1, Foreword
recently, I encountered a thread blocking problem caused by log4j2 logging (thanks to the development brother's logging, otherwise there would be no following operations).
Give a general description of the situation at that time (due to the restriction of Intranet, we can't take out the on-site things, so we can only dictate):
log4j2 configuration: three rollingrandomaccessfiles are configured at the same time, respectively for SQL statement, INFO log and ERROR log. The general configuration is as follows:
<RollingRandomAccessFile name="RandomAccessFile" fileName="${FILE_PATH}/async-log4j2.log" append="false"
filePattern="${FILE_PATH}/rollings/async-testLog4j2-%d{yyyy-MM-dd}_%i.log.gz">
<PatternLayout>
<Pattern>${LOG_PATTERN}</Pattern>
</PatternLayout>
<ThresholdFilter level="info" onMatch="ACCEPT" onMismatch="DENY"/>
<Policies>
<TimeBasedTriggeringPolicy interval="1" modulate="true" />
<SizeBasedTriggeringPolicy size="450MB"/>
</Policies>
<DefaultRolloverStrategy max="15" compressionLevel="0"/>
</RollingRandomAccessFile>Problem Description: 1. The compressed log of 32C machine occupies 30% + of resources; 2. All 50% + of tomcat main threads are in park status, and the thread status is roughly as follows;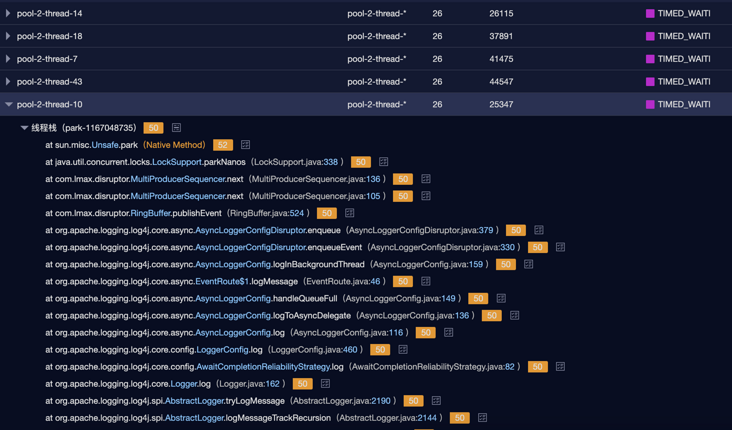
At that time, the optimization suggestions for log4j2 were: 1. Configure immediateflush = false. 2. Remove the gz suffix corresponding to filePattern (because the corresponding compressionLevel=0, it is not compressed at all). Will JDK's deflator not be called for compression. [guess, which is also one of the reasons for restoring the scene later. I want to verify it myself]
2, Local Reproduction & some source code learning
the process of problem recurrence is also very difficult, and we encounter all kinds of problems. The following records the problems and solutions I encountered during local replication, with some log4j2 source code learning based on the disruptor, which may be a little longer.
