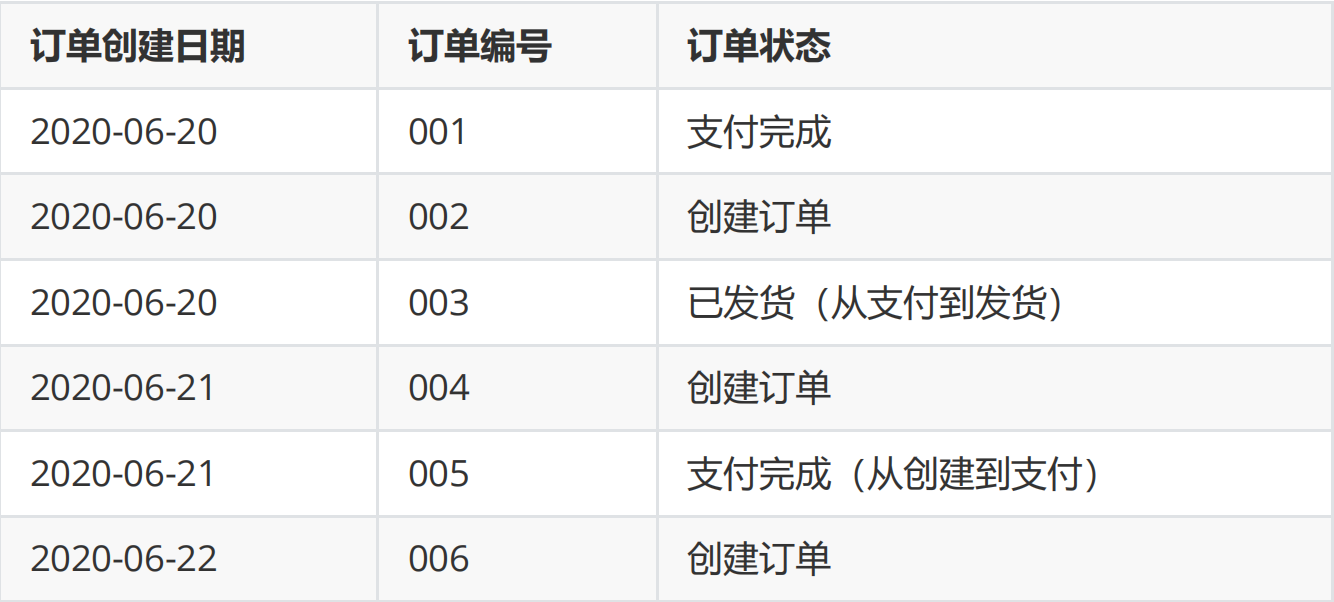
Processing method of order fact table:
- Only one full volume is reserved. The data is the same as the record on June 22. If you need to view the status of order 001 on June 21, it cannot be met;
- Keep a full copy every day. All historical information can be found in the data warehouse, but the amount of data is large, and many information is repeated, which will cause great storage waste;
The following table can be used to save historical information by using the zipper table. The historical zipper table can not only meet the needs of saving historical data, but also save storage resources.
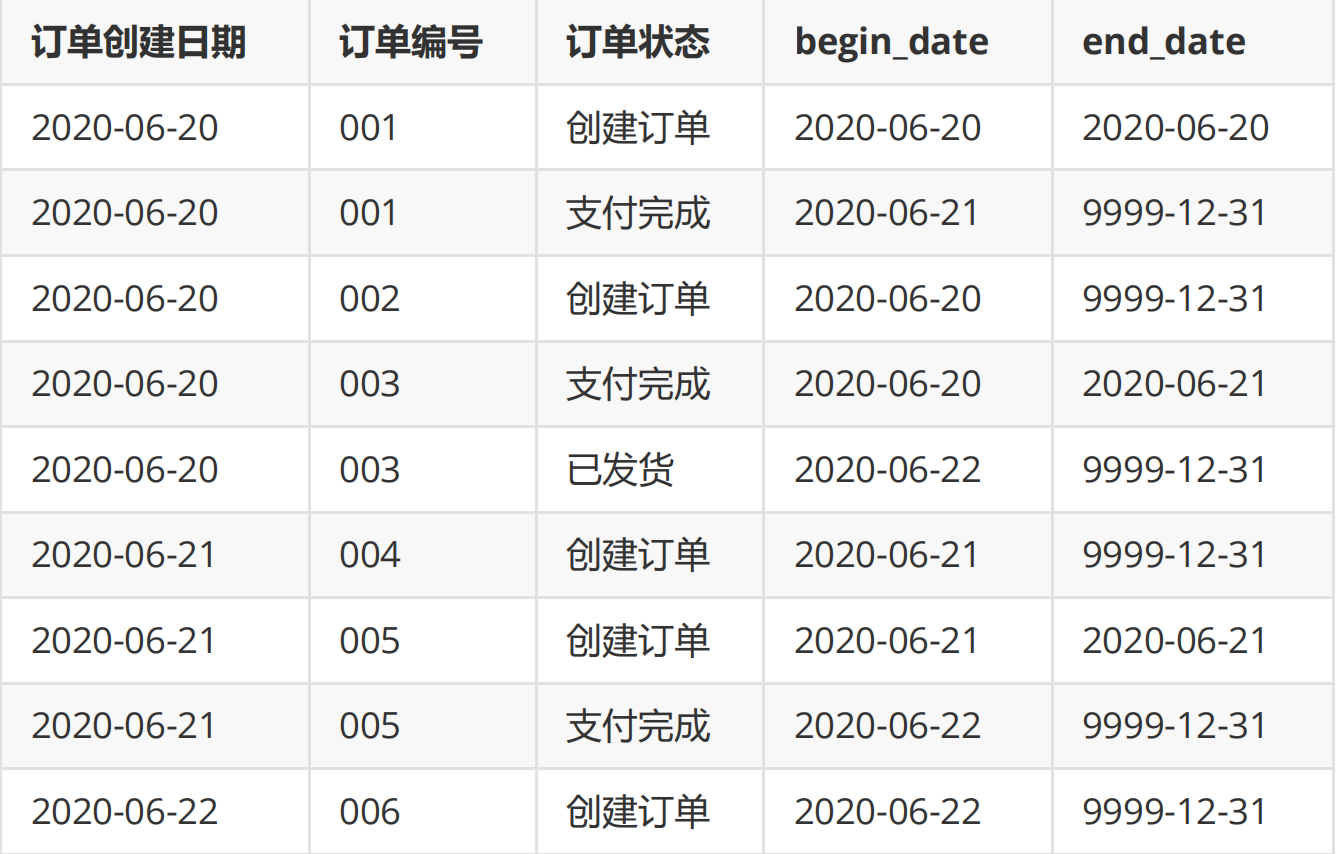
5.3.1 preconditions
- The refresh frequency of the order table is one day. When filled in, the incremental data of the previous day is obtained;
- If the status of an order changes many times in a day, only the information of the last status is recorded;
- Order status includes three: create, pay and complete;
- The creation time and modification time are only days. If there is no status modification time in the source order table, it is troublesome to extract the increment. A mechanism is needed to ensure that the daily increment data can be extracted;
The ODS layer of the data warehouse has an order table, and the data is divided by day to store the daily incremental data:
DROP TABLE test.ods_orders; CREATE TABLE test.ods_orders( orderid INT, createtime STRING, modifiedtime STRING, status STRING ) PARTITIONED BY (dt STRING) row format delimited fields terminated by ',';
The DWD layer of the data warehouse has an order zipper table to store the historical status data of the order:
