preface
A friend's school in the list is Xiamen University. When I remember the agreement between my roommate and me in senior three, I wanted to go to Jimei University, and my friend wanted to go to Xiamen University. As a result, neither of us was admitted to hahaha
I said to blog more before, but a sudden project disrupted my plan. Until today, I should put things right, so I began to blog more today and later. In the summary of news crawling before, I said that I could try crawling news from other schools with my ideas. I don't know if you tried, but I didn't try anyway, ha ha ha, Today's data collection class was boring. I suddenly remembered that I would like to take you to the news on the official website of Xiamen University to verify whether the idea is universal and feasible
Don't doubt it, Bao. I've tried. The idea is absolutely feasible. Hahaha!
⭐ This paper attempts to expand again based on the course content of the school. The data crawled are for learning and use, and should not be used for other purposes
- preparation:
- Crawl address: https://alumni.xmu.edu.cn/xwzx/tzgg.htm
- Crawling purpose: crawling news and statistical analysis of word frequency of news content (more on word frequency in the next chapter)
- Learn about the lead article
- Environment requirements: install the extension libraries BeautifulSoup and urllib( ⭐ It won't be installed here Python download and install third-party libraries)
- Basic knowledge:
- Understand the basic knowledge of web pages
- Master basic python syntax
- Master the syntax of writing python files
1, Crawl the single page content of the column
00 thinking analysis
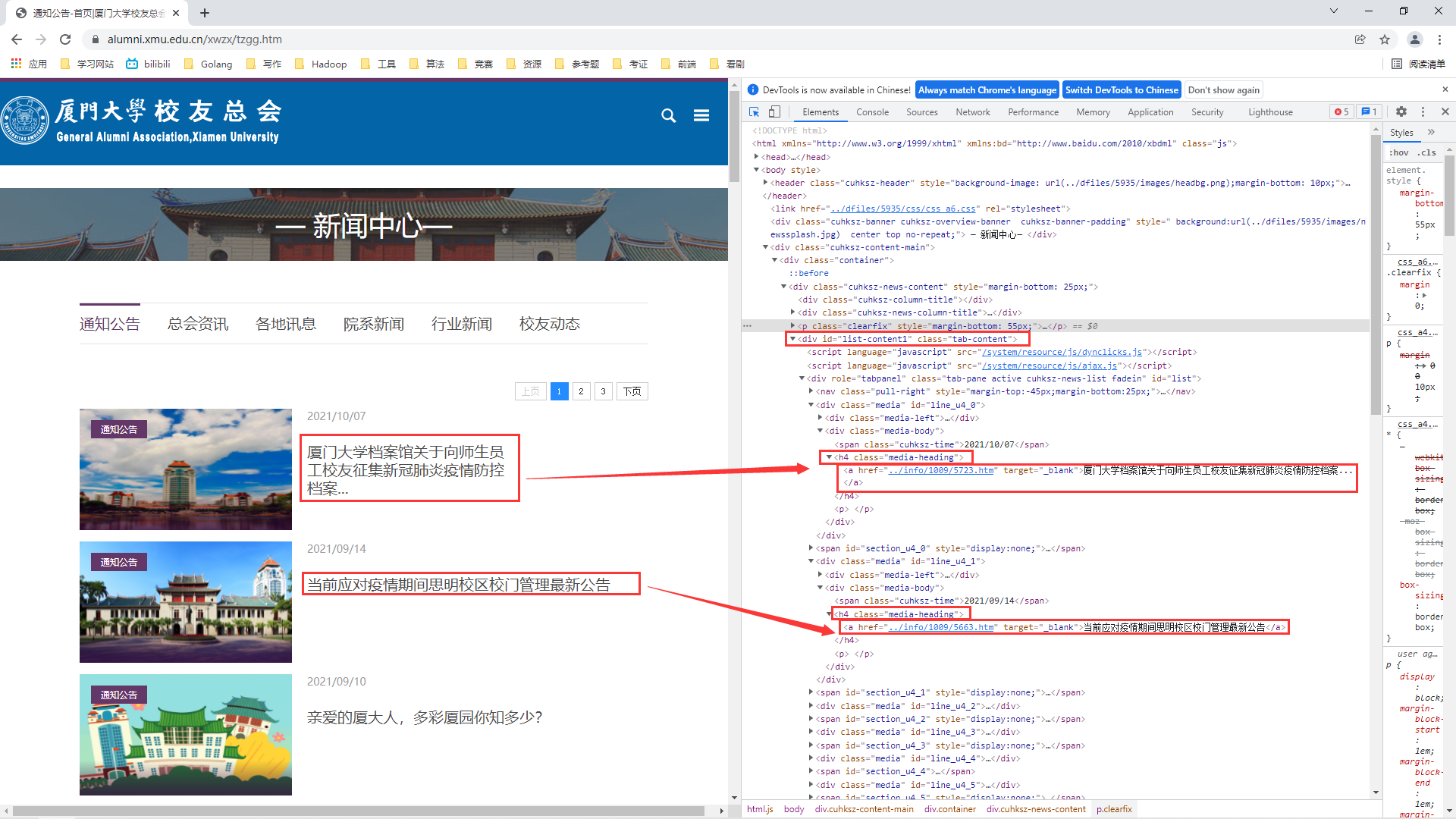
According to the previous idea, all news is wrapped in a div tag, so we choose web page debugging, find the div tag, find the conditions for identifying the div tag, and then observe how each news is displayed, so as to find out the conditions for obtaining news titles and links, as shown in the figure below:
