Daily Share:
Never start self-denial because of the denial of others. Life is a subjective process. Whether people like you or not is actually a matter of the other side's world. So when people don't like you, don't feel inferior and don't mean to be nice. You should focus on being yourself.
Idea analysis:
- URL (url of web page)
- Create driver Object
- Send get request
- parse data
- save data
- Page Flip
Repeatedly perform 4, 5, 6 operations in a loop and jump out of the loop if you reach the last page.
And some of the other issues I encounter when writing code:
- Use xpath to find the element you are looking for, but if you want to click on it, you need to slide down the page to have it on the page before you can click on it
- With regard to the crawling of cover pictures of each room in the fighting fish, I spent a lot of time trying. I felt I should set up a reverse crawl, crawl directly, crawl to three pictures, then set the hibernation time, crawl to several pictures, and crawl to less than ten pictures in 20s. (Because he is also a beginner, and has not yet learned anti-crawling, anti-crawling, so he gave up)
- time.sleep(1) must be written before the sliding operation (sleep time set by myself), and I was here for a long time because I found that the web page was not sliding, so it also led to "Next Page" "This element failed to click. If you do not set a second of hibernation, on closer inspection, you will find that it is not that the page does not slip, but that the page slides down and then goes back to the top, which may be a kind of anti-crawling.
- It is recommended that the xpath on the next page be written in a reliable way, such as content lookup; the xpath of the label that was copied directly at that time would cause an error when turning over to the fourth page, possibly because the xpath could not be found
- Source comments are more detailed
- If I crawled all (I was over 200 pages at that time), it would take a long time to crawl
The source code is as follows:
from selenium import webdriver
import time
class Dou_yu(object):
def __init__(self):
self.url = 'https://www.douyu.com/directory/all'
self.driver = webdriver.Chrome()
def parse_data(self):
# It is recommended to add this hibernation, otherwise the page may not load completely and crawl fails due to network speed problems
time.sleep(3)
# Store all rooms on each page in a list
room_list = self.driver.find_elements('xpath', '//*[@id="listAll"]/section[2]/div[2]/ul/li/div')
# 120, proof no error
# print(len(room_list))
# Create lists to temporarily store crawled information
data_list = []
for room in room_list:
# Put the crawled information into the dictionary
tmp = {}
tmp['title'] = room.find_element('xpath', './a/div[2]/div[1]/h3').get_attribute('textContent')
tmp['type'] = room.find_element('xpath', './a/div[2]/div[1]/span').get_attribute('textContent')
tmp['owner'] = room.find_element('xpath', './a/div[2]/div[2]/h2/div').get_attribute('textContent')
tmp['popularity'] = room.find_element('xpath', './a/div[2]/div[2]/span').get_attribute('textContent')
data_list.append(tmp)
# tmp['picture'] = room.find_element('xpath', './a/div[1]/div[1]/picture/img').get_attribute('src')
# print(tmp)
return data_list
def save_data(self, data_list):
# Convert to str first for easy file writing
data_list = str(data_list)
with open('Dogfish.txt', 'a', encoding='utf-8')as f:
f.write(data_list+'\n')
def run(self):
self.driver.get(self.url)
# url
# Create driver
# Send get
# parse-data
while True:
data_list = self.parse_data()
# save-data
self.save_data(data_list)
# Page Flip
# This time.sleep(1) has to be written (sleep time set by myself), and I was here for a long time because I found that the web page was not sliding, so it also led to "Next Page" "This element failed to click. If you do not set a second of hibernation, on closer inspection, you will find that it is not that the page does not slip, but that the page slides down and then goes back to the top, which may be a kind of anti-crawling.
