Select reference
Because I am learning to write at the same time, rather than starting to write in a very organized way after I have learned it completely, so reference materials are very important (originally personal development experience is very important, but I am zero Foundation)
- Official Python documentation
- Relevant information of Zhihu (1) This is a very good, easy to understand overview of the whole Python learning framework
- Relevant information of Zhihu (2)
At the time of writing here, I've read the first answer of the second and third links above. I won't write some of the parts they mentioned (for example, the route of crawling can't have a loop).
A simple pseudo code
The following simple pseudo code uses two classic data structures, set and queue. The function of set is to record the visited pages, and the function of queue is to search breadth first
The internal principle of the Set used here is to use Hash table. The traditional Hash takes up too much space for the crawler, so there is a kind of Set called Bloom Filter I'm going to see how to use this data structure later. Now I'll skip it, because for zero based me, this is not the point
Code implementation (1): using Python to grab the specified page
The editor I use is Idle. After installing Python 3, the editor is also installed. It is small and light. Press F5 to run and display the result. The code is as follows:
#encoding:UTF-8
import urllib.request
url = "http://www.baidu.com"
data = urllib.request.urlopen(url).read()
data = data.decode('UTF-8')
print (data)urllib.request It's a library under urllib Click here to open official documents How to use the official documents? First of all, click the page just mentioned in the link to have several sub libraries of urllib. We temporarily use request, so let's take a look first urllib.request The first thing I see is a sentence about what this library is for:
The urllib.request module defines functions and classes which help in opening URLs (mostly HTTP) in a complex world — basic and digest authentication, redirections, cookies and more. """ urllib.request Modules are defined to help open in a complex environment URL(Mainly HTTP)Functions and classes of-Basic and digest authentication, redirection, Cookie Wait. """
Then read the urlopen() function used in our code
urllib.request.urlopen(url,data=None,[timeout,]*,cafile=None,capath=None,cadefault=False)
The key part is the return value. This function returns a http.client.HTTPResponse Object. There are various methods for this object, such as the read() method we use. These methods can be used according to the links in the official documents. According to the official documents, I use the console to run the above program. After this program, I continue to run the following code to be more familiar with these methods What do you do?
a = urllib.request.urlopen(full_url) type(a) a.geturl() a.info() a.getcode()
Code implementation (2): simple handling of URL s in Python
If you want to capture the webpage with the keyword Jecvay Notes on Baidu, the code is as follows:
import urllib
import urllib.request
data = {}
data ['word'] = 'Jecvay Notes'
url_values = urllib.parse.urlencode(data)
url = "http://www.baidu.com/s?"
full_url = url + url_values
data = urllib.request.urlopen(full_url).read()
data = data.decode('UTF-8')
print(data)Data is a dictionary, and then through urllib.parse.urlencode() to convert data to a string of 'word=Jecvay+Notes', and finally merge it with url to full_url, the rest is the same as the simplest example above. About urlencode(), learn what he does through official documents. Check
- urllib.parse.urlencode(query, doseq=False, safe=", encoding=None, errors=None)
- urllib.parse.quote_plus(string, safe=", encoding=None, errors=None)
I know that it is to convert a popular string into a url format string.
