Project description
Reproduction of Paper "Adversarial Learning for Semi-Supervised Semantic Segmentation" with PaddlePaddle.
This project reproduces the classic paper "Adversarial Learning for Semi-Supervised Semantic Segmentation" in semi supervised semantic segmentation field based on PaddlePaddle, and achieves the index of thesis.
AdvSemiSeg is one of the earliest articles in the field of semi supervised semantic segmentation. Different from the classification level label data and classification level loss function commonly used in the field of weak supervision, semi supervised learning emphasizes the combination of a small amount of labeled data and a large amount of unlabeled data. Its core lies in how to better mine the supervision information of unlabeled data through labeled data, so as to improve the performance of the model and reduce labor expenditure.
Method flow
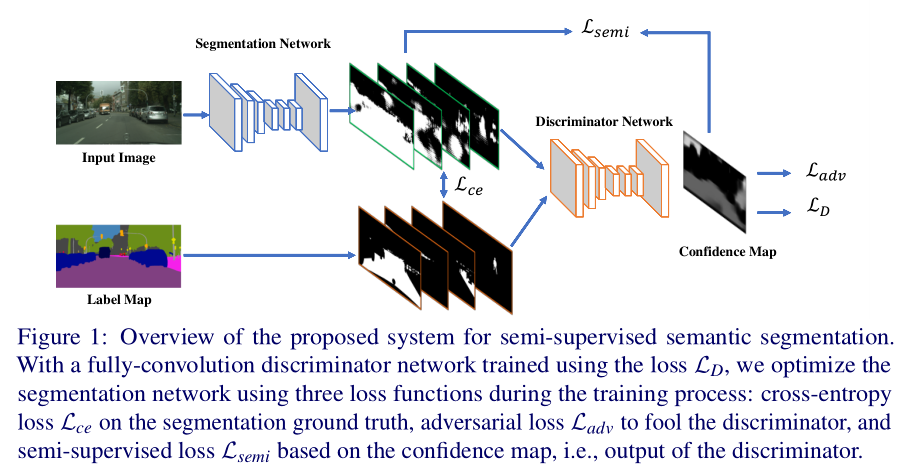
The model consists of two modules
- Split network
𝐻 × 𝑊 × 3 - > split network - > 𝐻 × 𝑊 × 𝐶 (where 𝐶 is the number of split categories)
- Discriminant network
The input is a class probability graph, which is obtained by dividing the network or one hot coding from the ground truth label
The output is 𝐻 × 𝑊 × In the probability diagram of 1, the pixel value 𝑝 = 1 represents from the ground truth label, and the pixel value 𝑝 = 0 represents from the segmentation network.
Training process:
Both labeled and unlabeled images are used in training
1. When using labeled images, the segmentation network is subject to both standard cross entropy loss based on ground truth label and adversarial loss based on Discriminant network. Note that the training discriminant network only uses labeled data.
2. When the unlabeled image is used, the preliminary segmentation result is obtained by the segmentation network, and then the preliminary segmentation result is sent to the discrimination network to obtain the confidence map. The confidence map is used as the supervision signal, and the preliminary segmentation prediction result is mask ed as the label. The segmentation network is trained by the self-learning method.
Reference
-
Thesis address: https://arxiv.org/abs/1802.07934
-
Original project: https://github.com/hfslyc/AdvSemiSeg
-
Reference blog: Semi supervised semantic segmentation network advanced learning for semi supervised semantic segmentation paper reading notes
Reproduction description
The default configuration is ResNet101+Deeplabv2+VOC2012+1/8Label
Other training settings are consistent with the original items: 20000 iter, batch size 10;
- Recurrence index
advSemiSeg folder Version (original version)
| Thesis index | Recurrence index |
|---|---|
| 69.5 miou | 70.4 miou |
1. The settings of the model are in the corresponding code:
- Line 204 in train.py;
- Line 197 in evaluate.py;
2. Label rate setting: – labeled ratio 0.125 indicates 1 / 8 label rate
3. It has been set under the training instruction and evaluation instruction
4. The evaluation results are stored in the txt file in results
PaddleSeg suite version:
The model is consistent with other PaddleSeg models. Label needs to be specified_ Ratio enables semi supervised training algorithms. See the PaddleSeg/semi directory for details.
| Thesis index | Recurrence index |
|---|---|
| 69.5 miou | 72.6 miou |
The following training evaluation and codes can be run with one click; Fully supervised baseline and automated testing are optional and should be noted.
Dataset preparation
PASCAL VOC2012 data set is adopted as the data set, and the enhanced label provided by the original text is adopted.