The commissioning observation shows that:
① All news as a whole is wrapped in a div tag with a class attribute of tab content
② Each news is wrapped in a h4 tag with a class attribute of media heading, in which the news link and news title are wrapped in a tag under the h4 tag
③ So far, our idea of obtaining single page content is basically clear:
1> Get the overall content of the page
2> Find and obtain the content under the div tag of class = "tab content" from the overall content of the page
3> Find and obtain the contents under the div tag of class = "tab content" from the contents under the h4 tag of class = "media heading"
01 code implementation
Next, change the idea into code. In the crawling process, we output and print news links and news titles, and store the crawling results in urlList.txt file. The code implementation is as follows:
# News crawling of Xiamen University
# coding=utf-8
import urllib.request
from urllib.parse import urljoin
from bs4 import BeautifulSoup
# Read the html code of the URL, enter the URL and output html
response = urllib.request.urlopen('https://alumni.xmu.edu.cn/xwzx/tzgg.htm')
content = response.read().decode('utf-8')
# analysis
soup = BeautifulSoup(content, 'html.parser')
divs = soup.find_all('div', {'class': "tab-content"})
# media-heading
hs = divs[0].find_all('h4')
with open('urlList.txt', 'w', encoding='utf8') as fp:
for h in hs:
url1 = "https://zs.xmu.edu.cn/"
url2 = h.find_all('a')[0].get("href")
# Splice two addresses using urljoin() of urllib
# The first parameter of urljoin is the url of the basic parent site, and the second parameter is the url that needs to be spliced into an absolute path
# Using url join, we can splice the relative paths of crawled URLs into absolute paths
url = urljoin(url1, url2)
title = h.findAll('a')[0].text
# It is used to prompt in crawling
print(url+','+title)
fp.write(url + "," + title + '\n')
# Used to prompt the end of crawling
print("Crawling is over!!!")
