Code in Open source warehouse 3 xxxhttps://github.com/3xxx/engineercms
https://github.com/3xxx/engineercms
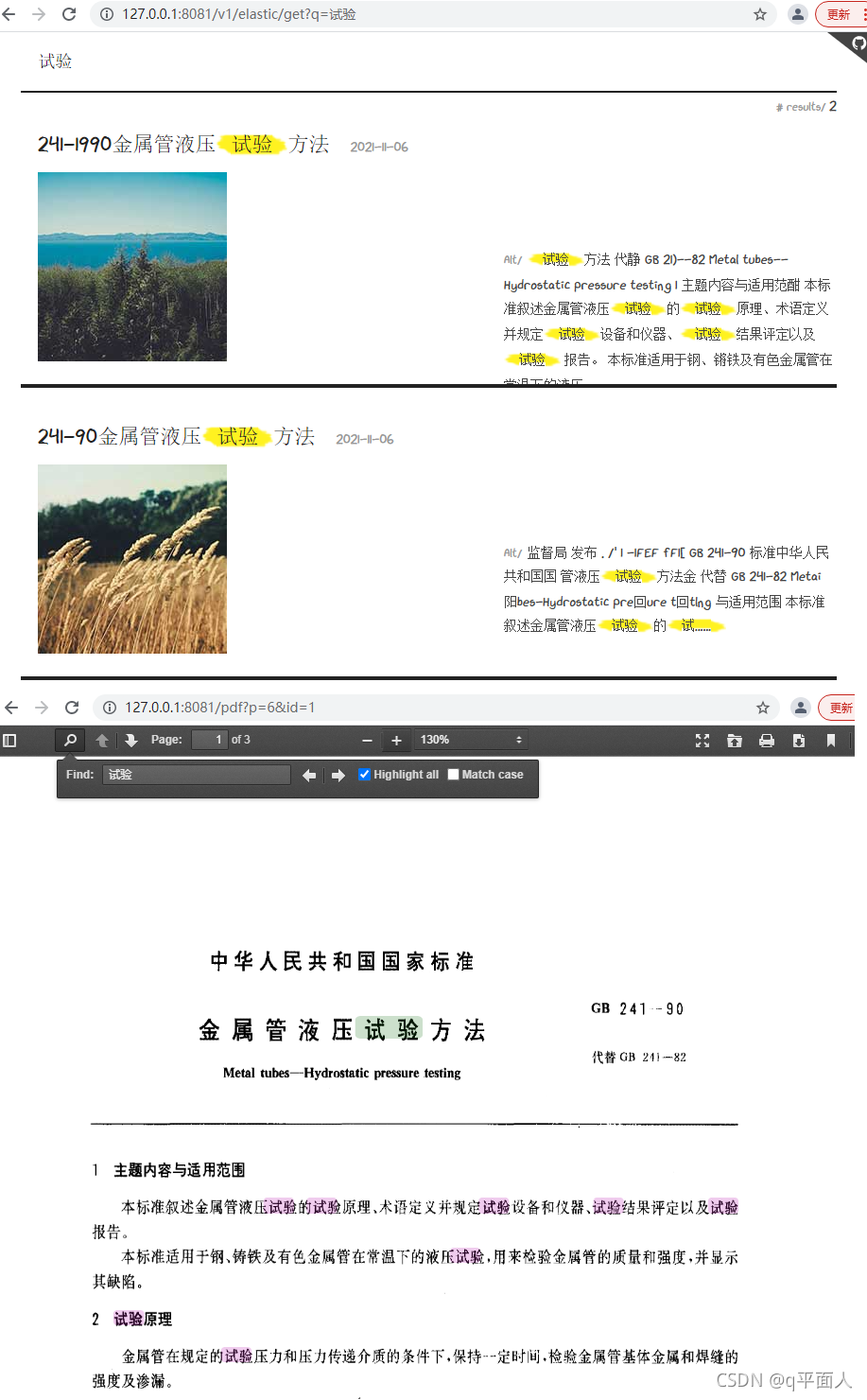
The general idea is to install es and tika services with docker, upload word and other documents in cms, parse them with tika, get plain text, and submit them to es for storage. Front end retrieval, query in ES, return the highlighted text and result list, click to locate the document and open it.
