
background
With the increasing scale of AI model and training data, users have higher and higher requirements for the iterative efficiency of the model. Obviously, the computing power of a single GPU can not meet most business scenarios. The use of single machine multi card or multi machine multi card training has become a trend. The parameter synchronization of single machine multi card training scenario has been well solved with the help of NVIDIA NVLINK technology, while the multi machine multi card scenario is not so simple due to its strong dependence on network communication.
At present, the RoCE and other RDMA technologies provided by network card manufacturers have greatly improved the multi machine communication efficiency. However, how to improve the communication efficiency of distributed training system in 25G or 50G VPC network environment is still an urgent problem for public cloud manufacturers. The innovation of Taco training different from other solutions in the industry is that in addition to the commonly used AI acceleration technologies such as multi-level communication, multi stream communication, gradient fusion and compressed communication, it also introduces a user-defined protocol stack HARP, which effectively solves the network communication problem in multi machine and multi card training in VPC environment.
The custom user state protocol stack HARP can achieve a linear speedup of nearly 100G RDMA network in the VPC distributed training environment, and has more than twice the performance improvement on some models compared with the open source Horovod framework.
Taco training can be deployed in both ECs and cloud container environments. The accelerated deployment scheme of Taco training on GPU ECS has been launched in the official website document. For details, see Deploy AI acceleration engine taco training on GPU ECS.
This article will introduce the deployment scheme based on Tencent cloud container service (TKE). Let's understand the distributed training acceleration scheme of Taco training on cloud container, and accelerate AI training with the help of Tencent cloud self-developed network protocol stack HARP!
introduce
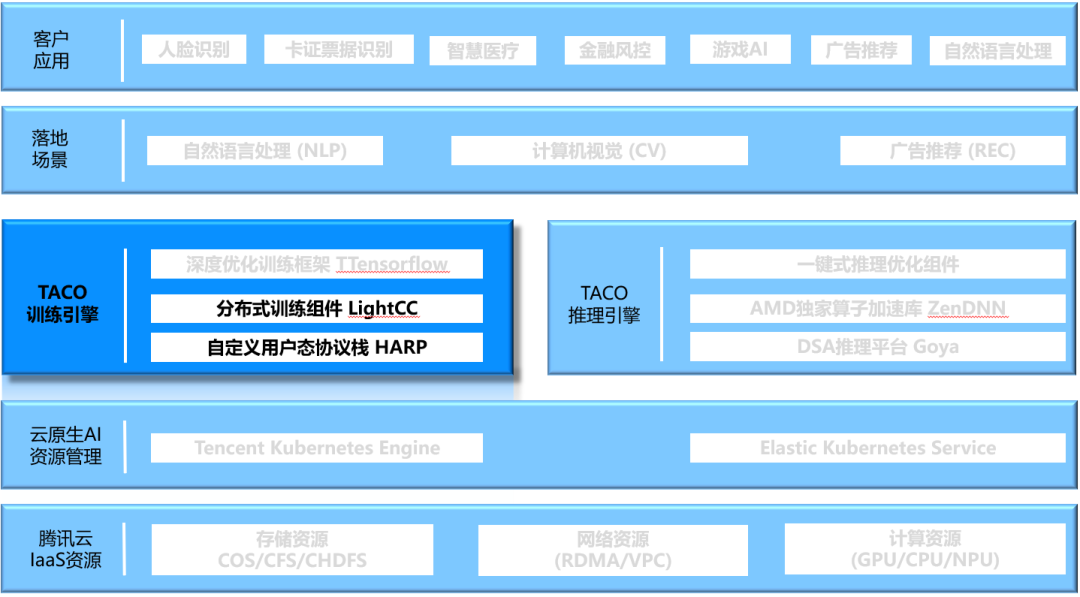
TACO-Training
Taco training is an AI training acceleration engine launched by Tencent cloud heterogeneous computing team based on IaaS resources, providing users with out of the box AI training suite. Taco training is backed by Yunfan Oteam. Based on the rich AI business scenarios within Tencent, taco training provides multi-level optimization such as bottom-up network communication, distributed strategy and training framework. It is a set of ecological training acceleration scheme. In order to better serve users, Tencent cloud decided to provide an in-depth optimized AI training acceleration scheme to users' deployment experience, help users save computing costs and improve the efficiency of AI product R & D.
