On the way, I found that many people like listening to novels with headphones. My colleagues can actually listen to novels with one headphone all day. Xiao Bian expressed great shock. Download and listen to novels in Python today tingchina.com Audio.

List of titles and chapters
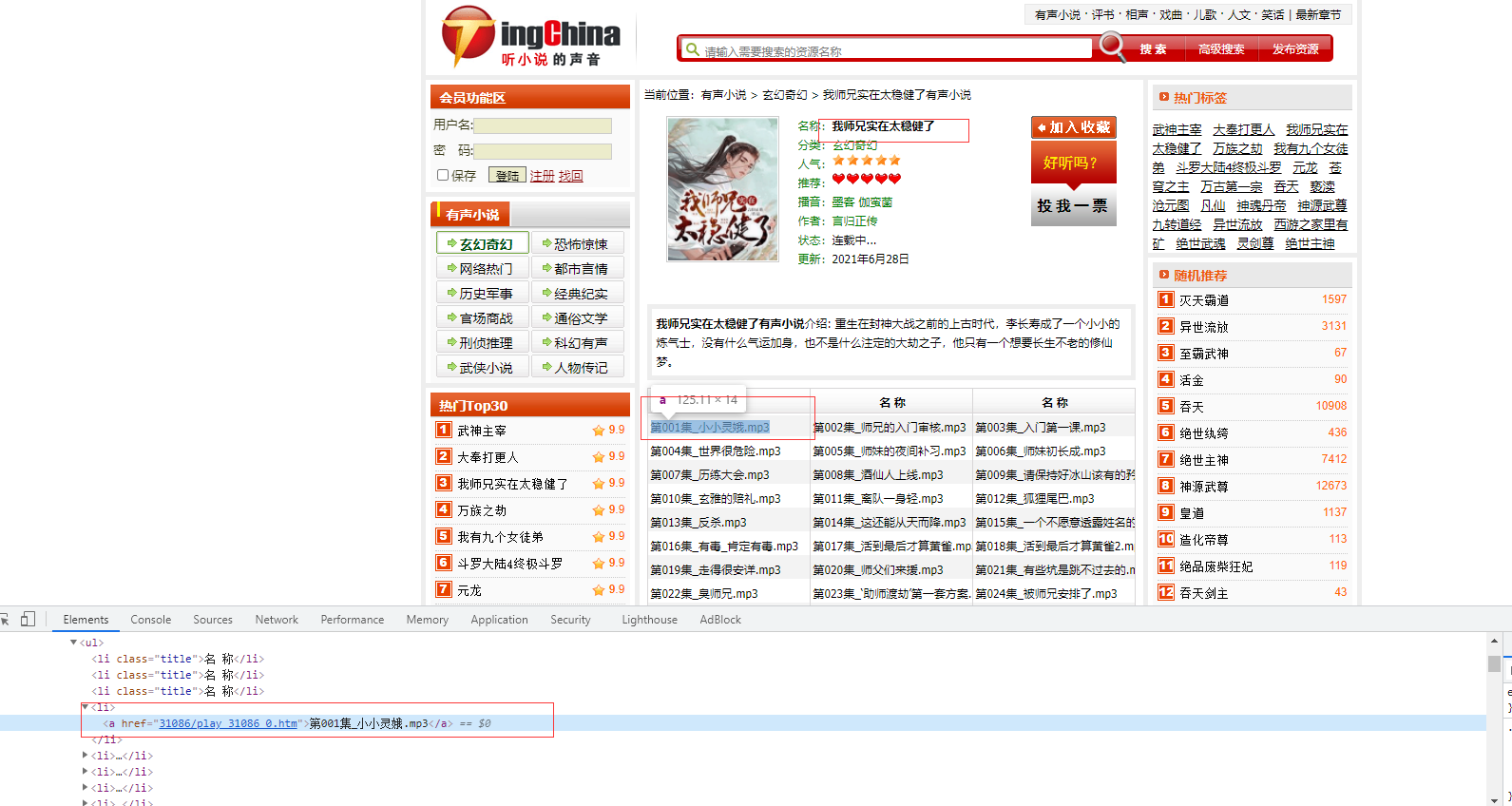
Click to open a Book randomly. On this page, you can use beautiful soup to obtain the list of book titles and audio of all individual chapters. Copy the address of the browser, such as: https://www.tingchina.com/yousheng/disp_31086.htm.
