0 Introduction
Recently, I was helping a student with a Chinese character recognition project. The senior recorded and released some project related knowledge bases and partial implementations here. Welcome to discuss and learn
Chinese character recognition based on deep learning
Bi design help, problem opening guidance, technical solutions 🇶746876041
1 data set
Senior students have a printed image data set of 3755 Chinese characters (first-class font). We can use them to build the next 3755 Chinese character recognition system.
The network used for deep learning for character recognition is of course CNN. Which classic network does it use? VGG?RESNET? Or something else? I thought that the deeper the network training, the better the model should be. But considering the difficulty of training and the predicted speed of online deployment in the future, I think we should first establish a relatively shallow network (based on the improvement of LeNet) for basic character recognition, and then try other network structures according to the project requirements. The deep learning framework used in this task is the powerful Tensorflow.
2 network construction
The first step, of course, is to build the network and calculation diagram
In fact, character recognition is a multi classification task. For example, this 3755 character recognition is a classification task of 3755 categories. The network we defined is very simple. It is basically an improved version of LeNet. It is worth noting that we have added batch normalization. In addition, our loss function is sparse_softmax_cross_entropy_with_logits, the optimizer selects Adam, and the learning rate is set to 0.1
#network: conv2d->max_pool2d->conv2d->max_pool2d->conv2d->max_pool2d->conv2d->conv2d->max_pool2d->fully_connected->fully_connected
def build_graph(top_k):
keep_prob = tf.placeholder(dtype=tf.float32, shape=[], name='keep_prob')
images = tf.placeholder(dtype=tf.float32, shape=[None, 64, 64, 1], name='image_batch')
labels = tf.placeholder(dtype=tf.int64, shape=[None], name='label_batch')
is_training = tf.placeholder(dtype=tf.bool, shape=[], name='train_flag')
with tf.device('/gpu:5'):
#To slim.conv2d and slim.fully_connected prepares the default parameter: batch_norm
with slim.arg_scope([slim.conv2d, slim.fully_connected],
normalizer_fn=slim.batch_norm,
normalizer_params={'is_training': is_training}):
conv3_1 = slim.conv2d(images, 64, [3, 3], 1, padding='SAME', scope='conv3_1')
max_pool_1 = slim.max_pool2d(conv3_1, [2, 2], [2, 2], padding='SAME', scope='pool1')
conv3_2 = slim.conv2d(max_pool_1, 128, [3, 3], padding='SAME', scope='conv3_2')
max_pool_2 = slim.max_pool2d(conv3_2, [2, 2], [2, 2], padding='SAME', scope='pool2')
conv3_3 = slim.conv2d(max_pool_2, 256, [3, 3], padding='SAME', scope='conv3_3')
max_pool_3 = slim.max_pool2d(conv3_3, [2, 2], [2, 2], padding='SAME', scope='pool3')
conv3_4 = slim.conv2d(max_pool_3, 512, [3, 3], padding='SAME', scope='conv3_4')
conv3_5 = slim.conv2d(conv3_4, 512, [3, 3], padding='SAME', scope='conv3_5')
max_pool_4 = slim.max_pool2d(conv3_5, [2, 2], [2, 2], padding='SAME', scope='pool4')
flatten = slim.flatten(max_pool_4)
fc1 = slim.fully_connected(slim.dropout(flatten, keep_prob), 1024,
activation_fn=tf.nn.relu, scope='fc1')
logits = slim.fully_connected(slim.dropout(fc1, keep_prob), FLAGS.charset_size, activation_fn=None,
scope='fc2')
# Because we didn't do hot coding, we used spark_ softmax_ cross_ entropy_ with_ logits
loss = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(logits=logits, labels=labels))
accuracy = tf.reduce_mean(tf.cast(tf.equal(tf.argmax(logits, 1), labels), tf.float32))
update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
if update_ops:
updates = tf.group(*update_ops)
loss = control_flow_ops.with_dependencies([updates], loss)
global_step = tf.get_variable("step", [], initializer=tf.constant_initializer(0.0), trainable=False)
optimizer = tf.train.AdamOptimizer(learning_rate=0.1)
train_op = slim.learning.create_train_op(loss, optimizer, global_step=global_step)
probabilities = tf.nn.softmax(logits)
# Draw a loss accuracy curve
tf.summary.scalar('loss', loss)
tf.summary.scalar('accuracy', accuracy)
merged_summary_op = tf.summary.merge_all()
# Return top k prediction results and their probabilities; Return top K accuracy
predicted_val_top_k, predicted_index_top_k = tf.nn.top_k(probabilities, k=top_k)
accuracy_in_top_k = tf.reduce_mean(tf.cast(tf.nn.in_top_k(probabilities, labels, top_k), tf.float32))
return {'images': images,
'labels': labels,
'keep_prob': keep_prob,
'top_k': top_k,
'global_step': global_step,
'train_op': train_op,
'loss': loss,
'is_training': is_training,
'accuracy': accuracy,
'accuracy_top_k': accuracy_in_top_k,
'merged_summary_op': merged_summary_op,
'predicted_distribution': probabilities,
'predicted_index_top_k': predicted_index_top_k,
'predicted_val_top_k': predicted_val_top_k}
3 model training
Before training, we should design the data to feed the network training efficiently.