The main acceleration technologies introduced by taco training in distributed scenarios include:
- The LightCC communication component based on Horovod deep customization and optimization provides optimization technologies such as multi-level communication, TOPK compression communication and Multi Strategy gradient fusion on the basis of compatibility with the original API
- Self developed user state network protocol stack HARP
HARP
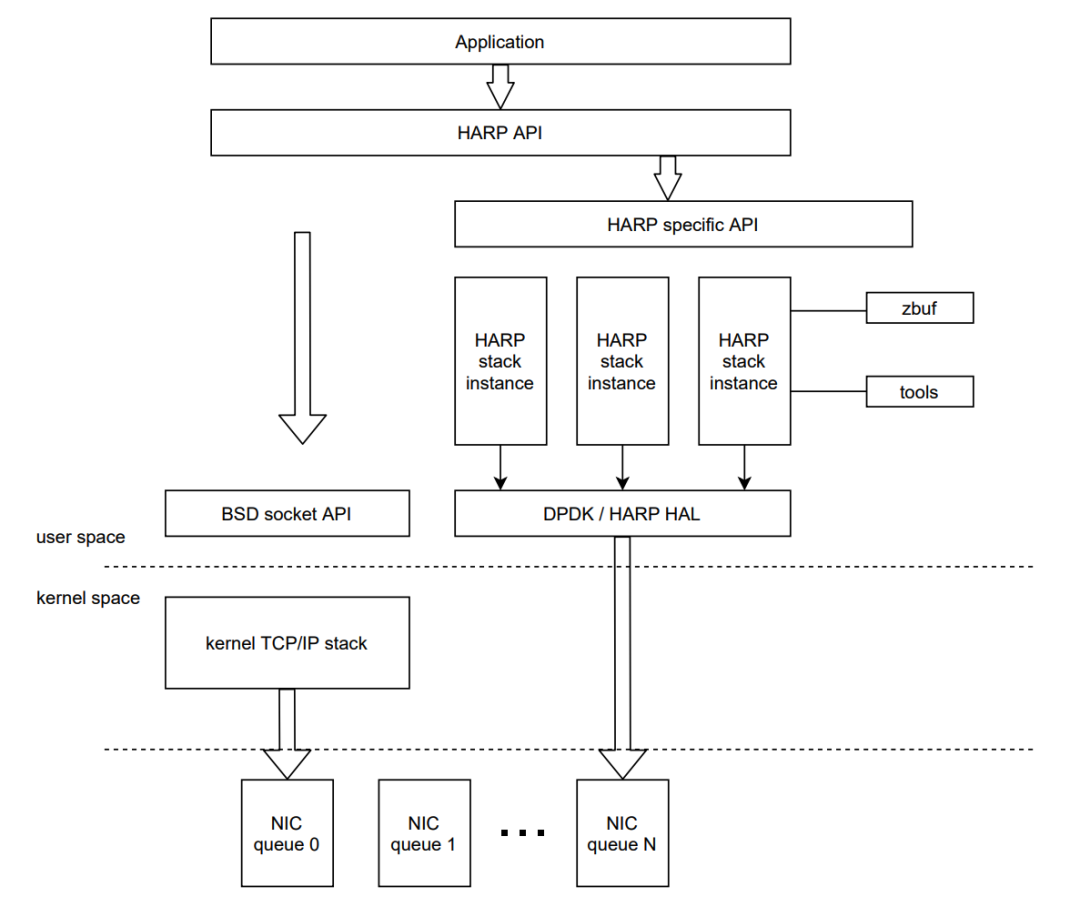
With the development of network hardware technology, the speed of network card has increased from 10G to 100G or even higher, and is widely deployed in the data center. However, the kernel network protocol stack commonly used at present has some necessary overhead, which makes it unable to make good use of high-speed network devices. In order to solve the problems existing in the kernel network protocol stack, Tencent cloud has developed the user state network protocol stack HARP, which can be integrated into NCCL in the form of Plug-in without any business changes to accelerate the distributed training performance on the cloud. In the VPC environment, compared with the traditional kernel protocol stack, HARP provides the following capabilities:
- It supports zero copy of the whole link memory. The HARP protocol stack provides a specific buffer to the application, so that the application data can be directly sent and received by the network card after being processed by the HARP protocol stack, so as to eliminate multiple memory copy operations in the kernel protocol stack that are time-consuming and occupy a high CPU.