2, Realize automatic page turning and crawling
00 thinking analysis
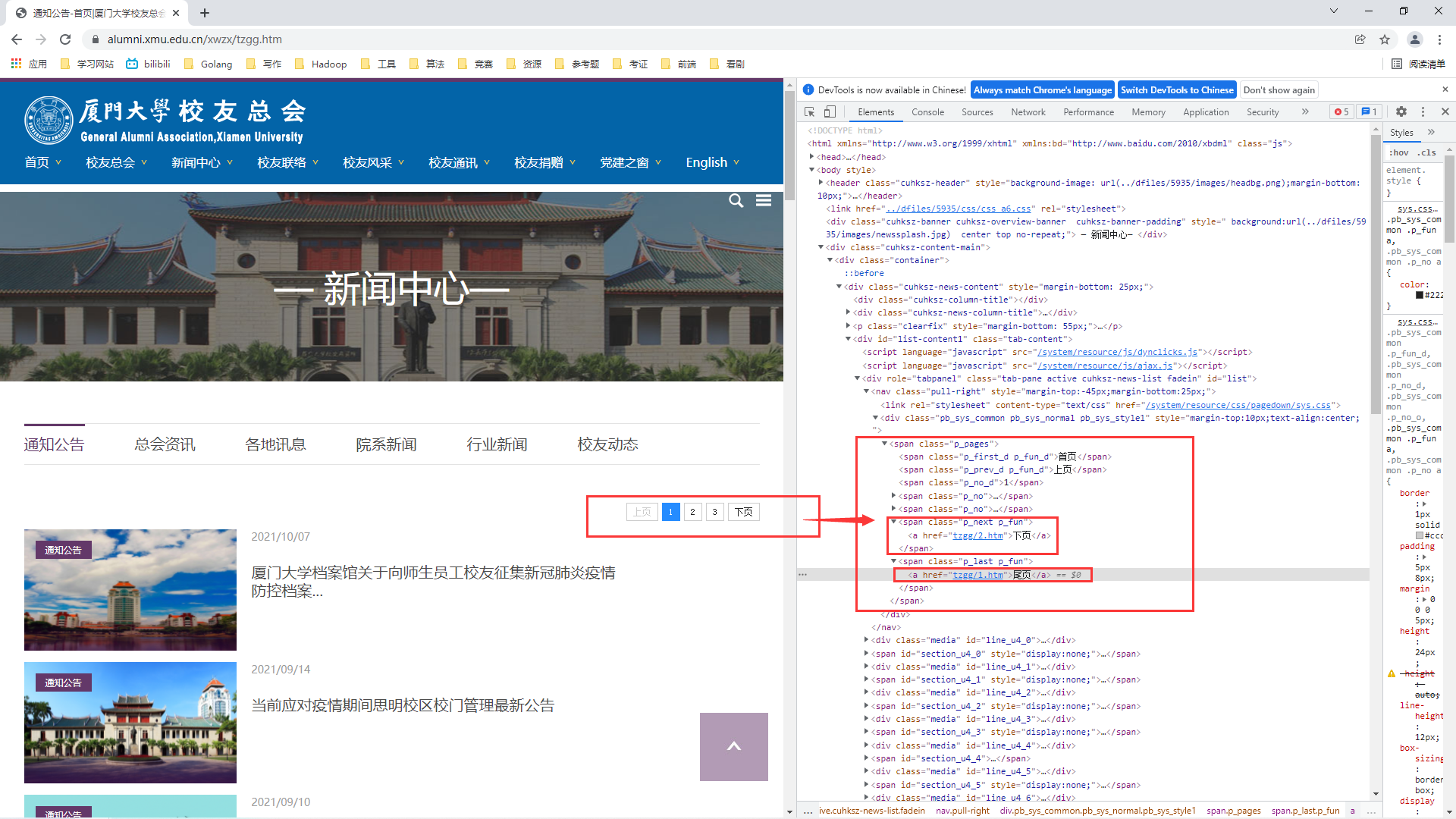
The browser turns the page because we click the link to jump to the next page, and then the browser obtains the content of the next page according to the link and displays it to us. Similarly, turning the page is to obtain the link of the next page, and then we climb each page according to the above thought of climbing a single page according to the link. Therefore, our first step is to get the link of the next page and find out The second step is to find out the conditions for judging that the current page is the last page. Therefore, Bao, now let's start web page debugging:
The commissioning observation shows that:
① All buttons are wrapped in a span tag with a class attribute of p_pages
② The link on the next page is wrapped in a span tag with the class attribute p_next p_fun
③ When debugging the first page, we can get the link to the last page, that is, the link to the last page. Therefore, to know whether the current page is the last page, we only need to compare the link of the current page with the link of the last page. If it is equal, it is the last page
So far, our idea of realizing automatic page turning is basically clear:
1> Find and obtain the content under the span tag of class="p_pages" from the overall content of the obtained page
2> Find and obtain the next page link of the relative path in the a tag under the span tag of class="p_next p_fun" from the content under the span tag of the obtained class="p_pages"
3> Use the while loop to perform the above steps to realize automatic page turning. The condition for the end of the while loop is that the link of the current page is equal to the link of the last page
01 code implementation
Compared with the previous step, we have more code for the while loop to realize automatic page turning and crawling. The code implementation is as follows:
# News crawling of Xiamen University
# coding=utf-8
import urllib.request
from urllib.parse import urljoin
from bs4 import BeautifulSoup
conUrl = 'https://alumni.xmu.edu.cn/xwzx/tzgg.htm'
# Read the html code of the URL, enter the URL and output html
response = urllib.request.urlopen(conUrl)
content = response.read().decode('utf-8')
# analysis
soup = BeautifulSoup(content, 'html.parser')
spans = soup.find_all('span', {'class': "p_pages"})
# Get next page link
nextPage = spans[0].find_all('span', {'class': "p_next p_fun"})
nextPageHref = nextPage[0].find_all('a')[0].get("href")
# Get last page (last page) link
lastPage = spans[0].find_all('span', {'class': "p_last p_fun"})
lastPageHref = lastPage[0].find_all('a')[0].get("href")
while conUrl != lastPageHref:
divs = soup.find_all('div', {'class': "tab-content"})
# media-heading
hs = divs[0].find_all('h4')
pageNum = divs[0].find_all('span', {'class': "p_no_d"})
pageNum = pageNum[0].text