First, we create a data flow diagram, which is composed of some pipeline stages, which are connected by queues. The first stage will generate file names, which we read and put in the file name queue. The second stage reads data from the file (using Reader), generates samples, and puts the samples in a sample queue. According to your settings, you can actually copy the samples in the second stage to make them independent of each other, so that they can be read from multiple files in parallel. At the end of the second stage, there is a queuing operation, that is, entering the queue and leaving the queue in the next stage. Because we are the thread to start running these queueing operations, our training cycle will make the samples in the sample queue continuously out of the queue.
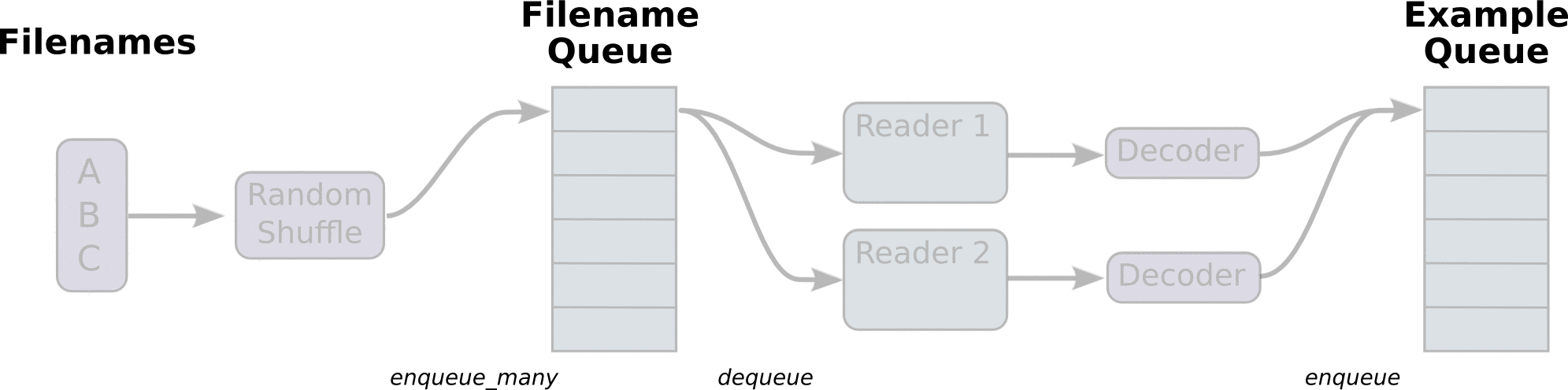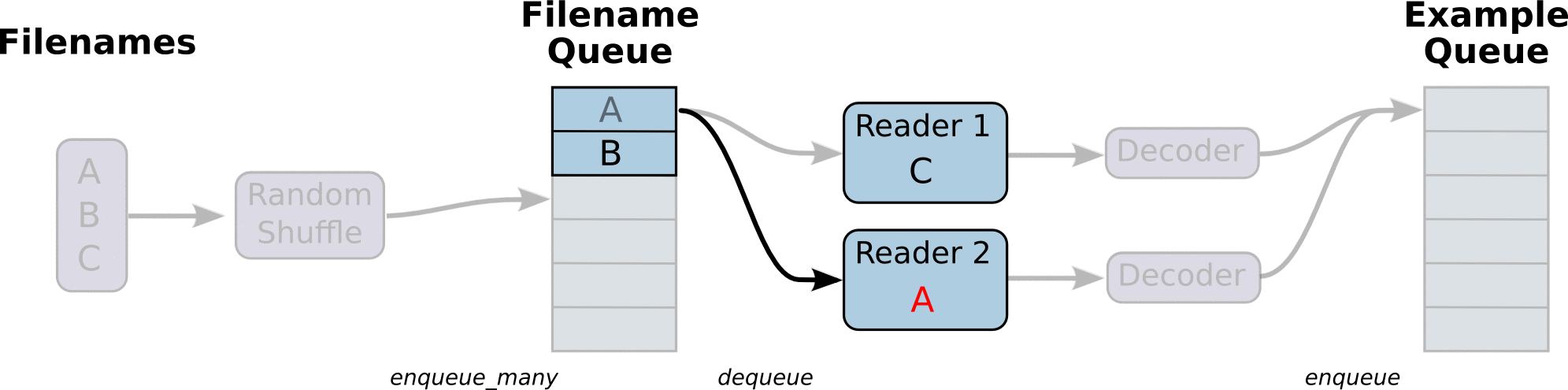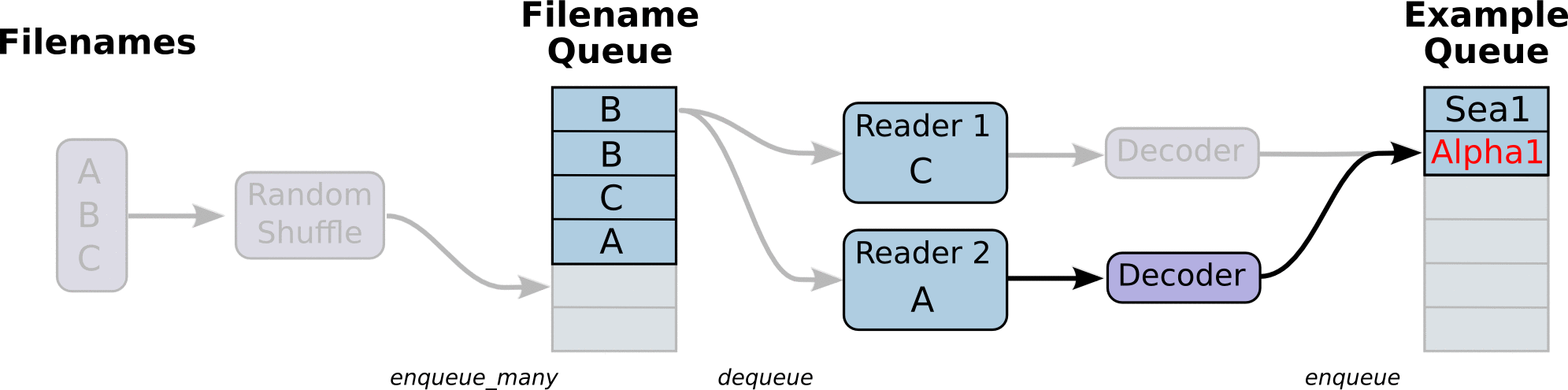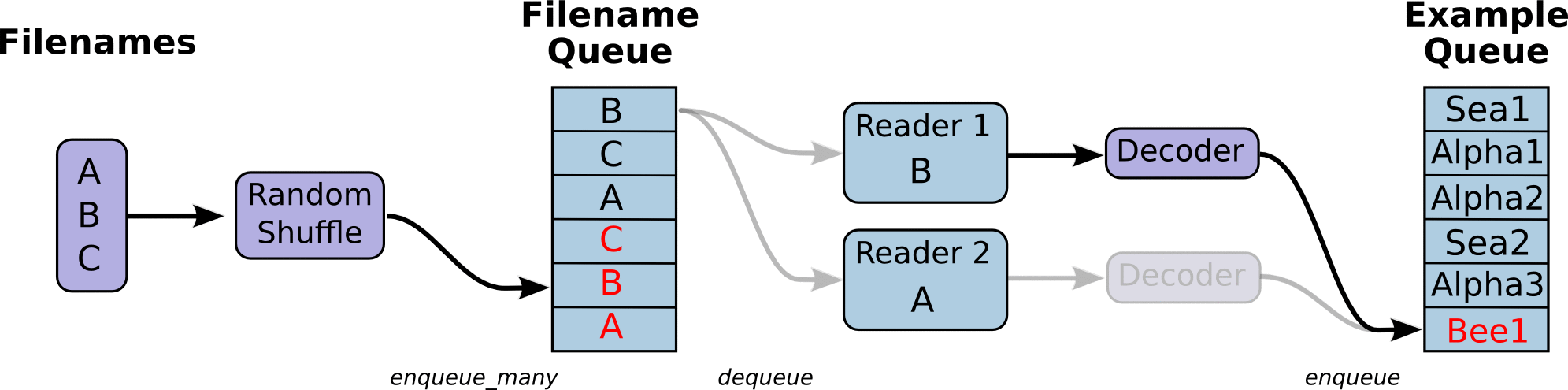
Queue operations are performed in the main thread, and multiple threads can run together in the Session. In the application scenario of data input, the queue operation is to read the input from the hard disk and put it into the memory, which is slow. Using QueueRunner, you can create a series of new threads for queue operation, so that the main thread can continue to use data. In the scenario of training neural network, the training network and reading data are asynchronous. The main thread is training the network and the other thread is reading data from the hard disk into memory.
# batch generation
def input_pipeline(self, batch_size, num_epochs=None, aug=False):
# numpy array to tensor
images_tensor = tf.convert_to_tensor(self.image_names, dtype=tf.string)
labels_tensor = tf.convert_to_tensor(self.labels, dtype=tf.int64)
# Will image_ list ,label_ Do a slice for the list
input_queue = tf.train.slice_input_producer([images_tensor, labels_tensor], num_epochs=num_epochs)
labels = input_queue[1]
images_content = tf.read_file(input_queue[0])
images = tf.image.convert_image_dtype(tf.image.decode_png(images_content, channels=1), tf.float32)
if aug:
images = self.data_augmentation(images)
new_size = tf.constant([FLAGS.image_size, FLAGS.image_size], dtype=tf.int32)
images = tf.image.resize_images(images, new_size)
image_batch, label_batch = tf.train.shuffle_batch([images, labels], batch_size=batch_size, capacity=50000,