- Write the main framework of the crawler with pseudo code;
- In Python urllib.request The library grabs the page of the specified url;
- In Python urllib.parse The library converts a normal string to a url - compliant string
This time, I started to use Python to implement all parts of the pseudo code. Because the title of this article is "zero basis", I will introduce the two data structure queues and sets I used first. For the "regular expression" part, I can't introduce it for the limited space, but I will give some reference materials that I prefer
Python queues
In the crawler, the BFS algorithm is used. The data structure of this algorithm is queue
Python's List function is enough to complete the queue function. You can use append() to add elements to the end of the queue. You can use an array like way to get the first element of the queue. You can use pop(0) to pop up the first element of the queue. But List is inefficient to complete the queue function, because it is inefficient to use pop(0) and insert() at the front of the queue, Python officially recommended collection.deque To efficiently complete queue tasks
from collections import deque
queue = deque(["Eric","John","Michael"])
queue.append("Terry") #Terry joins the team
queue.append("Graham") #Graham joins the team
print (queue.popleft()) #Team leader out
#Output: 'Eric'
print (queue.popleft()) #Team leader out
#Output: 'John'
queue #The remaining elements in the queue
#Output: deque(['Michael','Terry','Graham '])Collection of Python
In the crawler, in order not to repeatedly crawl those websites that have already crawled, we need to put the url of the crawled page into the collection. Before climbing a certain url every time, we need to see whether the collection already exists. If it already exists, we will skip the url; if it doesn't exist, we will put the url into the collection first, and then climb the page
Python provides the data structure of set. Set is an unordered structure that does not contain repeating elements. It is generally used to test whether an element has been included or to de duplicate many elements. Like the set theory in mathematics, it supports operations of intersection, union, difference and symmetry difference
You can use set() function or curly bracket {} to create a set. But you can't use a curly bracket to create an empty set, you can only use set() function. Because an empty curly bracket creates a dictionary data structure. The following is also an example provided by Python official website
basket = {'apple','orange','apple','pear','orange','banana'}
print (basket) #Here is a demonstration of the de duplication function
print ('orange' in basket) #Quickly determine whether an element is in a collection
print ('crabgrass' in basket)
# The following shows the operation between two sets
a = set('abracadabra') #set is an unordered structure without repeating elements
b = set('alacazam')
print (a)
print (a - b)# Set a contains elements
print (a | b)# All elements contained in set a or b
print (a & b)# Elements contained in sets a and b
print (a ^ b )# Elements different from a and bIn fact, we only use the function of quickly judging whether the element is in the set and the combination operation of the set
Python's regular expression
In the crawler, the crawled data is a string, and the content of the string is the html code of the page. We need to extract all the URLs mentioned by the page from the string. This requires the crawler to have a simple string processing ability, and regular expression can easily complete this task
reference material
- 30 minute introduction to regular expressions
- The Python regular expression part of w3cschool
- Python regular expression Guide
Although the function of regular expression is very powerful, many rules used in practice are also very clever. It takes a long practice to be really proficient in regular expression. However, we only need to master how to use regular expression in a string and find out all URLs. If we really want to skip this part, You can find many ready-made expressions that match the url on the Internet
Python web crawler Ver 1.0 alpha
With the above foreshadowing, I can finally start to write real crawlers. The entry address I chose is uncle Fenng's Startup News , I think uncle Fenng just got $70 million in financing, and I don't mind if your reptiles come to his little station. Although this reptile can barely run, it can only climb some static pages due to the lack of exception handling, and can't distinguish what is static and what is dynamic, and should skip when encountering any situation, so it will be defeated in a short time
import re
import urllib.request
import urllib
from collections import deque
queue= deque()
visited = set()
url = 'https://health.pclady.com.cn / '(the entry page can be changed to another
queue.append(url)
cnt = 0
while queue:
url = queue.popleft()# Team leader out
visited |= {url} #Mark as accessed
print ('Captured: ' + str(cnt) + ' Grabbing <- - - ' + url)
cnt += 1
urlop = urllib.request.urlopen(url)
if 'html' not in urlop.getheader('Content-Type'):
continue
# Avoid program abort, use try...catch to handle exceptions
try:
data = urlop.read().decode('utf-8')
except:
continue
# Regular expression extracts all the queues in the page, judges whether it has been visited, and then joins the queue to be crawled.
linkre = re.compile('href ="(.+?)"')
for x in linkre.findall(data):
if 'http' in x and x not in visited:
queue.append(x)
print ('Join queue - - ->' + x )
Execute the above program and return the following results:
Crawled: 0 is grabbing < --- https://health.pclady.com.cn/
The regular expressions used by this version of crawler are:
'href="(.+?)"'