Environment: Macbook Pro x86 (16C32G), jdk1.8, log4j core 2.12.1, log4j API 2.12.1, disruptor 3.4.2
Test code (start 50 threads to write logs continuously [the field system involves 200 Tomcat threads]):
public class TestLog4j {
private static Logger logger = LogManager.getLogger(TestLog4j.class);
private final ThreadPoolExecutor executor;
public TestLog4j() {
this.executor = new ThreadPoolExecutor(50, 50,
60, TimeUnit.SECONDS,
new ArrayBlockingQueue(1000),
Executors.defaultThreadFactory(),
new ThreadPoolExecutor.AbortPolicy());
}
public void testLog() {
for (int i = 0; i < this.executor.getCorePoolSize(); i++) {
this.executor.execute(() -> {
while (true) {
logger.info("Test log--Quickly block--Quickly block--Quickly block--Quickly block" +
"--Quickly block--Quickly block--Quickly block--Quickly block--Quickly block" +
"--Quickly block--Quickly block--Quickly block--Quickly block--Quickly block");
}
});
}
}
public static void main(String[] args) {
new TestLog4j().testLog();
}
}Partial log4j2.xml configuration (reduce the backup compressed log size to 100M and increase the number of backup files to 100):
<appenders>
<RollingRandomAccessFile name="RandomAccessFile" fileName="${FILE_PATH}/async-log4j2.log" append="false"
filePattern="${FILE_PATH}/rollings/async-testLog4j2-%d{yyyy-MM-dd}_%i.log.gz">
<PatternLayout>
<Pattern>${LOG_PATTERN}</Pattern>
</PatternLayout>
<ThresholdFilter level="info" onMatch="ACCEPT" onMismatch="DENY"/>
<Policies>
<TimeBasedTriggeringPolicy interval="1" modulate="true" />
<SizeBasedTriggeringPolicy size="100MB"/>
</Policies>
<DefaultRolloverStrategy max="100" compressionLevel="0"/>
</RollingRandomAccessFile>
</appenders>
<loggers>
<!--disruptor Asynchronous log-->
<AsyncLogger name="DisruptorLogger" level="info" includeLocation="false">
<AppenderRef ref="RandomAccessFile"/>
</AsyncLogger>
<Asyncroot level="info" includeLocation="false">
<appender-ref ref="RandomAccessFile"/>
</Asyncroot>
</loggers>(1) Thread Blocked
everything is ready, click Run, jps+jstack+jmap, full of confidence. The moment I opened thread dump, I was stunned. It was red blocked. At this time, I should have a question mark face. The thread situation is as follows: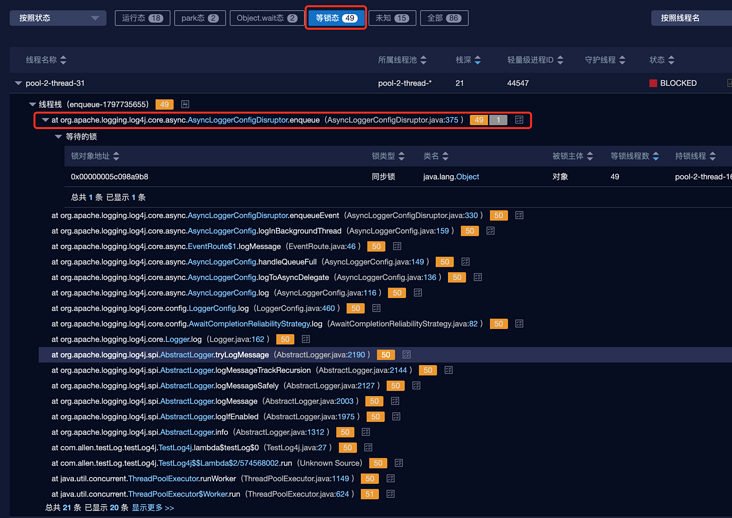
It feels a little worse than expected. It seems that it is blocked when writing logs to the RingBuffer of the disruptor. You can compare the threads of previous threads. It is not blocked. It seems that something different has been found in the memory dump: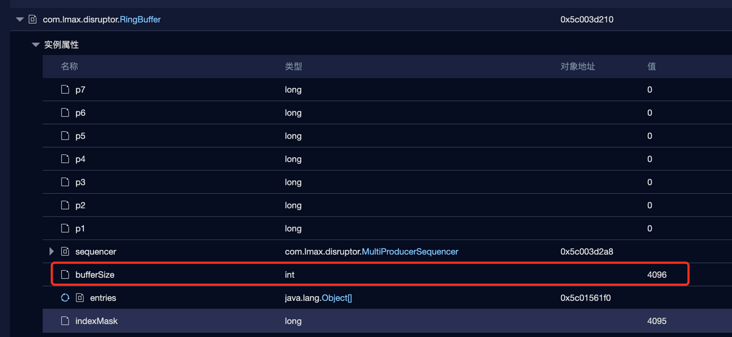
RingBuffer is only 4096. If it is not set in the impression, it is 256 * 1024 by default.
