awk of the Three Swordsmen of Linux (Foundation and Advancement)
Label (Space Separation): Linux Practical Teaching Notes - Chen Siqi
Quick jump directory:
Chapter 1 Introduction to awk Foundation
To understand awk programs, you must be familiar with the rules of this tool. The purpose of this battle notes is to take students to master the use of awk in enterprises through practical cases or interview questions, rather than the help manual of awk program.
1.1 awk
- A language with strange names
- Mode Scanning and Processing
Awk is not only a command in linux system, but also a programming language, which can be used to process data and generate reports (excel). The data processed can be one or more files, can be from standard input, can also be obtained through the pipeline standard input, awk can edit commands directly on the command line for operation, can also be written into awk program for more complex use. This chapter mainly explains the use of awk command.
1.2 After awk, you can master:
- Records and fields
- Pattern Matching: Patterns and Actions
- Basic awk execution process
- Common built-in variables for awk (predefined variables)
- awk arrays (commonly used for work)
- awk grammar: loop, condition
- awk common function
- Transfer parameters to awk
- awk refers to shell variables
- awk program and debugging ideas
1.3 awk environment brief introduction
[root@chensiqi1 ~]# cat /etc/redhat-release CentOS release 6.8 (Final) [root@chensiqi1 ~]# uname -r 2.6.32-642.el6.x86_64 [root@chensiqi1 ~]# ll `which awk` lrwxrwxrwx. 1 root root 4 Dec 23 20:25 /bin/awk -> gawk [root@chensiqi1 ~]# awk --version GNU Awk 3.1.7 Copyright (C) 1989, 1991-2009 Free Software Foundation. This program is free software; you can redistribute it and/or modify it under the terms of the GNU General Public License as published by the Free Software Foundation; either version 3 of the License, or (at your option) any later version. This program is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU General Public License for more details. You should have received a copy of the GNU General Public License along with this program. If not, see http://www.gnu.org/licenses/.
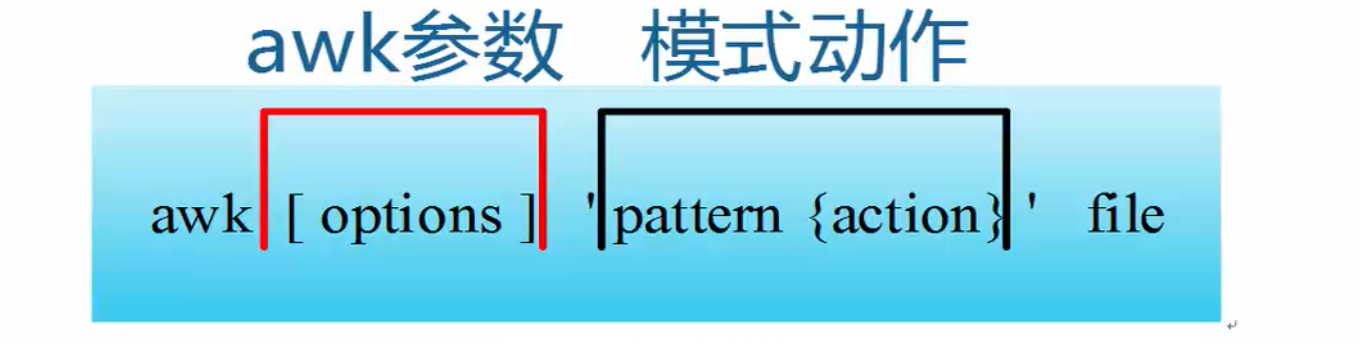
1.4 awk format
- awk instructions are composed of patterns, actions, or combinations of patterns and actions.
- Patterns are patterns, which can be understood as sed pattern matching. They can be composed of expressions or regular expressions between two forward slashes. For example, NR==1, which is the pattern, can be understood as a condition.
- Actions, or action s, consist of one or more statements in braces separated by semicolons. For example, awk uses formats:
The content that awk handles can come from standard input (<), one or more text files or pipes.
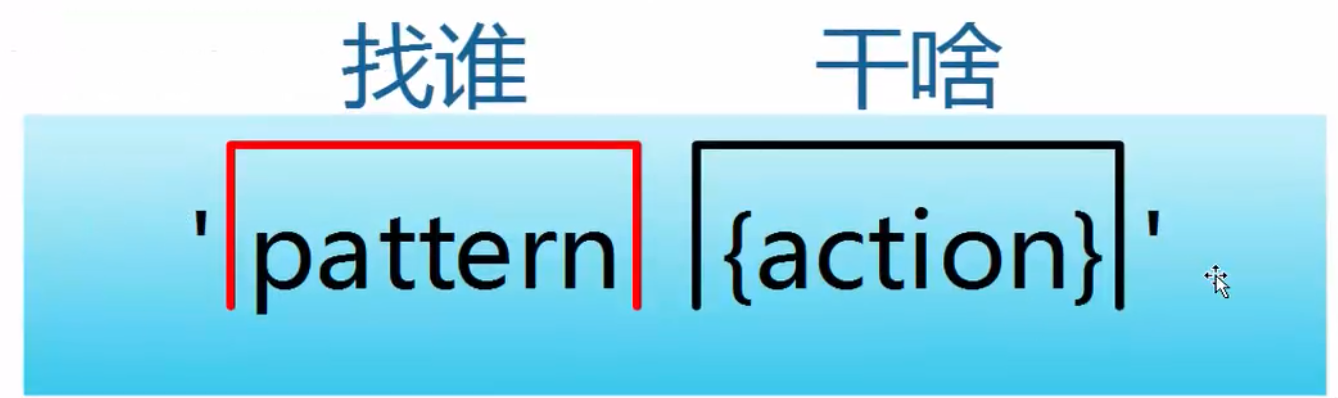
- Patterns are not only pattern s, but also conditions. Who are you looking for and who are you looking for? Tall, fat and thin, men and women? They are both conditions and modes.
- Action is both action and action. It can be understood as what to do and what to do when you find someone.
The detailed introduction of mode and action is put in the latter part. Now we have a better understanding of awk structure.
1.5 Mode Action
Example 1-1: Basic patterns and actions
[root@chensiqi1 ~]# awk -F ":" 'NR>=2 && NR<=6{print NR,$1}' /etc/passwd
2 bin
3 daemon
4 adm
5 lp
6 sync
Instructions:
- F specifies the separator as a colon, which is equivalent to cutting fields with ":" as a kitchen knife.
NR >= 2 & & NR<== 6: This part represents the schema, which is a condition to take the second line to the sixth line.
{print NR,{}: This section represents the action, indicating that the NR line number and the first column of $1 are to be output.Example 1-2 has only modes
[root@chensiqi1 ~]# awk -F ":" 'NR>=2&&NR<=6' /etc/passwd bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin adm:x:3:4:adm:/var/adm:/sbin/nologin lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin sync:x:5:0:sync:/sbin:/bin/sync Instructions: - F specifies the separator as a colon NR >= 2 &&NR<== 6 is the condition, which means take the second line to the sixth line. But there's no action here, so you need to understand that if there's only condition (mode) and no action, awk defaults to output the whole line.
Example 1-3: Only actions
[root@chensiqi1 ~]# awk -F ":" '{print NR,$1}' /etc/passwd
1 root
2 bin
3 daemon
4 adm
5 lp
6 sync
7 shutdown
8 halt
9 mail
10 uucp
The following omissions...
Instructions:
- F specifies the separator as a colon
There are no conditions, which means that every line is processed.
{print NR,{} represents the action, showing the NR line number and the first column of $1
Understand that awk handles every line when there are no conditions.Example 1-4: Multiple patterns and actions
[root@chensiqi1 ~]# awk -F ":" 'NR==1{print NR,$1}NR==2{print NR,$NF}' /etc/passwd
1 root
2 /sbin/nologin
Instructions:
- F specifies the separator as a colon
There are several combinations of conditions and actions.
NR==1 denotes the condition. When the condition of line number (NR) equal to 1 is satisfied, the {print NR,{} action is executed to output the line number and the first column.
NR==2 denotes the condition. When the condition of line number (NR) equal to 2 is satisfied, the {print NR,$NF} action is executed, and the line number and the last column ($NF) are output.Be careful:
- Pattern s and {Action} need to be raised in single quotes to prevent shell s from interpreting.
- Patterns are optional. If not specified, awk will process all records in the input file. If a Pattern is specified, awk only processes records that match the specified Pattern.
- The {Action} is an awk command, which can be either a single command or multiple commands. The entire action (including all the commands in it) must be placed between {and}.
- Action must be wrapped by {and Patern is the one that is not wrapped by {
- Target file to be processed by file
1.6 awk execution process
Before we get into awk, we need to know how awk handles files.
