PS: To reproduce, please indicate the source, I have the copyright.
PS: This is based solely on my own understanding.
If there is a conflict with your principles and ideas, please understand.
Pre-description
_This article serves as a backup of my csdn blog's main site. (BlogID=114)
Environmental description
- MLU220 Development Board
- Ubuntu 18.04 + MLU270 Development Host One
- aarch64-linux-gnu-gcc 6.x cross-compilation environment
Preface
_Before reading this article, be sure to know the following pre-article concepts:
- Guidelines for Fishing on Cambrian Accelerated Platform (MLU200 Series) (1) - Basic Concepts and Related Introduction (1) https://blog.csdn.net/u011728480/article/details/121194076 )
- Cambrian Accelerated Platform (MLU200 Series) Guidelines for Fishing (2) - Model Transplantation - Environment Building (2) https://blog.csdn.net/u011728480/article/details/121320982 )
- Cambrian Accelerated Platform (MLU200 Series) Guidelines for Fishing (3) - Model Transplantation-Split Network Instance (3) https://blog.csdn.net/u011728480/article/details/121456789 )
_Here is a review of the Cambrian Accelerated Platform (MLU200 Series) Fishing Guide (1) - Basic Concepts and Related Introduction) Content, Cambrian Acceleration Card is a hardware platform, the bottom layer exists, on the hardware platform, there are drivers, on the driver, there are runtime.
_As the end of this series, this article will start with the offline model above and build our offline model inference code structure from scratch. After a reasonable deployment, it will run properly on the MLU220 development board.
_If there is infringement on the quoted part of the text, please contact me to delete it in time.
Prerequisites for Offline Model Inference
_With the introduction above, we can know that we are mainly calling the runtime-related api. There are two sets of API available here, one is cnrt and the other is easydk. easydk is an API encapsulated by cnrt, which greatly simplifies the development process of offline model inference. However, our main line of development is consistent, that is, to initialize mlu devices, load models, preset Reason, model inference, post-processing, processing results.
_In addition, the Cambrian provides a CNStream program framework, based on EasyDk development, which provides a simple and easy-to-use framework in the pipeline+observer way. If you are interested, please check its website https://github.com/Cambricon/CNStream .
_We are actually using this development method of EasyDK+CNRT to construct a program like CNStream.
Introduction and Compilation of EasyDK
First of all, its official website is: https://github.com/Cambricon/easydk.
In addition to CNToolKit's neuware dependency, it also relies on glog,gflags,opencv, which need to be installed in advance. An introduction to the version of CNToolKit x86 has been described in the Model Migration Environment section.
_Because we are developing an edge-end offline model inference program, in general, we mainly use the EasyInfer part of EasyDK. Its compilation process is as officially described:
- cmake ..
- make
_If you are familiar with the cmake compilation process, you know that the above process is very common. Compiling under x86 is easy for EasyDK compilation, but if cross-compiling is required, it is best to generate only core libraries, with all other sample s and test s turned off.
Complete offline model run on ML270
_Remember in the article "Cambrian Acceleration Platform (MLU200 Series) Fishing Guide (3) - Model Transplantation-Split Network Instance", we can see that by torch_mlu.core.mlu_model.set_core_version('MLU220') allows us to adjust the platform on which the resulting offline model runs, whether it's an edge-end MLU220 or a server deployment-side MLU270. Yes, no mistake. MLU270 can be used for both model migration and offline model deployment. As mentioned at the beginning of this series, these platforms are just differences in deployment scenarios.
_Why do we need to debug the offline model on MLU270? For convenience. Since MLU220 generally requires cross-compilation, especially the generation of related dependent libraries is cumbersome, if the board of MLU220 is also easy to debug, it can also be developed and debugged directly based on MLU220.
_Since I am here in the form of EasyDK+CNRT mixed calls, I mainly comment and introduce them based on their official CNRT inference code and label what EasyDK can do in one step at a relevant location. Here are a few simple answers. Why do I need EasyDK? Why not develop directly based on CNRT? My answer is to make choices based on the need to move the project forward. As for the final form of this program, I'm actually looking forward to developing it directly based on CNRT because it works, but at the expense of knowing the relevant content very well.
_Following is an introduction to the official reasoning code (there may be some changes in the order, some returns are not handled by the official code, you need to be aware when you write your own, and there are some omissions in the official code that I have modified):
/* Copyright (C) [2019] by Cambricon, Inc. */
/* offline_test */
/*
* A test which shows how to load and run an offline model.
* This test consists of one operation --mlp.
*
* This example is used for MLU270 and MLU220.
*
*/
#include "cnrt.h"
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int offline_test(const char *name) {
// This example is used for MLU270 and MLU220. You need to choose the corresponding offline model.
// when generating an offline model, u need cnml and cnrt both
// when running an offline model, u need cnrt only
// First, you must call cnrtInit() to initialize the runtime environment
cnrtInit(0);
// The second step is to check the MLU device and set the current device, which is actually prepared for multi-device reasoning
cnrtDev_t dev;
cnrtGetDeviceHandle(&dev, 0);
cnrtSetCurrentDevice(dev);
// The first and second steps here may actually be done by creating an EasyInfer object with complete error checking.
//
// prepare model name
// load model
// The third step is to load the model
cnrtModel_t model;
cnrtLoadModel(&model, "test.cambricon");
// get model total memory
// The fourth step is to get some properties of the model, such as memory usage and parallelism, which is optional.
int64_t totalMem;
cnrtGetModelMemUsed(model, &totalMem);
printf("total memory used: %ld Bytes\n", totalMem);
// get model parallelism
int model_parallelism;
cnrtQueryModelParallelism(model, &model_parallelism);
printf("model parallelism: %d.\n", model_parallelism);
// The fifth step is to establish the logical flow of inference, which is to generate the model inference structure dynamically in memory based on the offline model. Here "subnet0" is a kernel-func name, which is not fixed, but the common name is subnet0.
// In.cambricon_ There are related definitions in the twins companion file.
// This is similar to cuda Programming in that the model inference structure we just generated is actually treated as a kernel function, and this is the function name.
// load extract function
cnrtFunction_t function;
cnrtCreateFunction(&function);
cnrtExtractFunction(&function, model, "subnet0");
// Step 6, get the number of input and output nodes and the size of input and output data. Note that many networks have multiple inputs and may have multiple outputs. With secondary attention to this concept, subsequent operations are designed on the basis of multiple inputs and outputs.
int inputNum, outputNum;
int64_t *inputSizeS, *outputSizeS;
cnrtGetInputDataSize(&inputSizeS, &inputNum, function);
cnrtGetOutputDataSize(&outputSizeS, &outputNum, function);
// prepare data on cpu
// Step 7, Request input and output memory on the cpu, where is a two-dimensional pointer, representing multiple inputs and outputs
void **inputCpuPtrS = (void **)malloc(inputNum * sizeof(void *));
void **outputCpuPtrS = (void **)malloc(outputNum * sizeof(void *));
// allocate I/O data memory on MLU
// Step 8, Request input and output memory on mlu, where is a two-dimensional pointer, representing multiple inputs and outputs.
// Data memory has not been actually requested at this time, only a handle (pointer) to the data node has been requested
void **inputMluPtrS = (void **)malloc(inputNum * sizeof(void *));
void **outputMluPtrS = (void **)malloc(outputNum * sizeof(void *));
// prepare input buffer
// Step 9 applies for real memory space for the data node handles in step 8, respectively. Here, inputCpuPtrS and inputMluPtrS correspond one to one. This is because the memory addresses are different and the memory managers are different. The same is true for output.
// malloc is the standard c request heap memory interface
// cnrtMalloc is the memory interface managed by the application mlu, which can be directly interpreted as requesting video memory by analogy to cuda
for (int i = 0; i < inputNum; i++) {
// converts data format when using new interface model
inputCpuPtrS[i] = malloc(inputSizeS[i]);
// malloc mlu memory
cnrtMalloc(&(inputMluPtrS[i]), inputSizeS[i]);
cnrtMemcpy(inputMluPtrS[i], inputCpuPtrS[i], inputSizeS[i], CNRT_MEM_TRANS_DIR_HOST2DEV);
}
// prepare output buffer
for (int i = 0; i < outputNum; i++) {
outputCpuPtrS[i] = malloc(outputSizeS[i]);
// malloc mlu memory
cnrtMalloc(&(outputMluPtrS[i]), outputSizeS[i]);
}
// Step 10, first fill the inputCpuPtrS with the preprocessed image data, and copy the cpu input data into the mlu input data memory
cv::Mat _in_img;
_in_img = cv::imread("test.jpg");
_in_img.convertTo(_in_img, CV_32FC3);
for (int i = 0; i < inputNum; i++) {
// Note that I added memcpy here. Generally speaking, the data input of the model is fp16 or fp32, but generally our opencv generated uint8. You need to convert to fp32, or fp16.
// Importantly, it happens three times, pay attention to the data format after picture preprocessing and the data format of model input, different words, need to be converted, the official provided cnrtCastDataType to assist the conversion process.
// Importantly, it happens three times, pay attention to the data format after picture preprocessing and the data format of model input, different words, need to be converted, the official provided cnrtCastDataType to assist the conversion process.
// Importantly, it happens three times, pay attention to the data format after picture preprocessing and the data format of model input, different words, need to be converted, the official provided cnrtCastDataType to assist the conversion process.
::memcpy( inputCpuPtrS[i], _in_img.data, inputSizeS[i]);
cnrtMemcpy(inputMluPtrS[i], inputCpuPtrS[i], inputSizeS[i], CNRT_MEM_TRANS_DIR_HOST2DEV);
}
// The 10th step is image preprocessing, which transfers image data to the mlu.