DROP TABLE test.dwd_orders; CREATE TABLE test.dwd_orders( orderid INT, createtime STRING, modifiedtime STRING, status STRING, start_date STRING, end_date STRING ) row format delimited fields terminated by ',';
5.3.2 implementation of periodic event table
- Full initialization
-- data file order1.dat -- /root/data/lagoudw/data/order1.dat 001,2020-06-20,2020-06-20,establish 002,2020-06-20,2020-06-20,establish 003,2020-06-20,2020-06-20,payment load data local inpath '/root/data/lagoudw/data/order1.dat' into table test.ods_orders partition(dt='2020-06-20'); INSERT overwrite TABLE test.dwd_orders SELECT orderid, createtime, modifiedtime, status, createtime AS start_date, '9999-12-31' AS end_date FROM test.ods_orders WHERE dt='2020-06-20';
Incremental extraction
-- data file order2.dat 001,2020-06-20,2020-06-21,payment 004,2020-06-21,2020-06-21,establish 005,2020-06-21,2020-06-21,establish load data local inpath '/root/data/lagoudw/data/order2.dat' into table test.ods_orders partition(dt='2020-06-21');
Incremental refresh of historical data
-- The data in the zipper table is realized in two parts: new data(ods_orders),historical data (dwd_orders) -- Processing new data SELECT orderid, createtime, modifiedtime, status, modifiedtime AS start_date, '9999-12-31' AS end_date FROM test.ods_orders where dt='2020-06-21'; -- Process historical data. Historical data includes modified and unmodified data -- ods_orders And dwd_orders Make table connection -- On the connection, the data is modified -- Not connected, indicating that the data has not been modified select A.orderid, A.createtime, A.modifiedtime, A.status, A.start_date, case when B.orderid is not null and A.end_date>'2020-06-21' then '2020-06-20' else A.end_date end end_date from test.dwd_orders A left join (select * from test.ods_orders where dt='2020-06-21') B on A.orderid=B.orderid; -- Overwrite the zipper table with the above information insert overwrite table test.dwd_orders SELECT orderid, createtime, modifiedtime, status, modifiedtime AS start_date, '9999-12-31' AS end_date FROM test.ods_orders where dt='2020-06-21' union all select A.orderid, A.createtime, A.modifiedtime, A.status, A.start_date, case when B.orderid is not null and A.end_date>'2020-06-21' then '2020-06-20' else A.end_date end end_date from test.dwd_orders A left join (select * from test.ods_orders where dt='2020-06-21') B on A.orderid=B.orderid;
[the external chain image transfer fails. The source station may have an anti-theft chain mechanism. It is recommended to save the image and upload it directly (img-nic3jvy6-16314986453) (C: \ users \ 21349 \ appdata \ roaming \ typora \ user images \ image-20210909151346705. PNG)]
[the external chain image transfer fails. The source station may have an anti-theft chain mechanism. It is recommended to save the image and upload it directly (img-x9j47ur6-163149864554) (C: \ users \ 21349 \ desktop \ QRcode \ 2021-09-09_151458. PNG)]
[the external link image transfer fails. The source station may have an anti-theft chain mechanism. It is recommended to save the image and upload it directly (img-SuSm8n3e-1631498645356)(C:\Users349\Desktop\QrCode21-09-09_151834.png)]
5.4 summary of zipper table
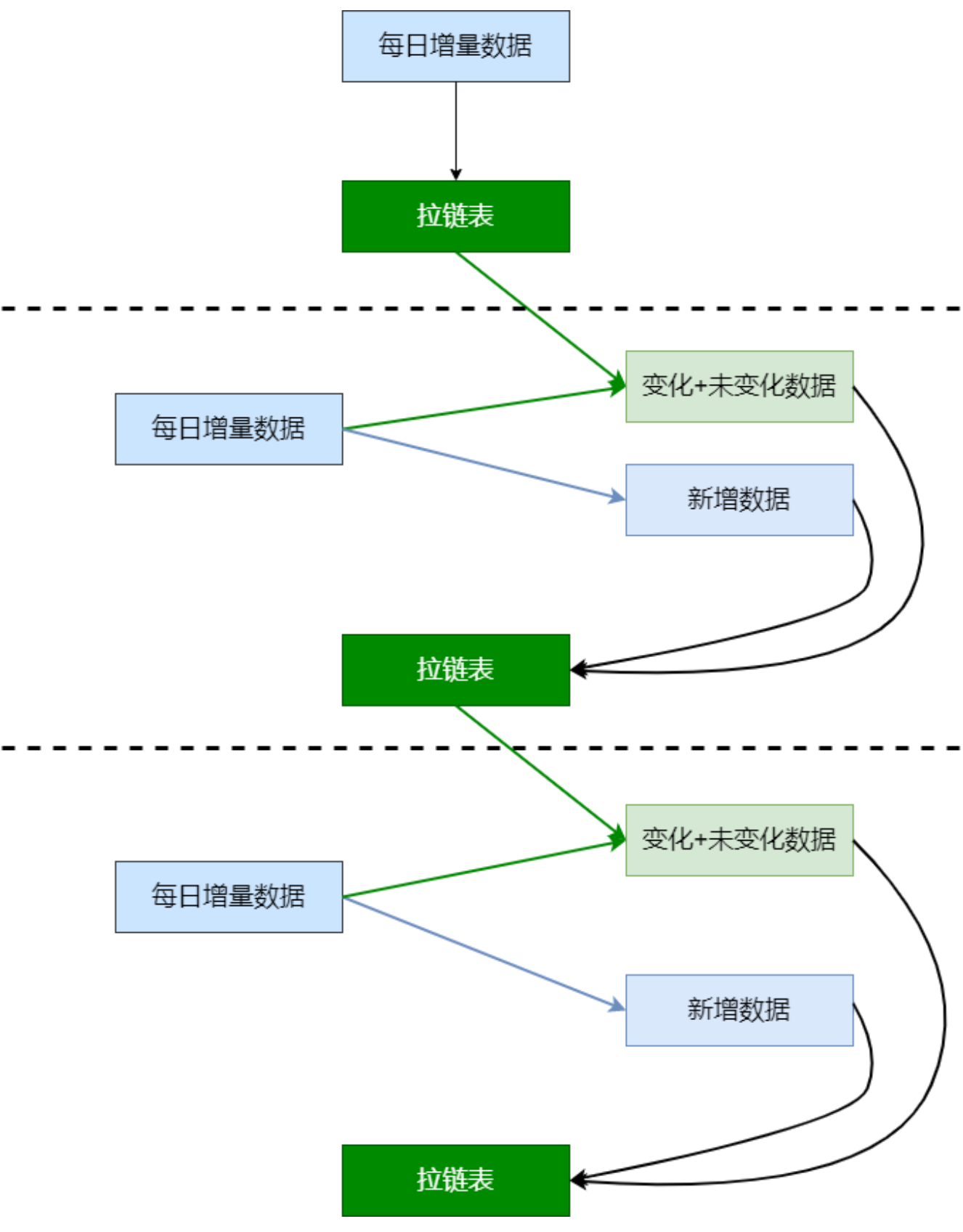
6, DIM layer building table loading data
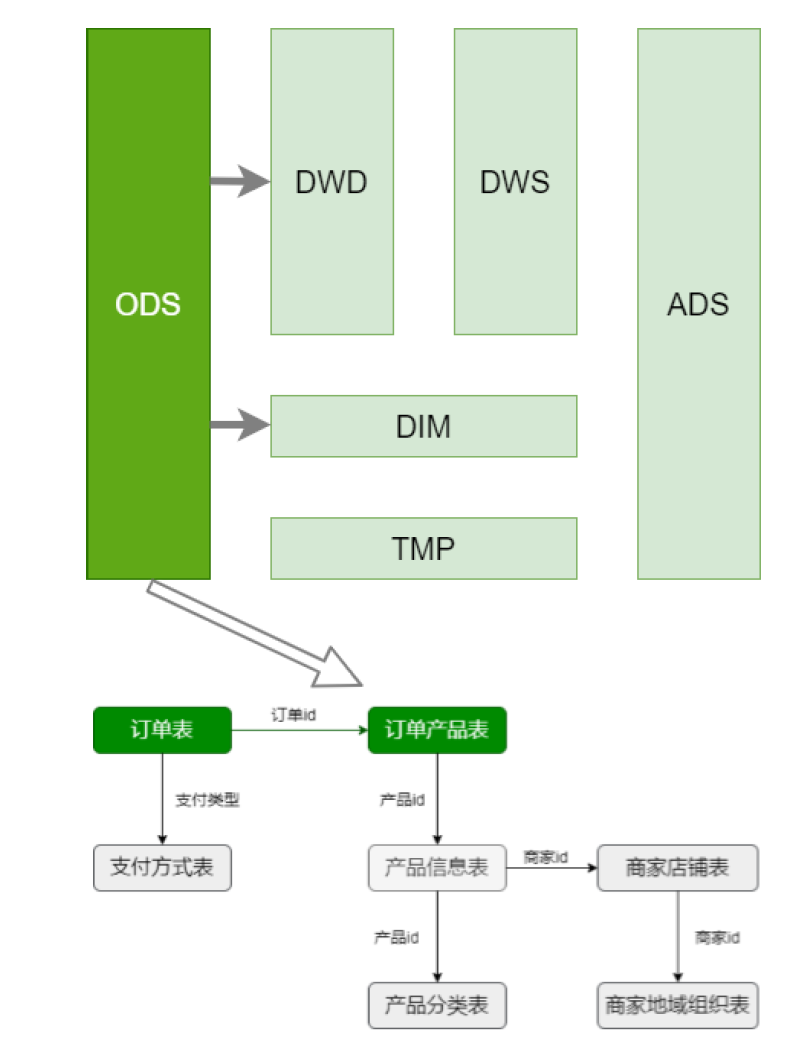
First, determine which are fact tables and which are dimension tables?