Install the ik plug-in in es and debug it with head, postman or curl.
Because postman is used for the first time, es always returns an error saying that there is a lack of body. The solution is to check the content length in the head
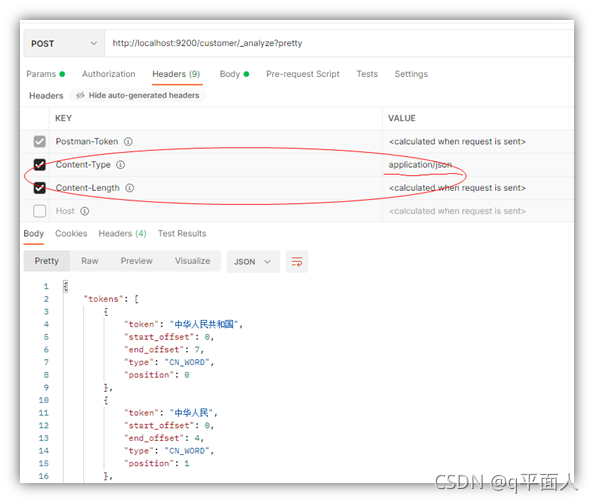
The curl command under win, too, should use double quotation marks, not single quotation marks. The json file should be saved as a text file. Use the @ file name. json in the command. You can't submit it directly with the json file content in the command.
curl -X POST "localhost:9200/customer/_analyze?pretty" -H "Content-Type: application/json" -d@2.json
2.json file content:
{
"analyzer": "ik_max_word",
"text": "National Anthem of the people's Republic of China"
}Chinese word segmentation ik can be put into the plug-in, and the versions correspond to es one by one. Nothing else.
Go elastic serach or Oliver / elastic is required for golang development. What is the difference between them? It is explained in the issue, but it is not very clear. Technology selection is very important and involves future modifications. The former is official and the latter is maintained by the author. The number of star s is twice that of the former, but both are very large.
The former has few tutorials, and only its official example can be learned. This article uses.
tika continues to install with docker. Use go tika to dock.
docker pull apache/tika docker run -d -p 9998:9998 apache/tika:<tag>
What engineercms needs to do is upload, submit and retrieve data structures, return and front-end display
1.tika identification document - extracting text data
f, err := os.Open("./test.pdf")
if err != nil {
log.Fatal(err)
}
defer f.Close()
fmt.Println(f.Name())
client := tika.NewClient(nil, "http://localhost:9998")
body, err := client.Parse(context.Background(), f)
// body, err := client.Detect(context.Background(), f) //application/pdf
// fmt.Println(err)
// fmt.Println(body)
dom, err := goquery.NewDocumentFromReader(strings.NewReader(body))
if err != nil {
log.Fatalln(err)
}
dom.Find("p").Each(func(i int, selection *goquery.Selection) {
if selection.Text() != " " || selection.Text() != "\n" {
fmt.Println(selection.Text())
}
})2.es insert n pieces of data
// example from go elastic search
var (
articles []*Article
countSuccessful uint64
res *esapi.Response
// err error
)
log.Printf(
"\x1b[1mBulkIndexer\x1b[0m: documents [%s] workers [%d] flush [%s]",
humanize.Comma(int64(numItems)), numWorkers, humanize.Bytes(uint64(flushBytes)))
log.Println(strings.Repeat("▁", 65))
// >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
//
// Use a third-party package for implementing the backoff function
//
retryBackoff := backoff.NewExponentialBackOff()
// <<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<
// >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
//
// Create the Elasticsearch client -- 0. Initialize a client
//
// NOTE: For optimal performance, consider using a third-party HTTP transport package.
// See an example in the "benchmarks" folder.
