I haven't finished my work for a long time, tiezi. Recently, I saw a picture in a website called Meibao. Um ~ you know, hehe hehe
Don't ask why the subsequent pictures are coded. If you don't code, you can't pass the examination, brother
Meibao.com - beauty photo, beauty model private house photo network (abwzhuan.com) http://www.abwzhuan.com/ First, let's analyze the target website, and then find that as long as you call out the debugging window, there will be an infinite debugger loop. This is a bad website to analyze. Just click the blue arrow and you will jump here indefinitely, and then you won't load the data
http://www.abwzhuan.com/ First, let's analyze the target website, and then find that as long as you call out the debugging window, there will be an infinite debugger loop. This is a bad website to analyze. Just click the blue arrow and you will jump here indefinitely, and then you won't load the data
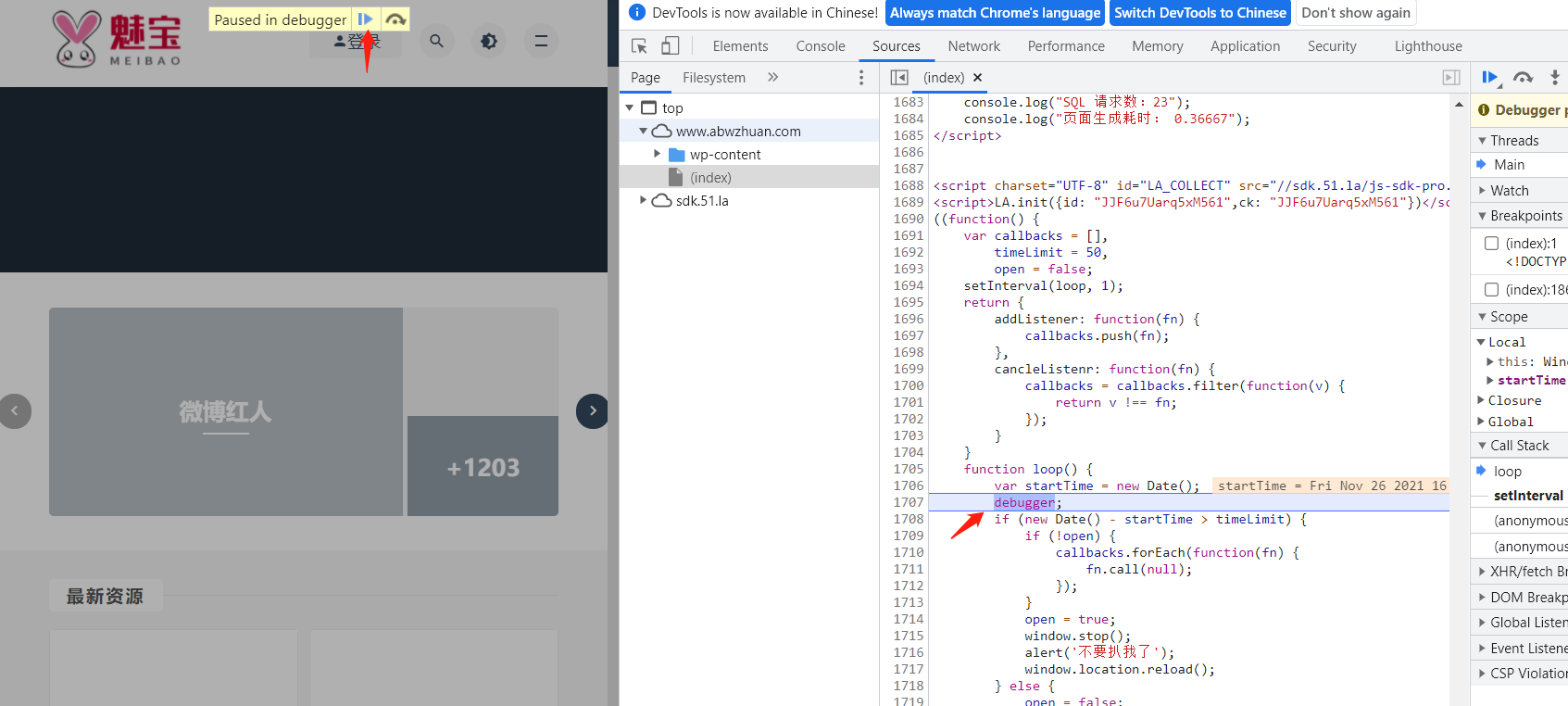
For this processing method, let's try the first one. Right click the number on the left of the debugger line and select the one indicated by the arrow, which means that the breakpoint will never be here. After testing and clicking, we can click the blue arrow to debug the website normally, and it will not appear
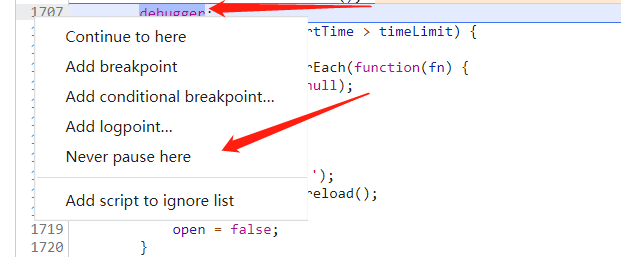