Example 1-5 Sample File Creation
[root@chensiqi1 ~]# mkdir /server/files/ -p [root@chensiqi1 ~]# head /etc/passwd > /server/files/awkfile.txt [root@chensiqi1 ~]# cat /server/files/awkfile.txt root:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin adm:x:3:4:adm:/var/adm:/sbin/nologin lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin sync:x:5:0:sync:/sbin:/bin/sync shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown halt:x:7:0:halt:/sbin:/sbin/halt mail:x:8:12:mail:/var/spool/mail:/sbin/nologin uucp:x:10:14:uucp:/var/spool/uucp:/sbin/nologin
This file contains only ten lines. We use the following command:
Example 1-6 awk execution process demonstration
[root@chensiqi1 ~]# awk 'NR>=2{print $0}' /server/files/awkfile.txt
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
uucp:x:10:14:uucp:/var/spool/uucp:/sbin/nologin
//Instructions:
//The condition NR >= 2 indicates that when the line number is greater than or equal to 2, the whole line is displayed by executing {print $0}.
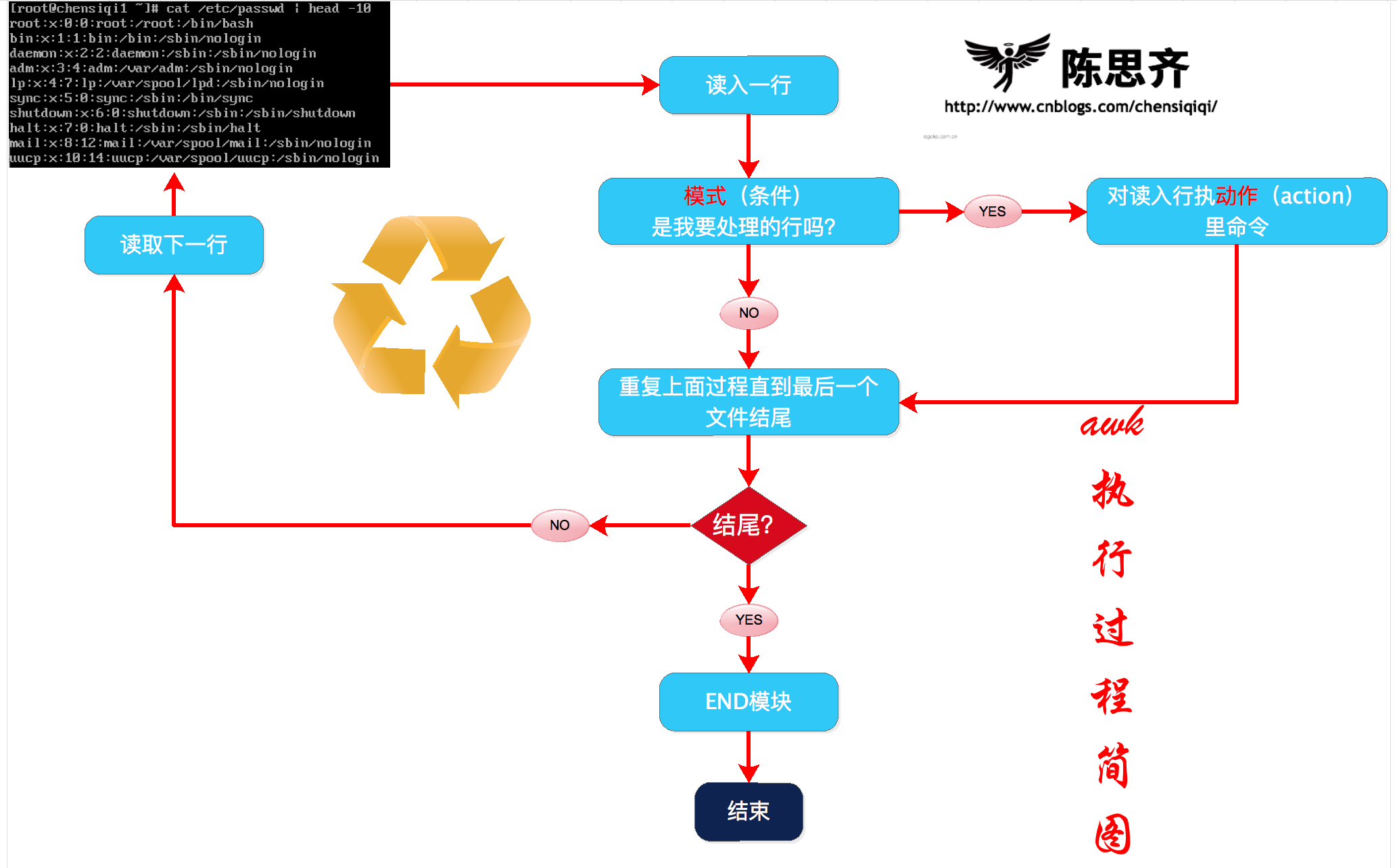
awk This command contains the schema part (condition) and the action part (action) through processing files one line at a time. awk Rows specified by mode (condition) will be processed1.6.1 Summary of awk execution process
1) awk reads in the first line
2) Judging whether the condition NR >= 2 in the model is met
a, if matched, execute the corresponding action {print $0}
b, if the condition does not match, continue reading the next line
3) Continue reading the next line
4) Repeat process 1-3 until the last line is read (EOF: end of file)
1.7 Records and Fields
Next, I bring you two new concepts of records and fields. Here, for your understanding, records can be treated as rows, that is, records= rows, fields are equivalent to columns, and fields= columns.
| Name | Meaning |
|---|---|
| record | Record, row |
| field | Domain, region, field, column |
1.7.1 Records (Lines)
Check out the following paragraph
root:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin adm:x:3:4:adm:/var/adm:/sbin/nologin lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin sync:x:5:0:sync:/sbin:/bin/sync shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown halt:x:7:0:halt:/sbin:/sbin/halt mail:x:8:12:mail:/var/spool/mail:/sbin/nologin uucp:x:10:14:uucp:/var/spool/uucp:/sbin/nologin
Reflection:
How many lines are there? How do you know? Through what sign?
awk considers every input data to be processed to be formatted and structured, not just a bunch of strings. By default, each line is a record and ends with a newline separator (\n)
1.7.2 Record Separator-RS

- By default, awk is a record for each line
- RS not only records separator input and output data record separator, but also how each line is missing, which indicates how the separator is when each record is input, and how the line is separated from each other.
- NR is both number of record record record (line) number, indicating the number of record (line) currently being processed.
- ORS outputs both record separator and record separator.
awk uses the built-in variable RS to store the input record separator. RS represents the input record separator. This value can be redefined and modified by the BEGIN module.
Example 1-1: Use "/" as the default record delimiter
Sample file:
[root@chensiqi1 ~]# cat /server/files/awkfile.txt root:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin adm:x:3:4:adm:/var/adm:/sbin/nologin lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin sync:x:5:0:sync:/sbin:/bin/sync shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown halt:x:7:0:halt:/sbin:/sbin/halt mail:x:8:12:mail:/var/spool/mail:/sbin/nologin uucp:x:10:14:uucp:/var/spool/uucp:/sbin/nologin
[root@chensiqi1 ~]# awk 'BEGIN{RS="/"}{print NR,$0}' /server/files/awkfile.txt
1 root:x:0:0:root:
2 root:
3 bin
4 bash
bin:x:1:1:bin:
5 bin:
6 sbin
7 nologin
daemon:x:2:2:daemon:
8 sbin:
9 sbin
10 nologin
adm:x:3:4:adm:
11 var
12 adm:
13 sbin
14 nologin
lp:x:4:7:lp:
15 var
16 spool
17 lpd:
18 sbin
19 nologin
sync:x:5:0:sync:
20 sbin:
21 bin
22 sync
shutdown:x:6:0:shutdown:
23 sbin:
24 sbin
25 shutdown
halt:x:7:0:halt:
26 sbin:
27 sbin
28 halt
mail:x:8:12:mail:
29 var
30 spool
31 mail:
32 sbin
33 nologin
uucp:x:10:14:uucp:
34 var
35 spool
36 uucp:
37 sbin
38 nologin
//Instructions:
//Print out NR (record number line number) at the beginning of each line and print out the content of $0 (whole line) for each line.
//We set the value of RS (record separator) to "/", which means that a line (record) ends with "/".
//In awk's eyes, the file is a continuous string from beginning to end, which happens to have some \ n (return line break), n is also a character.Let's review what line (record) really means.
- Line (record): End by default withn (return line change). And the end of this line is a record delimiter.
- So in awk, the RS (record separator) variable represents the end symbol of the line (by default, carriage return).
In our work, we can change the value of RS variable to determine the end mark of the line, and ultimately determine the content of "each line".
To make it easy for people to understand, awk defaults to set the value of RS to " n"
Be careful:
Awk's BEGIN module, I will explain in detail later (pattern-BEGIN module), here you just need to know that in the BEGIN module we define some awk built-in variables.
1.7.3 Understanding of $0
- As an example of 1.7.2, you can see that in awk, $0 represents the whole line, but in fact, awk uses $0 to represent the whole record. Record delimiters exist in RS variables, or each record ends with RS built-in variables.
- In addition, awk has a built-in variable NR for the record number of each row, and the value of NR automatically + 1 after each record is processed.
- Here's an example to impress you.