- Support multi instance isolation of protocol stack, that is, the application can create specific protocol stack instances on multiple CPU core s to process network messages. Each instance is isolated from each other to ensure linear growth of performance.
- The data plane is designed without lock. The HARP protocol stack ensures that the data of the network session is processed only on the CPU core that created the session, using a specific protocol stack instance. It reduces the overhead of synchronization lock in the kernel, reduces the Cache Miss rate of CPU, and greatly improves the processing performance of network data.
In the figure below, the kernel protocol stack is on the left and the user mode protocol stack HARP is on the right.
TKE Kubeflow
Kubeflow is a tool set for the development, training, optimization, deployment and management of machine learning on the k8s platform, integrating many open-source projects in the field of machine learning, such as Jupyter, tfserving, Katib, Argo, etc. It can manage different stages of machine learning: data preprocessing, model training, model prediction, service deployment, etc. As long as k8s is installed, it can be deployed in local, computer room and cloud environment.
At present, TKE has integrated some AI components provided by open source Kubeflow, such as MPI operator, TF operator, pytorch operator, elastic Jupiter operator, etc., which can be easily installed and used by users.
performance data
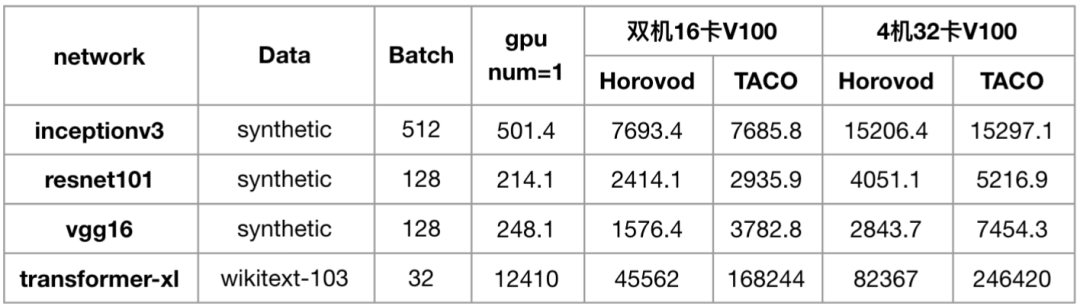
The following figure shows the acceleration effect of distributed training of each open source model using TACO training under the CVM GPU training cluster.
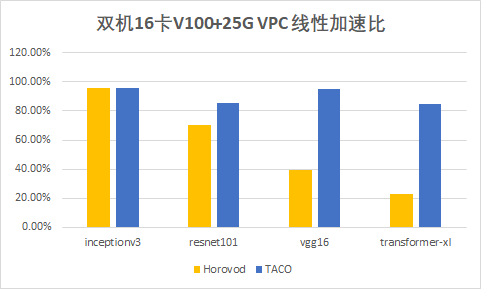
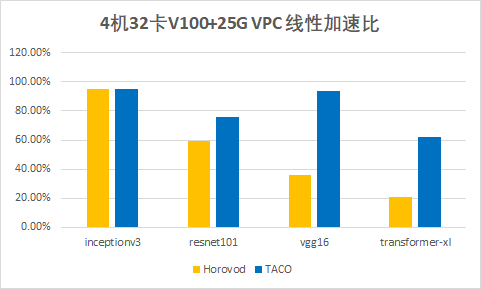
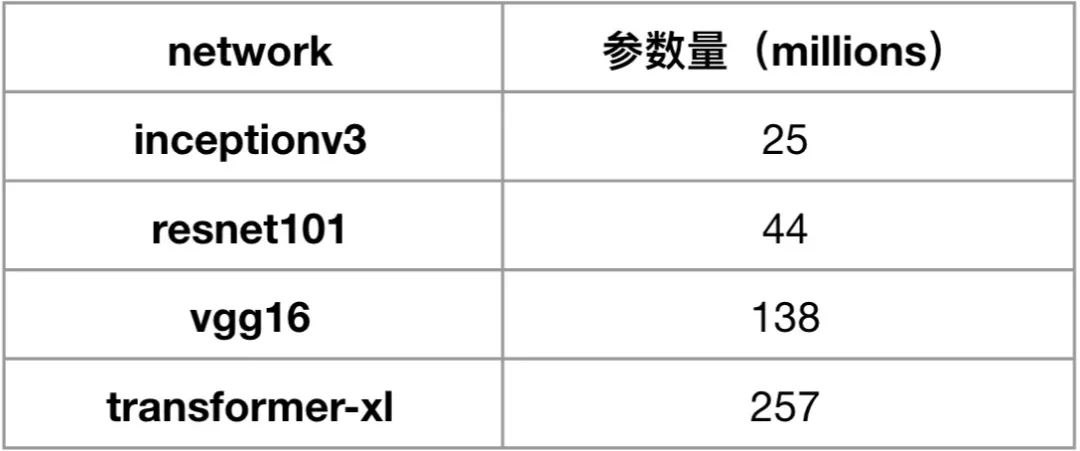
It can be found that with the increase of network model parameters, the improvement effect of TACO compared with Horovod is more and more obvious, and the performance of transformer XL is even improved by more than twice.
