Introduction: starting from an example of data duplication in nailing real person authentication scenario, this paper analyzes that the reason is idempotent failure caused by concurrency, and leads to the concept of idempotent. Aiming at the idempotent problem in concurrent scenario, a feasible methodology for realizing idempotent is proposed. Combined with the business scenario of adding address book, the database idempotent problem is simply analyzed, and the method of realizing idempotent by distributed lock is discussed in detail. This paper analyzes the problems of lock in distributed scenario, including single point of failure, network timeout, wrong release of others' lock, early release of lock and single point of failure of distributed lock, puts forward the corresponding solutions, and introduces the specific implementation of the corresponding solutions.

Author Bai Shu
Source: Ali technical official account
Write before: the idempotent problems discussed in this paper are idempotent problems in concurrent scenarios. That is, the system has idempotent design, but it fails in the concurrent scenario.
I. summary
Starting from an example of data duplication in nailing real person authentication scenario, this paper analyzes that the reason is idempotent failure caused by concurrency, and leads to the concept of idempotent.
Aiming at the idempotent problem in concurrent scenario, a feasible methodology for realizing idempotent is proposed. Combined with the business scenario of adding address book, the database idempotent problem is simply analyzed, and the method of realizing idempotent by distributed lock is discussed in detail.
This paper analyzes the problems of lock in distributed scenario, including single point of failure, network timeout, wrong release of others' lock, early release of lock and single point of failure of distributed lock, puts forward the corresponding solutions, and introduces the specific implementation of the corresponding solutions.
Two questions
There is a problem of data duplication in nailing real person authentication business.
1 problem phenomenon
Under normal circumstances, there should be only one real person authentication success record in the database, but in fact, there are multiple records for a user.

2. Causes of problems
Concurrency leads to non idempotent.
Let's first review the concept of idempotent:
- Idempotent (idempotent, idempotence) is a mathematical and computer concept, which is common in abstract algebra.
- In programming, the characteristic of an idempotent operation is that the impact of any multiple execution is the same as that of one execution.
- --From Baidu Encyclopedia
Real person authentication has idempotent design in business, and its general process is as follows:
1) After the user selects real person authentication, a record will be initialized at the server;
2) The user completes the face comparison at the nail moving end according to the instructions;
3) After the comparison, access the server to modify the database status.
In step 3, before modifying the database state, judge whether it has been initialized, whether it has been authenticated, and whether Zhike returns successful authentication to ensure idempotence. The idempotent judgment condition can be satisfied and the database state can be modified only when the server attempts to modify the database state for the first time. Any other requests will be returned directly without affecting the database status. The result of requesting multiple access to the server is the same as that of requesting the first access to the server. Therefore, on the premise of successful real person authentication, the database should have and only one successful authentication record.
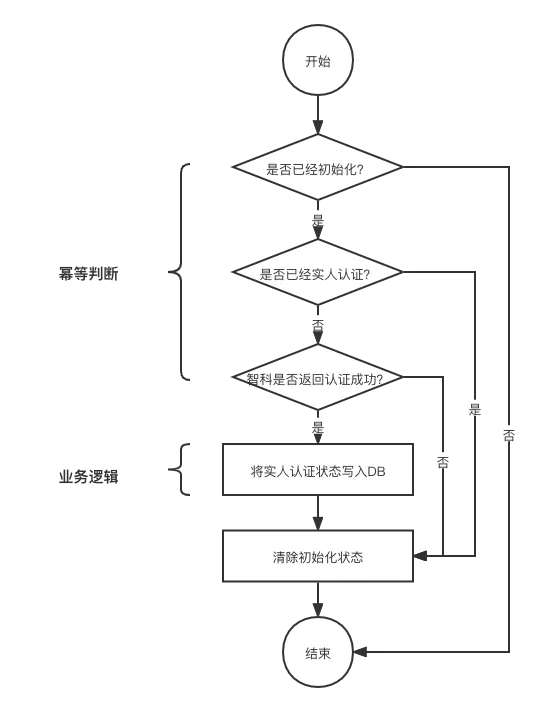
However, in the actual process, we find that the same request will modify the database state many times, and the system does not realize idempotence as we expected. The reason is that concurrent access is requested. Before the first request completes the modification of the server state, other concurrent requests and the first request pass the idempotent judgment and modify the database state for many times.