The second method is to click this button and an input box will pop up. Enter false in the input box and press enter. After clicking the blue arrow, we can debug the website normally
The above two methods are not applicable to all websites. If other websites are not applicable, we will use Fiddler to capture the package and rewrite the file before returning it to the browser. I will write a separate article on how to capture the package and rewrite it in a few days
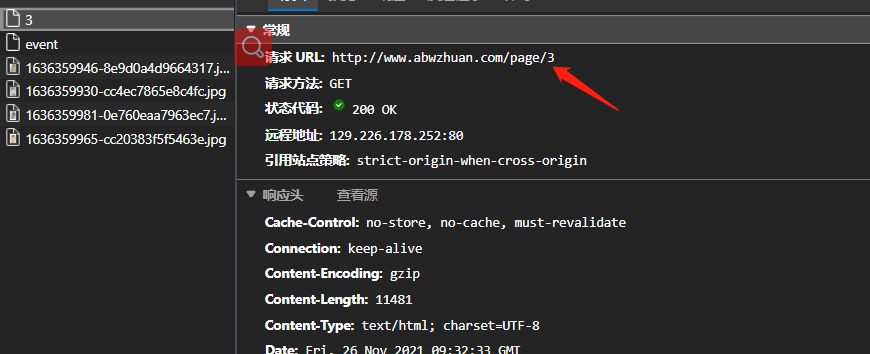
There's no big problem here. Start normal analysis of the website. You can see that the picture details page is in
//div[@class="placeholder"]/a/@href
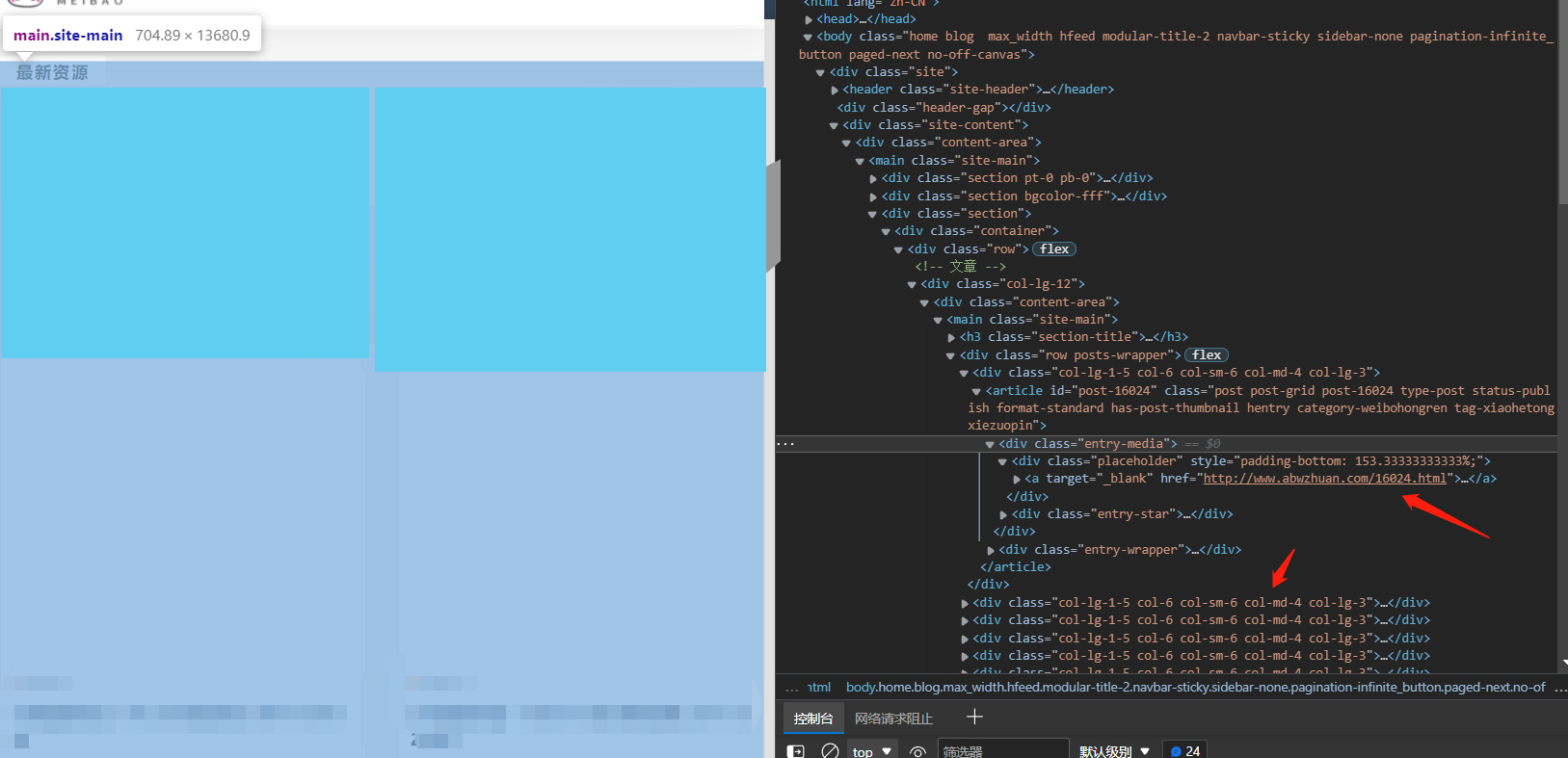 Verify with xpath that there is no problem
Verify with xpath that there is no problem

So what if I climb to the next page after this page is taken? You can see that you need to click this button, and there is no change in the website after clicking. This is also a front-end and back-end interactive website
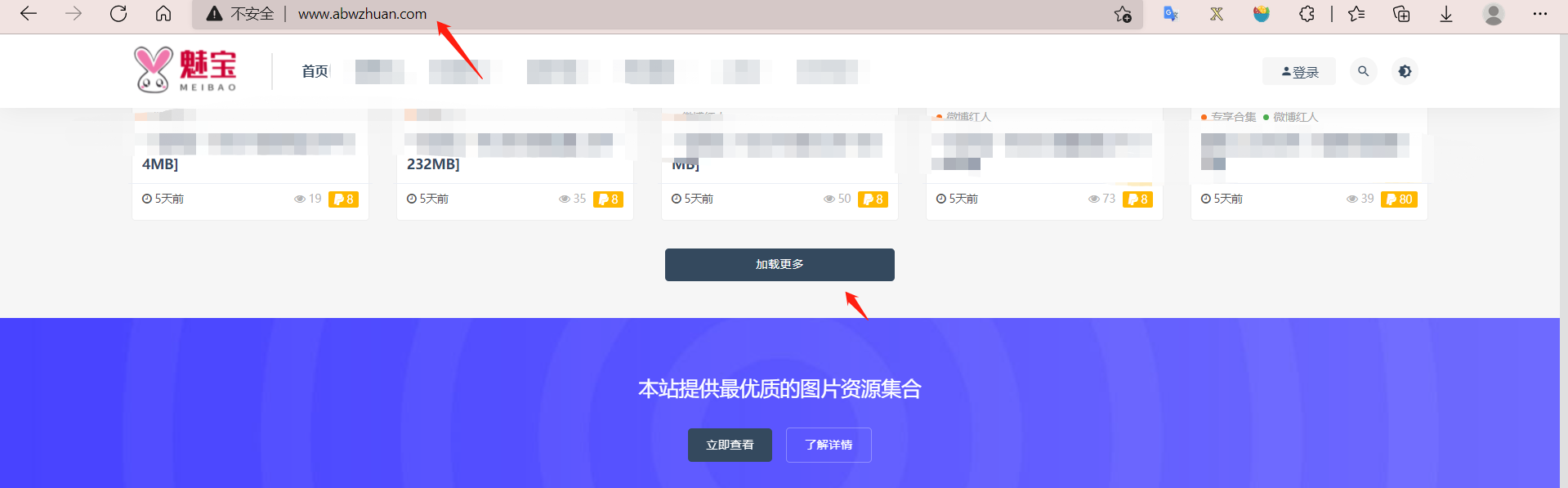
Let's analyze that one more such file will be loaded each time Only the number in page / {} changes. This is probably a page turning file. We only need to construct the number at the end to achieve the effect of page turning
Let's write the previous code and forge a header. Remember to pass in a cookie. Some websites will identify the identity information and also pass in a Referer. This is to mark where you come from. If you don't have