This paper only introduces the multi-classification process and some minor problems encountered in it. The accuracy rate has been relatively low and the efficiency is relatively low. It is only a simple explanation of the process.
1. Loading VOC datasets
There are many blogs that load data sets on the Internet. Here we just mention a simple idea. First, we observe VOC data sets. Under the Main folder of ImageSets, we have classified all the pictures. Each kind of picture is saved in the txt file under the corresponding name. We need to read the picture code and find the corresponding picture in the JPEImages folder, whose label is the name of the TXT folder, which can be converted to the corresponding number instead.
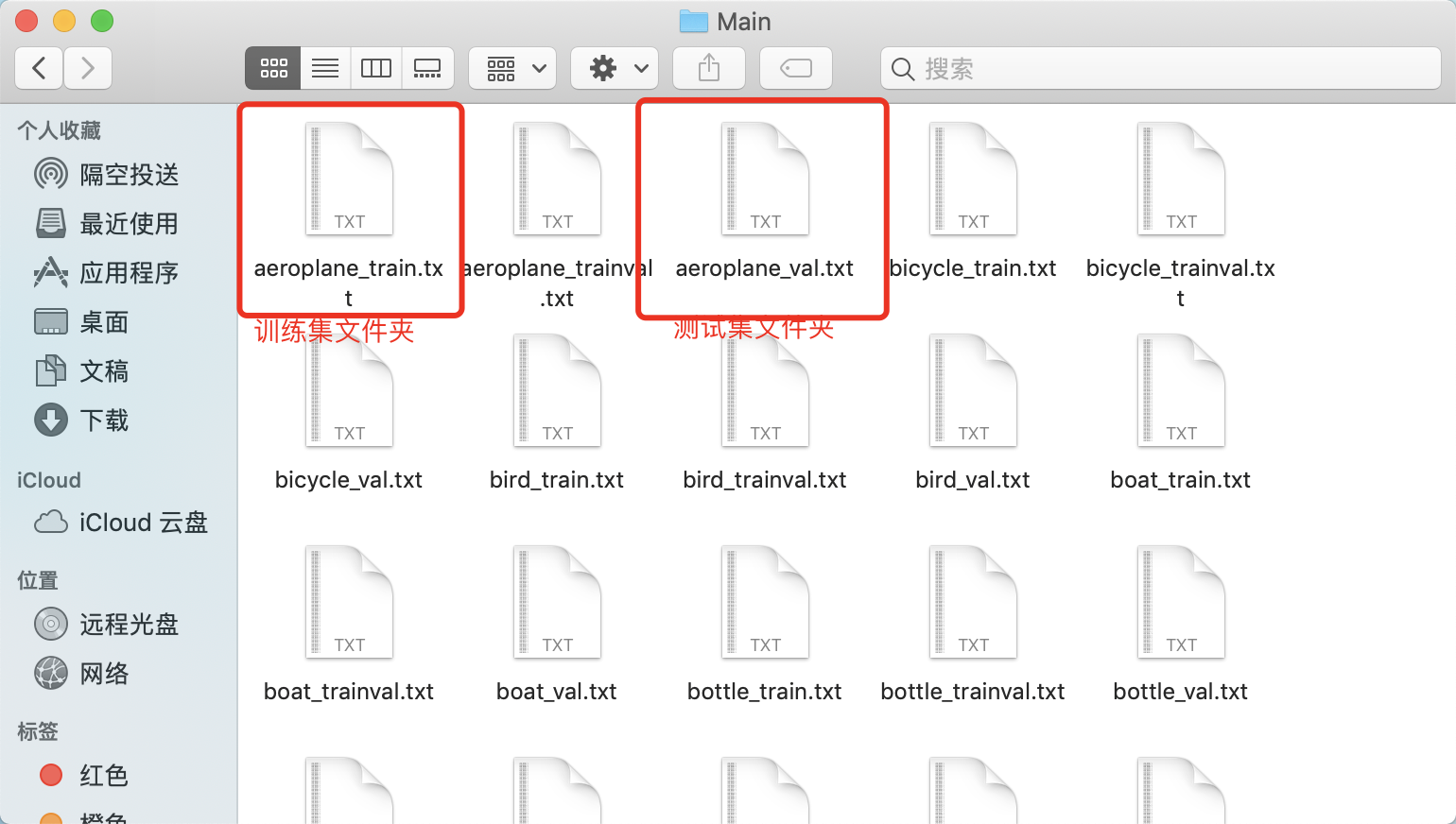
The training set folder corresponds to the training set data, and the test set folder corresponds to the test set data. First, we need to read all the txt files under the Main folder, find out to remove the trainval with the string, then open, save all the image paths, and save the corresponding labels.