min_after_dequeue=10000)
# print 'image_batch', image_batch.get_shape()
return image_batch, label_batch
The data reading mode during training is as described above, and the training code is designed as follows according to the architecture:
def train():
print('Begin training')
# Fill in the data reading path
train_feeder = DataIterator(data_dir='./dataset/train/')
test_feeder = DataIterator(data_dir='./dataset/test/')
model_name = 'chinese-rec-model'
with tf.Session(config=tf.ConfigProto(gpu_options=gpu_options, allow_soft_placement=True)) as sess:
# batch data acquisition
train_images, train_labels = train_feeder.input_pipeline(batch_size=FLAGS.batch_size, aug=True)
test_images, test_labels = test_feeder.input_pipeline(batch_size=FLAGS.batch_size)
graph = build_graph(top_k=1) # top k = 1 during training
saver = tf.train.Saver()
sess.run(tf.global_variables_initializer())
# Setting up a multithreaded Coordinator
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
train_writer = tf.summary.FileWriter(FLAGS.log_dir + '/train', sess.graph)
test_writer = tf.summary.FileWriter(FLAGS.log_dir + '/val')
start_step = 0
# You can continue training from the model under a step
if FLAGS.restore:
ckpt = tf.train.latest_checkpoint(FLAGS.checkpoint_dir)
if ckpt:
saver.restore(sess, ckpt)
print("restore from the checkpoint {0}".format(ckpt))
start_step += int(ckpt.split('-')[-1])
logger.info(':::Training Start:::')
try:
i = 0
while not coord.should_stop():
i += 1
start_time = time.time()
train_images_batch, train_labels_batch = sess.run([train_images, train_labels])
feed_dict = {graph['images']: train_images_batch,
graph['labels']: train_labels_batch,
graph['keep_prob']: 0.8,
graph['is_training']: True}
_, loss_val, train_summary, step = sess.run(
[graph['train_op'], graph['loss'], graph['merged_summary_op'], graph['global_step']],
feed_dict=feed_dict)
train_writer.add_summary(train_summary, step)
end_time = time.time()
logger.info("the step {0} takes {1} loss {2}".format(step, end_time - start_time, loss_val))
if step > FLAGS.max_steps:
break
if step % FLAGS.eval_steps == 1:
test_images_batch, test_labels_batch = sess.run([test_images, test_labels])
feed_dict = {graph['images']: test_images_batch,
graph['labels']: test_labels_batch,
graph['keep_prob']: 1.0,
graph['is_training']: False}
accuracy_test, test_summary = sess.run([graph['accuracy'], graph['merged_summary_op']],
