Subquery refers to a query in which one query statement is nested inside another query statement. This feature has been introduced since MySQL 4.1. The use of SQL sub query greatly enhances the ability of SELECT query, because many times the query needs to obtain data from the result set, or calculate a data result from the same table, and then compare it with the data result (which may be a scalar or a set).
1. Demand analysis and problem solving
1.1 practical problems
#Mode 1: SELECT salary FROM employees WHERE last_name = 'Abel'; SELECT last_name,salary FROM employees WHERE salary > 11000; #Mode 2: self connection SELECT e2.last_name,e2.salary FROM employees e1,employees e2 WHERE e1.last_name = 'Abel' AND e1.`salary` < e2.`salary`; #Method 3: sub query SELECT last_name,salary FROM employees WHERE salary > ( SELECT salary FROM employees WHERE last_name = 'Abel' );
1.2 basic usage of sub query
Basic syntax structure of subquery:
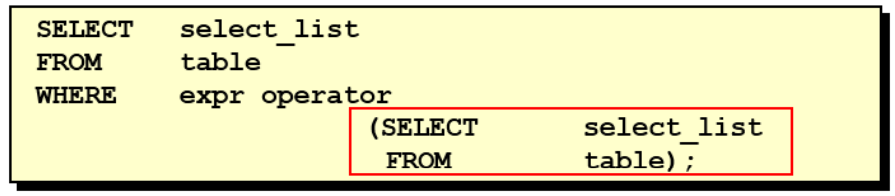
The sub query (internal query) is executed once before the main query.
The results of the sub query are used by the main query (external query).
matters needing attention:
① Subqueries should be enclosed in parentheses.
② Place the subquery to the right of the comparison criteria.
③ Single row operators correspond to single row subqueries, and multi row operators correspond to multi row subqueries.
1.3 classification of sub query
Classification method 1: sub query is divided into single line sub query and multi line sub query according to whether one or more records are returned according to the results of internal query.
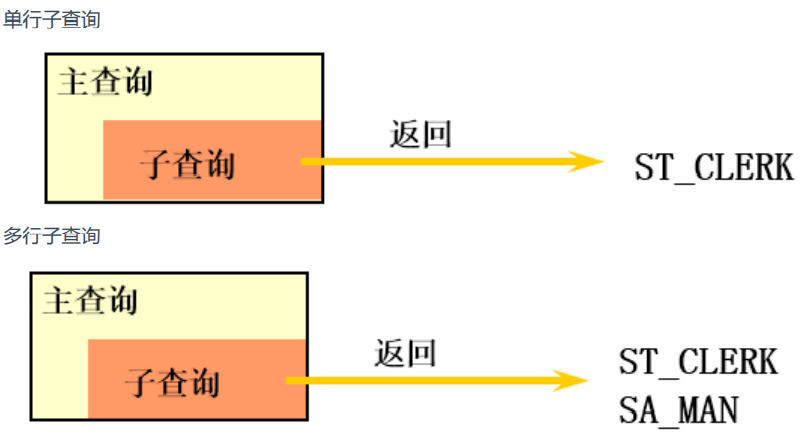
Classification method 2: sub queries are divided into related (or associated) sub queries and unrelated (or non associated) sub queries according to whether the internal query has been executed multiple times.
The sub query queries the data result from the data table. If the data result is executed only once, and then the data result is executed as the condition of the main query, such a sub query is called irrelevant sub query.
Similarly, if the sub query needs to be executed multiple times, that is, in a circular way, start from the external query, pass in the sub query for query each time, and then feed back the results to the external, this nested execution method is called related sub query.
2. Single line subquery
2.1 single line comparison operator

2.2 code example
#Return job_ The ID is the same as that of employee 141. Salary is more than that of employee 143_ ID and salary. SELECT last_name, job_id, salary FROM employees WHERE job_id = (SELECT job_id FROM employees WHERE employee_id = 141) AND salary > (SELECT salary FROM employees WHERE employee_id = 143);
2.3 sub query in having
Execute the subquery first, and then return the results to the HAVING clause in the main query.