Concurrency leads to the failure of the original idempotent design.
Concurrency leads to non idempotent.
Three solutions
The key to solving the idempotent problem in the concurrent scenario is to find the uniqueness constraint, perform the uniqueness check, save the same data once and operate the same request once.
A request to access the server may generate the following interactions:
- Interact with data sources, such as database state change;
- Interact with other business systems, such as calling downstream services or sending messages;
A request can contain only one interaction or multiple interactions. For example, a request can modify the database state only once, or send a message of successful database state modification after modifying the database state.
So we can draw a conclusion: in the concurrent scenario, if a system depends on idempotent components, then the system is naturally idempotent.
Taking the database as an example, if the impact of a request on the data is to add a new piece of data, the unique index can be the solution of the idempotent problem. The database will help us perform uniqueness check, and the same data will not fall into the database repeatedly.
Nailing address book addition solves the idempotent problem through the unique index of the database. Take the addition of nailed address book as an example. Before writing data to the database, you will first judge whether the data already exists in the database. If it does not exist, the addition request will eventually insert a piece of data into the employee table of the database. A large number of concurrent address book add-on requests make it possible for the idempotent design of the system to fail. In one addition request, (Organization ID, job number) can uniquely mark a request, and there is also a unique index (Organization ID, job number) in the database. Therefore, we can ensure that the same add in request will only modify the database state once, that is, add a record.
If the dependent components are naturally idempotent, the problem is simple, but the actual situation is often more complex. In the concurrent scenario, if the components that the system depends on cannot be idempotent, we need to use additional means to implement idempotent.
A common method is to use distributed locks. There are many ways to implement distributed locks, and the most commonly used is cache distributed locks.
Four distributed locks
What is a Java distributed lock? There are several paragraphs:
- In computer science, locks are mechanisms in a multithreaded environment to prevent different threads from operating on the same resource. When using locking, a resource is "locked" for access by a specific thread, and can only be accessed by a different thread once the resource has been released. Locks have several benefits: they stop two threads from doing the same work, and they prevent errors and data corruption when two threads try to use the same resource simultaneously.
- Distributed locks in Java are locks that can work with not only multiple threads running on the same machine, but also threads running on clients on different machines in a distributed system. The threads on these separate machines must communicate and coordinate to make sure that none of them try to access a resource that has been locked up by another.
These paragraphs tell us that the essence of lock is mutual exclusive access to shared resources. Distributed lock solves the problem of mutual exclusive access to shared resources in distributed systems.
The java.util.concurrent.locks package provides rich lock implementations, including fair lock / unfair lock, blocking lock / non blocking lock, read-write lock and reentrant lock.
How do we implement a distributed lock?
Scheme I
There are two common problems in distributed systems:
1) Single point of failure, that is, when a single point of failure occurs in the application holding the lock, the lock will be invalid for a long time;
2) Network timeout problem, that is, when the client has a network timeout but the actual locking is successful, we can't get the lock correctly again.
To solve problem 1, a simple solution is to introduce the leave time. The holding of locks will be time effective. When a single point of failure occurs in an application, the locks held by it can be released automatically.
To solve problem 2, a simple solution is to support reentry. We configure a non duplicate identity (usually UUID) for each client that obtains the lock. After locking successfully, the lock will bear the identity of the client. When the actual lock is successful and the client times out to retry, we can judge that the lock has been held by the client and return success.
To sum up, we give a lease based distribution lock scheme. For performance considerations, the cache is used as the storage medium of the lock, and the MVCC (multi version concurrency control) mechanism is used to solve the problem of mutually exclusive access to shared resources. See the appendix code for the specific implementation.
The general usage of distributed locks is as follows
● factory for initializing distributed locks
● use the factory to generate a distributed lock instance
● use the distributed instance to lock and unlock
@Test
public void testTryLock() {
//Initialize factory
MdbDistributeLockFactory mdbDistributeLockFactory = new MdbDistributeLockFactory();
mdbDistributeLockFactory.setNamespace(603);
mdbDistributeLockFactory.setMtairManager(new MultiClusterTairManager());
//Acquire lock
DistributeLock lock = mdbDistributeLockFactory.getLock("TestLock");
//Lock unlock operation
boolean locked = lock.tryLock();
if (!locked) {
return;
}
try {
//do something
} finally {
lock.unlock();
}
}The scheme is simple and easy to use, but the problem is also obvious. For example, when releasing a lock, you simply invalidate the key in the cache, so there is a problem of releasing another person's lock by mistake. Fortunately, as long as the lease term of the lock is set long enough, the probability of this problem is small enough.