-
The green one is the fact table
-
Gray is the dimension table
How to handle dimension tables, daily snapshots and zipper tables?
-
Daily snapshot of small table: product classification table, merchant store table, merchant regional organization table and payment method table
-
Zipper table for large table: product information table
6.1 commodity classification table
The data in the database is standardized (meeting the three paradigms), but the standardized data brings inconvenience to the query.
Note: the dimension table of commodity classification is de normalized here, and irrelevant information is omitted to make it Wide Watch
DROP TABLE IF EXISTS dim.dim_trade_product_cat; create table if not exists dim.dim_trade_product_cat( firstId int, -- Primary commodity classification id firstName string, -- Class I commodity classification name secondId int, -- Secondary commodity classification Id secondName string, -- Secondary commodity classification name thirdId int, -- Class III commodity classification id thirdName string -- Class III commodity classification name ) partitioned by (dt string) STORED AS PARQUET;
realization
select T1.catid, T1.catname, T2.catid, T2.catname, T3.catid, T3.catname from (select catid, catname, parentid from ods.ods_trade_product_category where level=3 and dt='2020-07-01') T3 left join (select catid, catname, parentid from ods.ods_trade_product_category where level=2 and dt='2020-07-01') T2 on T3.parentid=T2.catid left join (select catid, catname, parentid from ods.ods_trade_product_category where level=1 and dt='2020-07-01') T1 on T2.parentid=T1.catid;
Data loading:
/root/data/lagoudw/script/trade/dim_load_product_cat.sh
#!/bin/bash source /etc/profile if [ -n "$1" ] then do_date=$1 else do_date=`date -d "-1 day" +%F` fi sql=" insert overwrite table dim.dim_trade_product_cat partition(dt='$do_date') select t1.catid, -- Primary classification id t1.catname, -- Primary classification name t2.catid, -- Secondary classification id t2.catname, -- Secondary classification name t3.catid, -- Three level classification id t3.catname -- Three level classification name from -- Commodity tertiary classification data (select catid, catname, parentid from ods.ods_trade_product_category where level=3 and dt='$do_date') t3 left join -- Commodity secondary classification data (select catid, catname, parentid from ods.ods_trade_product_category where level=2 and dt='$do_date') t2 on t3.parentid = t2.catid left join -- Commodity primary classification data (select catid, catname, parentid from ods.ods_trade_product_category where level=1 and dt='$do_date') t1 on t2.parentid = t1.catid; " hive -e "$sql"
6.2 commodity regional organization table
Merchant store table, merchant regional organization table = > one dimension table
This is also an inverse standardized design, which organizes the merchant store table and merchant regional organization table into a table and widens it. It is reflected in one line of data: business information, city information, region information, and id and name are included in the information.
drop table if exists dim.dim_trade_shops_org; create table dim.dim_trade_shops_org( shopid int, shopName string, cityId int, cityName string , regionId int , regionName string ) partitioned by (dt string) STORED AS PARQUET;
realization
select T1.shopid, T1.shopname, T2.id cityid, T2.orgname cityname, T3.id regionid, T3.orgname regionname from (select shopid, shopname, areaid from ods.ods_trade_shops where dt='2020-07-01') T1 left join (select id, parentid, orgname, orglevel from ods.ods_trade_shop_admin_org where orglevel=2 and dt='2020-07-01') T2 on T1.areaid=T2.id left join (select id, orgname, orglevel from ods.ods_trade_shop_admin_org where orglevel=1 and dt='2020-07-01') T3 on T2.parentid=T3.id limit 10;
/root/data/lagoudw/script/trade/dim_load_shop_org.sh
#!/bin/bash source /etc/profile if [ -n "$1" ] then do_date=$1 else do_date=`date -d "-1 day" +%F` fi sql=" insert overwrite table dim.dim_trade_shops_org partition(dt='$do_date') select t1.shopid, t1.shopname, t2.id as cityid, t2.orgname as cityName, t3.id as region_id, t3.orgname as region_name from (select shopId, shopName, areaId from ods.ods_trade_shops where dt='$do_date') t1 left join (select id, parentId, orgname, orglevel from ods.ods_trade_shop_admin_org where orglevel=2 and dt='$do_date') t2 on t1.areaid = t2.id left join (select id, parentId, orgname, orglevel from ods.ods_trade_shop_admin_org where orglevel=1 and dt='$do_date') t3 on t2.parentid = t3.id; " hive -e "$sql"
6.3 payment method table
The table information in ODS is cropped and only the necessary information is retained
drop table if exists dim.dim_trade_payment; create table if not exists dim.dim_trade_payment( paymentId string, -- Payment method id paymentName string -- Name of payment method ) partitioned by (dt string) STORED AS PARQUET;
/root/data/lagoudw/script/trade/dim_load_payment.sh
#!/bin/bash source /etc/profile if [ -n "$1" ] then do_date=$1 else do_date=`date -d "-1 day" +%F` fi sql=" insert overwrite table dim.dim_trade_payment partition(dt='$do_date') select id, payName from ods.ods_trade_payments where dt='$do_date'; " hive -e "$sql"
6.4 commodity information table
Use zipper table to process product information.