from bs4 import BeautifulSoup
import requests
import re
import random
import os
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36'
}
def get_detail_urls(url):
url_list = []
response = requests.get(url, headers=headers)
response.encoding = 'gbk'
soup = BeautifulSoup(response.text, 'lxml')
name = soup.select('.red12')[0].strong.text
if not os.path.exists(name):
os.makedirs(name)
div_list = soup.select('div.list a')
for item in div_list:
url_list.append({'name': item.string, 'url': 'https://www.tingchina.com/yousheng/{}'.format(item['href'])})
return name, url_listAudio address
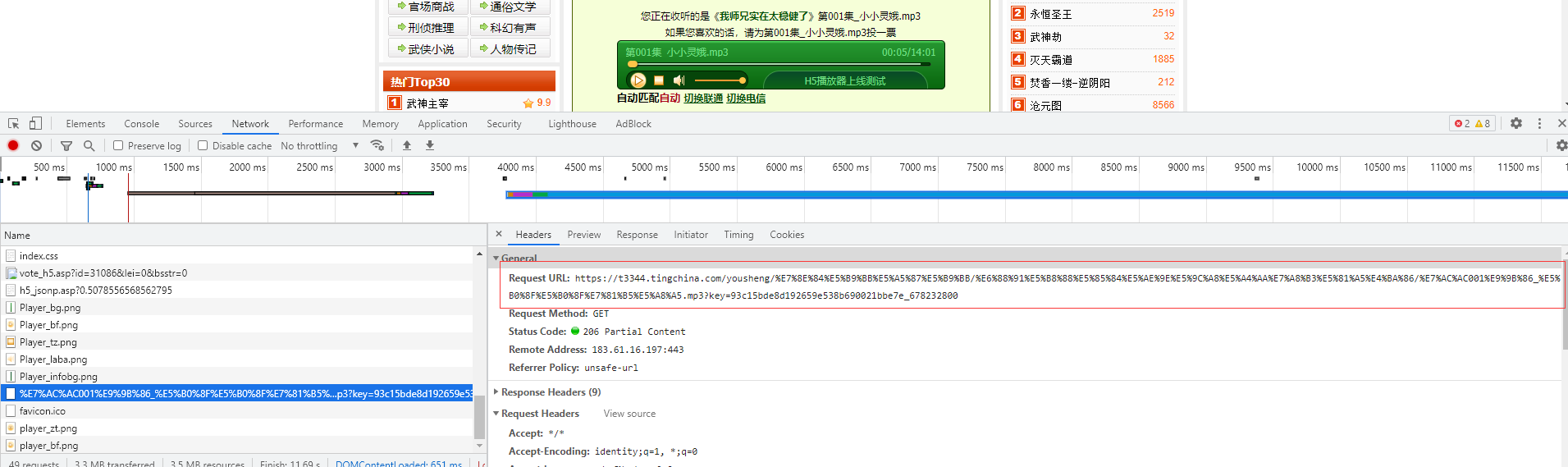
Open the link of a single chapter, use the chapter name as the search term in the Elements panel, and find a script at the bottom, which is the address of the sound source.

It can be seen from the Network panel that the url domain name of the sound source is different from that of the chapter list. You should pay attention to this when getting the download link.
def get_mp3_path(url):
response = requests.get(url, headers=headers)
response.encoding = 'gbk'
soup = BeautifulSoup(response.text, 'lxml')
script_text = soup.select('script')[-1].string
fileUrl_search = re.search('fileUrl= "(.*?)";', script_text, re.S)
if fileUrl_search:
return 'https://t3344.tingchina.com' + fileUrl_search.group(1)download
Surprises are always sudden. Take this https://t3344.tingchina.com/xxxx.mp3 Put it into the browser and run 404.