with open('urlList.txt', 'a+', encoding='utf8') as fp:
for h in hs:
url1 = "https://zs.xmu.edu.cn/"
url2 = h.find_all('a')[0].get("href")
# Splice two addresses using urljoin() of urllib
# The first parameter of urljoin is the url of the basic parent site, and the second parameter is the url that needs to be spliced into an absolute path
# Using url join, we can splice the relative paths of crawled URLs into absolute paths
url = urljoin(url1, url2)
title = h.findAll('a')[0].text
# It is used to prompt in crawling
print(url + ',' + title)
fp.write(url + "," + title + '\n')
# Used to prompt the end of the page
print("The first" + pageNum + "Page crawling is over!!!")
spans = soup.find_all('span', {'class': "p_pages"})
pageNum = spans[0].find_all('span', {'class': "p_no_d"})
pageNum = pageNum[0].text
# pageNum is used to identify whether the current page is the last page
if pageNum != '3':
nextPage = spans[0].find_all('span', {'class': "p_next p_fun"})
conUrl = nextPage[0].find_all('a')[0].get("href")
# The missing parent site url of the next page link crawled from different pages is different
# It is used to identify whether the current page is page 1, so as to determine the basic parent site url to be spliced
if pageNum == '1':
url = "https://alumni.xmu.edu.cn/xwzx/"
# i = i+1
else:
url = "https://alumni.xmu.edu.cn/xwzx/tzgg/"
conUrl = urljoin(url, conUrl)
response = urllib.request.urlopen(conUrl)
content = response.read().decode('utf-8')
# https://alumni.xmu.edu.cn/xwzx/tzgg/2.htm
# analysis
soup = BeautifulSoup(content, 'html.parser')
else:
break
3, Realize automatic switching between different column crawling
00 thinking analysis
Bao, can you see that the news of Xiamen University is divided into many columns? Before climbing the news of Heke, there were also different columns, but we only climbed the first column. This time, we added some difficulty to climb down the news under all columns. This requires us to automatically switch to other columns after climbing one column and continue to climb until all columns are finished.
The realization of automatic switching between different columns is essentially very similar to the realization of automatic page turning and crawling. The browser realizes switching columns because we click the corresponding link of the column, and the browser jumps to the corresponding column according to the link. Similarly, the realization of automatic switching between different columns is that we obtain the link of the column from the web page, and then give it to the browser, Bao, think about it, Is this very similar to the previous step, or do I call it "flipping"? Will it be easier to understand hahaha
Therefore, our first step is to get the link of the next column of the current column, find out the "column turning", and then switch different columns, that is, the problem solved by a sentence cycle. Is it still a while cycle this time?
