#Author introduction
Jiang Pengcheng, Suzhou wandianzhang Software Technology Co., Ltd
preface
CloudCanal recently provided the ability to build a wide table with custom code. We participated in the internal test of this feature for the first time, and it has been put into production and operated stably. See the official documents for the development process CloudCanal custom code real time processing.
Capability characteristics include:
- It is flexible and supports anti query and wide table printing, specific logic data cleaning, reconciliation, alarm and other scenarios
- Debugging is convenient. The debug port is automatically opened through task parameter configuration to interface with IDE debugging
- The SDK interface is clear and provides rich context information to facilitate data logic development
Based on the actual needs of our business (MySQL - > elasticsearch wide table construction), this paper combs the specific development and debugging process, hoping to be helpful to you.
Use case
Case 1: row construction of commodity table and SKU wide table
Business background
The following capabilities are required when conducting commodity search with the user's applet
- Full text index based on word segmentation
- Search fields in different tables at the same time
The original intention of full-text indexing is that users can search the desired goods by searching the keywords of goods. This is generally weak or even not supported in traditional databases, so it needs to search with the help of ES word splitter.
The second capability is mainly due to the fact that business data is usually distributed in multiple tables, but ES can not associate table queries like relational databases. The ability of CloudCanal user-defined code solves the pain point of multi table Association.
operation flow
The overall process of using CloudCanal becomes very clear. At the CloudCanal level, wide table rows that can be written to the peer ES can be directly generated by subscribing to the table combined with the anti query database and data processing in the user-defined code.
Table structure
The prepared mysql table structure is as follows. A commodity will correspond to multiple SKUs. We create an index on the opposite end, including SKUs_ Detail saves the SKU information associated with a commodity, which is a typical one to many scenario.
The fields in ES mapping correspond to the main table tb_ enterprise_ In the fields of goods, add an additional SKU_ The detail field is TB from the sub table_ enterprise_ Synchronized data in sku.
## Commodity list CREATE TABLE `tb_enterprise_goods` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(64) NOT NULL DEFAULT '' COMMENT 'Trade name', `enterprise_id` int(11) NOT NULL DEFAULT '0' COMMENT 'enterprise id', `goods_no` varchar(50) NOT NULL DEFAULT '' COMMENT 'Merchant commodity number', PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=9410 DEFAULT CHARSET=utf8mb4;
## SKU table
CREATE TABLE `tb_enterprise_sku` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`enterprise_goods_id` int(11) NOT NULL COMMENT 'Enterprise goods id',
`name` varchar(255) NOT NULL DEFAULT '' COMMENT 'sku{1:2,2:1}',
`sku_no` varchar(255) DEFAULT '' COMMENT 'commodity sku code',
`scan_goods` varchar(255) CHARACTER SET utf8 NOT NULL DEFAULT '' COMMENT 'sku bar code',
PRIMARY KEY (`id`),
