Catalog
Preface
According to another article of mine: How to Beautify Photos, DPED Machine Learning Open Source Project Installation Use | Machine Learning_ Alan's Blog - CSDN Blog
The DPED project was found to require commanded execution and a picture catalog as the processing source. I still magically changed the project to simplify the project structure and incorporate it into a python code.
The model file is large, so I provide the download address, which can be downloaded to the corresponding directory of the project.
Github warehouse address: github address
Project Description
Project structure
Take a look at the structure of the project as follows:
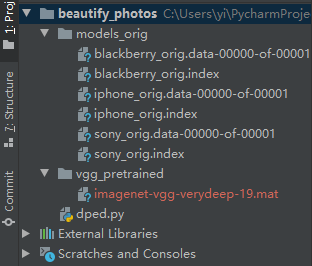
Where model file download address: https://pan.baidu.com/s/1IUm8xz5dhh8iW_bLWfihPQ Extraction Code: TUAN
Download imagenet-vgg-verydeep-19.mat and place it in vgg_ In the pretrained directory.
Environmental dependency can be directly referenced: Python implementation replaces photo character backgrounds, fine to hair (with code)|machine learning_ Alan's Blog - CSDN Blog
Data preparation
I have prepared a test chart as follows:

Magic Change Code
No crap, go to the core code.
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2021/11/27 13:48
# @Author: Swordsman Alan_ ALiang
# @Site :
# @File : dped.py
# python test_model.py model=iphone_orig dped_dir=dped/ test_subset=full
# iteration=all resolution=orig use_gpu=true
import imageio
from PIL import Image
import numpy as np
import tensorflow as tf
import os
import sys
import scipy.stats as st
import uuid
from functools import reduce
# ---------------------- hy add 2 ----------------------
def log10(x):
numerator = tf.compat.v1.log(x)
denominator = tf.compat.v1.log(tf.constant(10, dtype=numerator.dtype))
return numerator / denominator
def _tensor_size(tensor):
from operator import mul
return reduce(mul, (d.value for d in tensor.get_shape()[1:]), 1)
def gauss_kernel(kernlen=21, nsig=3, channels=1):
interval = (2 * nsig + 1.) / (kernlen)
x = np.linspace(-nsig - interval / 2., nsig + interval / 2., kernlen + 1)
kern1d = np.diff(st.norm.cdf(x))
kernel_raw = np.sqrt(np.outer(kern1d, kern1d))
kernel = kernel_raw / kernel_raw.sum()
out_filter = np.array(kernel, dtype=np.float32)
out_filter = out_filter.reshape((kernlen, kernlen, 1, 1))
out_filter = np.repeat(out_filter, channels, axis=2)
return out_filter
def blur(x):
kernel_var = gauss_kernel(21, 3, 3)
return tf.nn.depthwise_conv2d(x, kernel_var, [1, 1, 1, 1], padding='SAME')
def process_command_args(arguments):
# specifying default parameters
batch_size = 50
train_size = 30000
learning_rate = 5e-4
num_train_iters = 20000
w_content = 10
w_color = 0.5
w_texture = 1
w_tv = 2000
dped_dir = 'dped/'
vgg_dir = 'vgg_pretrained/imagenet-vgg-verydeep-19.mat'
eval_step = 1000
phone = ""
for args in arguments:
if args.startswith("model"):
phone = args.split("=")[1]
if args.startswith("batch_size"):
batch_size = int(args.split("=")[1])
if args.startswith("train_size"):
train_size = int(args.split("=")[1])
if args.startswith("learning_rate"):