We use a diagram of Martin Kleppmann in How to do distributed locking to illustrate this problem.
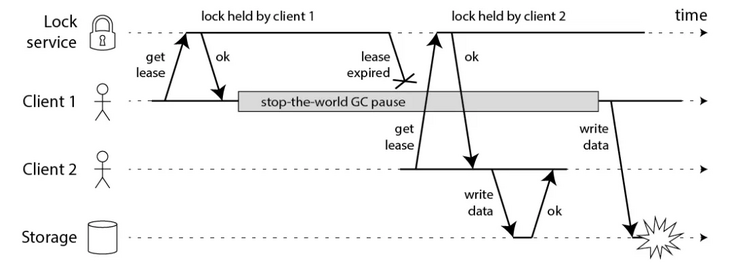
Imagine a situation where the lock has expired before the Client 1 occupying the lock releases the lock, and the Client 2 will acquire the lock. At this time, the lock is held by the Client 2, but the Client 1 may release it wrongly. For a better solution, we set an identity for each lock. When releasing the lock, 1) first query whether the lock is our own, and 2) release the lock if it is our own. Limited by the implementation method, steps 1 and 2 are not atomic operations. Between steps 1 and 2, if the lock expires and is obtained by other clients, the lock of others will also be released by mistake.
Scheme II
The Lua script of Redis can perfectly solve the problem of releasing locks held by others by mistake. In the Correct implementation with a single instance section of Distributed locks with Redis, we can get the answer we want - how to implement a distributed lock.
When we want to acquire a lock, we can do the following
SET resource_name my_random_value NX PX 30000
When we want to release the lock, we can execute the following Lua script
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
endProgramme III
During the discussion of scheme 1 and scheme 2, we repeatedly mentioned a problem: automatic release of lock.
This is a double-edged sword:
1) On the one hand, it solves the problem of single point of failure of the client holding the lock
2) On the other hand, if the lock is released in advance, the wrong holding state of the lock will occur
At this time, we can introduce the automatic renewal mechanism of Watch Dog. We can refer to the following Redisson implementation.
After the lock succeeds, Redisson will call the renewExpiration() method to start a Watch Dog thread to automatically renew the lock. Renew every 1 / 3 of the time. If successful, continue the next renewal. If failed, cancel the renewal operation.
We can see how Redisson renewed it. On line 17 of the renewExpiration() method, the renewExpirationAsync() method is the key operation to perform lock renewal. When we enter the method, we can see that reisson also uses the Lua script to renew the lock: 1) judge whether the lock exists, and 2) reset the expiration time if it exists.
private void renewExpiration() {
ExpirationEntry ee = EXPIRATION_RENEWAL_MAP.get(getEntryName());
if (ee == null) {
return;
}
Timeout task = commandExecutor.getConnectionManager().newTimeout(timeout -> {
ExpirationEntry ent = EXPIRATION_RENEWAL_MAP.get(getEntryName());
if (ent == null) {
return;
}
Long threadId = ent.getFirstThreadId();
if (threadId == null) {
return;
}
RFuture<Boolean> future = renewExpirationAsync(threadId);
future.onComplete((res, e) -> {
if (e != null) {
log.error("Can't update lock " + getRawName() + " expiration", e);
EXPIRATION_RENEWAL_MAP.remove(getEntryName());
return;
}
if (res) {
// reschedule itself
renewExpiration();
} else {
cancelExpirationRenewal(null);
}
});
}, internalLockLeaseTime / 3, TimeUnit.MILLISECONDS);
ee.setTimeout(task);
}protected RFuture<Boolean> renewExpirationAsync(long threadId) {
return evalWriteAsync(getRawName(), LongCodec.INSTANCE, RedisCommands.EVAL_BOOLEAN,
"if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return 1; " +
"end; " +
"return 0;",
Collections.singletonList(getRawName()),
internalLockLeaseTime, getLockName(threadId));
}Programme IV
With Redisson's automatic renewal mechanism, we no longer need to worry about the automatic release of locks. But at this point, I still have to face a problem: distributed lock itself is not a distributed application. When the Redis server fails to work normally, the entire distributed lock cannot provide services.