Code implementation:
dic_path = './VOCdevkit/VOC2012/ImageSets/Main'
object_categories = ['aeroplane', 'bicycle', 'bird', 'boat',
'bottle', 'bus', 'car', 'cat', 'chair',
'cow', 'diningtable', 'dog', 'horse',
'motorbike', 'person', 'pottedplant',
'sheep', 'sofa', 'train', 'tvmonitor']
train_all = []
val_all = []
def read_all():
files = os.listdir(dic_path)
for fi in files:
if('trainval' not in fi):
num = long(1)
for i,str in enumerate(object_categories,long(1)):
if (str in fi):
num = i
break
if('train' in fi):
f = open(dic_path+"/"+fi)
iter_f = iter(f)
for line in iter_f:
line = line[0:11]
train_all.append([line,num])
else:
f = open(dic_path+"/"+fi)
iter_f = iter(f)
for line in iter_f:
line = line[0:11]
val_all.append([line,num])
read_all()
It is important to note that when slicing, the first 11 characters are selected as the path of the image, and no mistakes will occur as follows:
cv2.error: OpenCV(4.1.0) /io/opencv/modules/imgproc/src/resize.cpp:3718: error: (-215:Assertion failed) !ssize.empty() in function 'resize'
This error is that there is a problem with the path when taking the picture. We need to pay attention to whether the path is correct.
At this point val_all, train_all stores the path and label of the data set.
Then the picture is read and saved in the form of torch.Tensor. Here you need to write a data loading class, inherit from the base class data.Dataset, and implement the len(),getitem() function of the base class. len returns the data set length. getitem usually returns the picture and label.
Code implementation:
class Data(data.Dataset):
def __init__(self,li,transform=None,size=(224,224)):
self.transform = transform
self.size = size
self.img = []
self.lab = []
for i in li:
self.img.append(i[0])
self.lab.append(int(i[1]))
def __getitem__(self, index):
img_path = './VOCdevkit/VOC2012/JPEGImages/'+self.img[index]+'.jpg'
# print (img_path)
image = cv2.imread(img_path)
image = cv2.resize(image,self.size)
image = self.transform(image)
label = torch.LongTensor([self.lab[index]])
return image,label
def __len__(self):
return len(self.img)2. Loading into the form of DataLoader
Read data in the form of DataLoader, call torch.utils.DataLoader function, parameters are dataset,batch_size,shuffle,num_workers, respectively, data sets, the number of images loaded at a time, whether random, the number of threads.
trainset = Data(train_all,transform) train_loader = data.DataLoader(trainset,batch_size=40,shuffle=True,num_workers=0) valset = Data(val_all,transform) val_loader = data.DataLoader(valset,batch_size=40,shuffle=True,num_workers=0)
3. Define Model for Training
Here the Model uses VGG16, I Xiaobai, the choice of Model and design there are many unknown places, here is simply written a Model to verify whether the data is read, and understand the general process of image classification.
It should be noted that because pascalvoc has 20 classifications, the final output layer has 20 output values, and the subscript corresponding to the maximum value is taken as the prediction label, and finally compared with the correct label obtained.