feed_dict=feed_dict)
if step > 300:
test_writer.add_summary(test_summary, step)
logger.info('===============Eval a batch=======================')
logger.info('the step {0} test accuracy: {1}'
.format(step, accuracy_test))
logger.info('===============Eval a batch=======================')
if step % FLAGS.save_steps == 1:
logger.info('Save the ckpt of {0}'.format(step))
saver.save(sess, os.path.join(FLAGS.checkpoint_dir, model_name),
global_step=graph['global_step'])
except tf.errors.OutOfRangeError:
logger.info('==================Train Finished================')
saver.save(sess, os.path.join(FLAGS.checkpoint_dir, model_name), global_step=graph['global_step'])
finally:
# Clean up and close the thread when the maximum number of training iterations is reached
coord.request_stop()
coord.join(threads)
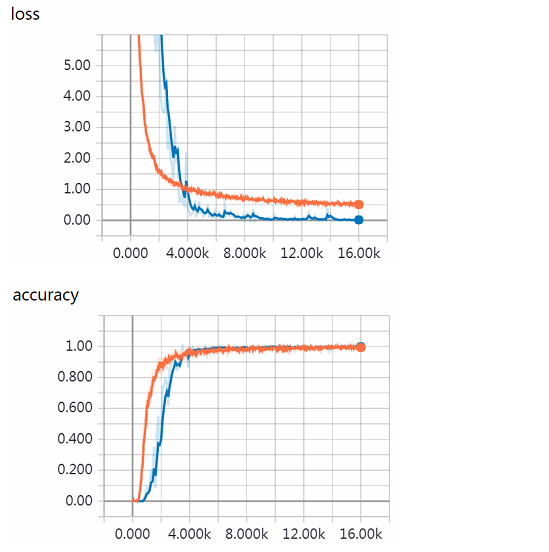
Execute the following instructions for model training. Because I use TITAN X, I feel that the training time is not long. I can finish the training in about 1 hour. The loss and accuracy transformation curves of the training process are shown in the figure below
Then execute the instruction, set the maximum number of iteration steps to 16002, verify every 100 steps, and store the model every 500 steps.
python Chinese_OCR.py --mode=train --max_steps=16002 --eval_steps=100 --save_steps=500
4 model performance evaluation
We need to evaluate the modular model. We need to calculate the accuracy of top 1 and top 5 of the model.
Execute instruction
python Chinese_OCR.py --mode=validation

def validation():
print('Begin validation')
test_feeder = DataIterator(data_dir='./dataset/test/')
final_predict_val = []
final_predict_index = []
groundtruth = []
with tf.Session(config=tf.ConfigProto(gpu_options=gpu_options,allow_soft_placement=True)) as sess:
test_images, test_labels = test_feeder.input_pipeline(batch_size=FLAGS.batch_size, num_epochs=1)
graph = build_graph(top_k=5)
saver = tf.train.Saver()
sess.run(tf.global_variables_initializer())
sess.run(tf.local_variables_initializer()) # initialize test_feeder's inside state
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
ckpt = tf.train.latest_checkpoint(FLAGS.checkpoint_dir)
if ckpt:
saver.restore(sess, ckpt)
print("restore from the checkpoint {0}".format(ckpt))
logger.info(':::Start validation:::')
try:
i = 0
acc_top_1, acc_top_k = 0.0, 0.0
