1.time module
import time
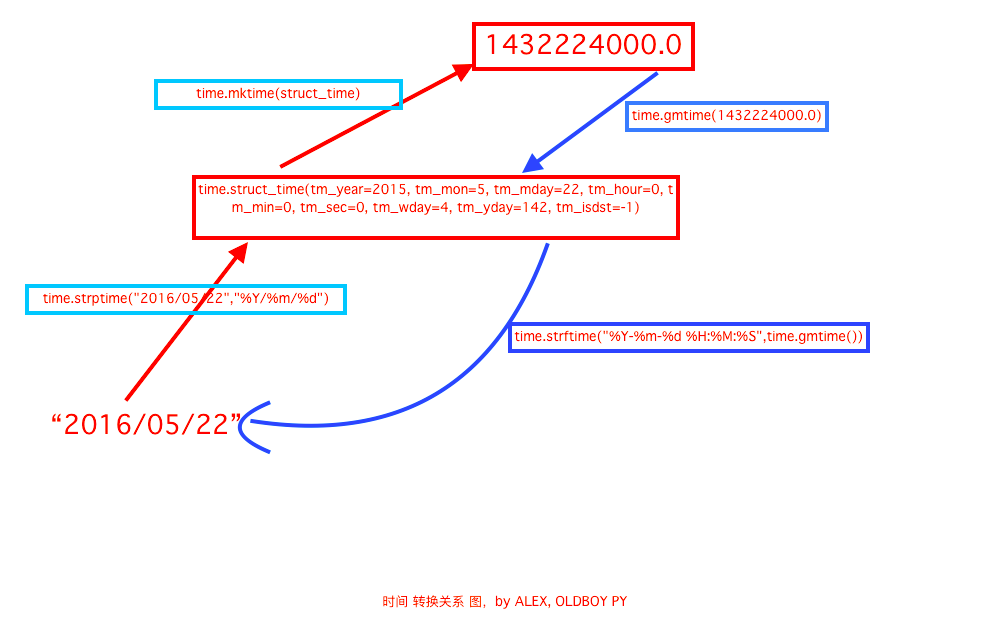
s = time.localtime() # Convert the time into the formatted time, and obtain the struct time format such as mm / DD / yyyy through
time.struct_time(tm_year=2018, tm_mon=3, tm_mday=11, tm_hour=19, tm_min=53, tm_sec=31, tm_wday=6, tm_yday=70, tm_isdst=0)
s=time.gmtime() #UTC time zone
s=time.time() # Returns the current timestamp
print(time.asctime()) #Receive struct_time and convert to Sun Mar 11 19:46:08 2018 do not transmit the default current time
print(time.ctime(0)) #Return to current time Sun Mar 11 19:46:08 2018 default current time
//When a number in time stamp format is passed in, it will be converted to time stamp date Thu Jan 1 08:00:00 1970
print(time.strftime("%Y-%m-%d", time.localtime())) # The time format of struct_time format is passed in and converted to the time format defined by itself
print(time.strptime("2017-12-12", "%Y-%m-%d")) # Convert string format to struct_time format
2.datetime module
import datetime
s=datetime.datetime.now() #(2018-03-11 20:19:10.993661)
s There are many ways year mouth day date()=2018-03-11 ctime()=Sun Mar 11 19:46:08 2018 strftime("%Y-%m-%d")
print(datetime.date.fromtimestamp(time.time())) # Convert a timestamp to March 11, 2018
# ############
# Mainly time operation
s = datetime.datetime.now()
print(s.timetuple()) # time.struct_time(tm_year=2018, tm_mon=3, tm_mday=11, tm_hour=20,
# tm_min=19, tm_sec=9, tm_wday=6, tm_yday=70, tm_isdst=-1)
print(s + datetime.timedelta(seconds=1)) # The function of implementing operation is followed by day hours seconds
d = datetime.datetime.now()
t = d.replace(year=2016) #Modify time and return the modified time. The modified time remains the same
print(t)
3. Use of random module
import random print(random.randint(1, 200)) # Randomly generated numbers between 1-200 include 200 print(random.randrange(1, 200, 2)) # Randomly generated 1-200 (even) does not contain 200 print(random.random()) # Decimal of 0-1 print(random.choice("dasdadsasdad")) # Randomly pick characters of a string print(random.sample("adasdasdasdad",5)) #Randomly select 5 characters in a string to make a list #Implementation verification code import string print(string.ascii_letters) #Case contains print(string.hexdigits) #Hexadecimal print(string.digits)#Decimal system s_list=random.sample(string.ascii_letters + string.digits,4) s=''.join(s_list) print(s)list_all=[i for i in range(80)] # # a='dasdasdasd' #Cannot be a string # random.shuffle(list_all) # Reshuffle to take effect in the original list # print(list_all)
The os module provides many functions that allow your program to interact directly with the operating system
# The os module provides many functions that allow your program to interact directly with the operating system
import os
BASE_DIR = os.path.abspath(__file__) # Return the data pair path of the file
os.listdir(".") # List directories under the specified folder
os.path.join('aaa', 'aaa') # Splicing paths
os.path.dirname(BASE_DIR) # Return directory path does not contain files
os.path.split(BASE_DIR) # Returns a list of file names and paths
os.path.exists(BASE_DIR) # Determine whether path exists
os.path.isfile(BASE_DIR) # Judge whether the file exists
os.path.isdir(BASE_DIR) # Determine whether it is a directory
os.path.splitext(BASE_DIR)
os.path.basename(BASE_DIR) # Get file name
os.path.getsize(BASE_DIR) # Get file size
5. Use of sys module
sys.argv Command line arguments List,The first element is the path of the program itself
sys.exit(n) Exit program, normal exit exit(0)
sys.version Obtain Python Interpreter version information
sys.maxint Maximal Int value
sys.path Returns the search path of the module, which is used during initialization PYTHONPATH Value of environment variable
sys.platform Return operating system platform name
sys.stdout.write('please:') #Standard output, which leads to the example of progress bar. Note, it's not good on py3. You can use print instead
val = sys.stdin.readline()[:-1] #Standard input
sys.getrecursionlimit() #Get the maximum recursion level
sys.setrecursionlimit(1200) #Set maximum recursion level
sys.getdefaultencoding() #Get interpreter default encoding
sys.getfilesystemencoding #Get the default encoding of memory data stored in the file