(1) RingBuffer size
many configuration attributes related to the DisruptorUtil class are defined in the org.apache.logging.log4j.core.async package.
There are three static properties of RingBuffer size and a method to get RingBuffer size calculateringbuffer size.
// DisruptorUtil class
private static final int RINGBUFFER_MIN_SIZE = 128;
private static final int RINGBUFFER_DEFAULT_SIZE = 256 * 1024;
private static final int RINGBUFFER_NO_GC_DEFAULT_SIZE = 4 * 1024;
static int calculateRingBufferSize(final String propertyName) {
// If enable_ If threadlocations is true, ringbuffer is used_ NO_ GC_ DEFAULT_ Size is the size of 4096
int ringBufferSize = Constants.ENABLE_THREADLOCALS ? RINGBUFFER_NO_GC_DEFAULT_SIZE : RINGBUFFER_DEFAULT_SIZE;
// Get the self-defined configuration size in the configuration file. If the above ringBufferSize is not returned
final String userPreferredRBSize = PropertiesUtil.getProperties().getStringProperty(propertyName,
String.valueOf(ringBufferSize));
try {
int size = Integer.parseInt(userPreferredRBSize);
// If the custom configuration size is less than 128, re assign the size to 128
if (size < RINGBUFFER_MIN_SIZE) {
size = RINGBUFFER_MIN_SIZE;
LOGGER.warn("Invalid RingBufferSize {}, using minimum size {}.", userPreferredRBSize,
RINGBUFFER_MIN_SIZE);
}
// Reassign the custom configuration size to ringBufferSize
ringBufferSize = size;
} catch (final Exception ex) {
LOGGER.warn("Invalid RingBufferSize {}, using default size {}.", userPreferredRBSize, ringBufferSize);
}
return Integers.ceilingNextPowerOfTwo(ringBufferSize);
}Then look at constants.enable_ Threadlocations tells the truth:
/**
* {@code true} if we think we are running in a web container, based on the boolean value of system property
* "log4j2.is.webapp", or (if this system property is not set) whether the {@code javax.servlet.Servlet} class
* is present in the classpath.
*/
public static final boolean IS_WEB_APP = PropertiesUtil.getProperties().getBooleanProperty(
"log4j2.is.webapp", isClassAvailable("javax.servlet.Servlet"));
/**
* Kill switch for object pooling in ThreadLocals that enables much of the LOG4J2-1270 no-GC behaviour.
* <p>
* {@code True} for non-{@link #IS_WEB_APP web apps}, disable by setting system property
* "log4j2.enable.threadlocals" to "false".
* </p>
*/
public static final boolean ENABLE_THREADLOCALS = !IS_WEB_APP && PropertiesUtil.getProperties().getBooleanProperty(
"log4j2.enable.threadlocals", true);Roughly speaking, if the application is not a web application [judge whether there is a javax.servlet.Servlet class], the threadlocals mode is used by default, that is, the RingBuffer of my local program is set to 4096.
It is also mentioned in the comments that you can set the jvm runtime parameters instead of using the mode of threadlocales, which can be set as follows: - dlog4j2. Enable. Threadlocales = false
Garbage-free logging
- Most log frameworks, including log4j, create temporary objects (log event objects, Strings, char arrays, byte arrays...) during normal log output, which will increase the pressure of GC;
- Starting from Log4j2.6, log4j uses garbage free mode by default. threadlocals is one of the implementations of garbage free. Based on ThreadLocal, objects (such as log event objects) will be reused;
- However, in web applications, threadlocals mode can easily lead to memory leakage of ThreadLocal, so threadlocals mode will not be used in web applications;
Some incomplete garbage free functions do not rely on ThreadLocal. They will convert the log events object into text, and then directly encode text into bytes and store it in the reusable byte buffer. There is no need to create zero time Strings, char arrays and byte arrays.