while not coord.should_stop():
i += 1
start_time = time.time()
test_images_batch, test_labels_batch = sess.run([test_images, test_labels])
feed_dict = {graph['images']: test_images_batch,
graph['labels']: test_labels_batch,
graph['keep_prob']: 1.0,
graph['is_training']: False}
batch_labels, probs, indices, acc_1, acc_k = sess.run([graph['labels'],
graph['predicted_val_top_k'],
graph['predicted_index_top_k'],
graph['accuracy'],
graph['accuracy_top_k']], feed_dict=feed_dict)
final_predict_val += probs.tolist()
final_predict_index += indices.tolist()
groundtruth += batch_labels.tolist()
acc_top_1 += acc_1
acc_top_k += acc_k
end_time = time.time()
logger.info("the batch {0} takes {1} seconds, accuracy = {2}(top_1) {3}(top_k)"
.format(i, end_time - start_time, acc_1, acc_k))
except tf.errors.OutOfRangeError:
logger.info('==================Validation Finished================')
acc_top_1 = acc_top_1 * FLAGS.batch_size / test_feeder.size
acc_top_k = acc_top_k * FLAGS.batch_size / test_feeder.size
logger.info('top 1 accuracy {0} top k accuracy {1}'.format(acc_top_1, acc_top_k))
finally:
coord.request_stop()
coord.join(threads)
return {'prob': final_predict_val, 'indices': final_predict_index, 'groundtruth': groundtruth}
5 text prediction
In the step we just did, we only used the data set we generated as the test set to test the model performance. This test is not accurate, because the text samples we need to recognize daily will not be as stable and regular as the text we synthesized. Then we try to use the model to recognize the characters of some actual scenes, and really investigate the generalization ability of the model.
First, write the prediction code
def inference(name_list):
print('inference')
image_set=[]
# The dimensions of each drawing are standardized and normalized
for image in name_list:
temp_image = Image.open(image).convert('L')
temp_image = temp_image.resize((FLAGS.image_size, FLAGS.image_size), Image.ANTIALIAS)
temp_image = np.asarray(temp_image) / 255.0
temp_image = temp_image.reshape([-1, 64, 64, 1])
image_set.append(temp_image)
# allow_soft_placement if the device you specified does not exist, TF is allowed to automatically allocate the device
with tf.Session(config=tf.ConfigProto(gpu_options=gpu_options,allow_soft_placement=True)) as sess:
logger.info('========start inference============')