learning_rate = float(args.split("=")[1])
if args.startswith("num_train_iters"):
num_train_iters = int(args.split("=")[1])
# -----------------------------------
if args.startswith("w_content"):
w_content = float(args.split("=")[1])
if args.startswith("w_color"):
w_color = float(args.split("=")[1])
if args.startswith("w_texture"):
w_texture = float(args.split("=")[1])
if args.startswith("w_tv"):
w_tv = float(args.split("=")[1])
# -----------------------------------
if args.startswith("dped_dir"):
dped_dir = args.split("=")[1]
if args.startswith("vgg_dir"):
vgg_dir = args.split("=")[1]
if args.startswith("eval_step"):
eval_step = int(args.split("=")[1])
if phone == "":
print("\nPlease specify the camera model by running the script with the following parameter:\n")
print("python train_model.py model={iphone,blackberry,sony}\n")
sys.exit()
if phone not in ["iphone", "sony", "blackberry"]:
print("\nPlease specify the correct camera model:\n")
print("python train_model.py model={iphone,blackberry,sony}\n")
sys.exit()
print("\nThe following parameters will be applied for CNN training:\n")
print("Phone model:", phone)
print("Batch size:", batch_size)
print("Learning rate:", learning_rate)
print("Training iterations:", str(num_train_iters))
print()
print("Content loss:", w_content)
print("Color loss:", w_color)
print("Texture loss:", w_texture)
print("Total variation loss:", str(w_tv))
print()
print("Path to DPED dataset:", dped_dir)
print("Path to VGG-19 network:", vgg_dir)
print("Evaluation step:", str(eval_step))
print()
return phone, batch_size, train_size, learning_rate, num_train_iters, \
w_content, w_color, w_texture, w_tv, \
dped_dir, vgg_dir, eval_step
def process_test_model_args(arguments):
phone = ""
dped_dir = 'dped/'
test_subset = "small"
iteration = "all"
resolution = "orig"
use_gpu = "true"
for args in arguments:
if args.startswith("model"):
phone = args.split("=")[1]
if args.startswith("dped_dir"):
dped_dir = args.split("=")[1]
if args.startswith("test_subset"):
test_subset = args.split("=")[1]
if args.startswith("iteration"):
iteration = args.split("=")[1]
if args.startswith("resolution"):
resolution = args.split("=")[1]
if args.startswith("use_gpu"):
use_gpu = args.split("=")[1]
if phone == "":
print("\nPlease specify the model by running the script with the following parameter:\n")
print(
"python test_model.py model={iphone,blackberry,sony,iphone_orig,blackberry_orig,sony_orig}\n")
sys.exit()
return phone, dped_dir, test_subset, iteration, resolution, use_gpu
def get_resolutions():
# IMAGE_HEIGHT, IMAGE_WIDTH
res_sizes = {}
res_sizes["iphone"] = [1536, 2048]
res_sizes["iphone_orig"] = [1536, 2048]
res_sizes["blackberry"] = [1560, 2080]
res_sizes["blackberry_orig"] = [1560, 2080]
res_sizes["sony"] = [1944, 2592]
res_sizes["sony_orig"] = [1944, 2592]
res_sizes["high"] = [1260, 1680]
res_sizes["medium"] = [1024, 1366]
res_sizes["small"] = [768, 1024]
res_sizes["tiny"] = [600, 800]
return res_sizes
def get_specified_res(res_sizes, phone, resolution):
if resolution == "orig":
IMAGE_HEIGHT = res_sizes[phone][0]