Example 1-2:NR record number
[root@chensiqi1 ~]# awk '{print NR,$0}' /server/files/awkfile.txt
1 root:x:0:0:root:/root:/bin/bash
2 bin:x:1:1:bin:/bin:/sbin/nologin
3 daemon:x:2:2:daemon:/sbin:/sbin/nologin
4 adm:x:3:4:adm:/var/adm:/sbin/nologin
5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
6 sync:x:5:0:sync:/sbin:/bin/sync
7 shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
8 halt:x:7:0:halt:/sbin:/sbin/halt
9 mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
10 uucp:x:10:14:uucp:/var/spool/uucp:/sbin/nologin
Instructions:
NR is not only the number of record, but also the record number of current record. It can be understood as line number at the beginning.
$0 represents the whole line or record1.7.4 Enterprise Interview Questions: Sort by word occurrence frequency in descending order (calculate the number of repetitions of each word in the file)
Note: (Use sort and uniq here)
Title:
Title creation method:
sed -r '1,10s#[^a-zA-Z]+# #g' /etc/passwd>/server/files/count.txt
[root@chensiqi1 files]# cat /server/files/count.txt root x root root bin bash bin x bin bin sbin nologin daemon x daemon sbin sbin nologin adm x adm var adm sbin nologin lp x lp var spool lpd sbin nologin sync x sync sbin bin sync shutdown x shutdown sbin sbin shutdown halt x halt sbin sbin halt mail x mail var spool mail sbin nologin uucp x uucp var spool uucp sbin nologin
Train of thought:
Line up all the words so that each word is a separate line
1) Set RS value to blank space
2) Replace all spaces in the file with the return line break "\n"
3) All successive letters of grep are arranged in a row by the grep-o parameter.
Method 1:
[root@chensiqi1 files]# awk 'BEGIN{RS="[ ]+"}{print $0}' count.txt | sort |uniq -c|sort
1
1 bash
1 lpd
2 daemon
2 lp
3 adm
3 halt
3 mail
3 root
3 shutdown
3 spool
3 sync
3 uucp
4 var
5 bin
6 nologin
10 x
12 sbinMethod two:
[root@chensiqi1 files]# cat count.txt | tr " " "\n" | sort | uniq -c | sort
1 bash
1 lpd
2 daemon
2 lp
3 adm
3 halt
3 mail
3 root
3 shutdown
3 spool
3 sync
3 uucp
4 var
5 bin
6 nologin
10 x
12 sbinMethod three:
[root@chensiqi1 files]# grep -o "[a-zA-Z]\+" count.txt | sort | uniq -c | sort
1 bash
1 lpd
2 daemon
2 lp
3 adm
3 halt
3 mail
3 root
3 shutdown
3 spool
3 sync
3 uucp
4 var
5 bin
6 nologin
10 x
12 sbin1.7.5 awk record knowledge summary
- NR stores the number of each record (line number) and automatically + 1 when reading a new line
- RS is the delimiter of the record of the input data. It is understood simply that the end flag of each record can be specified.
- The function of RS is to indicate the end of a record.
- When we modify the value of RS, it is better to cooperate with NR (line) to see the changes, that is, to modify the value of RS to view the results through NR, debug awk program.
- A record delimiter for ORS output data
One awk learning skill:
How many steps does an elephant take in the refrigerator? Open the refrigerator, put the elephant in and close the refrigerator door.
The same is true for awk. Step by step, first modify RS, then debug it with NR to see how it is segregated. Then, uniq-c is de-duplicated by sort sorting
1.7.6 fields (columns)
- Each record is composed of multiple fields. By default, the delimiters between regions are separated by spaces (i.e. spaces or tabs), and the delimiters are recorded in the built-in variable FS. The number of fields per row is stored in the built-in variable NF of awk.
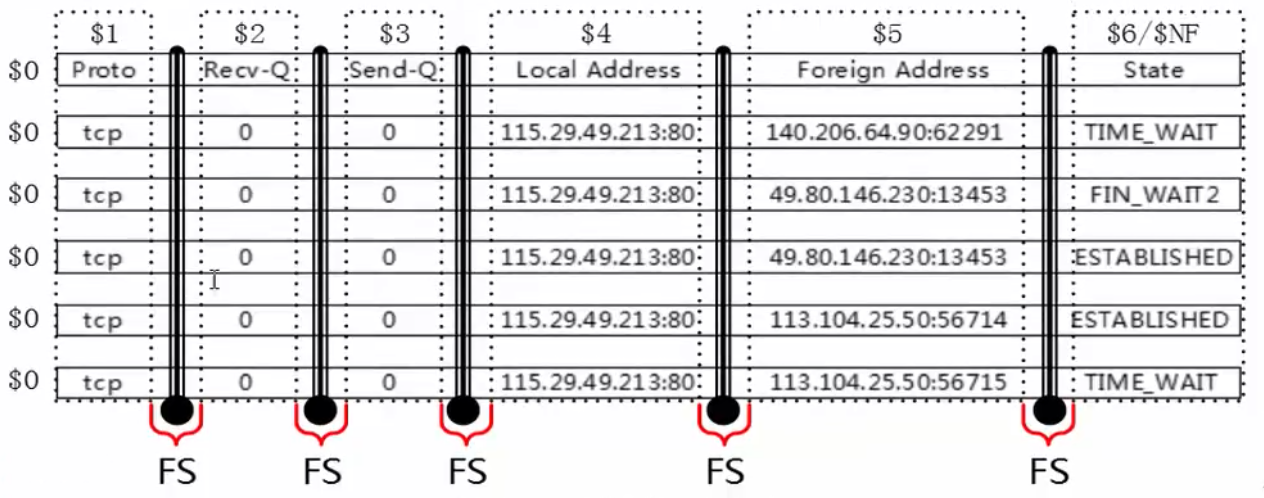
- FS is both field separator and input field (column) separator. The separator is the kitchen knife, which cuts a line of strings into many regions.
- NF is the number of fileds, representing the number of columns (fields) in a row. It can be understood as how many copies of a kitchen knife are cut after cutting a row.
OFS Output Field (Column) Separator
- awk uses the built-in variable FS to record the contents of the area separator. FS can be changed on the command line by the - F parameter or by the BEGIN module.
- Then we use $n and N as integers to get the cut region, $1 for the first region, $2 for the second region, $NF for the last region.
Here we use examples to enhance learning.
Example 1-3: Specify delimiters
[root@chensiqi1 files]# awk -F ":" 'NR>=2&&NR<=5{print $1,$3}' /server/files/awkfile.txt
bin 1
daemon 2
adm 3
lp 4
Instructions:
With: (colon) as the separator, the first and third regions between lines 2 and 5 are displayed.- The FS knowledge here is a character, in fact, it can specify more than one character, at this time the value specified by FS can be a regular expression.
- Normally, when you specify separators (non-spaces), for example, you specify multiple area separators, each of which is a knife that cuts the left and right sides into two parts.
Enterprise Interview Question: Take out both chensiqi and 215379068 at the same time (specify multiple separators)
[root@chensiqi1 files]# echo "I am chensiqi,my qq is 1234567890">>/server/files/chensiqi.txt [root@chensiqi1 files]# cat /server/files/chensiqi.txt I am chensiqi,my qq is 1234567890
At the same time, the contents of chensiqi and 1234567890 were taken out.
Train of thought:
We use the default idea of using a knife at a time, need to cooperate with the pipeline. How to use two knives at the same time? Look at the following results
[root@chensiqi1 files]# awk -F "[ ,]" '{print $3,$NF}' /server/files/chensiqi.txt
chensiqi 1234567890
Instructions:
Specify the area separator with the command-F parameter
[,] is the content of a regular expression, which represents a whole,'one'character, either space or comma (,), merged together, - F "[,]" denotes a space or comma (,) as a region delimiter.Tips:
A comma in an action ('{print$3, \ NF}') denotes a space. In fact, the comma in an action is the value of OFS, which we will explain later. At the beginning, we all regard commas as spaces in our actions.
Example: There are some differences between default and specified delimiters
[root@chensiqi1 files]# ifconfig eth0 | awk 'NR==2' >/server/files/awkblank.txt
[root@chensiqi1 files]# cat /server/files/awkblank.txt
inet addr:192.168.197.133 Bcast:192.168.197.255 Mask:255.255.255.0
#Default delimiter time
[root@chensiqi1 files]# awk '{print $1}' /server/files/awkblank.txt
inet
#When specifying a separator
[root@chensiqi1 files]# awk -F "[ :]+" '{print $1}' /server/files/awkblank.txt
[root@chensiqi1 files]# awk -F "[ :]+" '{print $2}' /server/files/awkblank.txt
inet
//Instructions:
awk Default FS A separator for a sequence of spaces, one or more spaces tab They all think it's the same, it's a whole.- The beginning of the file has many consecutive spaces, followed by the inet character
- When we use the default delimiter, $1 is content.
- When we specify other separators (non-spaces), the region changes.
- Why in the end, we do not study in depth here, as long as we understand the situation, pay attention to it.