No, Bao, didn't you find that we can get a list of all columns and column links? We directly use the for loop to traverse the li list, then obtain the column name and column link, and then start the first two steps according to the column link. However, Bao, you should pay attention to:
There is no news under the industry news column. If the previous two steps are carried out, there will be an error in analysis. Therefore, before crawling the news under all columns, we should judge whether the current column is an industry news column. If so, skip the next cycle,
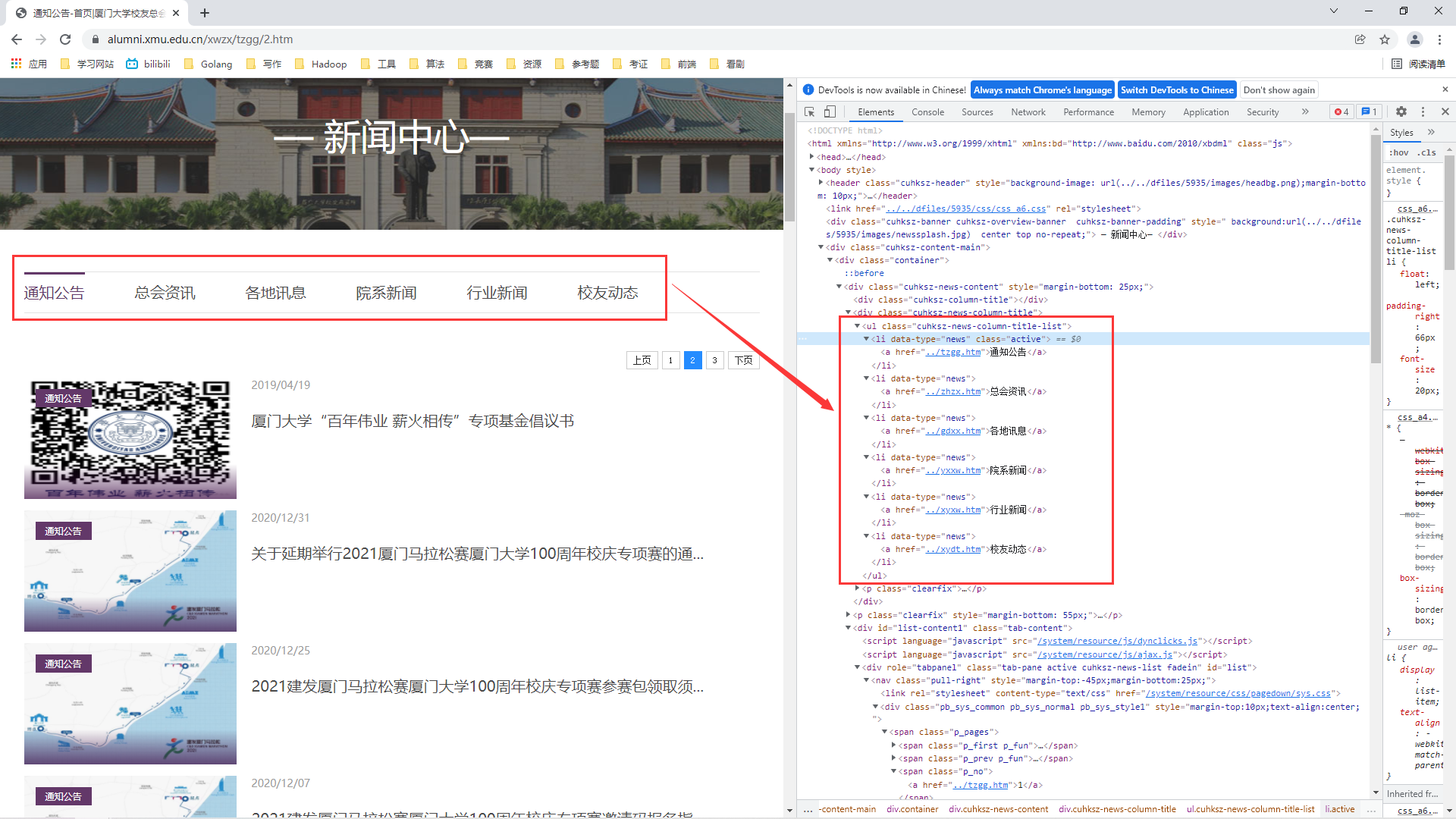
And we can also play a little fancy when storing. Hahaha, use the column name to name, and store the news information of different columns by categories. So, Bao, now let's start page debugging:
The commissioning observation shows that:
① All columns are wrapped in a ul tag with a class attribute of cuhksz news column title list
② The link of each column is wrapped in the li tag under a ul tag, and the class attribute of the current column will be active, while other columns do not have this attribute
③ According to the web page display and the popularity of the current column in ② different from other columns, the last column is alumni dynamic. Therefore, to know whether the current column is the last column, just judge whether the link text content in the li tag of class=active is alumni dynamic
So far, our idea of automatically switching different columns is basically clear:
1> Find and obtain the content under the ul tag of class = "cuhksz news column title list" from the overall content of the obtained page
2> Find and obtain the column link of the relative path in the a tag under the li tag of data type = "news" from the content under the ul tag of the obtained class = "cuhksz news column title list"
3> Find the next column link of the column with class="active" attribute and jump to it
4> Use the while loop to perform the above steps to automatically switch different columns. The condition for the end of the while loop is that the text content of the a tag under the li tag with class="active" attribute is alumni dynamic
01 code implementation
In the previous two steps, we have realized the complete function of crawling all page news of a column. Now, what we need to do is to embed the above code into a while loop to switch columns. The code implementation is as follows:
# News crawling of Xiamen University
# coding=utf-8
import urllib.request
from urllib.parse import urljoin
from bs4 import BeautifulSoup
conUrl = 'https://alumni.xmu.edu.cn/xwzx/tzgg.htm'
# Read the html code of the URL, enter the URL and output html
response = urllib.request.urlopen(conUrl)
content = response.read().decode('utf-8')
# analysis
soup = BeautifulSoup(content, 'html.parser')
uls = soup.find_all('ul', {'class': "cuhksz-news-column-title-list"})
lis = uls[0].find_all('li', {'data-type': "news"})
print(lis)
for li in lis:
# Column name
colName = li.findAll('a')[0].text
# Column link
colHref = li.find_all('a')[0].get("href")
baseUrl = "https://alumni.xmu.edu.cn/xwzx/"
colUrl = urljoin(baseUrl, colHref)
# Judge whether the current column is "industry news"
if colName != 'Industry news':
# Read the html code of the URL, enter the URL and output html
response = urllib.request.urlopen(colUrl)
content = response.read().decode('utf-8')
# analysis
soup = BeautifulSoup(content, 'html.parser')
spans = soup.find_all('span', {'class': "p_pages"})
# Get next page link
nextPage = spans[0].find_all('span', {'class': "p_next p_fun"})
nextPageHref = nextPage[0].find_all('a')[0].get("href")
# Get last page (last page) link
lastPage = spans[0].find_all('span', {'class': "p_last p_fun"})
lastPageHref = lastPage[0].find_all('a')[0].get("href")
while conUrl != lastPageHref:
divs = soup.find_all('div', {'class': "tab-content"})
# media-heading
hs = divs[0].find_all('h4')
pageNum = divs[0].find_all('span', {'class': "p_no_d"})
pageNum = pageNum[0].text
with open(colName+'.txt', 'a+', encoding='utf8') as fp:
for h in hs:
url1 = "https://zs.xmu.edu.cn/"
url2 = h.find_all('a')[0].get("href")
# Splice two addresses using urljoin() of urllib
# The first parameter of urljoin is the url of the basic parent site, and the second parameter is the url that needs to be spliced into an absolute path
# Using url join, we can splice the relative paths of crawled URLs into absolute paths
url = urljoin(url1, url2)
title = h.findAll('a')[0].text
# It is used to prompt in crawling
print(url + ',' + title)
fp.write(url + "," + title + '\n')
# Used to prompt the end of the page
print("The first" + pageNum + "Page crawling is over!!!")