- The above functions start by default (log4j2.enableDirectEncoders is true by default). In a multi-threaded environment, the log performance may not be ideal because the shared buffer is used for synchronous operation. Therefore, considering performance, it is recommended to use asynchronous logging.
reference resources: https://logging.apache.org/lo...,Garbage-free Logging
(2) Blocking core method enqueue
enqueue method of main blocking point org.apache.logging.log4j.core.async.AsyncLoggerConfigDisruptor
private void enqueue(final LogEvent logEvent, final AsyncLoggerConfig asyncLoggerConfig) {
// If synchronizeenqueuewhenquefull is true, enter the blocking method
if (synchronizeEnqueueWhenQueueFull()) {
synchronized (queueFullEnqueueLock) {
disruptor.getRingBuffer().publishEvent(translator, logEvent, asyncLoggerConfig);
}
} else {
disruptor.getRingBuffer().publishEvent(translator, logEvent, asyncLoggerConfig);
}
}
private boolean synchronizeEnqueueWhenQueueFull() {
return DisruptorUtil.ASYNC_CONFIG_SYNCHRONIZE_ENQUEUE_WHEN_QUEUE_FULL
// Background thread must never block
&& backgroundThreadId != Thread.currentThread().getId();
}About synchronize in DisruptorUtil_ ENQUEUE_ WHEN_ QUEUE_ Two static properties of full:
// The default is true
static final boolean ASYNC_LOGGER_SYNCHRONIZE_ENQUEUE_WHEN_QUEUE_FULL = PropertiesUtil.getProperties()
.getBooleanProperty("AsyncLogger.SynchronizeEnqueueWhenQueueFull", true);
static final boolean ASYNC_CONFIG_SYNCHRONIZE_ENQUEUE_WHEN_QUEUE_FULL = PropertiesUtil.getProperties()
.getBooleanProperty("AsyncLoggerConfig.SynchronizeEnqueueWhenQueueFull", true);As can be seen from the source code, the default enqueue method is to take the blocked branch code. If you want to set the non blocking operation mode, you need to manually configure the parameters as follows:
Create a new log4j2.component.properties file and add the following configuration:
[for other configurable parameters, see: https://logging.apache.org/lo...]
# Applicable to < root > and < logger > plus # Dlog4j2.contextSelector=org.apache.logging.log4j.core.async.AsyncLoggerContextSelector configured asynchronous log # Works on org.apache.logging.log4j.core.async.AsyncLoggerDisruptor AsyncLogger.SynchronizeEnqueueWhenQueueFull=false # Applicable to asynchronous logs configured by < asyncroot > & < asynclogger > # It works on org.apache.logging.log4j.core.async.AsyncLoggerConfigDisruptor AsyncLoggerConfig.SynchronizeEnqueueWhenQueueFull=false
note:
- Different processing classes (AsyncLoggerConfigDisruptor | AsyncLoggerDisruptor) will be used if the asynchronous log configuration methods are different, so the configuration parameters must match;
Setting synchronizeenqueuewhenquefull to false will lead to a surge in CPU utilization, which should also be the reason why it is set to true by default. You can see the results of the local experiment below, which is almost 10 times the gap. [setting false is not recommended in the official document unless the CPU core is bound.]
- CPU usage when true:
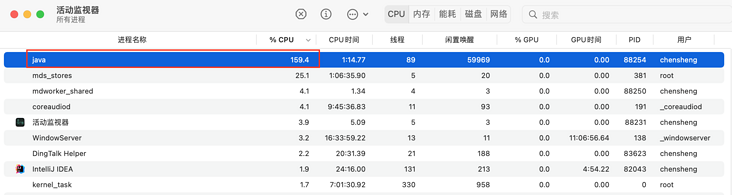
- CPU usage when false:
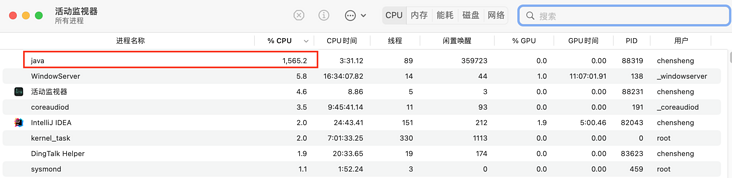
- CPU usage when true:
- Main reasons for high CPU:
When there is no blocking at enqueue method, all threads will enter the next method of MultiProducerSequencer. This method is to obtain the writable interval of RingBuffer. There is a while loop in the method to continuously perform CAS operations. At LockSupport.parkNanos(1), the original author also asked whether to use the waiting strategy of WaitStrategy.
@Override public long next(int n) { if (n < 1) { throw new IllegalArgumentException("n must be > 0"); } long current; long next; do { current = cursor.get(); next = current + n; long wrapPoint = next - bufferSize; long cachedGatingSequence = gatingSequenceCache.get(); if (wrapPoint > cachedGatingSequence || cachedGatingSequence > current) { long gatingSequence = Util.getMinimumSequence(gatingSequences, current); if (wrapPoint > gatingSequence) { LockSupport.parkNanos(1); // TODO, should we spin based on the wait strategy? continue; } gatingSequenceCache.set(gatingSequence); } else if (cursor.compareAndSet(current, next)) { break; } } while (true); return next; }
So far, the situation of the site has been basically restored: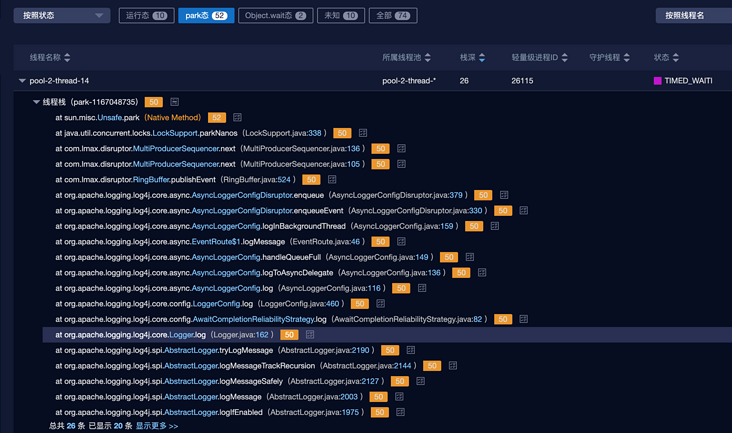
(3) Asynchronous log duplicate configuration problem
this is a personal curiosity. The Log4jContextSelector=org.apache.logging.log4j.core.async.AsyncLoggerContextSelector is used immediately, and the < asyncroot > tag is configured in log4j2.xml. The log object will be passed in the middle again:
app -> RingBuffer-1 -> thread a -> RingBuffer-2 -> thread b -> disk.
This results in unnecessary performance loss.
(2) Log compression
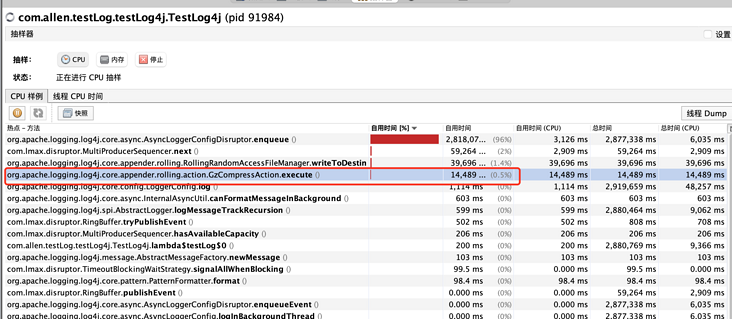
Try to remove the gz suffix and optimize the resource consumption of compression.