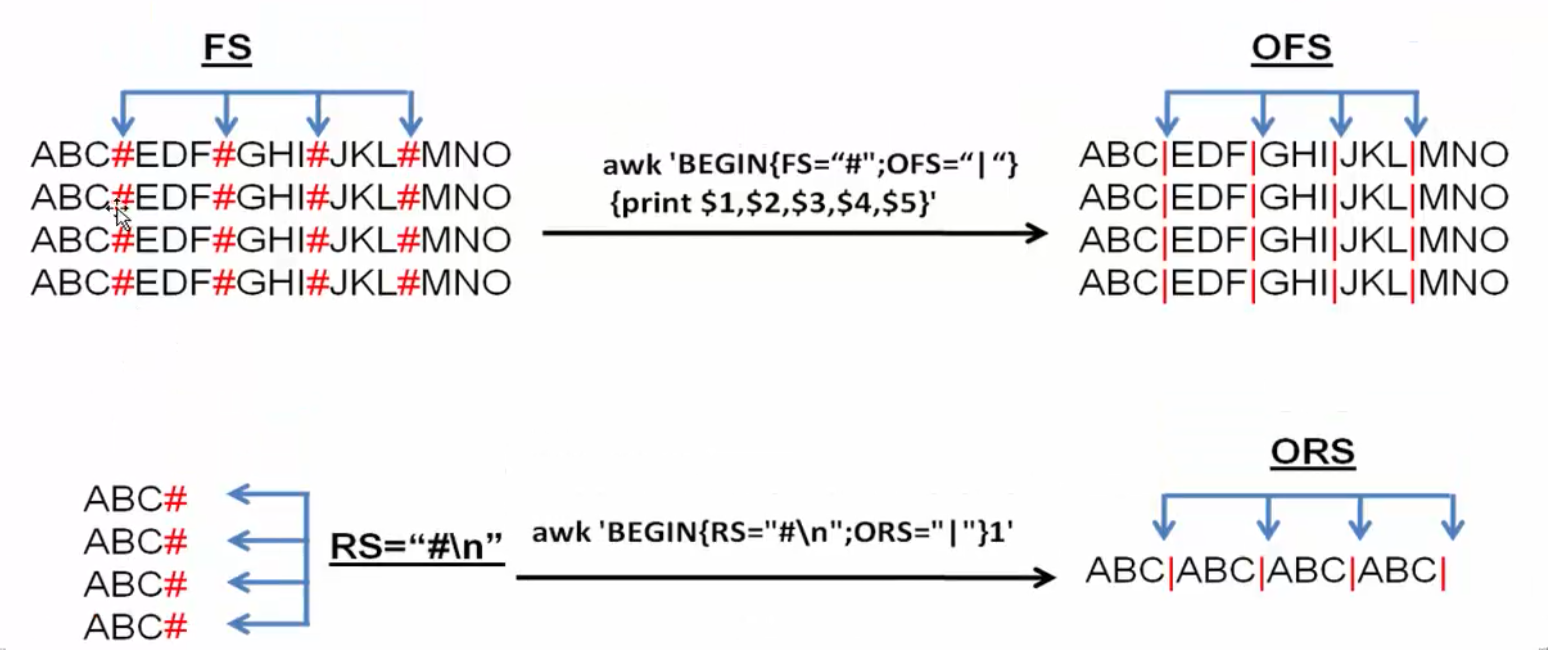
Introduction of 1.7.7 ORS and OFS
Now let's talk about the meaning of the two built-in variables, ORS and OFS.
- RS is the input record separator that determines how awk reads or separates each line (record)
- ORS represents the output record delimiter, which determines how awk outputs a line (record). By default, return line feeds (\n)
- FS is the input area separator, which determines how awk can be divided into multiple areas after reading a line.
- OFS represents the output area separator, which determines what to use when awk outputs each area.
- Awk is so powerful that you can use RS and FS to determine how awk reads data. You can also specify how awk outputs data by modifying the value of ORS and OFS.
1.8 Field and Record Summary
Now you should know something about awk's record field. Let's summarize it. Learning to summarize stage knowledge is a necessary skill for learning operation and maintenance.

- RS record separator, which represents the end flag of each line
- NR line number (record number)
- FS field separator, separator or end flag for each column
- NF is the number of columns per row and the number of fields in each record.
- The $symbol indicates taking a column (field), $1$NF
- NF represents the number of regions (columns) in the record, and $NF takes the last column (region).
- FS (- F) field (column) separator, - F (FS) "<==>'BEGIN{FS=':'}"
- RS record separator (end of line identifier)
- NR line number
- Choose the appropriate knife FS (***), RS,OFS,ORS
- Delimiter ==> end identifier
- Records and regions, you have a new understanding of what we call rows and columns (RS, FS)
1.9 awk basic introduction summary
When we get here, let's look back at what we learned before.
- Command line structure of awk
- awk mode and action
- Records and fields of awk
The core of comparison is the field.
In addition, these enterprise interview questions are necessary for learning awk, and they must be written by themselves.
Chapter 2 awk Advancement
2.1 awk mode and action
Following the detailed introduction, awk has several modes:
- Regular expressions as patterns
- Comparing expressions as patterns
- Scope mode
- Special patterns BEGIN and END
Awk mode is the essential and basic content for you to play awk well. You must master it skillfully.
2.2 Regular Expressions as Patterns
Like sed, awk can also match input text by pattern matching. When it comes to pattern matching, there must be regular expressions. awk also supports a large number of regular expression patterns, most of which are similar to the meta-characters supported by sed, and regular expressions are essential tools for playing with three swordsmen. The following table lists the meta-characters of regular expressions supported by awk:
awk supports metacharacters by default:
| Meta character | function | Example | explain |
|---|---|---|---|
| ^ | The beginning of a string | /^ chensiqi / or $3~/^chensiqi/ | Matches all strings starting with chensiqi; matches all third columns starting with chensiqi |
| \$ | End of string | / chensiqi $/or $3~/chensiqi$/ | Matches all strings ending with chensiqi; matches those ending with chensiqi in the third column |
| (point) | Match any but several characters (including carriage return characters) | /c..l/ | Match the letter c, then two arbitrary characters, and the line ending with l |
| * | Repeat 0 or more previous characters | /a*cool/ | Matching 0 or more a followed by cool's rows |
| + | Repeat the previous character one or more times | /a+b/ | Match one or more lines of a plus string b |
| ? | Match 0 or one character in front | /a?b/ | Match lines starting with the letters a or b or c |
| [] | Matches any character in a specified character group | /^[abc]/ | Match lines starting with the letters a or b or c |
| [^] | Matches any character that is not in the specified character group | /^[^abc]/ | Match rows that do not begin with the letters a or b or c |
| () | Subexpression combination | /(chensiqi)+/ | Represents one or more cool combinations, enclosed in parentheses when some characters need to be combined |
| \ | Or what it means | /(chensiqi)\ |
Metacharacters that awk does not support by default: (parameter -- posix)
| Meta character | function | Example | explain |
|---|---|---|---|
| x{m} | x character repeats m times | /cool{5}/ | Match l character 5 times |
| x{m,} | Repeat x characters at least m times | /(cool){2,}/ | Match cool as a whole, at least twice |
| x{m,n} | The x character is repeated at least m times, but not more than n times | /(cool){5,6}/ | Match cool as a whole, at least five times, up to six times |
Tips:
- Brackets represent a global match, and if not, a character in front of it is matched. awk does not support this form of regularization by default, requiring -- posix parameter or -- re-interval
- The use of regular expressions, by default, finds matched strings in rows and performs action operations if there are matches, but sometimes only fixed columns are needed to match the specified regular expressions, such as: I want to get the fifth column {$5} in the / etc/passwd file to find rows that match mail strings, so I need to use two other matching operators, and there are only two in awk. There are two operators to match regular expressions.
2.2.1 awk regular matching operator
awk regular matching operator:
|~| Expressions used to match records or regions|
|--|--|
|! | Used to convey meaning opposite to |
Here's how awk matches strings through regular expressions
2.2.2 awk regular expressions match entire rows
[root@chensiqi1 files]# awk -F ":" '/^root/' awkfile.txt root:x:0:0:root:/root:/bin/bash
The effect is the same as that below.
[root@chensiqi1 files]# awk -F ":" '$0~/^root/' awkfile.txt root:x:0:0:root:/root:/bin/bash
Tips:
When awk only uses regular expressions, it defaults to match the whole line, i.e.'$0~/^root /'is the same as'/^ root /'.
2.2.3 awk regular expression matches a column in a row
[root@chensiqi1 files]# awk -F ":" '$5~/shutdown/' awkfile.txt shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
Tips:
- $5 represents the fifth region (column)
- ~ Representation matching (regular expression matching)
- / shutdown / represents the string matching shutdown
Merge together
$5~/shutdown/ indicates that the fifth region (column) matches the regular expression / shutdown /, which displays the line when column 5 contains the string shutdown.