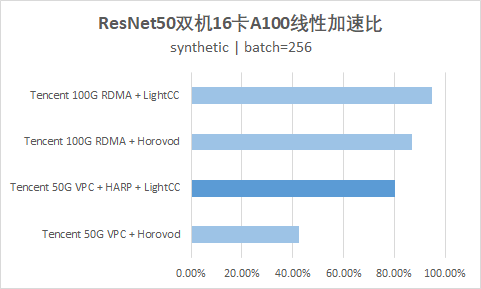
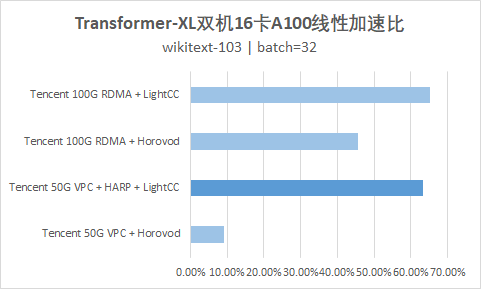
The following figure shows that both ResNet50 and transformer XL can provide performance close to Blackstone 100G RDMA product (HCCPNV4h) after CVM instance (GT4.41XLARGE948 + 50G VPC) is accelerated by HARP in the training environment of dual 16 card A100.
Deployment practice
In order to reproduce the above performance acceleration effect, next we begin to learn how to build a tke kubeflow + taco training GPU distributed training cluster step by step.
Environmental preparation
1. The console creates a TKE cluster. Nodes can select 8-card V100 (GN10Xp.20XLARGE320 + 25G network) or 8-card A100 (GT4.41XLARGE948 + 50G network) instances.
Refer to the following configuration:
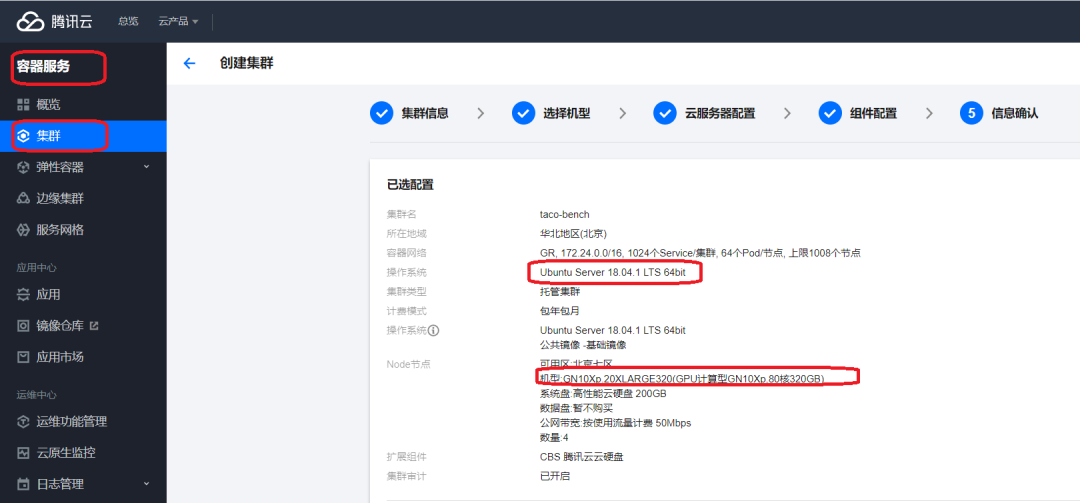
Note: verified operating systems include:
- Ubunut Server 18.04
- CentOS 7.8
- Tencent Linux 2.4
2. Install the Kubeflow component MPI operator on the console.
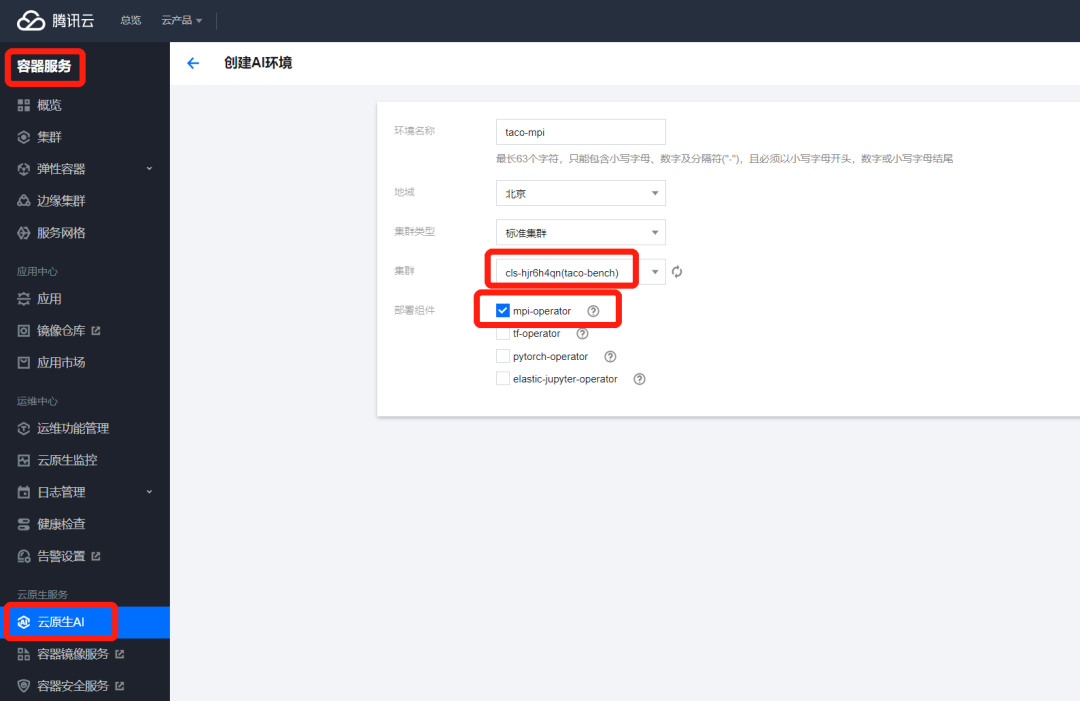
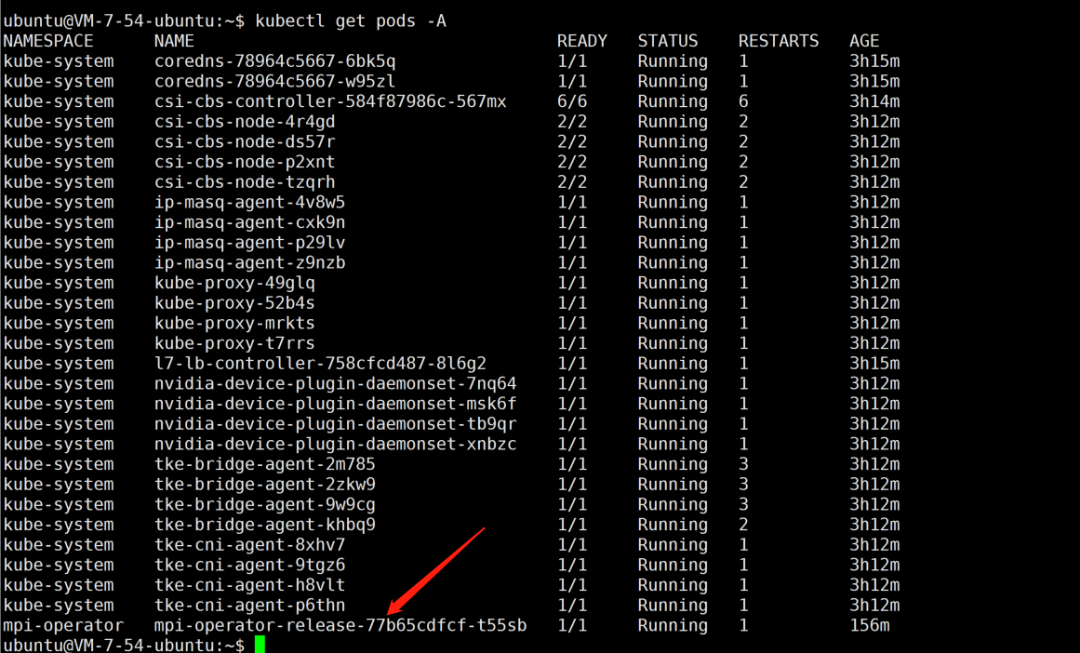
After successful installation, you can see the following pod on the worker node,
3. All worker nodes are configured with large page memory
// See the comment area document for the configuration command, which is invalid here kind: Service metadata: name: wordpress labels: app: wordpress spec: ports: - port: 80 selector: app: wordpress tier: frontend
After the host is up, check whether the configuration is successful,

4. Binding elastic network card
Sign in On the ECS console, find the instance, click ins id to enter the instance page, select the elastic network card, and click bind elastic network card. In the pop-up bind elastic network card window, select bind the created network card as needed, or create a new elastic network card and bind it. Click OK to complete the binding.