these parameters, you may fail to download the picture later. I also added the Host for insurance. In addition, don't remove the randomly suspended code in order to download quickly, After all, if you crawl too fast and collapse other people's websites, you have to go to the Bureau for tea~
import requests
import random #Random module
from lxml import etree
import time
UserAgents = ['This stores your request header']
user_agent = random.choice(UserAgents) # Use random request header
headers = {'User-Agent': user_agent,
'Cookie':'X_CACHE_KEY=292b6a4a0ebc1a4c227ee50e14c4cef0; __51vcke__JJF6u7Uarq5xM561=ec59775c-bbab-569e-b893-3d73dcc37223; __51vuft__JJF6u7Uarq5xM561=1637834687423; cao_notice_cookie=1; __51uvsct__JJF6u7Uarq5xM561=2; PHPSESSID=316mo0fl1u3h59e8f8m393kapv; __vtins__JJF6u7Uarq5xM561=%7B%22sid%22%3A%20%227db4ef0d-7bde-56d3-821a-7508134d21bc%22%2C%20%22vd%22%3A%2016%2C%20%22stt%22%3A%201180142%2C%20%22dr%22%3A%20229714%2C%20%22expires%22%3A%201637849029367%2C%20%22ct%22%3A%201637847229367%7D',
'Referer':'http://www.abwzhuan.com/siwameinv',
'Host':'www.abwzhuan.com'
}
def page_url(url):
response = requests.get(url, headers=headers)
# print(response.text)
# print('====='*40)
# text = response.text
content = response.content.decode('utf8')
# Parsing html strings
html = etree.HTML(content)
detail_urls=html.xpath('//div[@class="placeholder"]/a/@href ') # details page url