2.2.4 The beginning and end of an area
Now that you know how to use regular expression matching operators, let's look at the difference between awk regularity and grep and sed.
awk regular expression
|^| Match the beginning of a string|
|--|--|
| $| Matches the end of a string|
In both sed and grep commands, we treat them as the beginning and end of a line. But in awk, he represents the beginning and end of a string.
Next, we use exercises to relate how awk uses regular expressions.
2.2.5 Create a Test Environment
[root@chensiqi1 ~]# cat >>/server/files/reg.txt<<KOF Zhang Dandan 41117397 :250:100:175 Zhang Xiaoyu 390320151 :155:90:201 Meng Feixue 80042789 :250:60:50 Wu Waiwai 70271111 :250:80:75 Liu Bingbing 41117483 :250:100:175 Wang Xiaoai 3515064655 :50:95:135 Zi Gege 1986787350 :250:168:200 Li Youjiu 918391635 :175:75:300 Lao Nanhai 918391635 :250:100:175 KOF
2.2.6 Test File Description
Zhang Dandan 41117397 :250:100:175 Zhang Xiaoyu 390320151 :155:90:201 Meng Feixue 80042789 :250:60:50 Wu Waiwai 70271111 :250:80:75 Liu Bingbing 41117483 :250:100:175 Wang Xiaoai 3515064655 :50:95:135 Zi Gege 1986787350 :250:168:200 Li Youjiu 918391635 :175:75:300 Lao Nanhai 918391635 :250:100:175
Explain:
- The first column is surname.
- The second column is the name.
- The first column and the second column together are names.
- The third column is the corresponding ID number.
- The last three columns are the amount of three donations.
2.2.7 awk regular expression exercises
Exercise 1: Show Zhang's second donation amount and her name
Exercise 2: Show Xiaoyu's name and ID number
Exercise 3: Display the full name and ID number of all people with ID numbers starting at 41
Exercise 4: Show the full names of all people starting with a D or X
Exercise 5: Show the full name of a person whose last digit of all ID numbers is 1 or 5
Exercise 6: Show Xiaoyu's donation. Each value begins with $ For example, $520, $200, $135
Exercise 7: Display the full names of all people in the form of surnames and names, such as Meng, Feixue
2.2.8 awk Regular Expressions Exercise - Explanation
Example 1: Display Zhang's second donation amount and her name
[root@chensiqi1 files]# cat reg.txt
Zhang Dandan 41117397 :250:100:175
Zhang Xiaoyu 390320151 :155:90:201
Meng Feixue 80042789 :250:60:50
Wu Waiwai 70271111 :250:80:75
Liu Bingbing 41117483 :250:100:175
Wang Xiaoai 3515064655 :50:95:135
Zi Gege 1986787350 :250:168:200
Li Youjiu 918391635 :175:75:300
Lao Nanhai 918391635 :250:100:175
[root@chensiqi1 files]# awk -F "[ :]+" '$1~/^Zhang/{print $2,$(NF-1)}' reg.txt
Zhang 100
Zhang 90Explain:
- - F specifies the separator, and now you know that - F, or FS, also supports regular expressions.
- [:] + denotes a continuous space or colon
- - F "[:]+" is delimited by consecutive spaces or colons
- / Zhang / denotes the condition that the entire line contains Dan characters.
- {print {,$(NF-1)} denotes the action, and when the condition is met, the first column ($1) and the penultimate column ($(NF-1)) are displayed, of course, $5 is also possible.
Be careful:
How many columns are there in a row for NF, and the whole row for NF-1 is the penultimate column.
The $(NF-1) is the penultimate column.
Example 2: Display Xiaoyu's surname and ID number
[root@chensiqi1 files]#cat reg.txt
Zhang Dandan 41117397 :250:100:175
Zhang Xiaoyu 390320151 :155:90:201
Meng Feixue 80042789 :250:60:50
Wu Waiwai 70271111 :250:80:75
Liu Bingbing 41117483 :250:100:175
Wang Xiaoai 3515064655 :50:95:135
Zi Gege 1986787350 :250:168:200
Li Youjiu 918391635 :175:75:300
Lao Nanhai 918391635 :250:100:175
[root@chensiqi1 files]# awk -F "[ :]+" '$2~/^Xiaoyu/{print $1,$3}' reg.txt
Zhang 390320151
//Instructions:
//Specify the delimiter - F "[:]+"
$2~/Xiaoyu/Representation condition, the second column contains Xiaoyu Execute the corresponding action
{print $1,$3}Represents actions, displaying the contents of the first and third columnsExample 3: Display the full name and ID number of all people with ID numbers starting at 41
[root@chensiqi1 files]# cat reg.txt
Zhang Dandan 41117397 :250:100:175
Zhang Xiaoyu 390320151 :155:90:201
Meng Feixue 80042789 :250:60:50
Wu Waiwai 70271111 :250:80:75
Liu Bingbing 41117483 :250:100:175
Wang Xiaoai 3515064655 :50:95:135
Zi Gege 1986787350 :250:168:200
Li Youjiu 918391635 :175:75:300
Lao Nanhai 918391635 :250:100:175
[root@chensiqi1 files]# awk -F "[ :]+" '$3~/^(41)/{print $1,$2,$3}' reg.txt
Zhang Dandan 41117397
Liu Bingbing 41117483 Example 4: Display all full names starting with a D or X
[root@chensiqi1 files]# cat reg.txt
Zhang Dandan 41117397 :250:100:175
Zhang Xiaoyu 390320151 :155:90:201
Meng Feixue 80042789 :250:60:50
Wu Waiwai 70271111 :250:80:75
Liu Bingbing 41117483 :250:100:175
Wang Xiaoai 3515064655 :50:95:135
Zi Gege 1986787350 :250:168:200
Li Youjiu 918391635 :175:75:300
Lao Nanhai 918391635 :250:100:175
[root@chensiqi1 files]# awk -F "[ :]+" '$2~/^D|^X/{print $1,$2}' reg.txt
Zhang Dandan
Zhang Xiaoyu
Wang Xiaoai
//Instructions:
-F "[ : ]+"Specifies a delimiter
|Express or^with...StartBe careful:
Here we use parentheses to indicate that ^ (D|X) is equivalent to ^ D|^X. It is wrong for some students to write ^ D|X.
Example 5: Display the full name of a person whose last digit of all ID numbers is 1 or 5
[root@chensiqi1 files]# cat reg.txt
Zhang Dandan 41117397 :250:100:175
Zhang Xiaoyu 390320151 :155:90:201
Meng Feixue 80042789 :250:60:50
Wu Waiwai 70271111 :250:80:75
Liu Bingbing 41117483 :250:100:175
Wang Xiaoai 3515064655 :50:95:135
Zi Gege 1986787350 :250:168:200
Li Youjiu 918391635 :175:75:300
Lao Nanhai 918391635 :250:100:175
[root@chensiqi1 files]# awk -F "[ :]+" '$3~/1$|5$/{print $1,$2}' reg.txt
Zhang Xiaoyu
Wu Waiwai
Wang Xiaoai
Li Youjiu
Lao Nanhai
Example 6: Show Xiaoyu's contribution, each value starting with $ For example, $520, $200, $135
[root@chensiqi1 files]# cat reg.txt
Zhang Dandan 41117397 :250:100:175
Zhang Xiaoyu 390320151 :155:90:201
Meng Feixue 80042789 :250:60:50
Wu Waiwai 70271111 :250:80:75
Liu Bingbing 41117483 :250:100:175
Wang Xiaoai 3515064655 :50:95:135
Zi Gege 1986787350 :250:168:200
Li Youjiu 918391635 :175:75:300
Lao Nanhai 918391635 :250:100:175
[root@chensiqi1 files]# awk -F "[ :]+" '$2~/Xiaoyu/{print "$"$4"$"$5"$"$6}' reg.txt
$155$90$201Example 7: Display all people's full names in the form of surnames and names, such as Meng, Feixue
[root@chensiqi1 files]# cat reg.txt
Zhang Dandan 41117397 :250:100:175
Zhang Xiaoyu 390320151 :155:90:201
Meng Feixue 80042789 :250:60:50
Wu Waiwai 70271111 :250:80:75
Liu Bingbing 41117483 :250:100:175
Wang Xiaoai 3515064655 :50:95:135
Zi Gege 1986787350 :250:168:200
Li Youjiu 918391635 :175:75:300
Lao Nanhai 918391635 :250:100:175
[root@chensiqi1 files]# awk -F "[ ]+" '{print $1","$2}' reg.txt
Zhang,Dandan
Zhang,Xiaoyu
Meng,Feixue
Wu,Waiwai
Liu,Bingbing
Wang,Xiaoai
Zi,Gege
Li,Youjiu
Lao,Nanhai2.2.9 Enterprise Interview Question: Take out the ip address of eth0
Simplest: hostname-I
awk processing:
Method 1:
[root@chensiqi1 files]# ifconfig eth0|awk 'BEGIN{RS="[ :]"}NR==31'
192.168.197.133Method two:
[root@chensiqi1 files]# ifconfig eth0 | awk -F "(addr:)|( Bcast:)" 'NR==2{print $2}'
192.168.197.133 Method three:
[root@chensiqi1 files]# ifconfig eth0 | awk -F "[ :]+" 'NR==2{print $4}'
192.168.197.133Method four:
[root@chensiqi1 files]# ifconfig eth0 | awk -F "[^0-9.]+" 'NR==2{print $2}'
192.168.197.133Tips:
- The first three methods are better understood. This fourth method needs to learn to think backwards. Look at the result we want 10.0.0.50, ip address: numbers and dots (.). Can I specify a separator, using characters other than numbers and dots as separators?