# images = tf.placeholder(dtype=tf.float32, shape=[None, 64, 64, 1])
# Pass a shadow label 0. This label will not affect the computation graph.
graph = build_graph(top_k=3)
saver = tf.train.Saver()
# Automatically get the last saved model
ckpt = tf.train.latest_checkpoint(FLAGS.checkpoint_dir)
if ckpt:
saver.restore(sess, ckpt)
val_list=[]
idx_list=[]
# Predict each chart
for item in image_set:
temp_image = item
predict_val, predict_index = sess.run([graph['predicted_val_top_k'], graph['predicted_index_top_k']],
feed_dict={graph['images']: temp_image,
graph['keep_prob']: 1.0,
graph['is_training']: False})
val_list.append(predict_val)
idx_list.append(predict_index)
#return predict_val, predict_index
return val_list,idx_list
It needs to be explained here that I will store the text images I want to recognize in a folder called tmp, and the images in it are numbered in sequence. When we recognize, we will read all the pictures from this directory and only memory for recognition one by one.
# Get the image name in the image folder to be predicted
def get_file_list(path):
list_name=[]
files = os.listdir(path)
files.sort()
for file in files:
file_path = os.path.join(path, file)
list_name.append(file_path)
return list_name
Then we use the trained model to predict Chinese characters and observe the effect. First, I used the screenshot tool to intercept a text from a paper pdf, and then used the text cutting algorithm to cut the text paragraphs into words. As shown in the figure below, some words were discarded because a small number of words failed to be cut.
Use the screenshot tool to capture text paragraphs from an article.
Cut out words, white words on a black background.

Awesome Chinese characters are identified by the combination of all the identifying words in paragraphs. It shows that our OCR system based on deep learning is quite powerful.

So far, the OCR system supporting 3755 Chinese character recognition has been built. After testing, the effect is still very good. This is a model without much optimization. The accuracy of top 1 is 99.9%, which is awesome. In some ideal environments, the effect of text recognition is more powerful. But for complex scenes, some of the larger interference text images may not be ideal. This requires further optimization for specific scenarios.
6 finally - design help
Bi design help, problem opening guidance, technical solutions 🇶746876041