//
es, err := elasticsearch.NewClient(elasticsearch.Config{
// Retry on 429 TooManyRequests statuses
RetryOnStatus: []int{502, 503, 504, 429},
// Configure the backoff function
RetryBackoff: func(i int) time.Duration {
if i == 1 {
retryBackoff.Reset()
}
return retryBackoff.NextBackOff()
},
// Retry up to 5 attempts
MaxRetries: 5,
})
if err != nil {
log.Fatalf("Error creating the client: %s", err)
}
// <<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<
// >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
//
// Create the BulkIndexer -- 1. Create an index, which is equivalent to creating a table in mysql
//
// NOTE: For optimal performance, consider using a third-party JSON decoding package.
// See an example in the "benchmarks" folder.
//
bi, err := esutil.NewBulkIndexer(esutil.BulkIndexerConfig{
Index: indexName, // The default index name
Client: es, // The Elasticsearch client
NumWorkers: numWorkers, // The number of worker goroutines
FlushBytes: int(flushBytes), // The flush threshold in bytes
FlushInterval: 30 * time.Second, // The periodic flush interval
})
if err != nil {
log.Fatalf("Error creating the indexer: %s", err)
}
// <<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<
// Generate the articles collection -- 2. Construct a batch of documents,
//
names := []string{"Alice", "John", "Mary"}
for i := 1; i <= numItems; i++ {
articles = append(articles, &Article{
ID: i,
Title: strings.Join([]string{"Title", strconv.Itoa(i)}, " "),
Body: "Lorem ipsum dolor sit amet...",
Published: time.Now().Round(time.Second).UTC().AddDate(0, 0, i),
Author: Author{
FirstName: names[rand.Intn(len(names))],
LastName: "Smith",
},
})
log.Printf(articles[i-1].Body)
}
log.Printf("→ Generated %s articles", humanize.Comma(int64(len(articles))))
// Re create the index -- the following one first deletes the previously established index, which is actually meaningless
if res, err = es.Indices.Delete([]string{indexName}, es.Indices.Delete.WithIgnoreUnavailable(true)); err != nil || res.IsError() {
log.Fatalf("Cannot delete index: %s", err)
}
res.Body.Close()
res, err = es.Indices.Create(indexName)
if err != nil {
log.Fatalf("Cannot create index: %s", err)
}
if res.IsError() {
log.Fatalf("Cannot create index: %s", res)
}
res.Body.Close()
start := time.Now().UTC()
// Loop over the collection
for _, a := range articles {
// Prepare the data payload: encode article to JSON
//
data, err := json.Marshal(a)
if err != nil {
log.Fatalf("Cannot encode article %d: %s", a.ID, err)
}
log.Printf(string(data))
// >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
//
// Add an item to the BulkIndexer -- 3. Batch add records
//
err = bi.Add(
context.Background(),
esutil.BulkIndexerItem{
// Action field configures the operation to perform (index, create, delete, update)
Action: "index",
// DocumentID is the (optional) document ID
DocumentID: strconv.Itoa(a.ID),
// Body is an `io.Reader` with the payload
Body: bytes.NewReader(data),
// OnSuccess is called for each successful operation
OnSuccess: func(ctx context.Context, item esutil.BulkIndexerItem, res esutil.BulkIndexerResponseItem) {
atomic.AddUint64(&countSuccessful, 1)
},
// OnFailure is called for each failed operation
OnFailure: func(ctx context.Context, item esutil.BulkIndexerItem, res esutil.BulkIndexerResponseItem, err error) {
if err != nil {
log.Printf("ERROR: %s", err)
} else {
log.Printf("ERROR: %s: %s", res.Error.Type, res.Error.Reason)
}
},
},
)
if err != nil {
log.Fatalf("Unexpected error: %s", err)
}
// <<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<
}
// >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
// Close the indexer
//
if err := bi.Close(context.Background()); err != nil {
log.Fatalf("Unexpected error: %s", err)
}
// <<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<
biStats := bi.Stats()
// Report the results: number of indexed docs, number of errors, duration, indexing rate
//
log.Println(strings.Repeat("▔", 65))
dur := time.Since(start)
if biStats.NumFailed > 0 {