Note: the number of bound elastic network cards is the same as the number of local GPU cards.
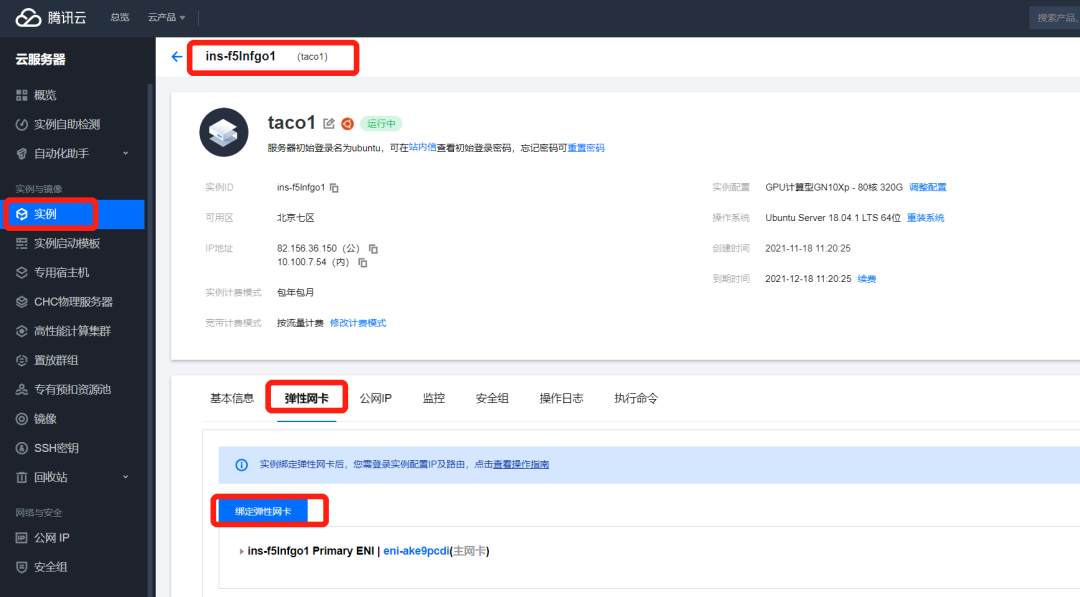
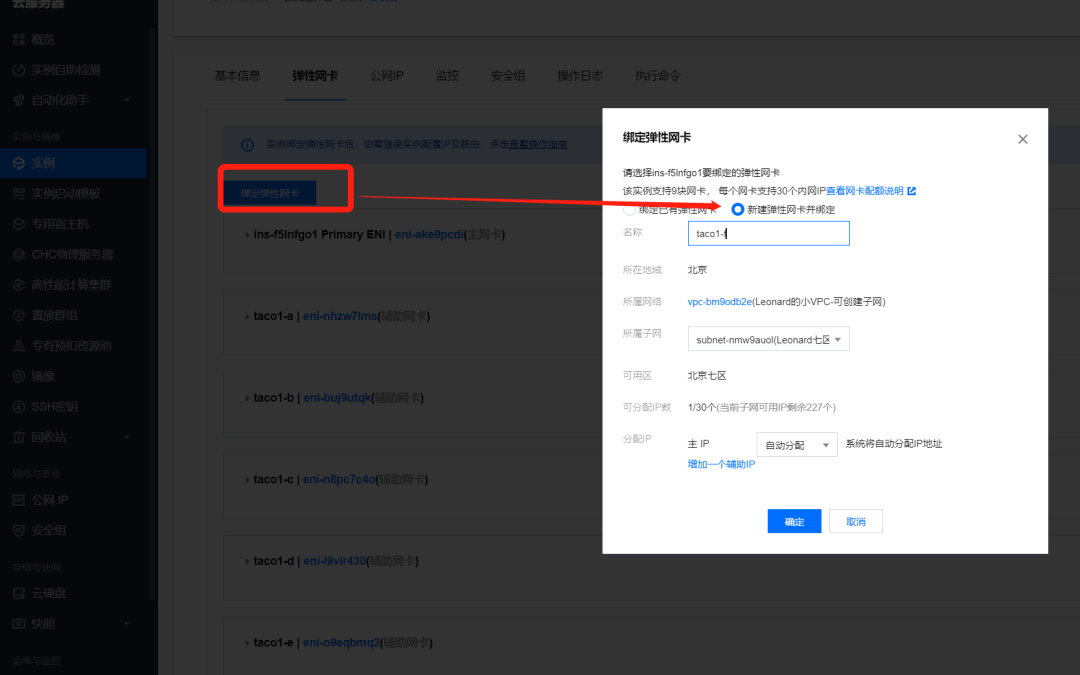
After binding is successful, 9 elastic network cards (1 primary network card and 8 secondary elastic network cards) can be seen on the host
5. Generate HARP profile
// Log in to the host of the worker node sudo curl -s -L http://mirrors.tencent.com/install/GPU/taco/harp_setup.sh | bash
If the execution is successful, 'Set up HARP successfully' will be printed,

Create pod
Refer to the following: taco.yaml file,
apiVersion: kubeflow.org/v1 kind: MPIJob metadata: name: taco-bench spec: slotsPerWorker: 1 runPolicy: cleanPodPolicy: Running mpiReplicaSpecs: Launcher: replicas: 1 template: spec: containers: - image: ccr.ccs.tencentyun.com/qcloud/taco-training:cu112-cudnn81-py3-0.3.2 name: mpi-launcher command: ["/bin/sh", "-ec", "sleep infinity"] resources: limits: cpu: 1 memory: 2Gi Worker: replicas: 4 template: spec: containers: - image: ccr.ccs.tencentyun.com/qcloud/taco-training:cu112-cudnn81-py3-0.3.2 name: mpi-worker securityContext: privileged: true volumeMounts: - mountPath: /sys/ name: sys - mountPath: /dev/hugepages name: dev-hge - mountPath: /usr/local/tfabric/tools name: tfabric resources: limits: hugepages-1Gi: "50Gi" memory: "100Gi" nvidia.com/gpu: 8 # requesting 1 GPU volumes: - name: sys hostPath: path: /sys/ - name: dev-hge hostPath: path: /dev/hugepages/ - name: tfabric hostPath: path: /usr/local/tfabric/tools/
Notes:
- Some device nodes and configuration files on the host side need to bind mount to pod for HARP
- pod needs to be configured with privileged permission, otherwise HARP cannot read the configuration file
- The pod needs to be configured with large page memory: hugepages-1Gi. For eight card machines, hugepages=50 can be configured. For other models, hugepages = (number of cards) is recommended × 5 + 10)
- ccr.ccs.tencentyun.com/qcloud/taco-training:cu112-cudnn81-py3-0.3.2 is the official image of Taco training. It is compiled based on Ubuntu 18.04/python 3.6.9/cuda 11.2.152/cudnn 8.1.1/nccl 2.8.4. If there are other version requirements, please contact Tencent cloud after-sales support
kubectl create -f taco.yaml
After successful creation,
Start test
Download the benchmark script and copy it to taco's container,
wget https://raw.githubusercontent.com/horovod/horovod/master/examples/tensorflow/tensorflow_synthetic_benchmark.py
for i in `kubectl get pods | grep worker | awk '{print $1}'`; do kubectl cp tensorflow_synthetic_benchmark.py $i:/mnt/; doneIn order to test the performance of different network models and the number of nodes, mpi launcher pod is not configured to directly start the training script.
