Data description
Data parameters
OrderNumber: customer nickname
LineNumber: purchase order. For example, the first three lines respectively represent three goods purchased by the same customer
Model: trade name
Problem description
Application of intelligent algorithm recommendation of association rules based on shopping basket.
Three basic questions:
1. How to push products with the goal of obtaining the highest marketing response rate?
2. How to recommend products with the goal of maximizing overall sales
3. Users do not generate consumption and recommend a product for them?
There are many kinds of intelligent recommendation algorithms. This paper only practices association rules.
This paper will focus on the most easily understood and classic shopping basket recommendation based on association rules. The correlation analysis of commodities is of great help to improve the vitality of commodities, tap consumers' purchasing power and promote maximum sales.
The modeling idea is that the mode that goods are purchased at the same time reflects the demand mode of customers.
Applicable scenarios: scenarios without personalized customization; Recommend products with sales records to old customers; Package design and product placement.
Shopping basket introduction
Q: what is a shopping basket? What are the main scenarios?
A: the combination of goods purchased by a single customer at one time is called a shopping basket, that is, the consumption ticket of a customer this time. Common scenarios: supermarket shelf layout: complementary products and mutually exclusive products; Package design.
Q: what are the common algorithms for shopping baskets?
A: common algorithms are
Do not consider shopping order: association rules. Shopping basket analysis is actually a causal analysis. Association rules are actually a very convenient algorithm to find the relationship between two commodities. The relationship of common promotion means that the two are positively correlated and can be used as complementary products. For example, selling bean paste and onion together is the best. The concept of substitute is that if I buy this, I don't have to buy another one.
Consider shopping order: sequential model. It is mostly used in e-commerce. For example, if you add this commodity to the shopping cart today and another commodity to the shopping cart a few days later, there will be a sequence. However, many physical stores cannot record the consumption order of users because they do not have real name authentication.
Q: what is the use of finding complementary and mutually exclusive products for layout?
A: after the association relationship between commodities is calculated according to the association rules, it may be found that there are three relationships among commodities: strong association, weak association and exclusion. Each model has its own layout.
Strong correlation: the value of correlation degree depends on the actual situation. In different industries, different formats are also different. The display of strongly related goods together will increase the sales volume of both sides. If the display position allows, the two-way related goods should be displayed in association, that is, there is B next to product A, and there must be A next to product B, such as common shaving cream and razor, men's hair oil and styling comb; For those one-way related commodities, only the related commodities need to be displayed next to the related commodities. For example, there is A paper cup next to the large coke, but there is no large coke next to the paper cup. After all, the consumers who buy the large coke probably need the paper cup, and the customers who buy the paper cup have little chance to buy the large coke.
Weak correlation: goods with low correlation can be placed together, and then analyze whether the correlation has changed. If the correlation has increased significantly, it indicates that the original weak correlation may be caused by display.
Exclusion relationship: it means that two products will not appear in the same shopping ticket, and such products should not be displayed together as far as possible.
The analysis of commodity relevance based on the information of shopping basket is not only the above three relationships, but also represents one aspect of commodity relevance analysis (reliability). Comprehensive and systematic commodity correlation analysis must have the concept of three degrees, including support, reliability and promotion.
Association rules
It will be difficult to understand directly according to the concept defined by the third degree of relevance, especially the problem of "who to whom" in the degree of credibility improvement. In fact, you can look at it in another way:
Support of rule x = number of transactions of rule X / total number of transactions. Understanding: support indicates whether rule x is universal.
Confidence of rule X(A → B) = number of transactions of rule X / number of transactions of commodity B in rule X. Understanding: confidence is A conditional probability, which indicates the probability that A customer who has purchased product A will purchase product B.
Q: is it reliable to just look at the support and confidence?
A: let's take a look at a case: the canteen sells rice. In the 1000 rice beating records, 800 people buy rice, 600 people buy beef, and 400 people buy together. Then we can get the rule (beef - > rice) support = P (beef & rice) = 400 / 1000 = 0.40; Confidence = P (rice | beef) = 400 / 600 = 0.67, with high confidence and support, but is it meaningful to recommend rice to beef buyers? Obviously, it doesn't make any sense. Because the probability of users buying rice without any conditions: P (rice) = 800 / 1000 = 0.8, which is 0.67 higher than the probability of buying rice on the premise of buying beef. After all, rice is better than beef.
This case leads to the concept of lifting degree: lifting degree = confidence / unconditional probability = 0.67/0.8. When the promotion degree of rule X(A → B) is n: if B is recommended to the customer who purchased A, the probability that the customer will buy B is n that TA will naturally buy B × About 100%. Life understanding: consumers seldom buy corner anti-collision sponges alone. They may think of buying them occasionally or when their children encounter them. If we add the recommendation of corner anti-collision sponges on the successful order page of the table (desk and dining table), it can greatly improve the sales of anti-collision sponges. This is also in line with our purpose of driving relatively non selling goods through selling goods.
Q: in addition to the meaning of the formula, is there any correlation between the three degrees of correlation (support, confidence and promotion)?
A: it can be understood as follows:
Support represents whether the share of this group of related products is large enough
Confidence (confidence) represents the strength of correlation
The promotion degree depends on whether the association rule has utilization value and is worthy of promotion, and how much more it is used (recommended by the customer after purchase) than useless (purchased naturally by the customer).
Therefore, 1.0 is a cut-off value for the improvement degree. In the case of buying rice just now, it is not difficult to understand that the improvement degree of the operation of recommending rice to users who bought beef is less than 1. In addition, two products with high confidence (assuming 100%, it means they always appear in pairs), but if the support is very low (it means low share), it will not help the overall sales improvement much.
Association rules Python code
Import base package
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
# Various details such as image size, axis label, scale, text size, legend text, etc
large = 22; med = 16; small = 12
params = {'axes.titlesize': large,
'legend.fontsize': med,
'figure.figsize': (16, 10),
'axes.labelsize': med,
'axes.titlesize': med,
'xtick.labelsize': med,
'ytick.labelsize': med,
'figure.titlesize': large}
plt.rcParams.update(params)
plt.style.use('seaborn-whitegrid')
sns.set_style("white")
plt.rc('font', **{'family': 'Microsoft YaHei, SimHei'}) # Set support for Chinese Fonts
# sns.set(font='SimHei') # Solve the problem of Seaborn Chinese display, but the background gray grid will be automatically added
plt.rcParams['axes.unicode_minus'] = False
# Solve the problem that the negative sign '-' is displayed as a square in the saved image
Data overview
#If utf-8 is used to read a file, decoding errors will occur, which needs to be changed to gbk decoding
bike=pd.read_csv("C://Python / / share materials 3//bike_data.csv",encoding='gbk')
print(bike.head())
print(bike.info())
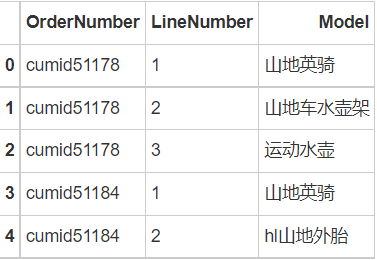
OrderNumber: customer nickname
LineNumber: purchase order. For example, the first three lines respectively represent three goods purchased by the same customer
Model: trade name
Exploratory data analysis EDA
#View missing values print(bike.isnull().sum()) #View duplicate values print(bike.duplicated().sum())
Exploration of commodity types
model=bike['Model'].nunique()
modelnames=bike['Model'].unique()
print("share"+str(model)+"Kinds of goods\n")
print("The trade names are:\n")
#5 per line
for i in range(0,len(modelnames),5):
print(modelnames[i:i+5])

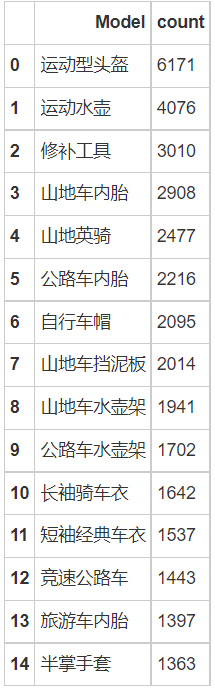
#Top 15 items
bestseller = bike.groupby('Model')['Model'].count().sort_values(ascending=False).reset_index(name='count')
bestseller.head(15)
top_15 = bestseller.head(15)
sns.barplot(x='count',y='Model',data=top_15)
plt.title('Top 15 items')
plt.grid(True)
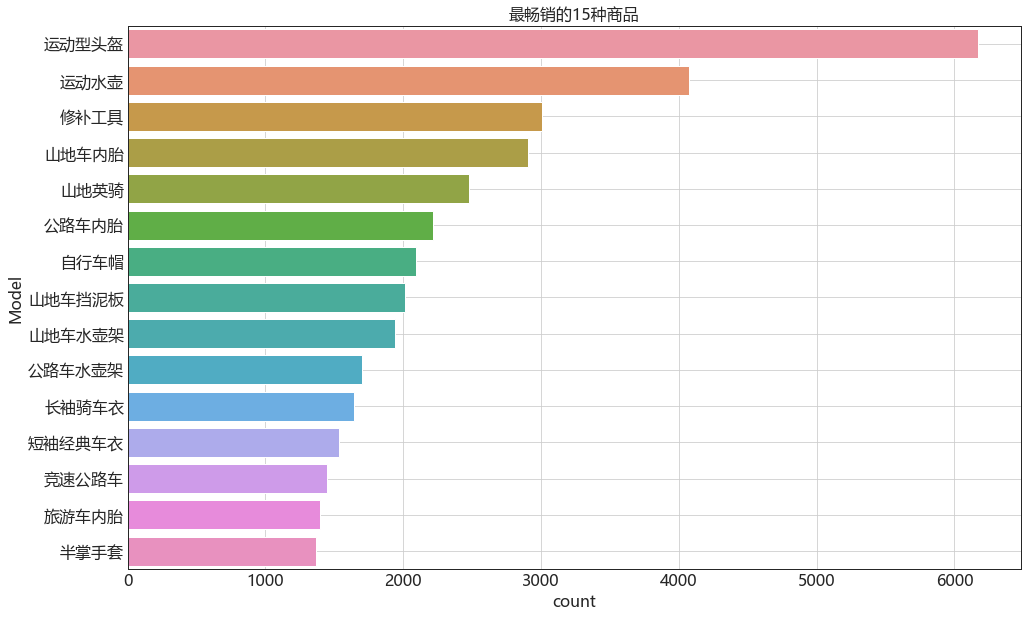
top_15 = top_15['Model'].tolist()
print('According to the sales ranking, the top 15 best-selling items of the bicycle store are:')
for i in range(0,15,5):
print(top_15[i:i+5])

Using Apriori algorithm to solve association rules
from mlxtend.frequent_patterns import apriori as apri
# Generate shopping basket: put all goods purchased by the same customer into the same shopping basket
baskets =bike.groupby('OrderNumber')['Model'].apply(lambda x :x.tolist())
baskets = list(baskets)
#Import package of association rule algorithm
from mlxtend.preprocessing import TransactionEncoder
from mlxtend.frequent_patterns import apriori
from mlxtend.frequent_patterns import association_rules
#Convert to algorithmically acceptable model (Boolean)
te = TransactionEncoder()
baskets_tf = te.fit_transform(baskets)
df = pd.DataFrame(baskets_tf,columns=te.columns_)
print(df.head(5))
Encoded data:
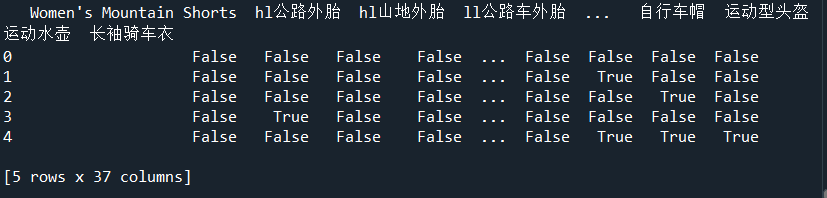
The dimension is (21255, 37). The row indicates a total of 21255 users. The list shows whether the goods under the corresponding user are purchased. If they are purchased, it is true, otherwise false. When the number of users and goods is very large, the matrix dimension will also be very large.
#Set support for frequent itemsets
frequent_itemsets = apriori(df,min_support=0.01,use_colnames= True)
#Find the association rules and set the minimum confidence to 0.15
rules = association_rules(frequent_itemsets,metric = 'confidence',min_threshold = 0.1)
#Set minimum lift
# rules = rules.drop(rules[rules.lift <1.0].index)
#Set title index and print results
rules.rename(columns = {'antecedents':'lhs','consequents':'rhs','support':'sup','confidence':'conf'},inplace = True)
rules = rules[['lhs','rhs','sup','conf','lift']]
print(rules)
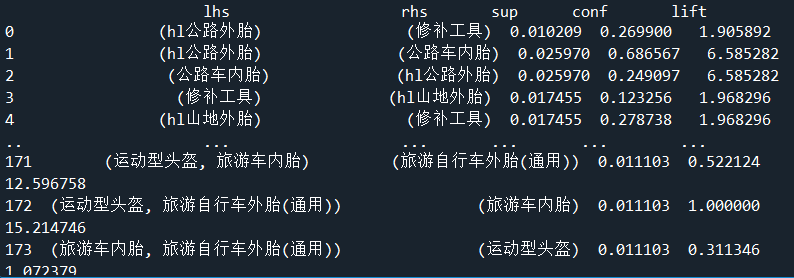
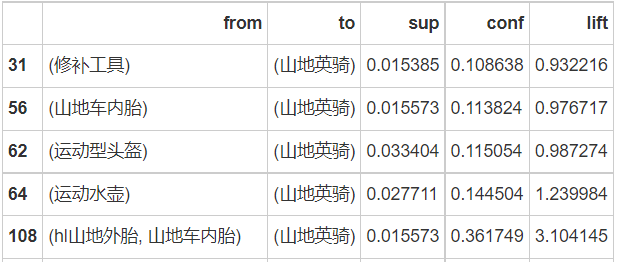
- lhs: known as the left-hand rule, it is commonly understood as the commodity purchased by users - mountain bike inner tube
- It is called the right-hand rule, which is popularly understood as another commodity recommended according to the user's purchase of a commodity - ll tire
- Support: support, the probability that the inner tube of mountain bike and ll mountain tire appear in a shopping ticket at the same time
- Confidence: confidence, the probability of purchasing ll mountain tires at the same time on the premise of purchasing inner tubes of mountain bikes
- lift: recommend ll mountain tires to customers who have purchased inner tubes of mountain bikes. The probability of this customer buying ll mountain tires is that this customer naturally buys about 400% of ll mountain tires, that is, more than 300% higher. Popular understanding: consumers rarely buy corner anti-collision sponges alone. They may think of buying them occasionally or when their children encounter them, such as If we add the recommendation of anti-collision sponge at the corner of the table on the successful order page of the table (desk and dining table), we can greatly improve the sales of anti-collision sponge. This is also in line with the purpose of "relatively non best-selling products" after the top 15 best-selling products found in our exploratory data analysis.
Screening complementary and mutually exclusive products
# Complementary products # The lift promotion degree should be greater than 1 first, and then sort and select the first n you want to study deeply complementary = rules[rules['lift'] > 1].sort_values(by='lift', ascending=False).head(20) # Mutex #lift must be less than 1 first, and then sort and select the first n you want to study deeply exclusive = rules[rules['lift'] < 1].sort_values(by='lift', ascending=True).head(20)
###Recommend products according to association rule results
It needs to be combined with business needs
- Get the maximum marketing response? -- look at the confidence, the higher the better
- Maximize sales? -- the higher the promotion, the better
- Users do not generate consumption, we recommend products to them?
1. Get the highest marketing response rate
If a customer has just placed an order for mountain bike Yingqi, what product should be recommended on his payment success page to obtain the highest marketing response rate.
# The left hand rule: lhs(left hand rules) is used. lhs represents the purchased product
## Use frozenset to select the keys of the dictionary
purchase_good = rules[rules['lhs'] == frozenset({'Mountain Yingqi'})]
print(purchase_good.sample(3))
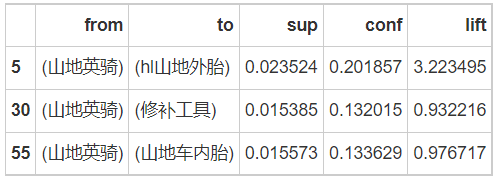
# Sort according to confidence print(purchase_good.sort_values(by='conf', ascending=False)) # According to the following table, mountain bike fenders should be recommended first
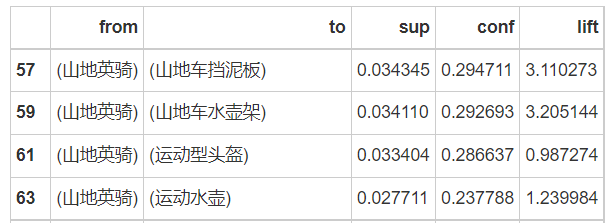
1. Maximize sales
If a new customer has just placed an order for mountain Yingqi,
If you want to maximize the overall sales, what products should you recommend on his paid success page?
print(purchase_good.sort_values(by='lift', ascending=False)) # It can be seen from the table below that hl mountain bike tire should be the first
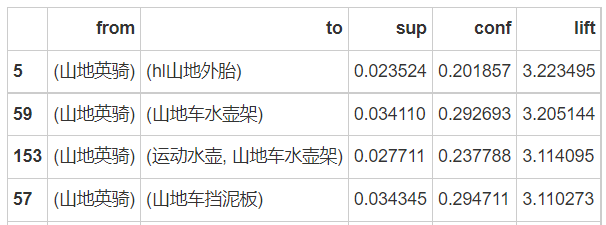
Compared with natural purchase, the promotion degree of A to B is 4.0. The understanding is as follows
If B is recommended to the user who has purchased A, the probability that the user will purchase B is that the user will purchase B alone
(i.e. natural purchase) 400% of the probability of buying B
If B is recommended to the user who has purchased A, the probability of the user purchasing B is higher than that of the user alone
(i.e. natural purchase) probability of buying B \ textbf {high} 300%
3. Users do not consume, and we recommend a product for them
# If you want to recommend mountain English cycling, how should you formulate a marketing strategy?
## The right-hand rule should be selected here, because it is the recommended product directly,
##There is no consumption. Only those who consume, that is, those who buy, use the left-hand rule
purchase_good = rules[rules['rhs'] == frozenset({'Mountain Yingqi'})].sort_values('lift')
# It can be sorted according to confidence or promotion degree, because it is directly in the data frame selected according to the right-hand rule,
## confidence is in direct proportion to lift. You are higher than me
print(purchase_good)
# Therefore, it's better to recommend mountain English riding together with mountain bike kettle rack, mountain bike fender and hl mountain tire cover