for detail_url in detail_urls:
# print(detail_url)
jiexi(detail_url) #Here, I define a jiexi function loop to parse the returned position details page
time.sleep(random.uniform(1, 3)) #Random pause
if __name__ == '__main__':
for x in range(1,16): #Enter the number of pages you want to crawl. There are left packets and no packets in python, that is, if it is 1-16, it actually gets 1-15 pages
url='http://www.abwzhuan.com/cosplay/page/{}'.format(x)
page_url(url)
You can see that it is under this tab. Let's write a function to parse the details page
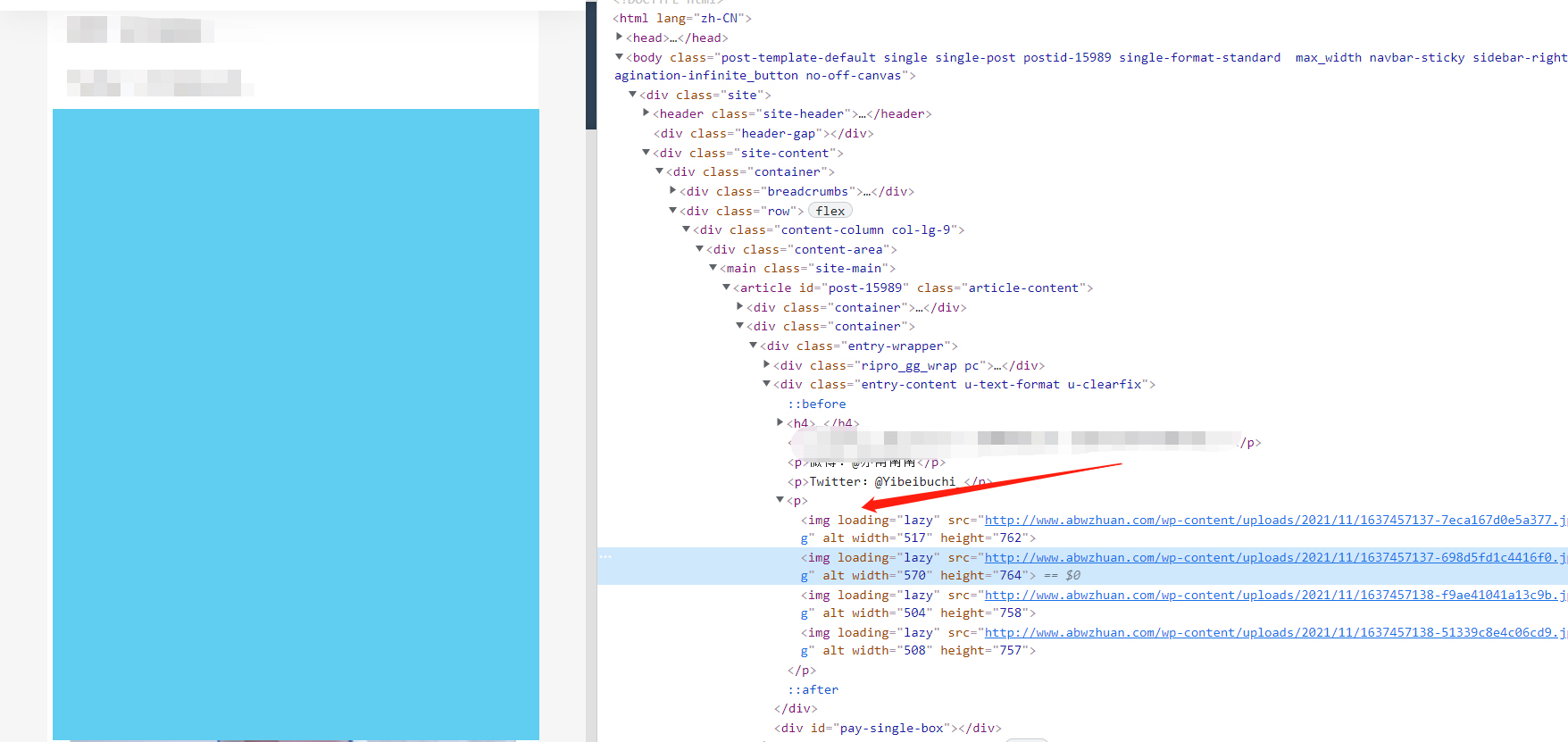
No matter downloading pictures or writing anything, remember to use try to run, otherwise if there is an unexpected error, you have to get it from the beginning, because this program is not an incremental crawler. If you report an error, you will not get it before crawling. When you have time, I will write a phase of incremental crawler
count=0
def jiexi(url):
response = requests.get(url, headers=headers)
content = response.content.decode('utf8')
# Parsing html strings
html = etree.HTML(content)
imgs=html.xpath('//p/img[@loading="lazy"]/@src ') # get picture url
# print(imgs)
try:
for img in imgs:
image_content = requests.get(img).content # After obtaining, de transcoding to binary
global count # Here we need to declare that it is a global variable, otherwise sometimes it will report an error and say that it has been assigned in advance