//Login to launcher pod kubectl exec -it taco-bench-launcher -- bash // Execute training benchmark /usr/local/openmpi/bin/mpirun -np 32 -H taco-bench-worker-0:8,taco-bench-worker-1:8,taco-bench-worker-2:8,taco-bench-worker-3:8 --allow-run-as-root -bind-to none -map-by slot -x NCCL_ALGO=RING -x NCCL_DEBUG=INFO -x HOROVOD_MPI_THREADS_DISABLE=1 -x HOROVOD_FUSION_THRESHOLD=0 -x HOROVOD_CYCLE_TIME=0 -x LIGHT_2D_ALLREDUCE=1 -x LIGHT_TOPK_ALLREDUCE=1 -x LIGHT_TOPK_THRESHOLD=2097152 -x LIGHT_INTRA_SIZE=8 -x LD_LIBRARY_PATH -x PATH -mca btl_tcp_if_include eth0 python3 /mnt/tensorflow_synthetic_benchmark.py --model=VGG16 --batch-size=128
If you need to switch to Horovod for comparison test, execute the following command to delete TACO related components and install open source Horovod,
// Uninstall HARP accelerator Library
for i in `kubectl get pods | grep worker | awk '{print $1}'`; do kubectl exec $i -- bash -c 'mv /usr/lib/x86_64-linux-gnu/libnccl-net.so /mnt/'; done
// Uninstall LightCC
for i in `kubectl get pods | grep worker | awk '{print $1}'`; do kubectl exec $i -- bash -c 'pip uninstall -y light-horovod;echo'; done
// Install horovod (about 8 minutes)
for i in `kubectl get pods | grep worker | awk '{print $1}'`; do kubectl exec $i -- bash -c 'export PATH=/usr/local/openmpi/bin:$PATH;HOROVOD_WITH_MPI=1 HOROVOD_GPU_OPERATIONS=NCCL HOROVOD_WITH_TENSORFLOW=1 HOROVOD_NCCL_LINK=SHARED pip3 install --no-cache-dir horovod==0.21.3'; done
// Check that all worker s have successfully horovod
for i in `kubectl get pods | grep worker | awk '{print $1}'`; do kubectl exec $i -- bash -c 'pip show horovod;echo'; doneAt this point, we can reproduce the performance data shown above,
4 machine 32 card V100:
Dual 16 card A100:
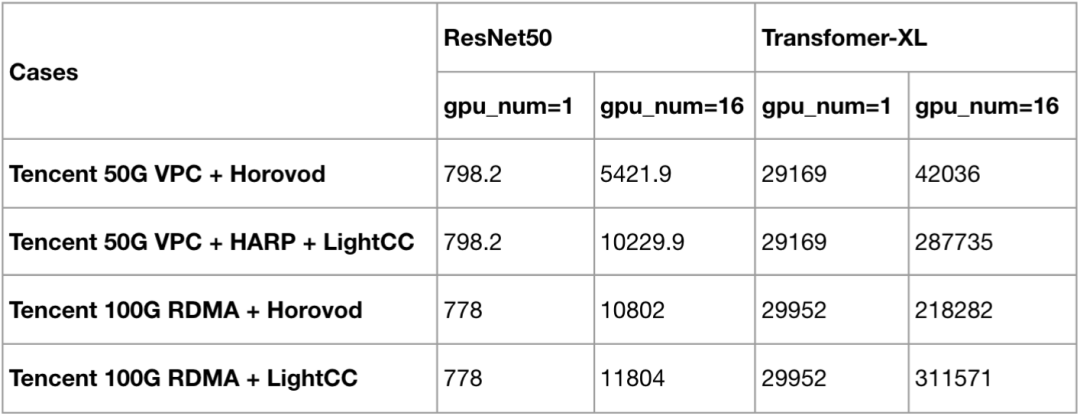
Note: the product test of Blackstone A100+RDMA requires additional environment configuration, and TACO image is not supported temporarily.
summary
This paper first introduces the current situation and problems of distributed training, then introduces the underlying optimization and exploration of Tencent cloud in distributed training, and leads to the first user-defined network protocol stack in the industry - HARP.
Then we show the acceleration effect of Taco training engine with HARP blessing:
- Under the same 25G VPC environment, TACO can provide about 20% - 200% performance improvement compared with Horovod, an open source solution in the industry. Basically, the more model parameters, the more obvious the performance improvement;
- TACO can provide training performance similar to 100G RDMA in 50G VPC environment;
Finally, we learned how to build taco training training cluster step by step based on TKE Kubeflow. The process is very simple and convenient. Let's try it together.