IMAGE_WIDTH = res_sizes[phone][1]
else:
IMAGE_HEIGHT = res_sizes[resolution][0]
IMAGE_WIDTH = res_sizes[resolution][1]
IMAGE_SIZE = IMAGE_WIDTH * IMAGE_HEIGHT * 3
return IMAGE_HEIGHT, IMAGE_WIDTH, IMAGE_SIZE
def extract_crop(image, resolution, phone, res_sizes):
if resolution == "orig":
return image
else:
x_up = int((res_sizes[phone][1] - res_sizes[resolution][1]) / 2)
y_up = int((res_sizes[phone][0] - res_sizes[resolution][0]) / 2)
x_down = x_up + res_sizes[resolution][1]
y_down = y_up + res_sizes[resolution][0]
return image[y_up: y_down, x_up: x_down, :]
# ---------------------- hy add 1 ----------------------
def resnet(input_image):
with tf.compat.v1.variable_scope("generator"):
W1 = weight_variable([9, 9, 3, 64], name="W1")
b1 = bias_variable([64], name="b1")
c1 = tf.nn.relu(conv2d(input_image, W1) + b1)
# residual 1
W2 = weight_variable([3, 3, 64, 64], name="W2")
b2 = bias_variable([64], name="b2")
c2 = tf.nn.relu(_instance_norm(conv2d(c1, W2) + b2))
W3 = weight_variable([3, 3, 64, 64], name="W3")
b3 = bias_variable([64], name="b3")
c3 = tf.nn.relu(_instance_norm(conv2d(c2, W3) + b3)) + c1
# residual 2
W4 = weight_variable([3, 3, 64, 64], name="W4")
b4 = bias_variable([64], name="b4")
c4 = tf.nn.relu(_instance_norm(conv2d(c3, W4) + b4))
W5 = weight_variable([3, 3, 64, 64], name="W5")
b5 = bias_variable([64], name="b5")
c5 = tf.nn.relu(_instance_norm(conv2d(c4, W5) + b5)) + c3
# residual 3
W6 = weight_variable([3, 3, 64, 64], name="W6")
b6 = bias_variable([64], name="b6")
c6 = tf.nn.relu(_instance_norm(conv2d(c5, W6) + b6))
W7 = weight_variable([3, 3, 64, 64], name="W7")
b7 = bias_variable([64], name="b7")
c7 = tf.nn.relu(_instance_norm(conv2d(c6, W7) + b7)) + c5
# residual 4
W8 = weight_variable([3, 3, 64, 64], name="W8")
b8 = bias_variable([64], name="b8")
c8 = tf.nn.relu(_instance_norm(conv2d(c7, W8) + b8))
W9 = weight_variable([3, 3, 64, 64], name="W9")
b9 = bias_variable([64], name="b9")
c9 = tf.nn.relu(_instance_norm(conv2d(c8, W9) + b9)) + c7
# Convolutional
W10 = weight_variable([3, 3, 64, 64], name="W10")
b10 = bias_variable([64], name="b10")
c10 = tf.nn.relu(conv2d(c9, W10) + b10)
W11 = weight_variable([3, 3, 64, 64], name="W11")
b11 = bias_variable([64], name="b11")
c11 = tf.nn.relu(conv2d(c10, W11) + b11)
# Final
W12 = weight_variable([9, 9, 64, 3], name="W12")
b12 = bias_variable([3], name="b12")
enhanced = tf.nn.tanh(conv2d(c11, W12) + b12) * 0.58 + 0.5
return enhanced
def adversarial(image_):
with tf.compat.v1.variable_scope("discriminator"):
conv1 = _conv_layer(image_, 48, 11, 4, batch_nn=False)
conv2 = _conv_layer(conv1, 128, 5, 2)
conv3 = _conv_layer(conv2, 192, 3, 1)
conv4 = _conv_layer(conv3, 192, 3, 1)
conv5 = _conv_layer(conv4, 128, 3, 2)
flat_size = 128 * 7 * 7
conv5_flat = tf.reshape(conv5, [-1, flat_size])
W_fc = tf.Variable(tf.compat.v1.truncated_normal(
[flat_size, 1024], stddev=0.01))
bias_fc = tf.Variable(tf.constant(0.01, shape=[1024]))
fc = leaky_relu(tf.matmul(conv5_flat, W_fc) + bias_fc)
W_out = tf.Variable(
tf.compat.v1.truncated_normal([1024, 2], stddev=0.01))
bias_out = tf.Variable(tf.constant(0.01, shape=[2]))