log.Fatalf(
"Indexed [%s] documents with [%s] errors in %s (%s docs/sec)",
humanize.Comma(int64(biStats.NumFlushed)),
humanize.Comma(int64(biStats.NumFailed)),
dur.Truncate(time.Millisecond),
humanize.Comma(int64(1000.0/float64(dur/time.Millisecond)*float64(biStats.NumFlushed))),
)
} else {
log.Printf(
"Sucessfuly indexed [%s] documents in %s (%s docs/sec)",
humanize.Comma(int64(biStats.NumFlushed)),
dur.Truncate(time.Millisecond),
humanize.Comma(int64(1000.0/float64(dur/time.Millisecond)*float64(biStats.NumFlushed))),
)
}3. Query
// Also from example
// 3. Search for the indexed documents
// Build the request body. - 1. Construct a query structure first
var buf bytes.Buffer
query := map[string]interface{}{
"query": map[string]interface{}{
"match": map[string]interface{}{
// "title": "Title 10",
"author.first_name": "John",
},
},
}
// query := map[string]interface{}{
// "query": map[string]interface{}{
// "match_all": map[string]interface{}{},
// },
// }
if err := json.NewEncoder(&buf).Encode(query); err != nil {
log.Fatalf("Error encoding query: %s", err)
}
// Perform the search request. - 2. Query statement
res, err := es.Search(
es.Search.WithContext(context.Background()),
es.Search.WithIndex(indexName), // default indexname
es.Search.WithBody(&buf),
es.Search.WithTrackTotalHits(true),
es.Search.WithPretty(),
)
// const searchAll = `
// "query" : { "match_all" : {} },
// "size" : 25,
// "sort" : { "published" : "desc", "_doc" : "asc" }`
// var b strings.Builder
// b.WriteString("{\n")
// b.WriteString(searchAll)
// b.WriteString("\n}")
// strings.NewReader(b.String())
// res, err = es.Search(
// es.Search.WithIndex("test-bulk-example"),
// es.Search.WithBody(strings.NewReader(b.String())),
// // es.Search.WithQuery("{{{one OR two"), // <-- Uncomment to trigger error response
// )
if err != nil {
log.Fatalf("Error getting response: %s", err)
}
defer res.Body.Close()
log.Printf(res.String())// Print query results
if res.IsError() {
var e map[string]interface{}
if err := json.NewDecoder(res.Body).Decode(&e); err != nil {
log.Fatalf("Error parsing the response body: %s", err)
} else {
// Print the response status and error information.
log.Fatalf("[%s] %s: %s",
res.Status(),
e["error"].(map[string]interface{})["type"],
e["error"].(map[string]interface{})["reason"],
)
}
}
var r map[string]interface{}
if err := json.NewDecoder(res.Body).Decode(&r); err != nil {
log.Fatalf("Error parsing the response body: %s", err)
}
// Print the response status, number of results, and request duration.
log.Printf(
"[%s] %d hits; took: %dms",
res.Status(),
int(r["hits"].(map[string]interface{})["total"].(map[string]interface{})["value"].(float64)),
int(r["took"].(float64)),
)
// Print the ID and document source for each hit.
for _, hit := range r["hits"].(map[string]interface{})["hits"].([]interface{}) {
log.Printf(" * ID=%s, %s", hit.(map[string]interface{})["_id"], hit.(map[string]interface{})["_source"])
}
log.Println(strings.Repeat("=", 37))The query output results are as follows: "author.first_name": "John",
[200 OK] 4 hits; took: 1ms * ID=2, map[author:map[first_name:John last_name:Smith] body:Lorem ipsum dolor sit amet... id:%!s(float64=2) published:2021-10-29T11:34:32Z title:Title 2] * ID=3, map[author:map[first_name:John last_name:Smith] body:Lorem ipsum dolor sit amet... id:%!s(float64=3) published:2021-10-30T11:34:32Z title:Title 3] * ID=7, map[author:map[first_name:John last_name:Smith] body:Lorem ipsum dolor sit amet... id:%!s(float64=7) published:2021-11-03T11:34:32Z title:Title 7] * ID=8, map[author:map[first_name:John last_name:Smith] body:Lorem ipsum dolor sit amet... id:%!s(float64=8) published:2021-11-04T11:34:32Z title:Title 8
During debugging, as in the above code, delete the old index first, then create a new index, and then insert the data. Pit: I put these in a piece of code, delete the index, create a new index, insert data, and query immediately. I can't get the result all the time. Because there's no time to find the data.