- In other words, to exclude numbers and points (.) Regular expressions and exclude commonly used is [^ 0-9.], that is, mismatched numbers and points (.)
- Finally, the - F "[^ 0 - 9]" bit separator, but use +, to denote continuity. Together, awk-F "[^ 0-9.]+"'NR==2{print }}"
Be careful:
Regular expression is a necessary condition to play awk well and must be mastered
2.2.10 Expanding Regular Expressions Clearly: +(plus sign)
[root@chensiqi1 files]# echo "------======1########2" ------======1########2 [root@chensiqi1 files]# echo "------======1########2" | grep "[-=#]" ------======1########2 [root@chensiqi1 files]# echo "------======1########2" | grep -o "[-=#]" - - - - - - = = = = = = # # # # # # # #
2.2.11 awk regular {} - curly brackets
The curly brackets in awk are not commonly used, but occasionally they are used here for a brief introduction.
Example: Remove rows with one or two o in the first column of awkfile
[root@chensiqi1 files]# awk -F: '$1~/o{1,2}/' awkfile.txt
[root@chensiqi1 files]# awk -F: --posix '$1~/o{1,2}/' awkfile.txt
root:x:0:0:root:/root:/bin/bash
daemon:x:2:2:daemon:/sbin:/sbin/nologin
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
[root@chensiqi1 files]# awk -F: --re-interval '$1~/o{1,2}/' awkfile.txt
root:x:0:0:root:/root:/bin/bash
daemon:x:2:2:daemon:/sbin:/sbin/nologin
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown2.2.12 Enterprise Case 1: Remove Common Service Port Numbers
Train of thought:
The corresponding table of service and port information under linux is in / etc/services, so this problem needs to deal with the / etc/services file.
Let's briefly analyze the following service files:
[root@chensiqi1 ~]# sed -n '23,30p' /etc/services tcpmux 1/tcp # TCP port service multiplexer tcpmux 1/udp # TCP port service multiplexer rje 5/tcp # Remote Job Entry rje 5/udp # Remote Job Entry echo 7/tcp echo 7/udp discard 9/tcp sink null discard 9/udp sink null
Starting from 23 rows, basically the first column of each row is the service name, the first part of the second column is the port number, and the second part of the second column is the tcp or udp protocol.
Method:
[root@chensiqi1 ~]# awk -F "[ /]+" '$1~/^(ssh)$|^(http)$|^(https)$|^(mysql)$|^(ftp)$/{print $1,$2}' /etc/services |sort|uniq
ftp 21
http 80
https 443
mysql 3306
ssh 22Tips:
- | Yes or no, regular expressions
- Sort is to sort the output
- uniq is to de-duplicate but not to mark the number of duplicates
- Uniq-c Deduplicates but Marks the Number of Repetitions
2.2.13 Enterprise Case 2: Remove Common Server Names
Let's try it by ourselves.
2.3 Comparative Expressions as Patterns - Some examples are needed
Before we looked at the use of regular expressions under awk, let's look at how comparative expressions work under awk.
Awk is a programming language that can make more complex judgments, and when the condition is true, awk executes related actions. The main purpose is to make relevant judgments for a certain area, such as lines with a print score of more than 80 points, so we must make a comparative judgment for this area. The following table lists the relational operators awk can use to compare digital strings, as well as regular expressions. When the expression is true, the result of the expression is 1, 0, and only if the expression is true, awk performs the relevant action.
| operator | Meaning | Example |
|---|---|---|
| < | less than | x>y |
| <= | Less than or equal to | x<=y |
| == | Be equal to | x==y |
| != | Not equal to | x!=y |
| >= | Greater than or equal to | x>=y |
| > | greater than | x<y |
The above operators are for numbers, and the following two operators have been illustrated before, for Strings
| ~ | Matching with regular expressions | x~/y/ |
|---|---|---|
| !~ | Mismatch with regular expressions | x!~y |
2.3.1 Enterprise Interview Question: Take out 23-30 lines of document/etc/services
Train of thought:
To represent a range, a range of rows, you need to use NR as a built-in variable, as well as a comparison expression.
Answer:
[root@www ~]# awk 'NR>=23&&NR<=30' /etc/services [root@www ~]# awk 'NR>22&&NR<31' /etc/services
Process:
[root@www ~]# awk 'NR>=23&&NR<=30' /etc/services tcpmux 1/tcp # TCP port service multiplexer tcpmux 1/udp # TCP port service multiplexer rje 5/tcp # Remote Job Entry rje 5/udp # Remote Job Entry echo 7/tcp echo 7/udp discard 9/tcp sink null discard 9/udp sink null [root@www ~]# awk 'NR>22&&NR<31' /etc/services tcpmux 1/tcp # TCP port service multiplexer tcpmux 1/udp # TCP port service multiplexer rje 5/tcp # Remote Job Entry rje 5/udp # Remote Job Entry echo 7/tcp echo 7/udp discard 9/tcp sink null discard 9/udp sink null
Explain:
1) Comparing expressions is more commonly used to express greater than or equal to, less than or equal to, or equal to, according to this example to learn.
2) NR denotes the line number, which is greater than or equal to 23, and NR >= 23 is less than or equal to 30, that is, NR<= 30.
3) Together, NR >= 23 and NR <= 30, & & denotes and, at the same time, holds the meaning.
4) To change the expression method, it is more than 22 rows and less than 31 rows, that is, NR > 22 & & NR < 31
2.3.2 What if a column is equal to a character?
Example: Find out that the fifth column in / etc/passwd is the row of root
Test files:
[root@www ~]# cat /server/files/awk_equal.txt root:x:0:0:root:/root:/bin/bash root:x:0:0:rootroot:/root:/bin/bash root:x:0:0:rootrooot:/root:/bin/bash root:x:0:0:rootrooot:/root:/bin/bash root:x:0:0:/root:/bin/bash
Answer:
awk -F":" '$5=="root"' /server/files/awk_equal.txt awk -F":" '$5~/^root$/' /server/files/awk_equal.txt
Process:
#Method 1: [root@www ~]# awk -F":" '$5=="root"' /server/files/awk_equal.txt root:x:0:0:root:/root:/bin/bash #Method two: [root@www ~]# awk -F":" '$5~/^root$/' /server/files/awk_equal.txt root:x:0:0:root:/root:/bin/bash
If we want to match the root string perfectly, we can use $5=="root", which is the answer.
Method two:
This problem can also restrict the string of root by regular matching. $5~/^root$/
2.4 Scope Model
| pattern1 | pattern2 | |
|---|---|---|
| Where do you come from? | reach | Where to go |
| Condition 1 | Condition 2 |
- A simple understanding of the scope model is where it comes from and where it goes.
- Matching begins with condition 1 and extends to the introduction of condition 2
1) Remember sed uses address ranges to process text content? The range mode of awk is similar to sed, but different from sed. awk can't use line number directly as the starting address of range, because awk has built-in variable NR to store record number. All of them need to use NR=1,NR=5.
2) The principle of scope pattern processing is to match the content between the first appearance of the first pattern and the first appearance of the second pattern, and perform the action. Then matching occurs from the next occurrence of the first pattern to the next occurrence of the second pattern until the end of the text. If the first pattern is matched and the second pattern is not matched, awk processes all rows from the first pattern until the end of the text. If the first pattern does not match, even if the second pattern matches, awk still does not process any rows.
awk '/start pos/,/end pos/{print $)} passwd chensiqi'
awk '/start pos/,NR==XXX{print $0}' passwd chensiqiThe expression must match a line when the scope pattern is used and when the scope condition is used.
Example 1:
[root@www files]# awk 'NR==2,NR==5{print NR,$0}' count.txt
2 bin x bin bin sbin nologin
3 daemon x daemon sbin sbin nologin
4 adm x adm var adm sbin nologin
5 lp x lp var spool lpd sbin nologinExplain:
The condition is: from the second line to the fifth line
Action: Display line number (NR) and whole line ($0)
Together, it shows the lines from the second to the fifth and the contents of the whole line.
Example 2:
[root@www files]# awk '/^bin/,NR==5{print NR,$0}' awkfile.txt
2 bin:x:1:1:bin:/bin:/sbin/nologin
3 daemon:x:2:2:daemon:/sbin:/sbin/nologin
4 adm:x:3:4:adm:/var/adm:/sbin/nologin
5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologinExplain:
The condition is: from the line starting with bin to the fifth line
The action is to display the line number and the whole line content.
Together, it shows the line number and the whole line content from the line beginning with bin to the fifth line.