#Query the Department id and the minimum wage of the Department whose minimum wage is greater than the minimum wage of No. 50 department. SELECT department_id, MIN(salary) FROM employees GROUP BY department_id HAVING MIN(salary) > (SELECT MIN(salary) FROM employees WHERE department_id = 50);
2.4 sub query in case
To use a single column subquery in a CASE expression:
#Explicit employee_id,last_name and location. Where, if the employee department_id and location_ Department with ID 1800_ If the ID is the same, the location is' Canada ', and the rest is' USA'. SELECT employee_id, last_name,CASE department_id WHEN (SELECT department_id FROM departments WHERE location_id = 1800) THEN 'Canada' ELSE 'USA' END location FROM employees;
3. Multiline subquery
① Also called collection comparison subquery
② Multiple rows returned by internal query
③ Using multiline comparison operators
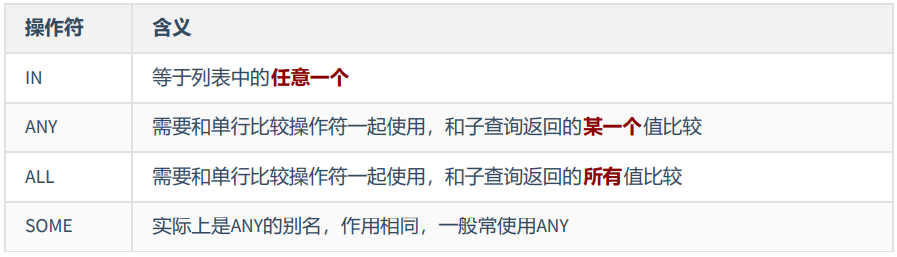
3.1 multiline comparison operator
3.2 code examples
Return other jobs_ Job in ID_ ID is' it '_ Prog 'employee number, name and job of any employee with low salary in the Department_ ID and salary.

Return other jobs_ Job in ID_ ID is' it '_ Prog 'employee number, name and job of all employees with low salary in the Department_ ID and salary.
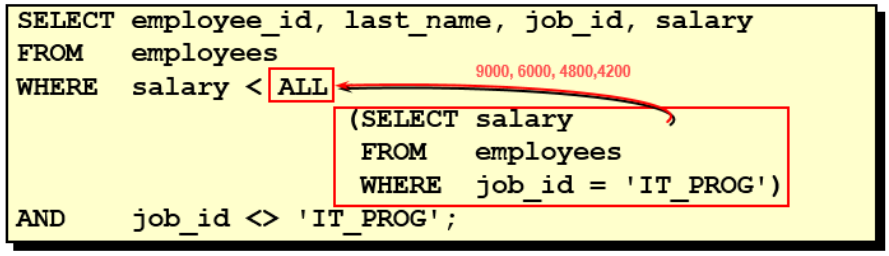
#Query the Department id with the lowest average wage SELECT department_id FROM employees GROUP BY department_id HAVING AVG(salary) <= ALL ( SELECT AVG(salary) FROM employees GROUP BY department_id );
4. Related sub query
4.1 related sub query execution process
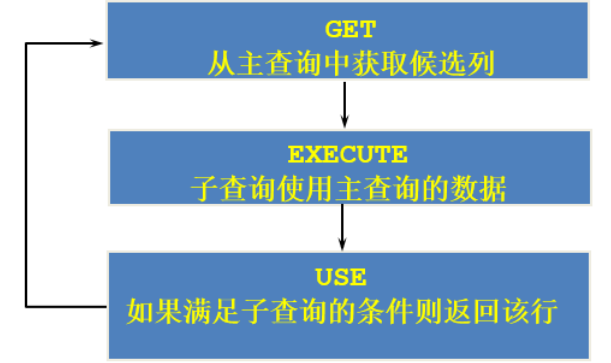
If the execution of a subquery depends on an external query, it is usually because the tables in the subquery use external tables and are conditionally associated. Therefore, every time an external query is executed, the subquery must be recalculated. Such a subquery is called an associated subquery. Related sub queries are executed row by row, and sub queries are executed once for each row of the main query.