- Historical data = > initialize zipper table (start date: current day; end date: 9999-12-31) [execute only once]
- Daily processing of zipper table [processing each time data is loaded]
- New data: daily new data (ODS) = > start date; same day; End date: 9999-12-31
- Historical data: the zipper meter (DIM) is left connected with the daily new data (ODS)
- Connect data, data changes, end date: current day
- The data is not connected, the data does not change, and the end date remains unchanged
6.4.1 create dimension table
Two columns shall be added to the zipper table to record the effective date and expiration date respectively
drop table if exists dim.dim_trade_product_info; create table dim.dim_trade_product_info( `productId` bigint, `productName` string, `shopId` string, `price` decimal, `isSale` tinyint, `status` tinyint, `categoryId` string, `createTime` string, `modifyTime` string, `start_dt` string, `end_dt` string ) COMMENT 'Product list' STORED AS PARQUET;
6.4.2 initial data loading (historical data loading, only once)
insert overwrite table dim.dim_trade_product_info select productId, productName, shopId, price, isSale, status, categoryId, createTime, modifyTime, -- modifyTime Non empty fetching modifyTime,Otherwise take createTime;substr Take date case when modifyTime is not null then substr(modifyTime, 0, 10) else substr(createTime, 0, 10) end as start_dt, '9999-12-31' as end_dt from ods.ods_trade_product_info where dt = '2020-07-12';
6.4.2 incremental data import (execute repeatedly, and execute each time the data is loaded)
/root/data/lagoudw/script/trade/dim_load_product_info.sh
#!/bin/bash source /etc/profile if [ -n "$1" ] then do_date=$1 else do_date=`date -d "-1 day" +%F` fi sql=" insert overwrite table dim.dim_trade_product_info select productId, productName, shopId, price, isSale, status, categoryId, createTime, modifyTime, case when modifyTime is not null then substr(modifyTime,0,10) else substr(createTime,0,10) end as start_dt, '9999-12-31' as end_dt from ods.ods_trade_product_info where dt='$do_date' union all select dim.productId, dim.productName, dim.shopId, dim.price, dim.isSale, dim.status, dim.categoryId, dim.createTime, dim.modifyTime, dim.start_dt, case when dim.end_dt >= '9999-12-31' and ods.productId is not null then '$do_date' else dim.end_dt end as end_dt from dim.dim_trade_product_info dim left join (select * from ods.ods_trade_product_info where dt='$do_date' ) ods on dim.productId = ods.productId " hive -e "$sql"
7, DWD layering table loading data
There are two tables to process: order table and order product table. Of which:
-
The order table is a periodic fact table; In order to keep the order status, you can use the zipper table for processing;
-
The order product table is a common fact table, which is processed in a conventional way;
- If there are business requirements for data cleaning and data conversion, ODS = > DWD
- If there are no business requirements for data cleaning and data conversion, it will remain in ODS without any change. This is the processing method of this project.
Order status
- -3: User rejection
- -2: Unpaid orders
- -1: User cancel
- 0: to be shipped
- 1: In distribution
- 2: User confirms receipt
There is a time limit from order creation to final completion; In business, it is not allowed that the status of an order is still changing after one month;
7.1 DWD floor construction table
Remarks:
- Unlike the dimension table, the order fact table has a large number of records
- The order has a life cycle; The order status cannot be changed forever (the life cycle of the order is generally about 15 days)
- The order is a zipper table and a partition table
- Partition purpose: once the order is terminated, it will not be calculated repeatedly
- Partition conditions: creation date of the order; Ensure that the same order is in the same partition
-- Order fact table(Zipper Watch) DROP TABLE IF EXISTS dwd.dwd_trade_orders; create table dwd.dwd_trade_orders( `orderId` int, `orderNo` string, `userId` bigint, `status` tinyint, `productMoney` decimal, `totalMoney` decimal, `payMethod` tinyint, `isPay` tinyint, `areaId` int, `tradeSrc` tinyint, `tradeType` int, `isRefund` tinyint, `dataFlag` tinyint, `createTime` string, `payTime` string, `modifiedTime` string, `start_date` string, `end_date` string ) COMMENT 'Order fact sheet' partitioned by (dt string) STORED AS PARQUET;
7.2 DWD layer data loading
-- Note: time date format conversion -- 'yyyy-MM-dd HH:mm:ss' => timestamp => 'yyyy-MM-dd' select unix_timestamp(modifiedtime, 'yyyy-MM-dd HH:mm:ss') from ods.ods_trade_orders limit 10; select from_unixtime(unix_timestamp(modifiedtime, 'yyyy-MM-ddHH:mm:ss'), 'yyyy-MM-dd') from ods.ods_trade_orders limit 10;
/root/data/lagoudw/script/trade/dwd_load_trade_orders.sh
#!/bin/bash
source /etc/profile
if [ -n "$1" ]
then
do_date=$1
else
do_date=`date -d "-1 day" +%F`
fi
sql="
set hive.exec.dynamic.partition.mode=nonstrict;
set hive.exec.dynamic.partition=true;
INSERT OVERWRITE TABLE dwd.dwd_trade_orders
partition(dt)
SELECT orderId,orderNo,userId,status,productMoney,totalMoney,payMethod,isPay,areaId,tradeSrc,tradeType,isRefund,
dataFlag,createTime,payTime,modifiedTime, case when modifiedTime is not null
then from_unixtime(unix_timestamp(modifiedTime,'yyyy-MM-dd HH:mm:ss'),'yyyy-MM-dd')
else from_unixtime(unix_timestamp(createTime,'yyyy-MM-dd HH:mm:ss'), 'yyyy-MM-dd')