Example 3:
[root@www files]# awk -F":" '$5~/^bin/,/^lp/{print NR,$0}' awkfile.txt
2 bin:x:1:1:bin:/bin:/sbin/nologin
3 daemon:x:2:2:daemon:/sbin:/sbin/nologin
4 adm:x:3:4:adm:/var/adm:/sbin/nologin
5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologinExplain:
Conditions: From the line starting with bin in column 5 to the line starting with lp
Action: Display the line number and the main course content
Together: From the third column with the line starting with bin to the line starting with lp, display its line number and the whole line content
[root@www files]# awk -F: '$5~/^bin/,$5~/^lp/{print NR,$0}' awkfile.txt
2 bin:x:1:1:bin:/bin:/sbin/nologin
3 daemon:x:2:2:daemon:/sbin:/sbin/nologin
4 adm:x:3:4:adm:/var/adm:/sbin/nologin
5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologinExplain:
Conditions: From the row of the third column beginning with bin to the row of the third column beginning with lp
Action: Display line number and whole line
2.5 awk special mode-BEGIN mode and END mode
- BEGIN module is executed before awk reads the file. It is commonly used to define our built-in variables (predefined variables, eg:FS, RS) and output headers (similar to excel table names).
- Before BEGIN mode, we mentioned in the example that custom variables, assignment of content variables, etc. have been used. It should be noted that BEGIN mode is followed by an action block, which is included in braces. Awk must perform actions in BEGIN before any processing of the input file. We can test the BEGIN module without any input files, because awk needs to execute the BEGIN mode before processing the input files. BEGIN patterns are often used to modify the ORS, RS, FS, OFS equivalents of built-in variables.
2.5.1 BEGIN module
1) First role, definition of built-in variables
Example: Take the IP address of eth0
Answer:
[root@www files]# ifconfig eth0|awk -F "(addr:)|( Bcast:)" 'NR==2{print $2}'
192.168.197.133
[root@www files]# ifconfig eth0 | awk -F "[ :]+" 'NR==2{print $4}'
192.168.197.133
[root@www files]# ifconfig eth0 | awk -F "[^0-9.]+" 'NR==2{print $2}'
192.168.197.133
#The above can also be written as
[root@www files]# ifconfig eth0 | awk 'BEGIN{FS="(addr:)|( Bcast:)"} NR==2{print $2}'
192.168.197.133
[root@www files]# ifconfig eth0 | awk 'BEGIN{FS="[ :]+"}NR==2{print $4}'
192.168.197.133
[root@www files]# ifconfig eth0 | awk 'BEGIN{FS="[^0-9.]+"}NR==2{print $2}'
192.168.197.133Be careful:
Command line-F is essentially a modified FS variable
2) The second function is to output some prompt information (header) before reading the file.
[root@www files]# awk -F: 'BEGIN{print "username","UID"}{print $1,$3}' awkfile.txt
username UID #This is the output header information.
root 0
bin 1
daemon 2
adm 3
lp 4
sync 5
shutdown 6
halt 7
mail 8
uucp 10Explain:
To output some username and UID on the first line, we should think of the special condition of BEGIN {} because BEGIN {} executes before awk reads the file.
So the result is BEGIN{print "username","UID"}, pay attention to the double quotation marks in the print command to eat, spit, and output as they are.
Then we implement the output of "username" and "UID" before outputting the contents of the file. The next step is to output the first and third columns of the file, namely {print {,}.
The final result is BEGIN{print "username","UID"}{print ,}.
3) The third function is to use the special properties of BEGIN module to carry out some tests.
[root@www files]#Simple output:
[root@www files]# awk 'BEGIN{print "hello world!"}'
hello world!
[root@www files]# #Calculate
[root@www files]# awk 'BEGIN{print 10/3}'
3.33333
[root@www files]# awk 'BEGIN{print 10/3+1}'
4.33333
[root@www files]# awk 'BEGIN{print 10/3+1/4*9}'
5.58333
[root@www files]# #Variable-related operations
[root@www files]# awk 'BEGIN{a=1;b=2;print a,b}'
1 2
[root@www files]# awk 'BEGIN{a=1;b=2;print a,b,a+b}'
1 2 34) Fourth usage: read the file with getline, then explain it at awk function
A Brief Introduction to the Concept of Variables in 2.5.2 awk
- Direct definition, direct use
- Letters in awk are considered variables. If you really want to assign a variable to a letter (string), use double quotation marks.
[root@chensiqi files]# awk 'BEGIN{a=abcd;print a}'
[root@chensiqi files]# awk 'BEGIN{abcd=123456;a=abcd;print a}'
123456
[root@chensiqi files]# awk 'BEGIN{a="abcd";print a}'
abcdExplain:
No file awk can still handle actions (commands) in BEGIN mode
2.5.3 END module
When the EHD reads all the files in awk, it executes the END module, which is usually used to output a result (cumulative, array results), or it can also be similar to the end identification information of the BEGIN module.
[root@chensiqi files]# awk 'BEGIN{print "hello world!"}{print NR,$0}END{print "end of file"}' count.txt
hello world!
1 root x root root bin bash
2 bin x bin bin sbin nologin
3 daemon x daemon sbin sbin nologin
4 adm x adm var adm sbin nologin
5 lp x lp var spool lpd sbin nologin
6 sync x sync sbin bin sync
7 shutdown x shutdown sbin sbin shutdown
8 halt x halt sbin sbin halt
9 mail x mail var spool mail sbin nologin
10 uucp x uucp var spool uucp sbin nologin
end of fileThe END mode corresponding to the BEGIN mode has the same format, but the END mode is only processed after awk has processed all the input lines.
Business case: counting the number of empty lines in / etc / services files
Train of thought:
(a) The blank line is implemented by regular expressions:____________^$
b) Statistics:
- grep -c
- awk
Method 1: grep
[root@chensiqi files]# grep "^$" /etc/services | wc -l 16 [root@chensiqi files]# grep -c "^$" /etc/services 16 Explain: The grep command - c indicates the count count count counts how many rows contain ^$.
Method two:
[root@chensiqi files]# awk '/^$/{i++}END{print i}' /etc/services
16Tips:
It uses awk's technical functions, which are very common.
Step 1: Number of empty lines
/^ The $/ denotes the condition, matches the empty line, and then executes {i++}(i++ equals i=i+1), i.e. /^$/{i=i+1}.
We can view awk execution by /^$/{i=i+1;print i}
[root@chensiqi files]# awk '/^$/{i=i+1;print "the value of i is:"i}' /etc/services
the value of i is:1
the value of i is:2
the value of i is:3
the value of i is:4
the value of i is:5
the value of i is:6
the value of i is:7
the value of i is:8
the value of i is:9
the value of i is:10
the value of i is:11
the value of i is:12
the value of i is:13
the value of i is:14
the value of i is:15
the value of i is:16Step 2: Output the final result
- But we just want the final result 16. What if we don't want the process? Output results using END mode
- Because of the special nature of END mode, it is suitable to output the final result.
So the end result is awk'/^$/{i=i+1} END {print "blank lines count:" i}'/etc/services.
awk programming idea:
- Processing first, then END module output
- {print NR,{print NR, $0} body }body module processing, after processing
- END{print "end of file"} outputs a result
Enterprise Interview Question 5: Document count.txt, the content of the document is 1 to 100 (generated by seq 100). Please calculate the results of adding up the values of each line of the file (calculated 1 +... + 100).
Train of thought:
Each line of a file has only one number, so we need to add up the contents of each line of the file.
Looking back on the previous question, we used i++ i=i+1.
Here we need to use the second commonly used expression.
i=i+$0
By contrast, it's just $0 for the top one.
[root@chensiqi files]# awk '{i=i+$0}END{print i}' count.txt
5050Actions in 2.6 awk
In a pattern-action statement, a pattern determines when an action is executed, and sometimes the action is very simple: a separate print or assignment statement. In some cases, actions may be multiple statements, separated by line breaks or semicolons.
If there are two or more statements in awk's actions, they need to be separated by semicolons
The action part can be understood as the content in curly brackets, which can be divided into:
- Expression
- Process Control Statement
- Empty statement
- Array (I'll write an awk advanced section later if I have time to introduce it)
2.7 awk mode and action summary
- The awk command core consists of patterns and actions
- The mode is the condition, the action is what to do.
1) Regular expression: must master regularity, proficiency
2) Conditional Expressions: Ratio Size, Equality of Comparisons
3) Range expression: where to go and where to go - Note that there can only be one BEGIN or END module. BEGIN{}BEGIN {} or END{}END {} are all wrong.
2.8 Summary of awk execution process
Look back at awk's structure
Awk-F specifies the separator'BRGIN{}END {}', as shown below

#awk complete execution process
[root@chensiqi ~]# awk -F ":" 'BEGIN{RS="/";print "hello world!"}{print NR,$0}END{print "end of file"}' /server/files/awkfile.txt
hello world!