// The eleventh step is to start setting up the reasoning parameters
// prepare parameters for cnrtInvokeRuntimeContext
void **param = (void **)malloc(sizeof(void *) * (inputNum + outputNum));
for (int i = 0; i < inputNum; ++i) {
param[i] = inputMluPtrS[i];
}
for (int i = 0; i < outputNum; ++i) {
param[inputNum + i] = outputMluPtrS[i];
}
// Step 12, Bind devices and set inference context
// setup runtime ctx
cnrtRuntimeContext_t ctx;
cnrtCreateRuntimeContext(&ctx, function, NULL);
// compute offline
cnrtQueue_t queue;
cnrtRuntimeContextCreateQueue(ctx, &queue);
// bind device
cnrtSetRuntimeContextDeviceId(ctx, 0);
cnrtInitRuntimeContext(ctx, NULL);
// Step 13, Reason and wait for the end of the reasoning.
// invoke
cnrtInvokeRuntimeContext(ctx, param, queue, NULL);
// sync
cnrtSyncQueue(queue);
// Step 14, copy the data back to the cpu from the mlu, and then post-process it
// copy mlu result to cpu
for (int i = 0; i < outputNum; i++) {
cnrtMemcpy(outputCpuPtrS[i], outputMluPtrS[i], outputSizeS[i], CNRT_MEM_TRANS_DIR_DEV2HOST);
}
// Step 15, Clean up the environment.
// free memory space
for (int i = 0; i < inputNum; i++) {
free(inputCpuPtrS[i]);
cnrtFree(inputMluPtrS[i]);
}
for (int i = 0; i < outputNum; i++) {
free(outputCpuPtrS[i]);
cnrtFree(outputMluPtrS[i]);
}
free(inputCpuPtrS);
free(outputCpuPtrS);
free(param);
cnrtDestroyQueue(queue);
cnrtDestroyRuntimeContext(ctx);
cnrtDestroyFunction(function);
cnrtUnloadModel(model);
cnrtDestroy();
return 0;
}
int main() {
printf("mlp offline test\n");
offline_test("mlp");
return 0;
}
Here is a brief list of the order in which EasyDK operates:
- The third and fourth steps above actually correspond to the ModelLoader module under EasyInfer. Initializing the ModelLoader module and passing it to the EasyInfer instance completes three or four or five steps. In fact, the previous content is in a fixed form, not the focus. The emphasis is on the following sections: data input, inference and data output.
- Steps 6,7,8,9 above are all about requesting memory space on the cpu and mlu for the model. The corresponding interface in EasyDk completes the memory request directly.
- Note that step 10 above is an important step, including image data preprocessing, image data type conversion, and image data input to mlu memory.
- Steps 11 and 12 above prepare parameters for reasoning
- Step 13 above to start reasoning
- Step 14 above copies the inference from the mlu memory to the cpu memory and postprocesses it.
- Step 15 above, Clean up the environment.
Deployment of offline model on ML220
_In the previous section, the main task is to complete the program development of offline model inference and run tests on MLU270. The main content of this section is how to deploy our tuned program to MLU220.
_Deploying to MLU220, the first problem we face is cross-compiling the program that generates AARCH64. There are three partial dependencies, CNToolkit-aarch64, easydk-aarch64, and other third-party libraries such as opencv-aarch64. At this point, we have an offline inference program for aarch64, which works with the offline model of the mlu220 version that we converted earlier.
_When we put the generated program on the mlu220 card, at this time, the program may still not be able to run, because the driver may not be loaded, at this time, it is recommended to find the driver and firmware to let the mlu220 run. Then run the program.
_Below is an example of error reporting without an mlu device:

Below is the last log of the load driver:

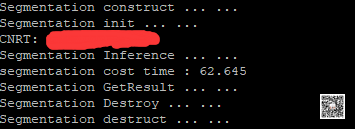
_Following is the output of the running program:
Postnote
_For RK3399pro and Cambrian MLU220 platforms, some long-term models may have a 300%+ performance improvement over RK3399pro due to the optimal comparison. However, for some new models and some non-classical (non-public) models, due to their own optimization or network structure, the performance may only be improved by 30%+, but this is also a pleasant thing, after all, many things can achieve quasi-real-time after hardware upgrade.
_This is the basic introduction of this series, the end of sprinkling ~~~~~.
Reference
- Guidelines for Fishing on Cambrian Accelerated Platform (MLU200 Series) (1) - Basic Concepts and Related Introduction (1) https://blog.csdn.net/u011728480/article/details/121194076 )
- Cambrian Accelerated Platform (MLU200 Series) Guidelines for Fishing (2) - Model Transplantation - Environment Building (2) https://blog.csdn.net/u011728480/article/details/121320982 )
- Cambrian Accelerated Platform (MLU200 Series) Guidelines for Fishing (3) - Model Transplantation-Split Network Instance (3) https://blog.csdn.net/u011728480/article/details/121456789 )
- https://www.cambricon.com/
- https://www.cambricon.com/docs/cnrt/user_guide_html/example/offline_mode.html
- Other relevant confidential information.

PS: Respect the original, do not spray.
PS: To reprint, please indicate the source. I have the copyright.
PS: Please leave a message if you have any questions and I will reply as soon as I see them.