JSON & pickle module the module of serialization and deserialization of python, which is used for the interaction between programs.
The point of json is that it is supported across platforms and different languages. There are not many str int list tuple dict types
json.loads() can be transferred to the string json. Load() json. Dumps() json. Dump() by json's file type json
pickle can only use data types supporting python in python, which takes up a large volume
import json
import pickle
# The point of json is that it is supported across platforms and different languages. There are not many str int list tuple dict types
# json.loads() can be transferred to the string json. Load() json. Dumps() json. Dump() by json's file type json
# pickle can only use data types supporting python in python, which takes up a large volume
d = {1: 2, 3: 4}
l = ["name", "age"]
s = json.dumps(d) # Convert dictionary and other formats into strings
print(s)
d1 = json.loads(s) # Convert string to dictionary form
print(d1)
f = open("test.json", 'w') # Convert the existing files in the form of dictionaries into strings into characters
json.dump(d, f)
f.close()
f = open("test.json", 'r') # Read it from the file and convert it to a string
d2 = json.load(f)
# Pickle is also in this form. Only when uploading, the file is saved in the form of pickle
shutil module is used for file copy and compression, mainly used for file packaging, moving, and other functions.
import shutil
# Copy a file if the file must be opened and the handle is passed
shutil.copyfileobj(open("Log.py", "r"), open("Log_new.py", "w"))
# Copy file encapsulates open file only need to transfer file name (not directory name)
shutil.copyfile("Log.py", "log_new.py")
shutil.copymode("Log.py", "lll.py") # Copy permission only, target file must exist
shutil.copy("Log.py", "lll.py") # Copy files and permissions
shutil.copy2("Log.py", "lll.py") # Copy files and status
# Copy directory must be a directory
shutil.copytree("../FTP", "ftp", ignore=shutil.ignore_patterns("__init__.py"))
# Recursive copy file, with a file ignored by the parameter ignore = shutil.ignore ﹐ patterns ("﹐ init ﹐ py")
shutil.rmtree("log_new.y") # No way to delete the catalog file
shutil.move("log_new.y", "ll.py") # Move files, or rename
shutil.make_archive(base_name="log_l", format="zip", root_dir="../FTP") # Compressed file
# Base "name specifies the path of compression followed by the name of compression file, format = compression format" zip "," tar "," bztar "," gztar "
# Root? The path (directory) of the file to be compressed owner user name group group name
Module xlrd, the module to read excel table xlrd external module needs pip installation and can only read excle
For other Excel write modification modules, please go to http://blog.csdn.net/yankaiwei120/article/details/52204427
import xlrd
# The module of parsing xls table file write xlwd with xlrd
Book = xlrd.open_workbook(r"C:\Users\zhuangjie23261\Desktop\Wind control document.xls") # Open file returns a book Object
sheet = Book.sheets() # Returns the objects of the specified sheet to form a list
num = Book.nsheets # Returns the number of sheet s for the file
Book.sheet_by_index(1) # Returns the name of the sheet page for the specified index value
Book.sheet_names() # Returns the names of all sheet pages
Book.sheet_by_name() # Return sheet page object by name
Book.sheet_loaded() # Error is reported when judging whether there is any according to the specified index or name
sheet.name # Returns the name of the sheet
sheet.nrows # Returns the number of rows on the sheet page ----- rows
sheet.ncols # Returns the number of columns in the sheet page
sheet.row(
1) # Get the specified lines to form a cell list [number: 20100805.0, text: 'O32 SP2', text: 'E-type risk control asset category', text: 'add N-offline subscription estimated winning assets (public issuance),' empty:'', text: 'Hu Yudong']
sheet.row_values(1) # List of designated banks [20100805.0, 'O32 SP2', 'type E risk control asset category', 'add N-offline subscription estimated winning assets (public issuance),', ','hu Yudong']
sheet.col(1) # Get the cell list of the specified column
sheet.col_values(1) # list of specified columns
cell = sheet.cell(1, 2) # Gets the Cell object based on the location.