1 root:x:0:0:root:
2 root:
3 bin
4 bash
bin:x:1:1:bin:
5 bin:
6 sbin
7 nologin
daemon:x:2:2:daemon:
8 sbin:
9 sbin
10 nologin
adm:x:3:4:adm:
11 var
12 adm:
13 sbin
14 nologin
lp:x:4:7:lp:
15 var
16 spool
17 lpd:
18 sbin
19 nologin
sync:x:5:0:sync:
20 sbin:
21 bin
22 sync
shutdown:x:6:0:shutdown:
23 sbin:
24 sbin
25 shutdown
halt:x:7:0:halt:
26 sbin:
27 sbin
28 halt
mail:x:8:12:mail:
29 var
30 spool
31 mail:
32 sbin
33 nologin
uucp:x:10:14:uucp:
34 var
35 spool
36 uucp:
37 sbin
38 nologin
end of fileExplain:
We also define delimiters on the command line and RS built-in variables in BEGIN mode, and finally output the results through END mode.
2.9 awk array
awk provides an array to store a set of related values.
Awk is a programming language, it certainly supports the use of arrays, but it is different from c language arrays. Arrays are called associative arrays in awk because their subscripts can be either numbers or strings. Subscripts are often referred to as keys and are associated with the values of the corresponding array elements. The keys and values of the array elements are stored in a table inside the awk program and stored by a certain hashing algorithm, so the array elements are not stored in order. The printing order is certainly not in a certain order, but we can achieve our own results by re-operating the required data through pipelines.
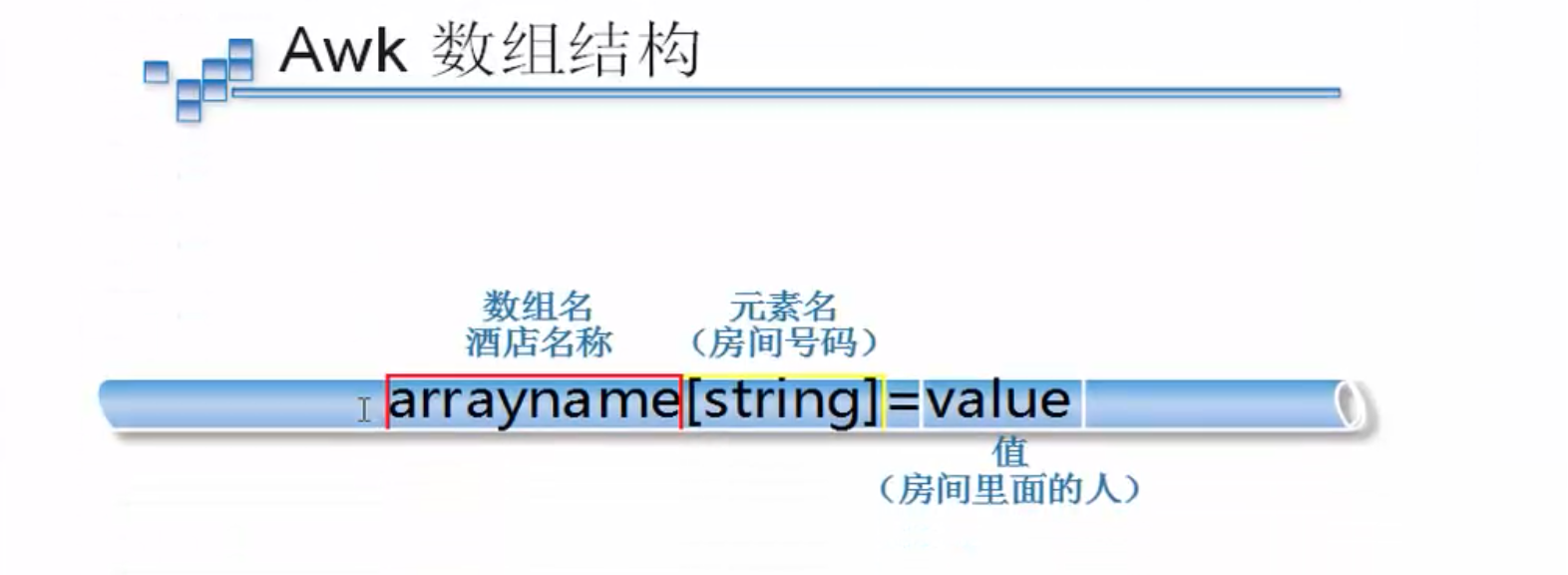
As you can easily see from the figure, awk arrays are just like hotels. The name of the array is like the name of the hotel, the name of the array element is like the hotel room number, and the contents of each array element are like the people in the hotel room.
2.10 Picture-Array
Suppose we have a hotel.
Hotel <==> chensiqihotel
There are several rooms in the hotel, 110, 119, 120 and 114.
Hotel Room 110 <==> chensiqihotel [110] Hotel Room 120 <==> chensiqihotel [120] Hotel Room 119 <==> chensiqihotel [119] Room 114 <==> chensiqi Hotel [114]
Guests staying in hotel rooms
Room 110 is occupied by Xiaoyu <==> chensiqihotel [110]= "xiaoyu" Room 119 is occupied by Ruxue <==> chensiqihotel [119]= "ruxue" Room 120 is occupied by dandandan <==> chensiqihotel [120]= "dandandan" Room 114 of the hotel has waiwaiwai <==> chensiqihotel [114]= "waiwaiwai"
Example:
[root@chensiqi ~]# awk 'BEGIN{chensiqihotel[110]="xiaoyu";chensiqihotel[119]="ruxue";chensiqihotel[120]="dandan";chensiqihotel[114]="waiwai";print chensiqihotel[110],chensiqihotel[119],chensiqihotel[120],chensiqihotel[114]}'
xiaoyu ruxue dandan waiwai[root@chensiqi ~]# awk 'BEGIN{chensiqihotel[110]="xiaoyu";chensiqihotel[119]="ruxue";chensiqihotel[120]="dandan";chensiqihotel[114]="waiwai";for(hotel in chensiqihotel)print hotel,chensiqihotel[hotel]}'
110 xiaoyu
120 dandan
114 waiwai
119 ruxueEnterprise Interview Question 1: Statistics of Domain Name Visits
Processing the contents of the following documents, taking out the domain name and sorting it according to the number of domain names: (Baidu and sohu interview questions)
http://www.etiantian.org/index.html http://www.etiantian.org/1.html http://post.etiantian.org/index.html http://mp3.etiantian.org/index.html http://www.etiantian.org/3.html http://post.etiantian.org/2.html
Train of thought:
1) Take out the second column (domain name) with the diagonal line as the kitchen knife.
2) Create an array
3) Subscript the second column (domain name) as the array
4) Counting in a form similar to i++.
5) Output the results after statistics
Process demonstration:
Step 1: Take a look at the content
[root@chensiqi ~]# awk -F "[/]+" '{print $2}' file
www.etiantian.org
www.etiantian.org
post.etiantian.org
mp3.etiantian.org
www.etiantian.org
post.etiantian.org
Instructions:
This is what we need to count.Step 2: Counting
[root@chensiqi ~]# awk -F "[/]+" '{i++;print $2,i}' file
www.etiantian.org 1
www.etiantian.org 2
post.etiantian.org 3
mp3.etiantian.org 4
www.etiantian.org 5
post.etiantian.org 6
//Instructions:
i++:i At first it was empty, when awk Read a line. i Oneself+1Step 3: Replace i with an array
[root@chensiqi ~]# awk -F "[/]+" '{h[$2]++;print $2,h["www.etiantian.org"]}' file
www.etiantian.org 1
www.etiantian.org 2
post.etiantian.org 2
mp3.etiantian.org 2
www.etiantian.org 3
post.etiantian.org 3
//Instructions:
1)take i replace with h[$2];It's like I created an array. h[],Then use $2 As my room number. But there is nothing in the room at present. In other words h[$2]=h["www.etiantian.org"] and h["post.etiantian.org"] and h["mp3.etiantian.org"] But there is nothing in the specific room, that is, empty.
2)h[$2]++Equals i++: That is to say, I began to add things to the room; when the same thing appeared, I did.++
3)print h["www.etiantian.org"]:That means I'm starting to export. What I want to output is a room number of ___________“ www.etiantian.org"What's in it? The content here was empty at first, with awk Read each line once the room number appears to be ___________“ www.etiantian.org"When I'm in the room, I give the content to the room.++.
4)To sum up, in the output, each time appears www.etiantian.org At that time, h["www.etiantian.org"]Will++. So the final output number is 3.Step 4: Output the final count result
[root@chensiqi ~]# awk -F "[/]+" '{h[$2]++}END{for(i in h)print i,h[i]}' file
mp3.etiantian.org 1
post.etiantian.org 2
www.etiantian.org 3
[root@chensiqi ~]#
Instructions:
Ultimately, what we need to output is to repeat the later statistical results, so we have to output in the END module.
for (i in h) traverse this array, I has room numbers in it
print i, h[i]: Output each room number and its contents (counting results)Tips:
One of the most important functions of awk applications is counting, and the most important function of arrays in awk is to repeat. Please understand it carefully and try it more.