with open("Write the location of the folder you created here/{}.jpg".format(count), "wb") as f:
f.write(image_content)
count = count + 1
print("Successfully downloaded page{}Picture!".format(count))
except:
print('There is something wrong with this picture'+img)Sure enough!! There was a problem with a picture while running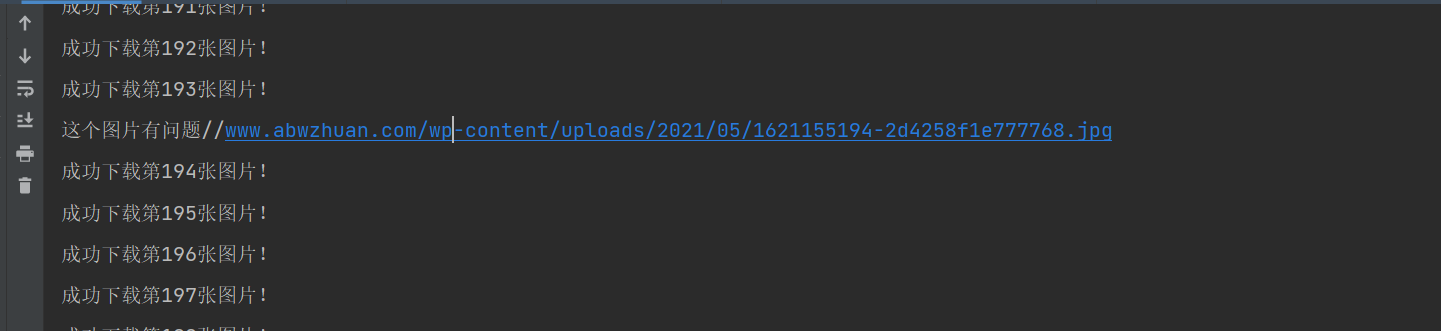
Finally, I got 1099 pictures
The full source code is as follows
import requests
import random #Random module
from lxml import etree
import time
UserAgents = ['This stores your request header']
user_agent = random.choice(UserAgents) # Use random request header
headers = {'User-Agent': user_agent,
'Cookie':'X_CACHE_KEY=292b6a4a0ebc1a4c227ee50e14c4cef0; __51vcke__JJF6u7Uarq5xM561=ec59775c-bbab-569e-b893-3d73dcc37223; __51vuft__JJF6u7Uarq5xM561=1637834687423; cao_notice_cookie=1; __51uvsct__JJF6u7Uarq5xM561=2; PHPSESSID=316mo0fl1u3h59e8f8m393kapv; __vtins__JJF6u7Uarq5xM561=%7B%22sid%22%3A%20%227db4ef0d-7bde-56d3-821a-7508134d21bc%22%2C%20%22vd%22%3A%2016%2C%20%22stt%22%3A%201180142%2C%20%22dr%22%3A%20229714%2C%20%22expires%22%3A%201637849029367%2C%20%22ct%22%3A%201637847229367%7D',
'Referer':'http://www.abwzhuan.com/siwameinv',
'Host':'www.abwzhuan.com'
}
def page_url(url):
response = requests.get(url, headers=headers)
# print(response.text)
# print('====='*40)
# text = response.text
content = response.content.decode('utf8')