So we will climb down the links of. ico or. jpg. In this way, if read() encounters decode('utf-8 '), an exception will be thrown. So we use getheader() Function to get the type of file to be crawled is html to continue to analyze the link
if 'html' not in urlop.getheader('Conten-Type'):
continueHowever, even if this is the case, there are still some websites that run decode() abnormally. Therefore, we surround the decode() function with a try..catch statement, so that it will not cause the program to stop. The program running effect is as follows:
import re
import urllib.request
import urllib
from collections import deque
queue= deque()
visited = set()
url = 'https://health.pclady.com.cn / '(the entry page can be changed to another
queue.append(url)
cnt = 0
while queue:
url = queue.popleft()# Team leader out
if url in visited:
continue
visited |= {url} #Mark as accessed
print ('Captured: ' + str(cnt) + ' Grabbing <- - - ' + url)
cnt += 1
urlop = urllib.request.urlopen(url)
if 'html' not in urlop.getheader('Content-Type'):
continue
# Avoid program abort, use try...catch to handle exceptions
try:
data = urlop.read().decode('utf-8')
except:
continue
# Regular expression extracts all the queues in the page, judges whether it has been visited, and then joins the queue to be crawled.
linkre = re.compile('href =\"(.+?)\"')
for x in linkre.findall(data):
if 'http' in x and x not in visited:
queue.append(x)
print ('Join queue - - ->' + x )
Add timeout skip feature:
First, I will simply:
urlop = urllib.request.urlopen(url)
Change to:
urlop = urllib.request.urlopen(url,timeout = 2)
After running, it is found that when the timeout occurs, the program is interrupted because of exception, so we put this sentence in try... Exception structure, and the problem is solved.
Auto jump is supported:
Climbing http://baidu.com When we climb back to something that has no content, it tells us that we should jump to http://www.baidu.com . But our crawler doesn't support auto jump. Now let's add this function to let the crawler climb baidu.com When it's time to grab www.baidu.com Content of
First of all, we need to know how to climb http://baidu.com We can use Fiddler or write a little crawler to grab the page he returned. Here's what I caught. You should also try to write a few lines of python to grab it
<html> <meta http-equiv = "refresh" content = " 0 ;url= http://www.baidu.com/" > </html>
Looking at the code, we know that this is a code that uses html meta to refresh and orient. The o is to wait for o seconds and jump, that is to say, jump immediately. Then, as we said last time, we can use a regular expression to extract the url and climb to the right place. The last crawler they wrote can have this function. Here, we only need to take it alone Come out and explain the meta jump of http.
Camouflage browser regular army:
The previous few small contents are relatively few. Now, I will study in detail how to let websites visit our Python crawler as a regular browser. Because if we don't camouflage ourselves, some websites won't be able to climb back. If we have seen the theoretical knowledge, we know that we need to add user agent to the header when we GET
If you haven't seen the theoretical knowledge, search and learn according to the following keywords: D
- There are two kinds of HTTP messages: request message and response message
- Request line and first line of request message
- GET, POST, HEAD, PUT, DELETE methods
When I visit Baidu homepage with IE browser, the request message sent by the browser is as follows:
GET http://www.baidu.com/ HTTP/1.1 Accept: text/html, application/xhtml+xml, */* Accept-Language: en-US,en;q=0.8,zh-Hans-CN;q=0.5,zh-Hans;q=0.3 User-Agent: Mozilla/5.0 (Windows NT 6.3; WOW64; Trident/7.0; rv:11.0) like Gecko Accept-Encoding: gzip, deflate Host: www.baidu.com DNT: 1 Connection: Keep-Alive Cookie: BAIDUID=57F4D171573A6B88A68789EF5DDFE87:FG=1; uc_login_unique=ccba6e8d978872d57c7654130e714abd; BD_UPN=11263145; BD
After Baidu receives this message, the response message returned to me is as follows (Abridged):