) ENGINE=InnoDB AUTO_INCREMENT=14397 DEFAULT CHARSET=utf8mb4 COMMENT='enterprise sku';The ES index is as follows:
"enterprise_id": {
"type": "integer"
},
"goods_no": {
"type": "text",
"analyzer": "custom_e",
"fields": {
"keyword": {
"type": "keyword"
}
}
},
"id": {
"type": "integer"
},
"name": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart",
"fields": {
"standard": {
"type": "text",
"analyzer": "standard"
},
"keyword":{
"type": "keyword"
}
},
"fielddata": true
},
"sku_detail": {
"type": "nested",
"properties": {
"id": {
"type": "integer"
},
"sku_no": {
"type": "text",
"analyzer": "custom_e",
"fields": {
"keyword": {
"type": "keyword"
}
}
},
"scan_goods": {
"type": "text",
"analyzer": "custom_e",
"fields": {
"keyword": {
"type": "keyword"
}
}
}Note: in order to facilitate your understanding, the table fields are reduced here
Custom code workflow
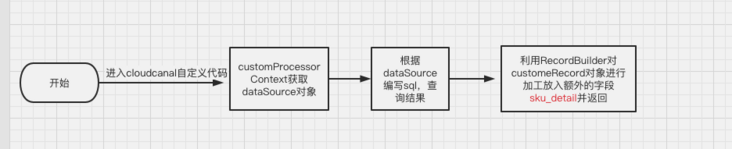
Custom code source code
public List<CustomRecord> addData(CustomRecord customRecord, DataSource dataSource) {
List<CustomRecord> customRecordList=new ArrayList<>();
String idStr = (customRecord.getFieldMapAfter().get("id")).toString();
List<EnterpriseSku> enterpriseSkuList = tryQuerySourceDs(dataSource, Integer.valueOf(Integer.parseInt(idStr.substring(idStr.indexOf("=") + 1, idStr.indexOf(")")))));
if (enterpriseSkuList.size() > 0) {
Map<String, Object> addFieldValueMap = new LinkedHashMap<>();
addFieldValueMap.put("sku_detail", JSONArray.parseArray(JSON.toJSONString(enterpriseSkuList)));
RecordBuilder.modifyRecordBuilder(customRecord).addField(addFieldValueMap);
}
customRecordList.add(customRecord);
return customRecordList;
}
public List<CustomRecord> updateData(CustomRecord customRecord, DataSource dataSource) {
List<CustomRecord> customRecordList=new ArrayList<>();
String idStr = (customRecord.getFieldMapAfter().get("id")).toString();
List<EnterpriseSku> enterpriseSkuList = tryQuerySourceDs(dataSource, Integer.valueOf(Integer.parseInt(idStr.substring(idStr.indexOf("=") + 1, idStr.indexOf(")")))));
if (enterpriseSkuList.size() > 0) {
Map<String, Object> addFieldValueMap = new LinkedHashMap<>();
addFieldValueMap.put("sku_detail", JSONArray.parseArray(JSON.toJSONString(enterpriseSkuList)));
RecordBuilder.modifyRecordBuilder(customRecord).addField(addFieldValueMap);
}
customRecordList.add(customRecord);
return customRecordList;
}
private List<EnterpriseSku> tryQuerySourceDs(DataSource dataSource, Integer id) {
try(Connection connection = dataSource.getConnection();
PreparedStatement ps = connection.prepareStatement("select * from `live-mini`.tb_enterprise_sku where is_del=0 and enterprise_goods_id=" + id)) {
ResultSet resultSet = ps.executeQuery();
BeanListHandler<EnterpriseSku> bh = new BeanListHandler(EnterpriseSku.class);
List<EnterpriseSku> enterpriseSkuList = bh.handle(resultSet);
return enterpriseSkuList;
} catch (Exception e) {
esLogger.error(e.getMessage());
return new ArrayList<>();
}
}thinking
The customRecord object is the parameter passed in by the user-defined code, and the passed in id is the sub table tb_enterprise_sku's foreign key enterprise_goods_id, query all the data about the foreign key in the sub table, put it into addFieldValueMap, and then process the customRecord using the method RecordBuilder.modifyRecordBuilder(customRecord).addField(addFieldValueMap) provided by the source code.