end as start_date,'9999-12-31' as end_date,
from_unixtime(unix_timestamp(createTime, 'yyyy-MM-dd HH:mm:ss'), 'yyyy-MM-dd') as dt
FROM ods.ods_trade_orders WHERE dt='$do_date' union all
SELECT A.orderId,A.orderNo,A.userId,A.status,A.productMoney,A.totalMoney,A.payMethod,A.isPay,A.areaId,A.tradeSrc,
A.tradeType,A.isRefund,A.dataFlag,A.createTime,A.payTime,A.modifiedTime,A.start_date,
CASE WHEN B.orderid IS NOT NULL AND A.end_date >'$do_date' THEN date_add('$do_date', -1)
ELSE A.end_date END AS end_date,
from_unixtime(unix_timestamp(A.createTime, 'yyyy-MM-dd HH:mm:ss'), 'yyyy-MM-dd') as dt
FROM (SELECT * FROM dwd.dwd_trade_orders WHERE dt>date_add('$do_date', -15)) A
left outer join (SELECT * FROM ods.ods_trade_orders WHERE dt='$do_date') B ON A.orderId = B.orderId;
"
hive -e "$sql"
8, DWS layering table loading data
DIM, DWD = > Data Warehouse layering, data warehouse theory
Demand: calculation day
-
All order information nationwide
-
Order information of national and first-class commodity classification
-
Order information of national and secondary commodity classification
-
All order information in the region
-
Regional and primary commodity classification order information
-
Regional and secondary commodity classification order information
-
City all order information
-
Order information of city and primary commodity classification
-
City and secondary commodity classification order information
Required information: order table, order commodity table, commodity information table dimension table, commodity classification dimension table, merchant region dimension table
Order table = > order id, order status
Order commodity table = > order id, commodity id, merchant id, unit price, quantity
Commodity information dimension table = > commodity id, three-level classification id
Commodity classification dimension table = > Level 1 name, level 1 Classification id, level 2 name, level 2 classification id, level 3 name, level 3 Classification id
Merchant region dimension table = > merchant id, region name, region id, city name, City idOrder table, order commodity table, commodity information dimension table = > order id, commodity id, merchant id, three-level classification id, unit price, quantity (order details)
Order details, commodity classification dimension table, merchant region dimension table = > order id, commodity id, merchant id, three-level classification name, unit price, quantity, region, city = > order details
8.1 DWS floor construction table
- dws_trade_orders is slightly aggregated from the following table:
- dwd.dwd_trade_orders (zipper table, partition table)
- ods.ods_trade_order_product (partition table)
- dim.dim_trade_product_info (dimension table, zipper table)
- dws_trade_orders_w (order details) consists of the following tables:
- ads.dws_trade_orders (partition table)
- dim.dim_trade_product_cat (partition table)
- dim.dim_trade_shops_org (partition table)
-- Order Details (Light summary fact sheet). Details of each order DROP TABLE IF EXISTS dws.dws_trade_orders; create table if not exists dws.dws_trade_orders( orderid string, -- order id cat_3rd_id string, -- Three level classification of commodities id shopid string, -- shop id paymethod tinyint, -- Payment method productsnum bigint, -- Quantity of goods paymoney double, -- Order item detail amount paytime string -- Order time ) partitioned by (dt string) STORED AS PARQUET; -- Order detail table DROP TABLE IF EXISTS dws.dws_trade_orders_w; create table if not exists dws.dws_trade_orders_w( orderid string, -- order id cat_3rd_id string, -- Three level classification of commodities id thirdname string, -- Commodity class III classification name secondname string, -- Commodity secondary classification name firstname string, -- Commodity primary classification name shopid string, -- shop id shopname string, -- Shop name regionname string, -- Store area cityname string, -- Store City paymethod tinyint, -- Payment method productsnum bigint, -- Quantity of goods paymoney double, -- Order detail amount paytime string -- Order time ) partitioned by (dt string) STORED AS PARQUET;
8.2 DWS layer loading data
/root/data/lagoudw/script/trade/dws_load_trade_orders.sh
Remarks: DWS_ trade_ orders/dws_ trade_ orders_ Multiple records may appear in an order in W
#!/bin/bash source /etc/profile if [ -n "$1" ] then do_date=$1 else do_date=`date -d "-1 day" +%F` fi sql=" insert overwrite table dws.dws_trade_orders partition(dt='$do_date') select t1.orderid as orderid,t3.categoryid as cat_3rd_id,t3.shopid as shopid,t1.paymethod as paymethod, t2.productnum as productsnum,t2.productnum*t2.productprice as pay_money,t1.paytime as paytime from (select orderid, paymethod, paytime from dwd.dwd_trade_orders where dt='$do_date') T1 left join (select orderid, productid, productnum, productprice from ods.ods_trade_order_product where dt='$do_date') T2 on t1.orderid = t2.orderid left join (select productid, shopid, categoryid from dim.dim_trade_product_info where start_dt <= '$do_date' and end_dt >= '$do_date' ) T3 on t2.productid=t3.productid; insert overwrite table dws.dws_trade_orders_w partition(dt='$do_date') select t1.orderid,t1.cat_3rd_id,t2.thirdname,t2.secondname,t2.firstname,t1.shopid,t3.shopname,t3.regionname,t3.cityname, t1.paymethod,t1.productsnum,t1.paymoney,t1.paytime from (select orderid,cat_3rd_id,shopid,paymethod,productsnum, paymoney,paytime from dws.dws_trade_orders where dt='$do_date') T1 join (select thirdid, thirdname, secondid, secondname,firstid, firstname from dim.dim_trade_product_cat where dt='$do_date') T2 on T1.cat_3rd_id = T2.thirdid join (select shopid, shopname, regionname, cityname from dim.dim_trade_shops_org where dt='$do_date') T3 on T1.shopid = T3.shopid " hive -e "$sql"