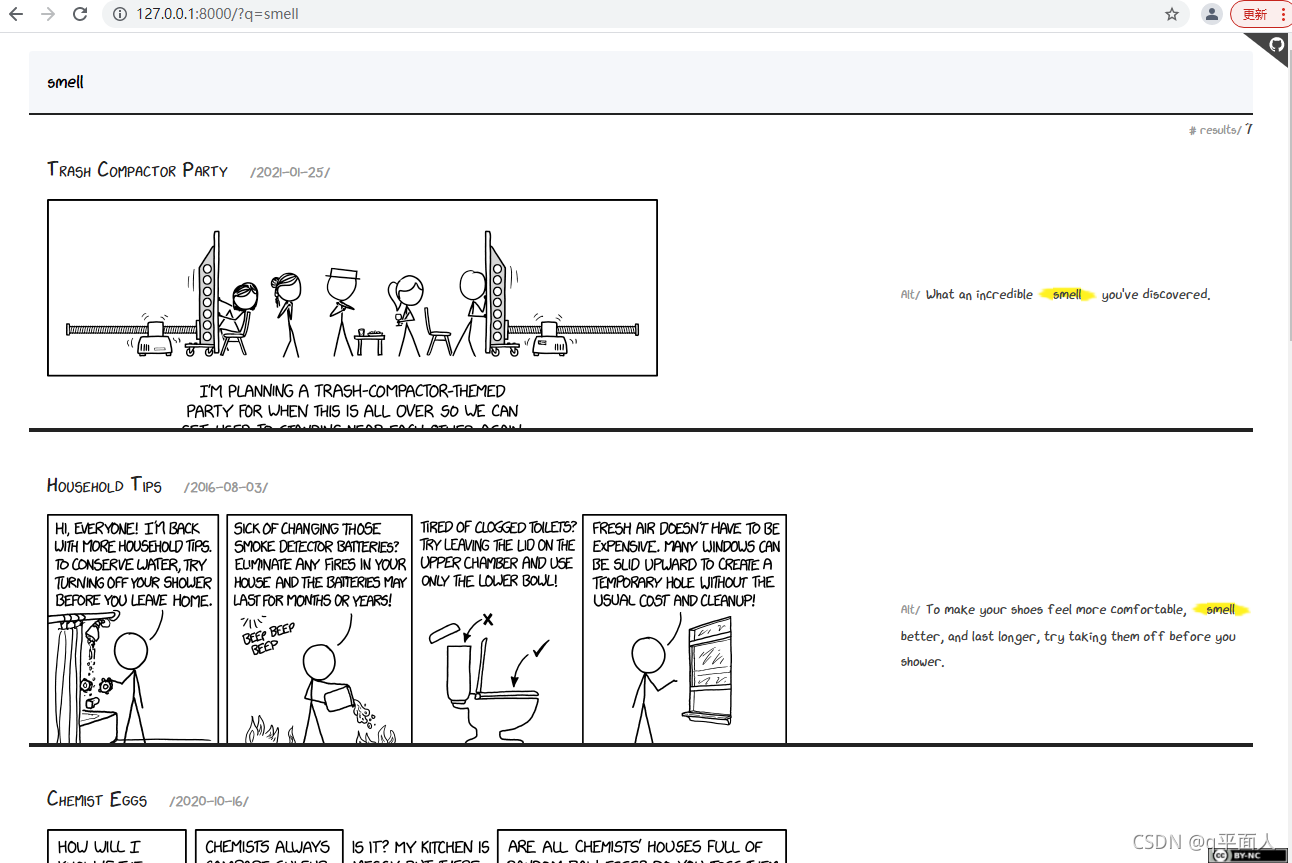
The following is the running effect of the xkcdsearch example in example.
The following is the full-text retrieval effect of the electronic specification of engineercms:
Through full-text retrieval, locate the specific specification, open the specification, and search for keywords again.