# Parsing html strings
html = etree.HTML(content)
detail_urls=html.xpath('//div[@class="placeholder"]/a/@href')
for detail_url in detail_urls:
# print(detail_url)
jiexi(detail_url) #Cycle to parse the returned position details page
time.sleep(random.uniform(1, 3)) #Random pause
count=0
def jiexi(url):
response = requests.get(url, headers=headers)
content = response.content.decode('utf8')
# Parsing html strings
html = etree.HTML(content)
imgs=html.xpath('//p/img[@loading="lazy"]/@src')
# print(imgs)
try:
for img in imgs:
image_content = requests.get(img).content # Request after obtaining
global count # Here we need to declare that it is a global variable, otherwise sometimes it will report an error and say that it has been assigned in advance
with open("F:\Written reptile\Various usages\Meitu\cosplay/{}.jpg".format(count), "wb") as f:
f.write(image_content)
count = count + 1
print("Successfully downloaded page{}Picture!".format(count))
except:
print('There is something wrong with this picture'+img)
if __name__ == '__main__':
for x in range(1,16):
url='http://www.abwzhuan.com/cosplay/page/{}'.format(x)
page_url(url)
By the way, there's another thing ~ after reading it, if you think it's OK, please praise it. Don't whore in vain
So far, the program has been written
statement
This article is limited to technical exchange and learning. Please do not use it for any illegal purpose!