class Net(nn.Module):
def __init__(self):
super(Net,self).__init__()
self.conv1 = nn.Conv2d(3,64,3,padding=1)
self.conv2 = nn.Conv2d(64,64,3,padding=1)
self.pool1 = nn.MaxPool2d(2, 2)
self.bn1 = nn.BatchNorm2d(64)
self.relu1 = nn.ReLU()
self.conv3 = nn.Conv2d(64,128,3,padding=1)
self.conv4 = nn.Conv2d(128, 128, 3,padding=1)
self.pool2 = nn.MaxPool2d(2, 2, padding=1)
self.bn2 = nn.BatchNorm2d(128)
self.relu2 = nn.ReLU()
self.conv5 = nn.Conv2d(128,128, 3,padding=1)
self.conv6 = nn.Conv2d(128, 128, 3,padding=1)
self.conv7 = nn.Conv2d(128, 128, 1,padding=1)
self.pool3 = nn.MaxPool2d(2, 2, padding=1)
self.bn3 = nn.BatchNorm2d(128)
self.relu3 = nn.ReLU()
self.conv8 = nn.Conv2d(128, 256, 3,padding=1)
self.conv9 = nn.Conv2d(256, 256, 3, padding=1)
self.conv10 = nn.Conv2d(256, 256, 1, padding=1)
self.pool4 = nn.MaxPool2d(2, 2, padding=1)
self.bn4 = nn.BatchNorm2d(256)
self.relu4 = nn.ReLU()
self.conv11 = nn.Conv2d(256, 512, 3, padding=1)
self.conv12 = nn.Conv2d(512, 512, 3, padding=1)
self.conv13 = nn.Conv2d(512, 512, 1, padding=1)
self.pool5 = nn.MaxPool2d(2, 2, padding=1)
self.bn5 = nn.BatchNorm2d(512)
self.relu5 = nn.ReLU()
self.fc14 = nn.Linear(512*10*10,1024)
self.drop1 = nn.Dropout2d()
self.fc15 = nn.Linear(1024,1024)
self.drop2 = nn.Dropout2d()
self.fc16 = nn.Linear(1024,20)
def forward(self,x):
x = self.conv1(x)
x = self.conv2(x)
x = self.pool1(x)
x = self.bn1(x)
x = self.relu1(x)
x = self.conv3(x)
x = self.conv4(x)
x = self.pool2(x)
x = self.bn2(x)
x = self.relu2(x)
x = self.conv5(x)
x = self.conv6(x)
x = self.conv7(x)
x = self.pool3(x)
x = self.bn3(x)
x = self.relu3(x)
x = self.conv8(x)
x = self.conv9(x)
x = self.conv10(x)
x = self.pool4(x)
x = self.bn4(x)
x = self.relu4(x)
x = self.conv11(x)
x = self.conv12(x)
x = self.conv13(x)
x = self.pool5(x)
x = self.bn5(x)
x = self.relu5(x)
# print(" x shape ",x.size())
x = x.view(-1,512*10*10)
x = F.relu(self.fc14(x))
x = self.drop1(x)
x = F.relu(self.fc15(x))
x = self.drop2(x)
x = self.fc16(x)
return x
def working(self,device):
path = 'test_train.tar'
opt = optim.SGD(net.parameters(),lr = 0.001,momentum = 0.9)
initepoch = 0
best_val = 0.0
if os.path.exists(path) is not True:
loss = nn.CrossEntropyLoss()
else:
checkpoint = torch.load(path)
self.load_state_dict(checkpoint['model_state_dict'])
opt.load_state_dict(checkpoint['opt_state_dict'])
initepoch = checkpoint['epoch']
loss = checkpoint['loss']
for epoch in range(initepoch,100):
running_loss = 0.0
# temp = self.test(device)
# best_val = max(best_val,temp)
totall = 0
right = 0
for i,data in enumerate(train_loader,0):
inputs,labels = data
inputs,labels = Variable(inputs.to(device)),Variable(labels.to(device))
opt.zero_grad()
outputs = net(inputs.to(device))
_, predicted = torch.max(outputs, 1)
totall += labels.size(0)
right += (predicted == labels).sum()
l = loss(outputs,labels.squeeze())
l.backward()
opt.step()
running_loss += l.data.item()
if i % 100 == 99:
print('[%d, %5d] : %.3f' %
(epoch + 1, i + 1, 100*right/100))
running_loss = 0.0
torch.save({'epoch':epoch,
'model_state_dict':net.state_dict(),
'opt_state_dict':opt.state_dict(),
'loss':loss
},path)
print(best_val)
def test(self,device):
correct = 0
total = 0
with torch.no_grad():
for data in val_loader:
images, labels = data
images = images.to(device)
labels = labels.to(device)
outputs = net(Variable(images.to(device)))
_,lis = torch.max(outputs,1)
# print (outputs)
total += labels.size(0)
# print (labels.shape)
# print (outputs)
# print (type(lis))
# print (type(labels))
correct += (lis == labels).sum()
print('Accuracy of the network on the 10000 test images: %d %%' % (
100 * correct / total))
return 100*correct/total
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
net = Net()
net.to(device)
net.working(device)
net.test(device)
Design epoch and num_workers, input and output with full connection layer, and finally the code can run. But the speed is very slow and the correct rate is very low. The key of this article is to understand the process, so these details will be solved later.
4. last
Due to the limited level, there will certainly be a variety of errors. Please also criticize and correct them.