To create a task
New source end-to-end data source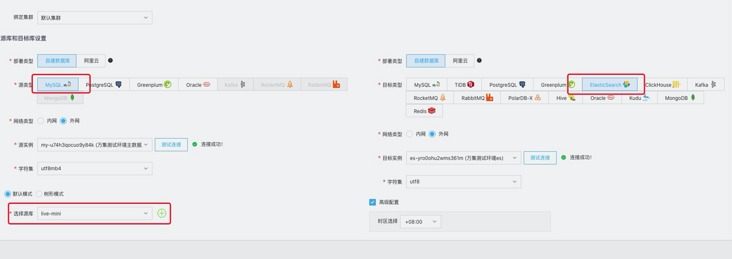
Select the subscription table and synchronize to the opposite index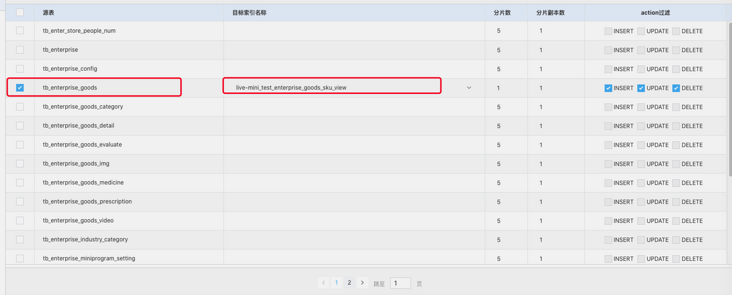
Select the synchronization field and select the custom package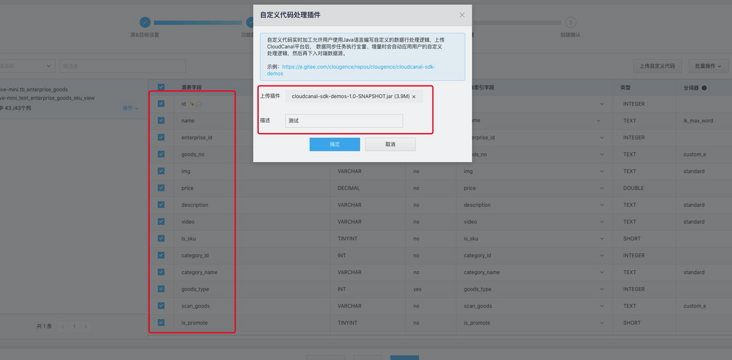
Complete the create task
Realization effect
{
"_index" : "live-mini_pro_enterprise_goods_sku_view",
"_type" : "_doc",
"_id" : "17385",
"_score" : 12.033585,
"_source" : {
"img" : "https://ovopark.oss-cn-hangzhou.aliyuncs.com/wanji/2020-11-30/1606786889982.jpg",
"category_name" : "No category",
"is_grounding" : 1,
"del_time" : "2021-11-01T17:13:32+08:00",
"goods_no" : "",
"distribute_second" : 0.0,
"uniform_proportion" : 0,
"description" : "10000 episodes of private domain live broadcast traffic conversion platform&Online mall",
"video" : "",
"self_uniform_proportion" : 0,
"update_time" : "2021-11-01T17:13:32+08:00",
"allocate_video" : null,
"self_commission_properation" : 0.0,
"category_id" : 0,
"is_promote" : 0,
"price" : 0.03,
"is_distributor_self" : 0,
"limit_purchases_max_quantity" : 0,
"limit_purchases_type" : 0,
"is_del" : 0,
"is_distributor" : 0,
"activity_price" : 0.0,
"id" : 17385,
"stock" : 0,
"distribute_first" : 0.0,
"is_distribution_threshold" : 0,
"refund_configure" : 1,
"create_time" : "2021-11-01T17:13:32+08:00",
"scan_goods" : "",
"limit_purchases_cycle" : 0,
"is_sku" : 1,
"allocate_mode" : 0,
"sku_detail" : [
{
"scan_goods" : "",
"sku_no" : "",
"id" : "19943"
}
],
"enterprise_id" : 24,
"is_delivery" : 0,
"is_limit_purchases" : 0,
"name" : "Test commodity test commodity test commodity tester",
"goods_type" : 0,
"goods_order" : 0,
"ts" : "2021-11-01T17:16:42+08:00",
"delivery_price" : 0.0
}
}Case 2: Construction of order table, commodity table and wide table
Business background
The small program mall needs to show and guess the goods you like. Guessing the goods you like is determined according to the frequency of users purchasing goods, mainly involving order table, order commodity table, user table, commodity table, etc. using ES query also faces the problem that multiple tables cannot be join ed. In this case, CloudCanal custom code is still used to synchronize to flat data.