sheet.cell_value(1, 2) # Gets the value of the Cell object based on its location.
print(cell.value) # Get cell value
# Print the first column of each table
for s in sheet:
print(s.name) # Get each sheet page
for i in range(s.nrows): # s.nrows how many lines per sheet page s.row(i) this is a list that returns each line - 1 for the last value for the text value
print(s.row(i)[0].value)
Parsing xml module
xml is a protocol for data exchange between different languages or programs. It's similar to json, but it's easier to use json. In ancient times, in the dark age when json was not born, you can only choose to use xml. Up to now, xml is the main interface of many systems in many traditional companies, such as the financial industry.
import xml.etree.ElementTree as ET
tree = ET.parse("test.xml")
root = tree.getroot()
print(root.tag) # The header of this attribute
for child in root:
print(child.tag, child.attrib) # Attributes in attrib < > form a dictionary
for i in child:
print(i.tag, i.text) # Text content
for year in root.iter("year"): # iter() is equivalent to a filter to filter the attributes in < >
print(year.text)
# *****************************************
# Modify xml
for year in root.iter("year"):
new_year = int(year.text) + 1
year.text = str(new_year) # Format write converted to string
year.set("updated", "yes") # set format type updated yes description update
tree.write("test.xml")
#Deletion of xml nodes
for country in root.findall("country"): # Node is the node that traverses and finds all countries under root
rank = country.find("rank").text # Print text for each rank node found under the country
rank = int(rank) # Convert str to int
if rank < 60:
country.remove(country.find("rank")) # In this way, you can remove the node rank under the country or the large node of the country directly
tree.write("new_test.xml") #Write the generated to a new file
# ***************************************
new_xml = ET.Element("namelist") # Generate the outermost node of the root node of an xml
name = ET.SubElement(new_xml, "name", attrib={"data": "2017-11"}) # Generate a node name under the outermost node
age = ET.SubElement(name, "age") # Regenerate to two nodes under the name node age,sex
sex = ET.SubElement(name, "sex") # sex
age.text = "33"
sex.text = "male"
# Set the number for age to be a character
# Multiple nodes can be added here
name2 = ET.SubElement(new_xml, "name", attrib={"data": "2018-11"}) # Generate a node name under the outermost node
age = ET.SubElement(name2, "age") # Regenerate two nodes under the node name age,sex
sex = ET.SubElement(name2, "sex") # If no text is set, a label is displayed
age.text = "33"
#*********************************************
et = ET.ElementTree(new_xml) # This step is to convert the above set format into xml document
et.write("new_xml.xml", encoding="utf8", xml_declaration=True) # Write to file
ET.dump(new_xml) # Print written file format
configparser reading configuration file and modifying configuration file
import configparser
"""
[DEFAULT]
ServerAliveInterval = 45
Compression = yes
CompressionLevel = 9
ForwardX11 = yes
[bitbucket.org]
User = hg
[topsecret.server.com]
Port = 50022
ForwardX11 = no
***************
[group2]
k1 = v1
[group3]
k1 = v1
"""
# analysis
conf = configparser.ConfigParser()
conf.read("conf_new.ini") # Open profile
sec_list = conf.sections() # Get sections of file ["default"] do not print
s = conf["bitbucket.org"]["User"] # Print the text of User under node section
for v in conf["topsecret.server.com"]:
print(v) # Print the node name under topsecret.server.com and the node under default by default
# query
opt = conf.options("bitbucket.org") # Find the matching key value under the specified node
print(opt)
item = conf.items("bitbucket.org") # Return the ancestor corresponding to key value
print(item)
val = conf.get("bitbucket.org", "compression") # group>[] key>k1:v1
val=conf.getint("topsecret.server.com", "Port") # The value obtained is int
print(val)
# Add and delete
conf.read("conf_new.ini") # Open profile
conf.remove_section("group1") # Delete node group1
conf.add_section("group3") # Add node group3
conf.remove_option("group3", "k1") # Delete option write group [] first and then key
print(conf.has_section("group1")) # Determine if there is this group
conf.set("group3", "k1", "v1") # set configuration
conf.write(open("conf_new.ini", 'w')) # To write a file, it must be an open file. To put it bluntly, it's an incoming file handle