spans = soup.find_all('span', {'class': "p_pages"})
pageNum = spans[0].find_all('span', {'class': "p_no_d"})
pageNum = pageNum[0].text
# The number of pages in different columns is different
if colName == 'Notice announcement':
endPageNum = '3'
elif colName == 'Association information':
endPageNum = '11'
elif colName == 'Local information':
endPageNum = '12'
elif colName == 'Department news':
endPageNum = '4'
elif colName == 'Alumni dynamics':
endPageNum = '13'
# pageNum is used to identify whether the current page is the last page
if pageNum != endPageNum:
nextPage = spans[0].find_all('span', {'class': "p_next p_fun"})
conUrl = nextPage[0].find_all('a')[0].get("href")
# The missing parent site url of the next page link crawled from different pages is different
# It is used to identify whether the current page is page 1, so as to determine the basic parent site url to be spliced
if pageNum == '1':
url = "https://alumni.xmu.edu.cn/xwzx/"
else:
url = colUrl[0:35]+'/'
nextPageUrl = urljoin(url, conUrl)
response = urllib.request.urlopen(nextPageUrl)
content = response.read().decode('utf-8')
# analysis
soup = BeautifulSoup(content, 'html.parser')
else:
break
else:
# Skip this cycle and proceed to the next cycle
continue
4, Complete code display
# News crawling of Xiamen University
# coding=utf-8
import urllib.request
from urllib.parse import urljoin
from bs4 import BeautifulSoup
conUrl = 'https://alumni.xmu.edu.cn/xwzx/tzgg.htm'
# Read the html code of the URL, enter the URL and output html
response = urllib.request.urlopen(conUrl)
content = response.read().decode('utf-8')
# analysis
soup = BeautifulSoup(content, 'html.parser')
uls = soup.find_all('ul', {'class': "cuhksz-news-column-title-list"})
lis = uls[0].find_all('li', {'data-type': "news"})
print(lis)
for li in lis:
# Column name
colName = li.findAll('a')[0].text
# Column link
colHref = li.find_all('a')[0].get("href")
baseUrl = "https://alumni.xmu.edu.cn/xwzx/"
colUrl = urljoin(baseUrl, colHref)
if colName != 'Industry news':
# Read the html code of the URL, enter the URL and output html
response = urllib.request.urlopen(colUrl)
content = response.read().decode('utf-8')
# analysis
soup = BeautifulSoup(content, 'html.parser')
spans = soup.find_all('span', {'class': "p_pages"})
# Get next page link
nextPage = spans[0].find_all('span', {'class': "p_next p_fun"})
nextPageHref = nextPage[0].find_all('a')[0].get("href")
# Get last page (last page) link
lastPage = spans[0].find_all('span', {'class': "p_last p_fun"})
lastPageHref = lastPage[0].find_all('a')[0].get("href")
while conUrl != lastPageHref:
divs = soup.find_all('div', {'class': "tab-content"})
# media-heading
hs = divs[0].find_all('h4')
pageNum = divs[0].find_all('span', {'class': "p_no_d"})
pageNum = pageNum[0].text
with open(colName+'.txt', 'a+', encoding='utf8') as fp:
for h in hs:
url1 = "https://zs.xmu.edu.cn/"
url2 = h.find_all('a')[0].get("href")
# Splice two addresses using urljoin() of urllib
# The first parameter of urljoin is the url of the basic parent site, and the second parameter is the url that needs to be spliced into an absolute path
# Using url join, we can splice the relative paths of crawled URLs into absolute paths
url = urljoin(url1, url2)
title = h.findAll('a')[0].text
# It is used to prompt in crawling
print(url + ',' + title)
fp.write(url + "," + title + '\n')
# Used to prompt the end of the page
print("The first" + pageNum + "Page crawling is over!!!")
spans = soup.find_all('span', {'class': "p_pages"})
pageNum = spans[0].find_all('span', {'class': "p_no_d"})
pageNum = pageNum[0].text
# The number of pages in different columns is different
if colName == 'Notice announcement':
endPageNum = '3'
elif colName == 'Association information':
endPageNum = '11'
elif colName == 'Local information':
endPageNum = '12'
elif colName == 'Department news':
endPageNum = '4'
elif colName == 'Alumni dynamics':
endPageNum = '13'
# pageNum is used to identify whether the current page is the last page
if pageNum != endPageNum:
nextPage = spans[0].find_all('span', {'class': "p_next p_fun"})
conUrl = nextPage[0].find_all('a')[0].get("href")
# The missing parent site url of the next page link crawled from different pages is different
# It is used to identify whether the current page is page 1, so as to determine the basic parent site url to be spliced
if pageNum == '1':
url = "https://alumni.xmu.edu.cn/xwzx/"
else:
url = colUrl[0:35]+'/'
nextPageUrl = urljoin(url, conUrl)
response = urllib.request.urlopen(nextPageUrl)
content = response.read().decode('utf-8')
# https://alumni.xmu.edu.cn/xwzx/tzgg/2.htm
# analysis
soup = BeautifulSoup(content, 'html.parser')
else:
break
else:
continue
5, Summary
So far, we synchronously climbed the news information on the official website of Xiamen University according to the previous idea. Of course, there are some detailed changes in the code, which is inevitable, because different website designs are also different, but mastering the whole idea is basically universal. Still, the static website is relatively simple, and various details are easy to find after debugging
Well, Bao, I don't want to write a summary today. I can write private letters or comments that have questions or don't understand!
(word frequency statistics and other blog posts will be more detailed later)