adv_out = tf.nn.softmax(tf.matmul(fc, W_out) + bias_out)
return adv_out
def weight_variable(shape, name):
initial = tf.compat.v1.truncated_normal(shape, stddev=0.01)
return tf.Variable(initial, name=name)
def bias_variable(shape, name):
initial = tf.constant(0.01, shape=shape)
return tf.Variable(initial, name=name)
def conv2d(x, W):
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
def leaky_relu(x, alpha=0.2):
return tf.maximum(alpha * x, x)
def _conv_layer(net, num_filters, filter_size, strides, batch_nn=True):
weights_init = _conv_init_vars(net, num_filters, filter_size)
strides_shape = [1, strides, strides, 1]
bias = tf.Variable(tf.constant(0.01, shape=[num_filters]))
net = tf.nn.conv2d(net, weights_init, strides_shape, padding='SAME') + bias
net = leaky_relu(net)
if batch_nn:
net = _instance_norm(net)
return net
def _instance_norm(net):
batch, rows, cols, channels = [i.value for i in net.get_shape()]
var_shape = [channels]
mu, sigma_sq = tf.compat.v1.nn.moments(net, [1, 2], keepdims=True)
shift = tf.Variable(tf.zeros(var_shape))
scale = tf.Variable(tf.ones(var_shape))
epsilon = 1e-3
normalized = (net - mu) / (sigma_sq + epsilon) ** (.5)
return scale * normalized + shift
def _conv_init_vars(net, out_channels, filter_size, transpose=False):
_, rows, cols, in_channels = [i.value for i in net.get_shape()]
if not transpose:
weights_shape = [filter_size, filter_size, in_channels, out_channels]
else:
weights_shape = [filter_size, filter_size, out_channels, in_channels]
weights_init = tf.Variable(
tf.compat.v1.truncated_normal(
weights_shape,
stddev=0.01,
seed=1),
dtype=tf.float32)
return weights_init
# ---------------------- hy add 0 ----------------------
def beautify(pic_path: str, output_dir: str, gpu='1'):
tf.compat.v1.disable_v2_behavior()
# process command arguments
phone = "iphone_orig"
test_subset = "full"
iteration = "all"
resolution = "orig"
# get all available image resolutions
res_sizes = get_resolutions()
# get the specified image resolution
IMAGE_HEIGHT, IMAGE_WIDTH, IMAGE_SIZE = get_specified_res(
res_sizes, phone, resolution)
if gpu == '1':
use_gpu = 'true'
else:
use_gpu = 'false'
# disable gpu if specified
config = tf.compat.v1.ConfigProto(
device_count={'GPU': 0}) if use_gpu == "false" else None
# create placeholders for input images
x_ = tf.compat.v1.placeholder(tf.float32, [None, IMAGE_SIZE])
x_image = tf.reshape(x_, [-1, IMAGE_HEIGHT, IMAGE_WIDTH, 3])
# generate enhanced image
enhanced = resnet(x_image)
with tf.compat.v1.Session(config=config) as sess:
# test_dir = dped_dir + phone.replace("_orig",
# "") + "/test_data/full_size_test_images/"
# test_photos = [f for f in os.listdir(
# test_dir) if os.path.isfile(test_dir + f)]
test_photos = [pic_path]
if test_subset == "small":
# use five first images only
test_photos = test_photos[0:5]
if phone.endswith("_orig"):
# load pre-trained model
saver = tf.compat.v1.train.Saver()
saver.restore(sess, "models_orig/" + phone)
for photo in test_photos:
# load training image and crop it if necessary
new_pic_name = uuid.uuid4()
print(
"Testing original " +