Original use technology and problems of business
The ES synchronization scheme originally used logstash to synchronize the data in full. Due to the problem of data volume, the synchronized data is placed in the early morning of each day. The problem is that the data synchronization is not timely and can only be full. The risk is relatively high. There are many times when the index data is not synchronized after being deleted.
Table structure
CREATE TABLE `tb_order` ( `id` int(11) NOT NULL AUTO_INCREMENT, `order_sn` varchar(32) NOT NULL COMMENT 'Order No', `user_id` int(11) NOT NULL COMMENT 'user id', `user_name` varchar(255) DEFAULT NULL COMMENT 'User name', `user_phone` varchar(11) DEFAULT NULL COMMENT 'Subscriber telephone', `store_id` int(11) NOT NULL COMMENT 'store id', `enterprise_id` int(11) DEFAULT '1' COMMENT 'enterprise id', `order_type` int(11) NOT NULL COMMENT '0: Express delivery; 1: Store self collection; 2:Meituan delivery instant order; 3:Meituan instant delivery reservation;', `order_status` tinyint(11) DEFAULT '0' COMMENT 'Original order status: 1: unpaid, 3: to be shipped/To be packed, 5: (to be received)/To be picked up), 6: transaction completion, 7: order invalidation, 8: transaction closing, 13: user cancellation,18:The merchant is forced to close, 19 agrees to refund, but the refund fails (not used), 30:Meituan instant delivery status is abnormal', `total_price` decimal(10,2) DEFAULT '0.00' COMMENT 'Total order price', PRIMARY KEY (`id`,`total_goods_weight`) USING BTREE ) ENGINE=InnoDB AUTO_INCREMENT=18630 DEFAULT CHARSET=utf8mb4 COMMENT='Order form'; CREATE TABLE `tb_order_goods` ( `id` int(11) NOT NULL AUTO_INCREMENT, `user_id` int(11) NOT NULL COMMENT 'user id', `order_id` int(11) NOT NULL COMMENT 'order id', `goods_id` int(11) NOT NULL COMMENT 'Order item id', `enterprise_goods_id` varchar(11) DEFAULT NULL COMMENT 'Enterprise goods id', `name` varchar(512) DEFAULT '' COMMENT 'Order item name', `spec` varchar(100) DEFAULT NULL COMMENT 'Specification properties', `img` varchar(100) DEFAULT '' COMMENT 'Order item picture', PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=19159 DEFAULT CHARSET=utf8mb4 COMMENT='Order item table';
ES index field
"store_id":{
"type": "integer"
},
"user_id":{
"type": "integer"
},
"sex":{
"type": "integer"
},
"birthday":{
"type": "keyword"
},
"goods_name":{
"type": "text",
"analyzer" : "ik_max_word",
"search_analyzer" : "ik_smart",
"fields": {
"keyword":{
"type": "keyword"
}
},
"fielddata": true
},
"goods_type":{
"type": "integer"
},
"order_goods_id":{
"type": "integer"
},
"enterprise_goods_id":{
"type": "integer"
},
"goods_price":{
"type": "double"
},
"order_id":{
"type": "integer"
},
"order_create_time":{
"type": "date"
}Note: multiple tables are involved in the ES table structure. For convenience of example, only two tables are pasted here. es_doc display dimension is the dimension of order goods.