Note: prepare the test data by yourself and ensure that the test date has data
-
dwd.dwd_trade_orders (zipper table, partition table)
-
ods.ods_trade_order_product (partition table)
-
dim.dim_trade_product_info (dimension table, zipper table)
-
dim.dim_trade_product_cat (partition table)
-
dim.dim_trade_shops_org (partition table)
Construction test data (zipper partition table)
insert overwrite table dwd.dwd_trade_orders -- The date can be set at will partition(dt='2020-07-12') select orderid,orderno,userid,status,productmoney,totalmoney,paymethod,ispay,areaid,tradesrc,tradetype,isrefund,dataflag, '2020-07-12',paytime,modifiedtime,start_date,end_date from dwd.dwd_trade_orders where end_date='9999-12-31';
9, ADS layer development
Demand: calculation day
-
All orders nationwide
-
National and first-class commodity classification order message
-
National and secondary commodity classification order message
-
Region all order messages
-
Regional and primary commodity classification order messages
-
Regional and secondary commodity classification order messages
-
City all order messages
-
City, first level commodity classification order message
-
City, secondary commodity classification order message
Table used: dws.dws_trade_orders_w
9.1 ADS floor construction table
-- ADS Layer order analysis table DROP TABLE IF EXISTS ads.ads_trade_order_analysis; create table if not exists ads.ads_trade_order_analysis( areatype string, -- Regional scope: regional type (national, regional and urban) regionname string, -- Area name cityname string, -- City name categorytype string, -- Commodity classification type (primary and secondary) category1 string, -- Commodity primary classification name category2 string, -- Commodity secondary classification name totalcount bigint, -- Order quantity total_productnum bigint, -- Quantity of goods totalmoney double -- Payment amount ) partitioned by (dt string) row format delimited fields terminated by ',';
9.2 ADS layer loading data
/root/data/lagoudw/script/trade/ads_load_trade_order_analysis.sh
Note: there are multiple goods in an order; Multiple commodities have different classifications; This will lead to multiple classifications of an order, which are counted separately;
#!/bin/bash source /etc/profile if [ -n "$1" ] then do_date=$1 else do_date=`date -d "-1 day" +%F` fi sql=" with mid_orders as ( select regionname, cityname, firstname category1, secondname category2, count(distinct orderid) as totalcount, sum(productsnum) as total_productnum, sum(paymoney) as totalmoney from dws.dws_trade_orders_w where dt='$do_date' group by regionname, cityname, firstname, secondname ) insert overwrite table ads.ads_trade_order_analysis partition(dt='$do_date') select 'whole country' as areatype, '' as regionname, '' as cityname, '' as categorytype, '' as category1, '' as category2, sum(totalcount), sum(total_productnum), sum(totalmoney) from mid_orders union all select 'whole country' as areatype, '' as regionname, '' as cityname, 'class a' as categorytype, category1, '' as category2, sum(totalcount), sum(total_productnum), sum(totalmoney) from mid_orders group by category1 union all select 'whole country' as areatype, '' as regionname, '' as cityname, 'second level' as categorytype, '' as category1, category2, sum(totalcount), sum(total_productnum), sum(totalmoney) from mid_orders group by category2 union all select 'Large area' as areatype, regionname, '' as cityname, '' as categorytype, '' as category1, '' as category2, sum(totalcount), sum(total_productnum), sum(totalmoney) from mid_orders group by regionname union all select 'Large area' as areatype, regionname, '' as cityname, 'class a' as categorytype, category1, '' as category2, sum(totalcount), sum(total_productnum), sum(totalmoney) from mid_orders group by regionname, category1 union all select 'Large area' as areatype, regionname, '' as cityname, 'second level' as categorytype, '' as category1, category2, sum(totalcount), sum(total_productnum), sum(totalmoney) from mid_orders group by regionname, category2 union all select 'city' as areatype, '' as regionname, cityname, '' as categorytype, '' as category1, '' as category2, sum(totalcount), sum(total_productnum), sum(totalmoney) from mid_orders group by cityname union all select 'city' as areatype, '' as regionname, cityname, 'class a' as categorytype, category1, '' as category2, sum(totalcount), sum(total_productnum), sum(totalmoney) from mid_orders group by cityname, category1 union all select 'city' as areatype, '' as regionname, cityname, 'second level' as categorytype, '' as category1, category2, sum(totalcount), sum(total_productnum), sum(totalmoney) from mid_orders group by cityname, category2; " hive -e "$sql"
Note: because in dws.dws_trade_orders_w, an order may have multiple records, so count (distinct order ID) should be used when counting the order quantity
10, Data export
ads.ads_trade_order_analysis partition table, export to MySQL using DataX.