Further, we can take a look at the redislock algorithm and its implementation mentioned in the article Distributed locks with Redis.
Redlock algorithm is not a silver bullet. There are many arguments about its good or bad:
How to do distributed locking:
https://martin.kleppmann.com/...
Is Redlock safe?:
http://antirez.com/news/101
Martin Kleppmann and Antirez argue about Redlock:
https://news.ycombinator.com/...
reference material
What is a Java distributed lock?
https://redisson.org/glossary...
Distributed locks and synchronizers:
https://github.com/redisson/r...
Distributed locks with Redis:
https://redis.io/topics/distl...
appendix
Distributed lock
public class MdbDistributeLock implements DistributeLock {
/**
* Lock namespace
*/
private final int namespace;
/**
* Cache key corresponding to lock
*/
private final String lockName;
/**
* The unique identification of the lock, which ensures that it can be re entered to deal with the case where the put succeeds but the return timeout occurs
*/
private final String lockId;
/**
* Whether the lock is held. true: Yes
*/
private boolean locked;
/**
* Cache instance
*/
private final TairManager tairManager;
public MdbDistributeLock(TairManager tairManager, int namespace, String lockCacheKey) {
this.tairManager = tairManager;
this.namespace = namespace;
this.lockName = lockCacheKey;
this.lockId = UUID.randomUUID().toString();
}
@Override
public boolean tryLock() {
try {
//Get lock status
Result<DataEntry> getResult = null;
ResultCode getResultCode = null;
for (int cnt = 0; cnt < DEFAULT_RETRY_TIMES; cnt++) {
getResult = tairManager.get(namespace, lockName);
getResultCode = getResult == null ? null : getResult.getRc();
if (noNeedRetry(getResultCode)) {
break;
}
}
//Reentry, lock held, success returned
if (ResultCode.SUCCESS.equals(getResultCode)
&& getResult.getValue() != null && lockId.equals(getResult.getValue().getValue())) {
locked = true;
return true;
}
//Unable to acquire lock, return failure
if (!ResultCode.DATANOTEXSITS.equals(getResultCode)) {
log.error("tryLock fail code={} lock={} traceId={}", getResultCode, this, EagleEye.getTraceId());
return false;
}
//Attempt to acquire lock
ResultCode putResultCode = null;
for (int cnt = 0; cnt < DEFAULT_RETRY_TIMES; cnt++) {
putResultCode = tairManager.put(namespace, lockName, lockId, MDB_CACHE_VERSION,
DEFAULT_EXPIRE_TIME_SEC);
if (noNeedRetry(putResultCode)) {
break;
}
}
if (!ResultCode.SUCCESS.equals(putResultCode)) {
log.error("tryLock fail code={} lock={} traceId={}", getResultCode, this, EagleEye.getTraceId());
return false;
}
locked = true;
return true;
} catch (Exception e) {
log.error("DistributedLock.tryLock fail lock={}", this, e);
}
return false;
}
@Override
public void unlock() {
if (!locked) {
return;
}
ResultCode resultCode = tairManager.invalid(namespace, lockName);
if (!resultCode.isSuccess()) {
log.error("DistributedLock.unlock fail lock={} resultCode={} traceId={}", this, resultCode,
EagleEye.getTraceId());
}
locked = false;
}
/**
* Determine whether to retry
*
* @param resultCode Cached return code
* @return true: Don't try again
*/
private boolean noNeedRetry(ResultCode resultCode) {
return resultCode != null && !ResultCode.CONNERROR.equals(resultCode) && !ResultCode.TIMEOUT.equals(
resultCode) && !ResultCode.UNKNOW.equals(resultCode);
}
}Distributed lock factory
public class MdbDistributeLockFactory implements DistributeLockFactory {
/**
* Cached namespace
*/
@Setter
private int namespace;
@Setter
private MultiClusterTairManager mtairManager;
@Override
public DistributeLock getLock(String lockName) {
return new MdbDistributeLock(mtairManager, namespace, lockName);
}
}Original link
This article is the original content of Alibaba cloud and cannot be reproduced without permission.