Implementation process
Subscription order form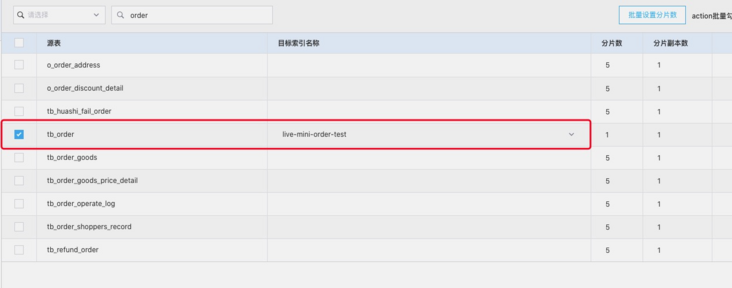
Subscription field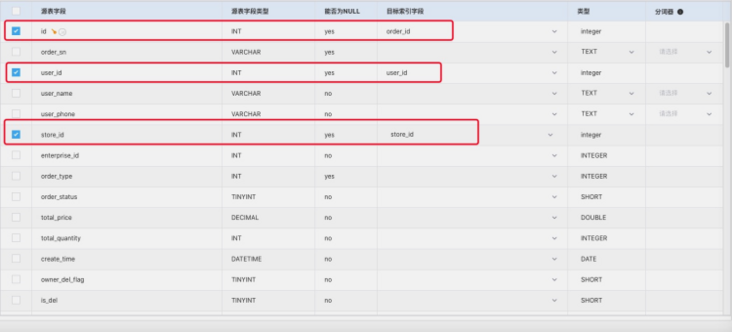
The fields marked with a horizontal line are the fields to be synchronized. One point needs special attention: the fields to be displayed in ES must be checked for synchronization. If they are not checked, they will not be synchronized after add ing in the user-defined code. The official interpretation is a black-and-white list of fields.
Here are some details. The dimension of the subscribed table is not the dimension of ES storage data, so the id here is not the dimension of ES_ id, for this field that must be transmitted during source side synchronization, you can set an existing field of the opposite side at will. You can flexibly reconfigure the field to be synchronized in the user-defined code. (if the default is set, the ES index will create this field, which is obviously not the effect we want to see.)
operation flow
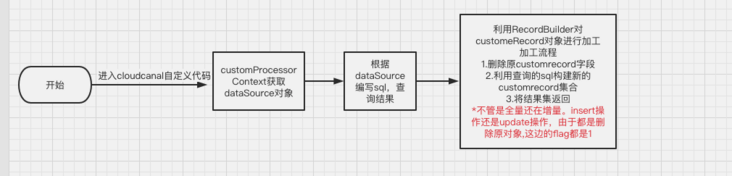
code implementation
Query flat data
SELECT
to2.store_id,
tuc.id AS user_id,
tuc.sex AS sex,
tuc.birthday,
tog.NAME AS goods_name,
tog.goods_type,
tog.goods_id AS order_goods_id,
tog.goods_price,
tog.create_time AS order_create_time,
tog.id AS order_id,
tog.enterprise_goods_id AS enterprise_goods_id
FROM
`live-mini`.tb_order to2
INNER JOIN `live-mini`.tb_order_goods tog ON to2.id = tog.order_id
AND tog.is_del = 0
AND to2.user_id = tog.user_id
INNER JOIN `live-mini`.tb_user_c tuc ON to2.user_id = tuc.id
AND tuc.is_del = 0
WHERE
to2.is_del = 0
AND to2.id= #{placeholder}
GROUP BY tog.idIdea: after the user-defined code obtains the primary key of the order table, query the above SQL, delete the data in the original customRecord, and then add data based on the query result dimension. The logic of modification is the same.