4.2 code examples
Title: query the last of employees whose salary is greater than the average salary of the Department_ Name, salary and their department_id
Method 1: related sub query

Method 2: use sub query in FROM
SELECT last_name,salary,e1.department_id FROM employees e1,(SELECT department_id,AVG(salary) dept_avg_sal FROM employees GROUP BY department_id) e2 WHERE e1.`department_id` = e2.department_id AND e2.dept_avg_sal < e1.`salary`;
From type sub query: the sub query is a part of from. The sub query should be led with (), and the sub query should be aliased and used as a "temporary virtual table".
Use subquery in ORDER BY:
#Query employee id,salary, by department_name sort SELECT employee_id,salary FROM employees e ORDER BY ( SELECT department_name FROM departments d WHERE e.`department_id` = d.`department_id` );
4.3 EXISTS and NOT EXISTS keywords
The associated subquery is usually used together with the EXISTS operator to check whether there are qualified rows in the subquery.
If there are no qualified rows in the subquery:
If the condition returns FALSE, continue to find in the sub query.
If there are qualified rows in the subquery:
Do not continue to search in the subquery, and the condition returns TRUE.
NOT EXISTS keyword indicates that if there is no condition, it returns TRUE; otherwise, it returns FALSE.
Title: query the employees of company managers_ id,last_name,job_id,department_id information
#Mode 1 SELECT employee_id, last_name, job_id, department_id FROM employees e1 WHERE EXISTS ( SELECT * FROM employees e2 WHERE e2.manager_id =e1.employee_id); #Mode 2: self connection SELECT DISTINCT e1.employee_id, e1.last_name, e1.job_id, e1.department_id FROM employees e1 JOIN employees e2 WHERE e1.employee_id = e2.manager_id; #Mode III SELECT employee_id,last_name,job_id,department_id FROM employees WHERE employee_id IN ( SELECT DISTINCT manager_id FROM employees );
4.4 relevant updates
UPDATE table1 alias1 SET column = (SELECT expression FROM table2 alias2 WHERE alias1.column = alias2.column);
Use related subqueries to update data from one table to another.
4.4 relevant deletion
DELETE FROM table1 alias1 WHERE column operator (SELECT expression FROM table2 alias2 WHERE alias1.column = alias2.column);
Use related subqueries to delete data from one table based on data from another.
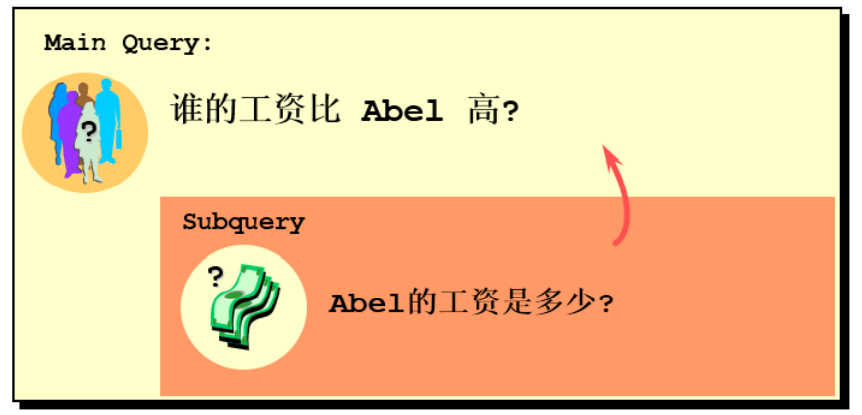
5. Throw a question
Whose salary is higher than Abel's?
#Mode 1: self connection SELECT e2.last_name,e2.salary FROM employees e1,employees e2 WHERE e1.last_name = 'Abel' AND e1.`salary` < e2.`salary` #Method 2: sub query SELECT last_name,salary FROM employees WHERE salary > ( SELECT salary FROM employees WHERE last_name = 'Abel' );
Are the above two methods good or bad?
Good self connection mode!
Subqueries or self connections can be used in topics. In general, it is recommended to use self join, because in the processing of many DBMS, the processing speed of self join is much faster than that of sub query. It can be understood that sub query is actually the condition judgment after query through unknown tables, while self connection is the condition judgment through known self data tables. Therefore, self connection processing is optimized in most DBMS.