#Decompress dataset !unzip -q data/data4379/pascalvoc.zip -d data/data4379/ !unzip -q data/data117898/SegmentationClassAug.zip -d data/data4379/pascalvoc/VOCdevkit/VOC2012/
!cp aug.txt data/data4379/pascalvoc/VOCdevkit/VOC2012/ImageSets/Segmentation/
# Data set structure !tree -L 1 /home/aistudio/data/data4379/pascalvoc/VOCdevkit/VOC2012
Training advSemiSeg
!cd PaddleSegSemi/ && python train.py --config configs/deeplabv2/deeplabv2_resnet101_os8_voc_semi_321x321_20k.yml --label_ratio 0.125 --num_workers 0 --use_vdl --do_eval --save_interval 1000 --save_dir deeplabv2_res101_voc_0.125_20k
## Do not use the PaddleSeg Suite # !cd advSemiSeg/ && python train.py --checkpoint_dir ./checkpoints/voc_semi_0_125 --labeled-ratio 0.125 --ignore-label 255 --num-classes 21 --use_vdl
Evaluate advSemiSeg
## Using the PaddleSeg Suite !cd PaddleSegSemi/ && python val.py --config configs/deeplabv2/deeplabv2_resnet101_os8_voc_semi_321x321_20k.yml --model_path deeplabv2_res101_voc_0.125_20k/best_model/model.pdparams
## Do not use the PaddleSeg Suite # !cd advSemiSeg/ && python evaluate.py --dataset pascal_voc --num-classes 21 --restore-from ./checkpoints/voc_semi_0_125/20000.pdparams
2021-11-24 10:15:59 [INFO] ------------Environment Information------------- platform: Linux-4.13.0-36-generic-x86_64-with-debian-stretch-sid Python: 3.7.4 (default, Aug 13 2019, 20:35:49) [GCC 7.3.0] Paddle compiled with cuda: True NVCC: Cuda compilation tools, release 10.1, V10.1.243 cudnn: 7.6 GPUs used: 1 CUDA_VISIBLE_DEVICES: None GPU: ['GPU 0: Tesla V100-SXM2-16GB'] GCC: gcc (Ubuntu 7.5.0-3ubuntu1~16.04) 7.5.0 PaddlePaddle: 2.2.0 OpenCV: 4.1.1 ------------------------------------------------ Namespace(data_dir='/home/aistudio/data/data4379/pascalvoc/VOCdevkit/VOC2012', data_list='./data/voc_list/val.txt', dataset='pascal_voc', gpu=0, ignore_label=255, model='Deeplabv2', num_classes=21, restore_from='./checkpoints/voc_semi_0_125/20000.pdparams', save_dir='results', save_output_images=False) W1124 10:15:59.974874 2351 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.0, Runtime API Version: 10.1 W1124 10:15:59.974916 2351 device_context.cc:465] device: 0, cuDNN Version: 7.6. 2021-11-24 10:16:03 [INFO] No pretrained model to load, ResNet_vd will be trained from scratch. 2021-11-24 10:16:03 [INFO] Loading pretrained model from ./checkpoints/voc_semi_0_125/20000.pdparams 2021-11-24 10:16:03 [INFO] There are 538/538 variables loaded into DeepLabV2. 0 processd evaluate.py:238: DeprecationWarning: `np.int` is a deprecated alias for the builtin `int`. To silence this warning, use `int` by itself. Doing this will not modify any behavior and is safe. When replacing `np.int`, you may wish to use e.g. `np.int64` or `np.int32` to specify the precision. If you wish to review your current use, check the release note link for additional information. Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations gt = np.asarray(label[0].numpy()[:size[0],:size[1]], dtype=np.int) evaluate.py:245: DeprecationWarning: `np.int` is a deprecated alias for the builtin `int`. To silence this warning, use `int` by itself. Doing this will not modify any behavior and is safe. When replacing `np.int`, you may wish to use e.g. `np.int64` or `np.int32` to specify the precision. If you wish to review your current use, check the release note link for additional information. Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations output = np.asarray(np.argmax(output, axis=2), dtype=np.int) 100 processd 200 processd 300 processd 400 processd 500 processd 600 processd 700 processd 800 processd 900 processd 1000 processd 1100 processd 1200 processd 1300 processd 1400 processd class 0 background IU 0.93 class 1 aeroplane IU 0.85 class 2 bicycle IU 0.41 class 3 bird IU 0.85 class 4 boat IU 0.67 class 5 bottle IU 0.78 class 6 bus IU 0.90 class 7 car IU 0.84 class 8 cat IU 0.84 class 9 chair IU 0.32 class 10 cow IU 0.72 class 11 diningtable IU 0.38 class 12 dog IU 0.81 class 13 horse IU 0.73 class 14 motorbike IU 0.81 class 15 person IU 0.83 class 16 pottedplant IU 0.44 class 17 sheep IU 0.78 class 18 sofa IU 0.43 class 19 train IU 0.72 class 20 tvmonitor IU 0.71 meanIOU: 0.7040637094579905
Train fully supervised baseline (optional)
!cd advSemiSeg/ && python train_full_pd.py --dataset pascal_voc \
--checkpoint-dir ./checkpoints/voc_full \
--ignore-label 255 \
--num-classes 21
TIPC automated test (optional)
You can view the README of PaddleSegSemi in detail. You need to install the related dependencies of the logger.
- Install autolog
git clone https://github.com/LDOUBLEV/AutoLog cd AutoLog pip3 install -r requirements.txt python3 setup.py bdist_wheel pip3 install ./dist/auto_log-1.0.0-py3-none-any.whl cd ../
#Enter the PaddleSegSemi folder and run the command %cd PaddleSegSemi/ !pip3 install -r requirements.txt !bash test_tipc/prepare.sh ./test_tipc/configs/advsemiseg_deeplabv2_res101_humanseg/train_infer_python.txt 'lite_train_lite_infer' !bash test_tipc/test_train_inference_python.sh ./test_tipc/configs/advsemiseg_deeplabv2_res101_humanseg/train_infer_python.txt 'lite_train_lite_infer'
summary
When only a part of labeled data is used in the original data set, the addition of unlabeled data improves the performance, which proves that the adaptive semi supervised learning setting proposed in this paper is very effective.
But this paper also has shortcomings. For example, the discriminator does not use image information, which is optimized in s4GAN(TPAMI,2019).
In the future, we will continue to open-source Paddle of semi supervised semantic segmentation method ~
Welcome to pay more attention