public List<CustomRecord> addData(CustomRecord customRecord, DataSource dataSource) {
List<CustomRecord> customRecordList=new ArrayList<>();
String idStr = (customRecord.getFieldMapAfter().get("id")).toString();
List<OrderGoods> orderGoodsList = tryQuerySourceDs(dataSource, Integer.valueOf(Integer.parseInt(idStr.substring(idStr.indexOf("=") + 1, idStr.indexOf(")")))));
RecordBuilder.modifyRecordBuilder(customRecord).deleteRecord();
if (orderGoodsList.size() > 0) {
for (OrderGoods orderGoods:orderGoodsList){
//Add the required rows and columns
Map<String,Object> fieldMap=BeanMapTool.beanToMap(orderGoods);
customRecordList.add(RecordBuilder.createRecordBuilder().createRecord(fieldMap).build());
}
}
return customRecordList;
}
public List<CustomRecord> updateData(CustomRecord customRecord, DataSource dataSource) {
List<CustomRecord> customRecordList=new ArrayList<>();
String idStr = (customRecord.getFieldMapAfter().get("id")).toString();
List<OrderGoods> orderGoodsList = tryQuerySourceDs(dataSource, Integer.valueOf(Integer.parseInt(idStr.substring(idStr.indexOf("=") + 1, idStr.indexOf(")")))));
RecordBuilder.modifyRecordBuilder(customRecord).deleteRecord();
if (orderGoodsList.size() > 0) {
for (OrderGoods orderGoods:orderGoodsList){
//Add the required rows and columns
Map<String,Object> fieldMap=BeanMapTool.beanToMap(orderGoods);
customRecordList.add(RecordBuilder.createRecordBuilder().createRecord(fieldMap).build());
}
}
return customRecordList;
}
private List<OrderGoods> tryQuerySourceDs(DataSource dataSource, Integer id) {
String sql="SELECT to2.store_id,tuc.id AS user_id,tuc.sex AS sex,tuc.birthday,tog.NAME AS goods_name,tog.goods_type,tog.goods_id AS order_goods_id,tog.goods_price,tog.create_time AS order_create_time,tog.id AS order_id,tog.enterprise_goods_id AS enterprise_goods_id FROM `live-mini`.tb_order to2 INNER JOIN `live-mini`.tb_order_goods tog ON to2.id = tog.order_id AND tog.is_del = 0 AND to2.user_id = tog.user_id INNER JOIN `live-mini`.tb_user_c tuc ON to2.user_id = tuc.id AND tuc.is_del = 0 WHERE to2.is_del = 0 and to2.id=";
try(Connection connection = dataSource.getConnection();
PreparedStatement ps = connection.prepareStatement(sql + id+" GROUP BY tog.id")) {
ResultSet resultSet = ps.executeQuery();
BeanListHandler<OrderGoods> bh = new BeanListHandler(OrderGoods.class);
List<OrderGoods> orderGoodsList = bh.handle(resultSet);
return orderGoodsList;
} catch (Exception e) {
esLogger.error(e.getMessage());
return new ArrayList<>();
}
}Realization effect
{
"_index" : "live-mini-order-pro",
"_type" : "_doc",
"_id" : "359",
"_score" : 1.0,
"_source" : {
"goods_type" : 0,
"order_id" : 359,
"order_goods_id" : 450,
"order_create_time" : "2020-12-22T10:45:20.000Z",
"enterprise_goods_id" : 64,
"goods_name" : "[Exclusive for regular customers] WanDian palm 2021 new year customized desk calendar",
"sex" : 2,
"goods_price" : 1.0,
"user_id" : 386,
"store_id" : 1,
"birthday" : ""
}
}Write at the end
The user-defined code of CloudCanal has well solved the problem of multi table Association and synchronization ES. The simple and easy-to-use interface and in-depth functions are impressive. We look forward to more new capabilities of CloudCanal. You are also welcome to communicate with me about CloudCanal's ability to customize code.
Participate in internal test
CloudCanal will continue to provide some preview capabilities, including new data links, optimization capabilities, function plug-ins. The custom code capability described in this article is also in the internal test stage. If you want to experience, you can add our little assistant (wechat: suhuayue001) for understanding and trial.
Join the CloudCanal fan group to master first-hand news and get more benefits. Please add our little assistant wechat: suhuayue001
CloudCanal - a free and easy-to-use enterprise data synchronization tool. Welcome to taste it.
To learn more about products, you can view Official website: http://www.clougence.com
CloudCanal community: https://www.askcug.com/