phone.replace(
"_orig",
"") +
" model, processing image " +
photo)
image = np.float16(np.array(
Image.fromarray(imageio.imread(photo)).resize([res_sizes[phone][1], res_sizes[phone][0]]))) / 255
image_crop = extract_crop(
image, resolution, phone, res_sizes)
image_crop_2d = np.reshape(image_crop, [1, IMAGE_SIZE])
# get enhanced image
enhanced_2d = sess.run(enhanced, feed_dict={x_: image_crop_2d})
enhanced_image = np.reshape(
enhanced_2d, [IMAGE_HEIGHT, IMAGE_WIDTH, 3])
before_after = np.hstack((image_crop, enhanced_image))
photo_name = photo.rsplit(".", 1)[0]
# save the results as .png images
# imageio.imwrite(
# "visual_results/" +
# phone +
# "_" +
# photo_name +
# "_enhanced.png",
# enhanced_image)
imageio.imwrite(os.path.join(output_dir, '{}.png'.format(new_pic_name)), enhanced_image)
# imageio.imwrite(
# "visual_results/" +
# phone +
# "_" +
# photo_name +
# "_before_after.png",
# before_after)
imageio.imwrite(os.path.join(output_dir, '{}_before_after.png'.format(new_pic_name)), before_after)
return os.path.join(output_dir, '{}.png'.format(new_pic_name))
else:
num_saved_models = int(len([f for f in os.listdir(
"models_orig/") if f.startswith(phone + "_iteration")]) / 2)
if iteration == "all":
iteration = np.arange(1, num_saved_models) * 1000
else:
iteration = [int(iteration)]
for i in iteration:
# load pre-trained model
saver = tf.compat.v1.train.Saver()
saver.restore(
sess,
"models_orig/" +
phone +
"_iteration_" +
str(i) +
".ckpt")
for photo in test_photos:
# load training image and crop it if necessary
new_pic_name = uuid.uuid4()
print("iteration " + str(i) + ", processing image " + photo)
image = np.float16(np.array(
Image.fromarray(imageio.imread(photo)).resize(
[res_sizes[phone][1], res_sizes[phone][0]]))) / 255
image_crop = extract_crop(
image, resolution, phone, res_sizes)
image_crop_2d = np.reshape(image_crop, [1, IMAGE_SIZE])
# get enhanced image
enhanced_2d = sess.run(enhanced, feed_dict={x_: image_crop_2d})
enhanced_image = np.reshape(
enhanced_2d, [IMAGE_HEIGHT, IMAGE_WIDTH, 3])
before_after = np.hstack((image_crop, enhanced_image))
photo_name = photo.rsplit(".", 1)[0]
# save the results as .png images
# imageio.imwrite(
# "visual_results/" +
# phone +
# "_" +
# photo_name +
# "_iteration_" +
# str(i) +
# "_enhanced.png",
# enhanced_image)
imageio.imwrite(os.path.join(output_dir, '{}.png'.format(new_pic_name)), enhanced_image)
# imageio.imwrite(
# "visual_results/" +
# phone +
# "_" +
# photo_name +
# "_iteration_" +
# str(i) +
# "_before_after.png",
# before_after)
imageio.imwrite(os.path.join(output_dir, '{}_before_after.png'.format(new_pic_name)), before_after)
return os.path.join(output_dir, '{}.png'.format(new_pic_name))
if __name__ == '__main__':
print(beautify('C:/Users/yi/Desktop/6.jpg', 'result/'))
Code Description
1. The beautify method has three parameters: picture address, output directory, and whether to use gpu (default).
2. The output pictures have two pictures. In order not to duplicate the file name, use uuid as the file name with a suffix of _ before_after is a comparison chart.