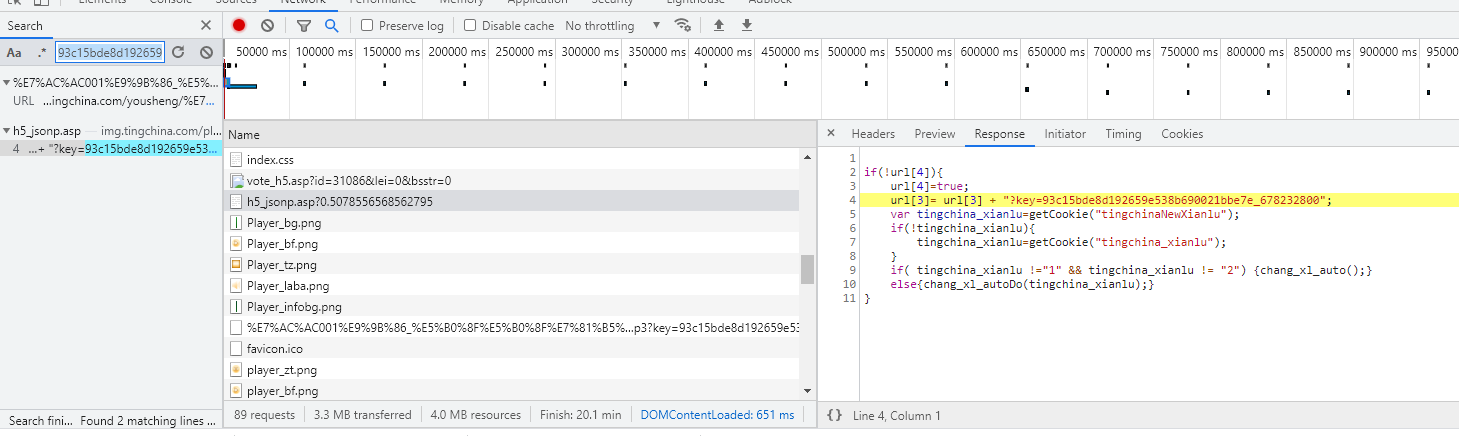
It must be the lack of key parameters. Back to the above, Network carefully observed the mp3 url and found a key keyword behind the url. As shown in the figure below, the key is from https://img.tingchina.com/play/h5_ jsonp.asp? zero point five zero seven eight five five six five six eight five six two seven nine five You can use a regular expression to get the key.
def get_key(url):
url = 'https://img.tingchina.com/play/h5_jsonp.asp?{}'.format(str(random.random()))
headers['referer'] = url
response = requests.get(url, headers=headers)
matched = re.search('(key=.*?)";', response.text, re.S)
if matched:
temp = matched.group(1)
return temp[len(temp)-42:]Last last last __ main__ Concatenate the above codes.
if __name__ == "__main__":
url = input("Please enter the address of the browser page:")
dir,url_list = get_detail_urls()
for item in url_list:
audio_url = get_mp3_path(item['url'])
key = get_key(item['url'])
audio_url = audio_url + '?key=' + key
headers['referer'] = item['url']
r = requests.get(audio_url, headers=headers,stream=True)
with open(os.path.join(dir, item['name']),'ab') as f:
f.write(r.content)
f.flush()summary
This Python crawler is relatively simple. The traffic of 30 yuan per month is not enough. With this small program, you can listen to novels without traffic on the subway.

The most important thing to learn Python is mentality. We are bound to encounter many problems in the process of learning. We may not be able to solve them if we want to break our head. This is normal. Don't rush to deny yourself and doubt yourself. If you have difficulties in learning at the beginning and want to find a python learning and communication environment, you can join us[ python skirt ], receiving learning materials and discussing together will save a lot of time and reduce many problems.