For the most part, I've recently learned about NLTK for the first time, so I'd like to learn the following code
nltk.tokenize import sent_tokenize
mytext = "Hello Mr. Adam, how are you? I hope everything is going well. Today is a good day, see you dude."
sent_tokenize(mytext)
An error has been reported.
Resource punkt not found.
Please use the NLTK Downloader to obtain the resource:
import nltk
nltk.download('punkt')
But it actually exists.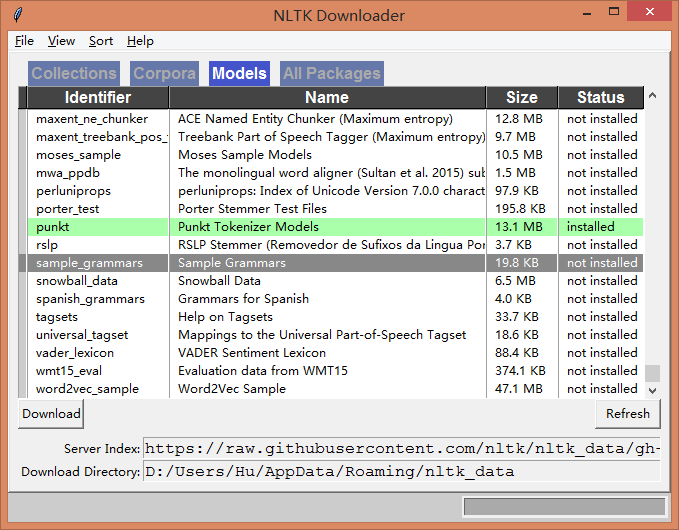
Look carefully.
In the error, Search is on disk C: Users Hu/nltk_data
Searched in:
- 'C:\Users\Hu/nltk_data'
- 'D:\ProgramData\Miniconda3\envs\tensorflow\nltk_data'
- 'D:\ProgramData\Miniconda3\envs\tensorflow\share\nltk_data'
- 'D:\ProgramData\Miniconda3\envs\tensorflow\lib\nltk_data'
- 'C:\Users\Hu\AppData\Roaming\nltk_data'
- 'C:\nltk_data'
- 'D:\nltk_data'
- 'E:\nltk_data'
- ''
See the source code
tokenizer=load('tokenizers/punkt/{0}.pickle'.format(language))
Look at the data load ed from nltk
def load(
resource_url,
format='auto',
cache=True,
verbose=False,
logic_parser=None,
fstruct_reader=None,
encoding=None,
From here, my first reaction was resource_url, so I quickly found the following
resource_url = normalize_resource_url(resource_url)
resource_url = add_py3_data(resource_url)
First you see the shielded instructions windows = sys.platform.startswith('win')
So I found the foreword.
path += [
os.path.join(sys.prefix, str('nltk_data')),
os.path.join(sys.prefix, str('share'), str('nltk_data')),
os.path.join(sys.prefix, str('lib'), str('nltk_data')),
os.path.join(os.environ.get(str('APPDATA'), str('C:\')), str('nltk_data')),
str(r'C:\nltk_data'),
str(r'D:\nltk_data'),
str(r'E:\nltk_data'),
So I changed nltk. data. path = ['D: Users / Hu / AppData / Roaming / nltk_data']
OK Runs Successfully
['Hello Mr. Adam, how are you?', 'I hope everything is going well.', 'Today is a good day, see you dude.']
Process finished with exit code 0