3. Documents are not checked and can be added if needed.
Verify the effect
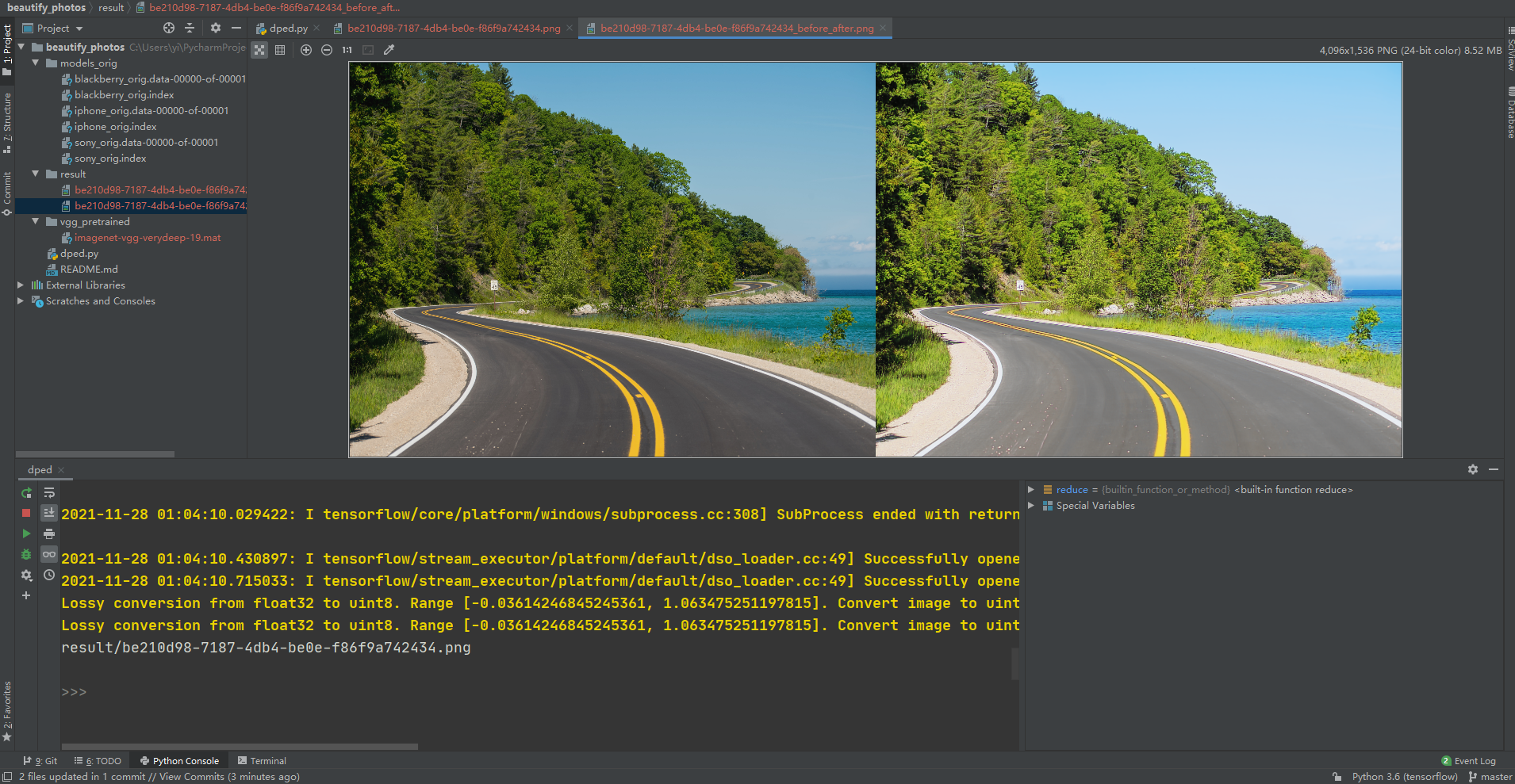
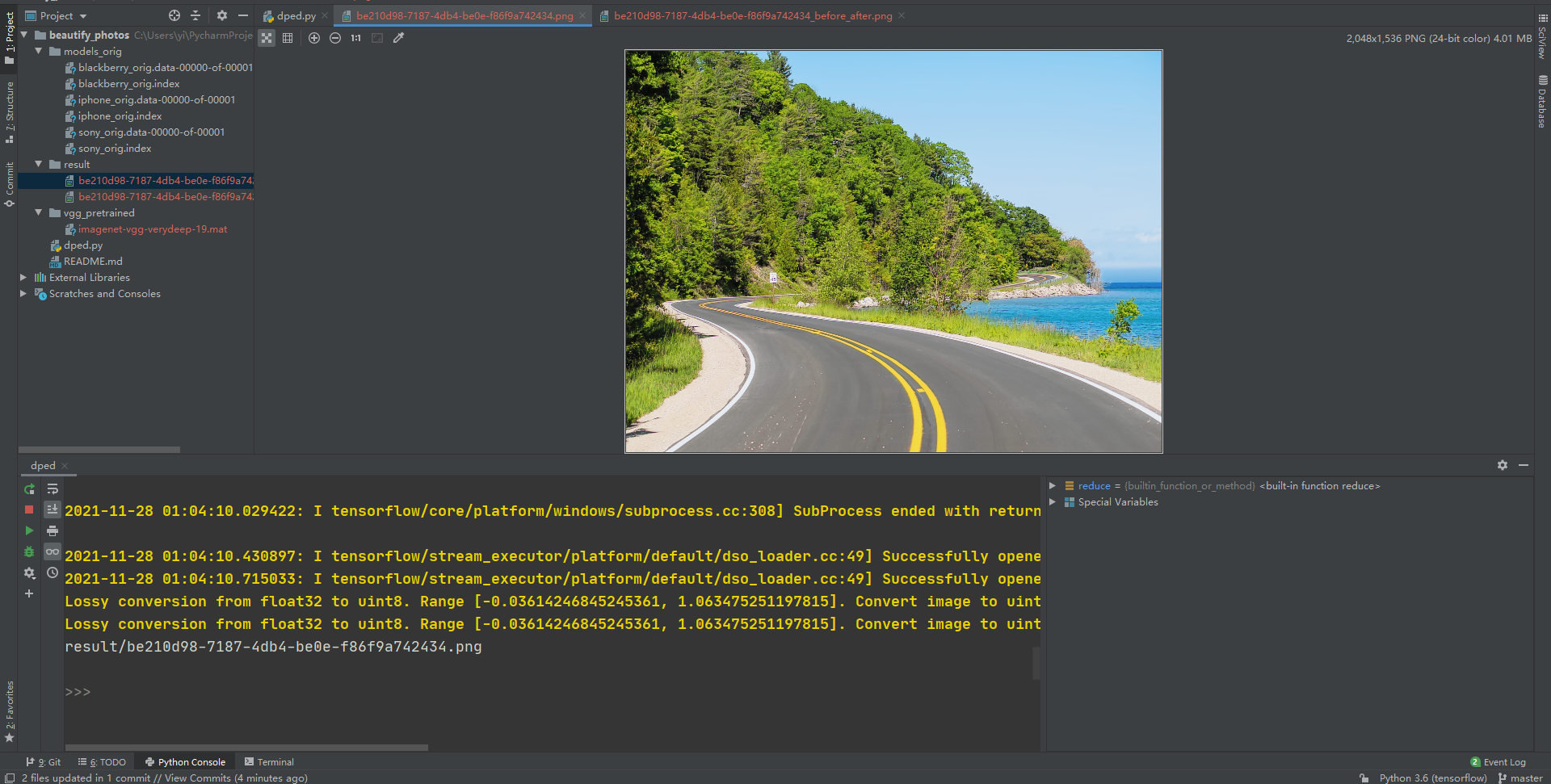
What about? It's gorgeous.
summary
It's still interesting to study this project, and recording and sharing is another joy. Before I thought I was a bright person, now I turn over my life in detail, more quiet and lonely. I used to read a quote from Marquez that on the way to old age, it is better to learn to enjoy loneliness than to resist it. So there's nothing bad about being alone. Immersing in another world of the program is another mood.
Share:
Life has never been lonely and independent. Whether we were born, we grew up, we loved each other, or we succeeded or failed, until the end loneliness existed in the corner of life like a shadow. Marquez
If this article is useful to you, please give it a compliment. Thank you.