HTTP/1.1 200 OK Date: Mon, 29 Sep 2014 13:07:01 GMT Content-Type: text/html; charset=utf-8 Connection: Keep-Alive Vary: Accept-Encoding Cache-Control: private Cxy_all: baidu+8b13ba5a7289a37fb380e0324ad688e7 Expires: Mon, 29 Sep 2014 13:06:21 GMT X-Powered-By: HPHP Server: BWS/1.1 BDPAGETYPE: 1 BDQID: 0x8d15bb610001fe79 BDUSERID: 0 Set-Cookie: BDSVRTM=0; path=/ Set-Cookie: BD_HOME=0; path=/ Content-Length: 80137 <!DOCTYPE html><!–STATUS OK–><html><head><meta http-equiv="content-type" content="text/html;charset=utf-8″><meta http-equiv="X-UA-Compatible" content="IE=Edge"><link rel="dns-prefetch" href="//s1.bdstatic.com ”/><link rel=”dns-prefetch” href=”//t1.baidu.com ”/><link rel=”dns-prefetch” href=”//t2.baidu.com ”/><link rel=”dns-prefetch” href=”//t3.baidu.com ”/><link rel=”dns-prefetch” href=”//t10.baidu.com ”/><link rel=”dns-prefetch” href=”//t11.baidu.com ”/><link rel=”dns-prefetch” href=”//t12.baidu.com ”/><link rel=”dns-prefetch” href=”//b1.bdstatic.com ”/>< title > Baidu once, you will know < / Title > < style index = "index" > 20 thousand words are omitted here . </script></body></html>
If you can understand the first sentence of this sentence, it's OK. You can cooperate with Fiddler to study it slowly later. So what we need to do is to write user agent in the request by the way when Python crawler sends a request to Baidu, indicating that you are the browser king
There are many ways to add a header when getting. Here are two ways
The first method is simple and direct, but it is not easy to extend functions. The code is as follows:
import urllib.request
url ='http://www.baidu.com/'
req = urllib.request.Request(url,headers={
'Connection':'keep-alive',
'Accept':'text/html,application/xhtml+xml,*/*;text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Language':'zh-CN,zh;q=0.9',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36'
})
oper = urllib.request.urlopen(req)
data = oper.read()
print (data.decode())The second method is build_opener is a method used to define opener. The advantage of this method is that it can easily expand functions. For example, the following code expands the automatic processing of Cookies.
import urllib.request
import http.cookiejar
"""
http.cookiejar.CookieJar()
"""
#head:dict of header
def makeMyOpenner(head = {
'Connection': 'keep-alive',
'Accept': 'text/html,application/xhtml+xml,*/*;text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Language': 'zh-CN,zh;q=0.9',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36'
}):
cj = http.cookiejar.CookieJar()#Use cookie jar to get cookie value
opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cj))
header = []
for key,value in head.items():
elem =(key,value)
header.append(elem)
opener.addheaders = header
return opener
oper = makeMyOpenner()
uop = oper.open('http://www.baidu.com/',timeout = 1000)
data = uop.read()
print (data.decode())The GET message caught by Fiddler after running the above code is as follows:
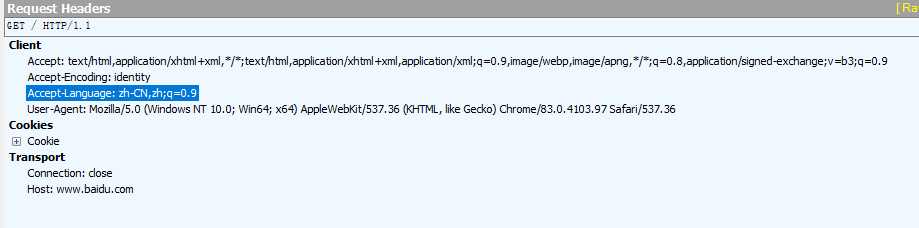
We can see that what we write in the code is added to the request message
Save the retrieved message:
By the way, file operation. Python's file operation is quite convenient. We can talk about how to save the captured data in binary form or in text form after being processed into a string by decode(). You can save the file in different poses by changing the way you open the file. Here is the reference code:
import urllib.request
import http.cookiejar
"""
http.cookiejar.CookieJar()
"""
def saveFile(data):
save_path = 'F:\\pythonDEV\\Reptile Technology\\Python Develop web crawler\\temp.out\\data.txt'
f_obj = open(save_path, 'wb') # wb means open mode
f_obj.write(data)
f_obj.close()
#head:dict of header
def makeMyOpenner(head = {
'Connection': 'keep-alive',
'Accept': 'text/html,application/xhtml+xml,*/*;text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Language': 'zh-CN,zh;q=0.9',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36'
}):
cj = http.cookiejar.CookieJar()#Use cookie jar to get cookie value
opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cj))
header = []
for key,value in head.items():
elem =(key,value)
header.append(elem)
opener.addheaders = header
return opener
oper = makeMyOpenner()
uop = oper.open('http://www.baidu.com/',timeout = 1000)
data = uop.read()
print (data.decode())
saveFile(data)