- Before modifying the CPU sampling, you can clearly see the compression related methods in the front row of resource occupation:
- Remove gz suffix and compression level parameter, and no compression related method can be found:
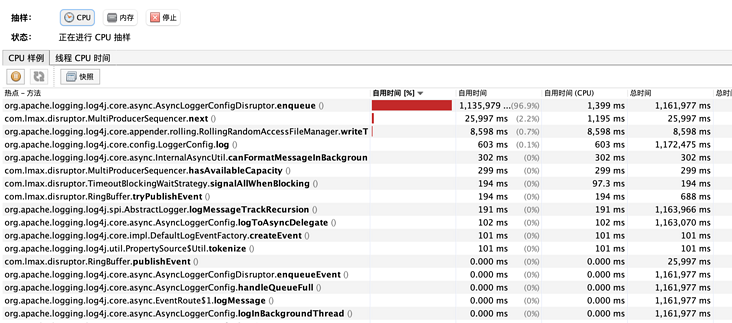
Verified the previous conjecture, RollingFile actually determines whether to compress according to the file suffix.
(3) WaitStrategy of consuming thread (IO thread)
log4j2.asyncLoggerWaitStrategy and log4j2.asyncLoggerConfigWaitStrategy are mainly used to configure the policy of I/O threads waiting for log events.
Four strategies are given in the official documents: Block, Timeout, default, sleep and yield.
But there are actually five kinds of source code:
// org.apache.logging.log4j.core.async.DisruptorUtil
static WaitStrategy createWaitStrategy(final String propertyName, final long timeoutMillis) {
final String strategy = PropertiesUtil.getProperties().getStringProperty(propertyName, "TIMEOUT");
LOGGER.trace("property {}={}", propertyName, strategy);
final String strategyUp = strategy.toUpperCase(Locale.ROOT); // TODO Refactor into Strings.toRootUpperCase(String)
switch (strategyUp) { // TODO Define a DisruptorWaitStrategy enum?
case "SLEEP":
return new SleepingWaitStrategy();
case "YIELD":
return new YieldingWaitStrategy();
case "BLOCK":
return new BlockingWaitStrategy();
case "BUSYSPIN":
return new BusySpinWaitStrategy();
case "TIMEOUT":
return new TimeoutBlockingWaitStrategy(timeoutMillis, TimeUnit.MILLISECONDS);
default:
return new TimeoutBlockingWaitStrategy(timeoutMillis, TimeUnit.MILLISECONDS);
}
}With the addition of a BusySpinWaitStrategy strategy, "JDK9 is really applicable. The following 9 is a simple dead cycle."
I will not introduce them one by one here, but mainly the contents related to disruptor. "For details, please refer to this article, and you can also write: https://blog.csdn.net/boling_... "In combination with log4j2:
- The default TimeoutBlockingWaitStrategy and BlockingWaitStrategy policies are implemented based on ReentrantLock. Because the bottom layer is based on AQS, AQS Node objects will be created during operation, which is not in line with the idea of garbage free;
- SLEEP is garbage free, and the official documents mention that compared with BLOCK, which is suitable for resource constrained environments, SLEEP balances performance and CPU resources.
3, Summary
for the performance optimization of log4j2, the following points are summarized: "there will be supplements later, which will be added here."
- When configuring the rolling log, if you do not need to compress the log, the file name of filePattern should not end with gz;
- When using the Disruptor asynchronous log, do not use Log4jContextSelector=org.apache.logging.log4j.core.async.AsyncLoggerContextSelector and < asyncroot >;
- Configure the immediateFlush="false" attribute of RollingRandomAccessFile to allow I/O threads to brush disks in batches (this actually involves the performance of native method calls);
- Whether to configure synchronizeenqueuewhenquefull to false according to the resource situation;
- Whether to change the WaitStrategy of I/O thread according to the actual situation;
- If the logs can be discarded, you can configure the discard policy, log4j2.asyncQueueFullPolicy=Discard, log4j2.discardThreshold=INFO "default". When the queue is full, the logs at INFO, DEBUG and TRACE levels will be discarded;