11, Summary
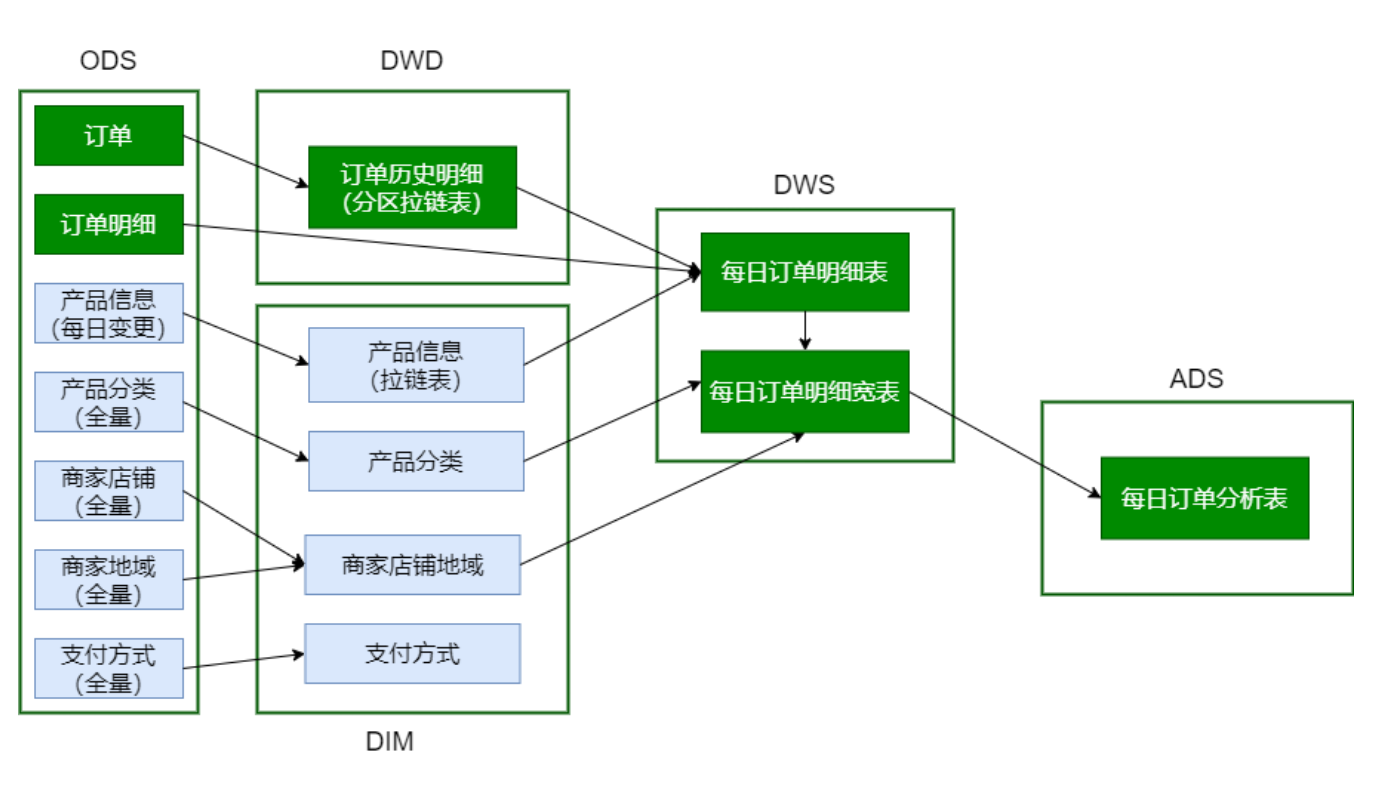
Script call order:
# Loading ODS data (including DataX migration data) /data/lagoudw/script/trade/ods_load_trade.sh # Loading DIM layer data /data/lagoudw/script/trade/dim_load_product_cat.sh /data/lagoudw/script/trade/dim_load_shop_org.sh /data/lagoudw/script/trade/dim_load_payment.sh /data/lagoudw/script/trade/dim_load_product_info.sh # Load DWD layer data /data/lagoudw/script/trade/dwd_load_trade_orders.sh # Load DWS layer data /data/lagoudw/script/trade/dws_load_trade_orders.sh # Load ADS layer data /data/lagoudw/script/trade/ads_load_trade_order_analysis.sh
Main technical points:
- Zipper Watch ]: create, use and rollback; Commodity information table and order table (periodic fact table; partition table + zipper table)
- Wide table (inverse normalization): commodity classification table, commodity regional organization table, order details and order details (light summary fact table)
um(totalmoney)
from mid_orders
group by category2
union all
select 'region' as areatype,
regionname,
'' as cityname,
'' as categorytype,
'' as category1,
'' as category2,
sum(totalcount),
sum(total_productnum),
sum(totalmoney)
from mid_orders
group by regionname
union all
select 'region' as areatype,
regionname,
'' as cityname,
As category type,
category1,
'' as category2,
sum(totalcount),
sum(total_productnum),
sum(totalmoney)
from mid_orders
group by regionname, category1
union all
select 'region' as areatype,
regionname,
'' as cityname,
As category type,
'' as category1,
category2,
sum(totalcount),
sum(total_productnum),
sum(totalmoney)
from mid_orders
group by regionname, category2
union all
select 'city' as areatype,
'' as regionname,
cityname,
'' as categorytype,
'' as category1,
'' as category2,
sum(totalcount),
sum(total_productnum),
sum(totalmoney)
from mid_orders
group by cityname
union all
select 'city' as areatype,
'' as regionname,
cityname,
As category type,
category1,
'' as category2,
sum(totalcount),
sum(total_productnum),
sum(totalmoney)
from mid_orders
group by cityname, category1
union all
select 'city' as areatype,
'' as regionname,
cityname,
As category type,
'' as category1,
category2,
sum(totalcount),
sum(total_productnum),
sum(totalmoney)
from mid_orders
group by cityname, category2;
"
hive -e "$sql"
Note: due to `dws.dws_trade_orders_w` In, an order may have multiple records, so it should be used when counting the order quantity `count(distinct orderid)` ### 10, Data export `ads.ads_trade_order_analysis` Partition tables, using DataX Export to MySQL. ### 11, Summary  Script call order: ```sh # Loading ODS data (including DataX migration data) /data/lagoudw/script/trade/ods_load_trade.sh # Loading DIM layer data /data/lagoudw/script/trade/dim_load_product_cat.sh /data/lagoudw/script/trade/dim_load_shop_org.sh /data/lagoudw/script/trade/dim_load_payment.sh /data/lagoudw/script/trade/dim_load_product_info.sh # Load DWD layer data /data/lagoudw/script/trade/dwd_load_trade_orders.sh # Load DWS layer data /data/lagoudw/script/trade/dws_load_trade_orders.sh # Load ADS layer data /data/lagoudw/script/trade/ads_load_trade_order_analysis.sh
Main technical points:
- Zipper Watch ]: create, use and rollback; Commodity information table and order table (periodic fact table; partition table + zipper table)
- Wide table (inverse normalization): commodity classification table, commodity regional organization table, order details and order details (light summary fact table)