time.sleep(1)
# Set a larger value and slide to the bottom
js = 'scrollTo(0,10000)'
# Execute js code
self.driver.execute_script(js)
# Looking closely at the first and last pages of the live game, the aria-disabled values in the li tag they belong to are different, not faule at the end, true at the end, and jump out of the loop after the end
if self.driver.find_element('xpath', '//li[@title="next page"]'.get_attribute ('aria-disabled') =='true':
break
# Find the next page button and click
self.driver.find_element('xpath', '//span[contains(text(), "next page"]'). click()
if __name__ == '__main__':
dou_yu = Dou_yu()
dou_yu.run()
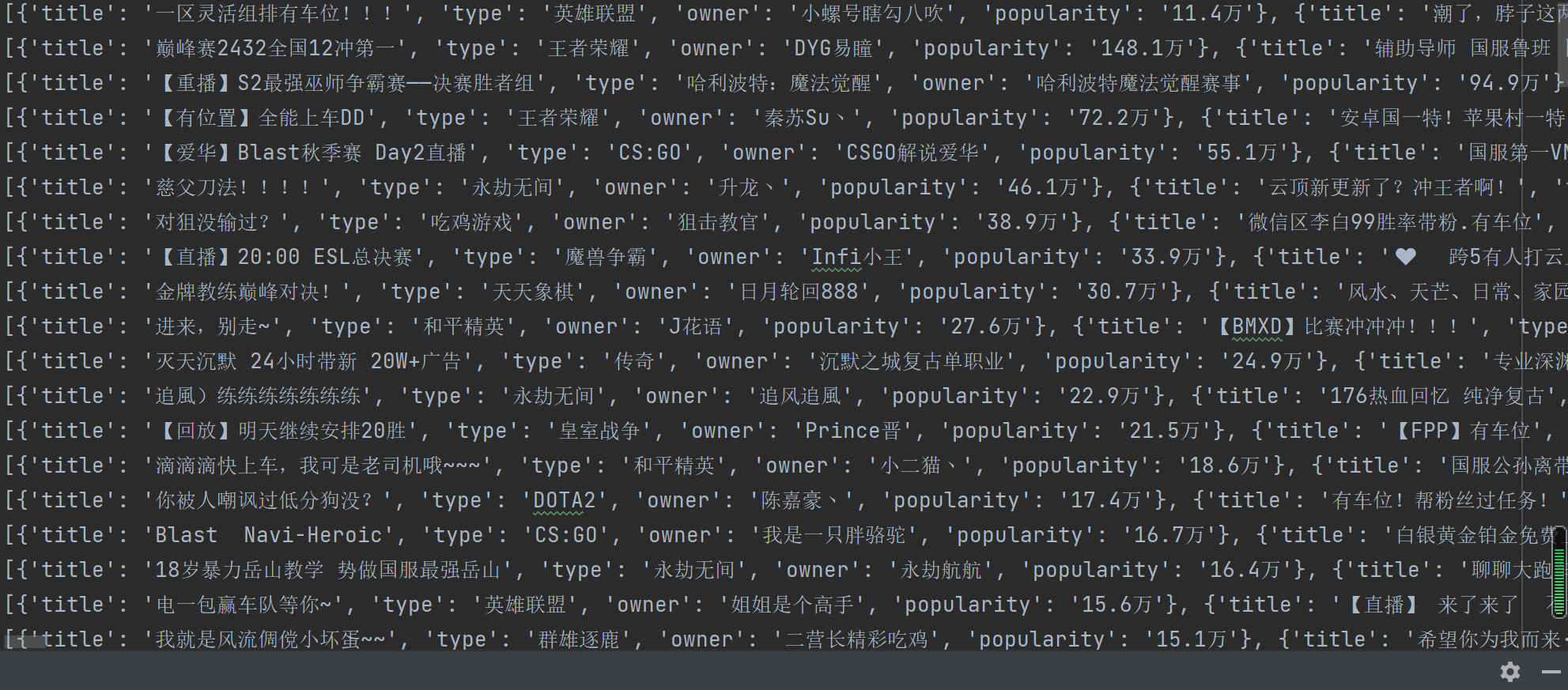
Some results are as follows: