Zero, write in front
First of all, it is purely entertainment, and there are many loose places!!
Mankiw's macroeconomics mentioned an example when talking about the CPI (consumer price index), that is, avatar ranked first at the box office with us $761 million at that time, but after considering inflation, avatar dropped to 14, but gone with the wind ranked first in 1939.
Then today, I saw that hot search said that "Changjin Lake" has become the box office champion in Chinese film history, so I want to see if our country's box office ranking will change after considering inflation hhh! Again, it's pure entertainment!
1, Total box office data of mainland films
The box office data comes from the general list of mainland box offices-- Art grace entertainment number
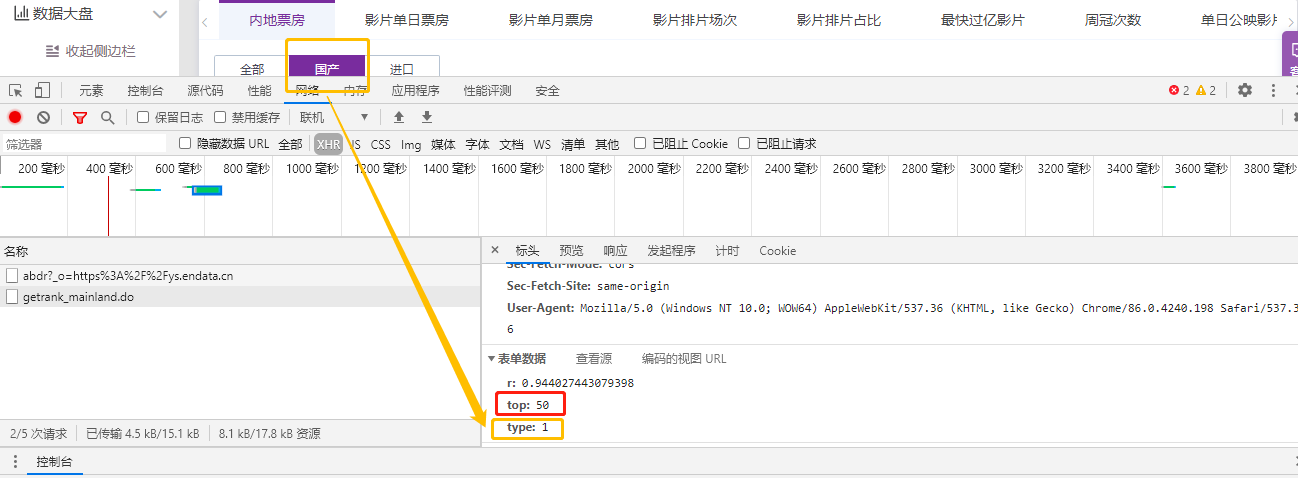
Open F12, select network, select XHR format, and finally select response, as shown in the following figure!
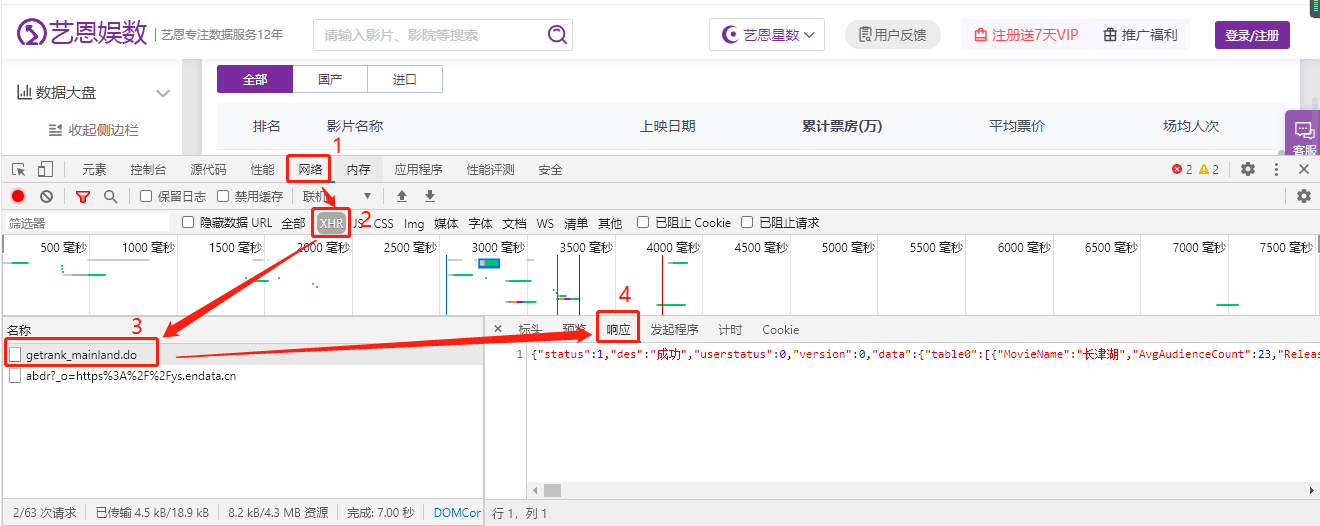
By viewing the response, you can find that the Post request returns a JSON. If you can see the internal data of JSON more clearly, you can use the website to format JSON, such as Online JSON verification formatting tool (Be JSON) . After formatting JSON, you can clearly see that the data includes the data we need most, that is, movie name, release time and cumulative box office. JSON format is shown in the following figure:
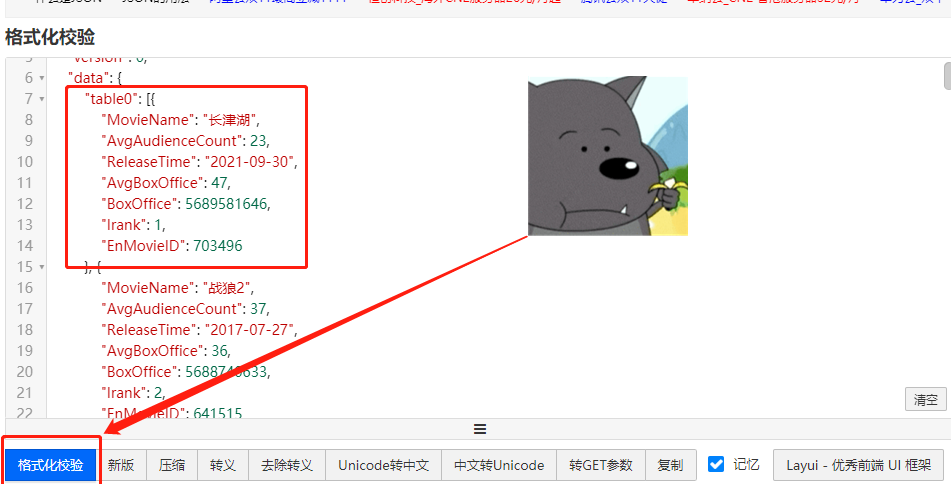
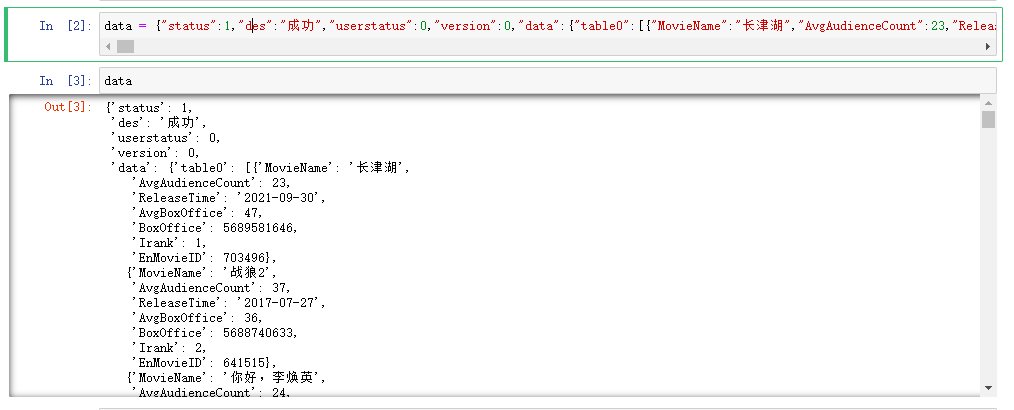
As like as two peas, the simplest way is to copy the JSON string directly into the Python code, and you can see that the same effect is being applied to the website format. See the figure below.
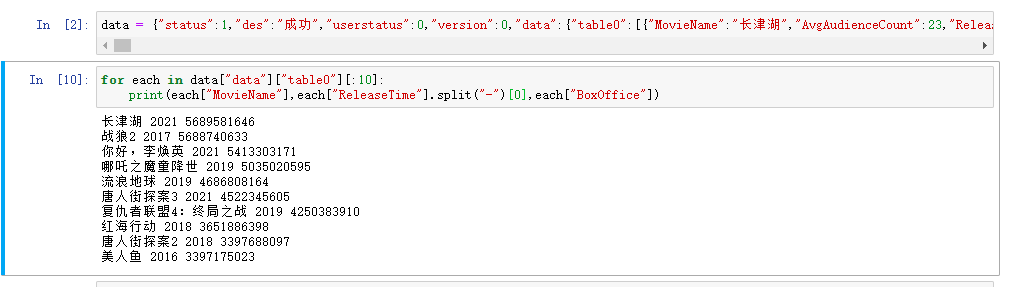
At this time, you can use the data variable as a dictionary type, and use the split function to process the release time, so that the time field only contains the release year. The details are shown in the figure below. You can see the title, release year and box office of the first 10 data printed respectively.
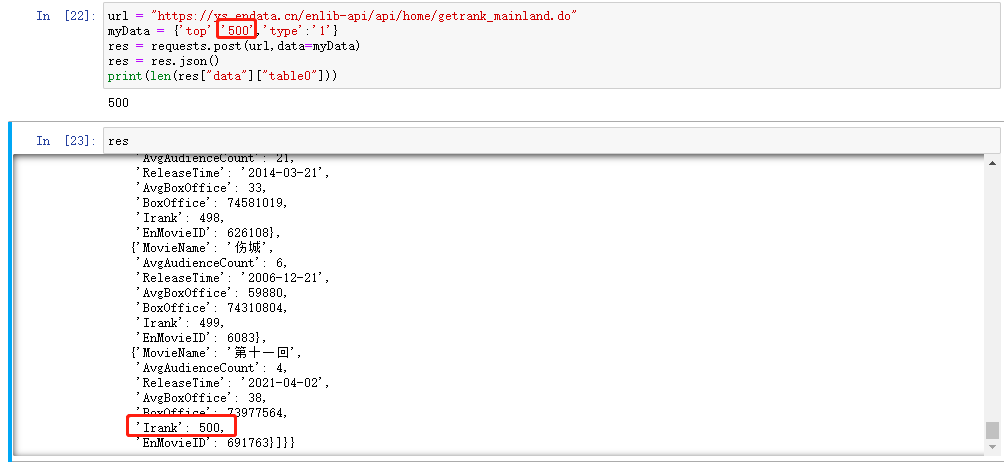
But at this time, I found a very embarrassing thing, that is, the front-end interface of the website only displays the top 50 box office. embarrassed!
However, it doesn't matter. We take a closer look at the post returned to the JSON and find that the mystery is in the "top:50", so the request only returns the top 50 rankings to the front-end interface. At the same time, we note that "type:1", which is used to distinguish all, domestic and imported! Readers can try. When they choose to import, the type will become 2.
Good luck. You can get the return directly by using the simplest Post. As can be seen from the figure below, we have successfully obtained the data of the top 500, jumping out of the limitations of the front-end interface. This situation can often be found when writing crawlers. The data sent by the server to the front end is only selectively displayed on the front end. For example, the loan data of Renren loan cannot be seen from the interface, but through F12, it can be found that the data returned by the server contains the field of loan reason, but it is not displayed on the front end.
Then these data are stored in the DataFrame of pandas for post-processing. The detailed codes and results are as follows:
dataDf = pd.DataFrame()
for myIndex,each in enumerate(res["data"]["table0"]):
dataDf = dataDf.append(pd.DataFrame({"MovieName":each["MovieName"],
"ReleaseTime":each["ReleaseTime"].split("-")[0],
"BoxOffice":each["BoxOffice"]},index=[myIndex]))
dataDf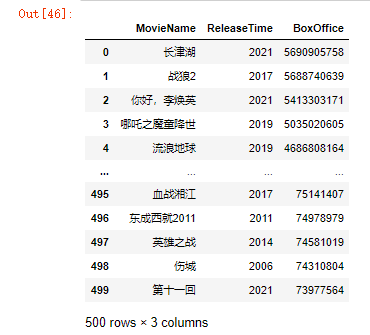
At this time, you can draw the total box office ranking of the mainland without inflation correction!! The code and diagram are shown below:
pandas.plot() reference: [python] explain the drawing function of pandas.DataFrame.plot()_ Brucewong 0516 blog - CSDN blog
#kind:barh transverse bar graph
#figsize: picture size
#legend=False: do not display legend
#Color: set color
#fontsize: sets the label text size
#List [:: - 1] - > reverse order
dataDf[:20][::-1].plot("MovieName","BoxOffice",kind='barh',figsize=(16,8),fontsize=15,legend=False,
color=["grey","gold","darkviolet","turquoise","r","g","b","c",
"k","darkorange","lightgreen","plum", "tan","khaki", "pink", "skyblue","lawngreen","salmon"])
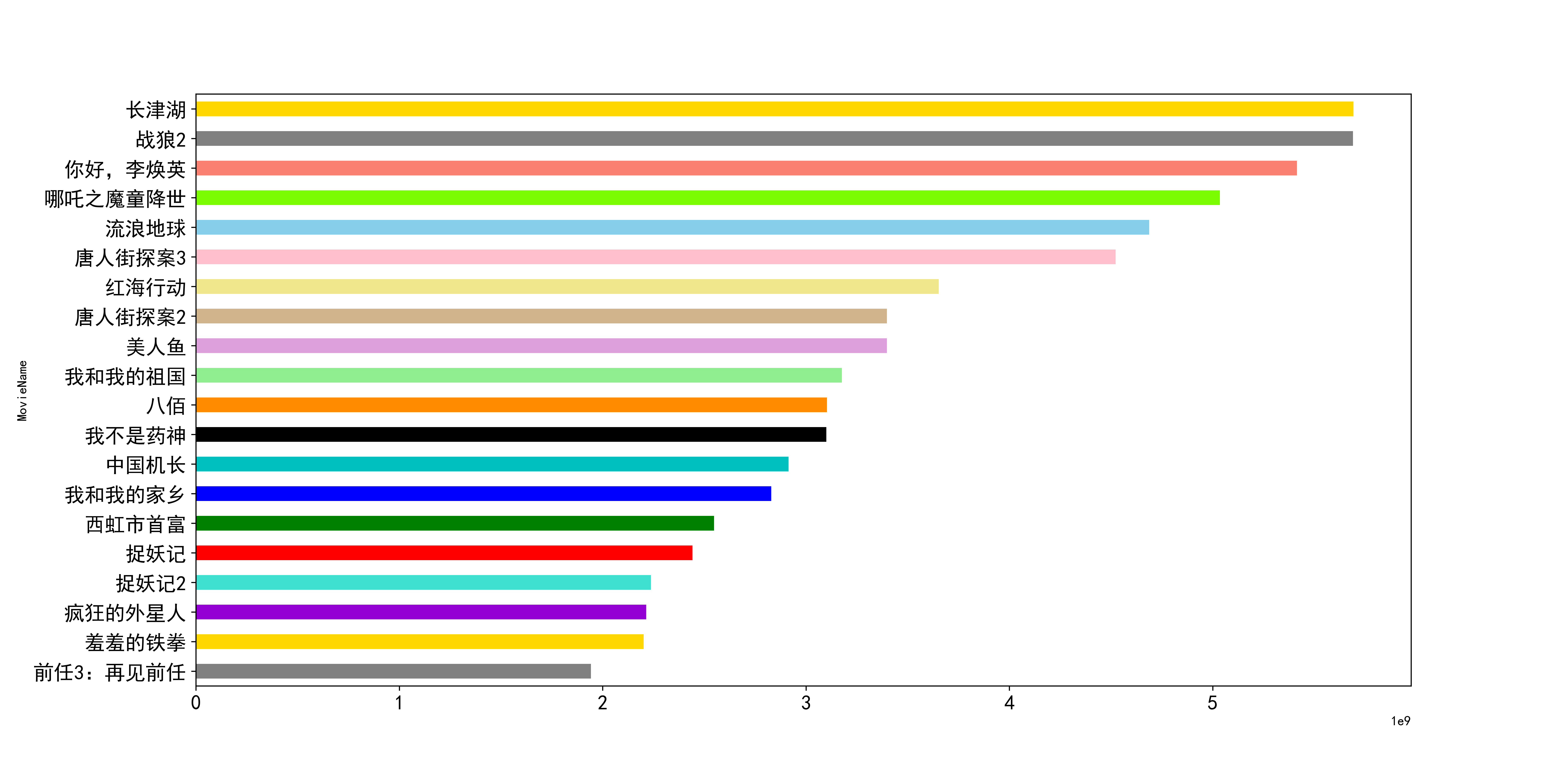
So far, the data processing of the film list is temporarily stopped. Next, it is necessary to add indicators to measure the price level.
2, Correcting box office with price level
Originally thought that CPI could be used for correction, but after reading the CPI data, it was found that CPI was basically very stable. I was greatly surprised. I clearly felt that since I was a child, the total price has risen slightly. Why is the CPI quite stable. If you are interested, you can search the reasons. It's very interesting.
So what is the better way to measure price ability? Haha, I don't know. Many indicators are inappropriate. The most appropriate one is the monetary purchasing power index, but no data is found.
So the entertainment part officially begins!!!
On how to measure money purchasing power, this paper refers to the following articles: 100 yuan purchasing power! The evolution history of 70 years (1950-2020) witnessed the country's development, inflation and planned economy_ Netease subscription
The article says that 100 yuan in the 1990s is about 1000 yuan in 2020; 100 yuan in the 1920s is equivalent to 300-400 yuan in 2020, taking 350 yuan; 100 yuan in the decade of the 21st century is about 157 yuan in 2020.
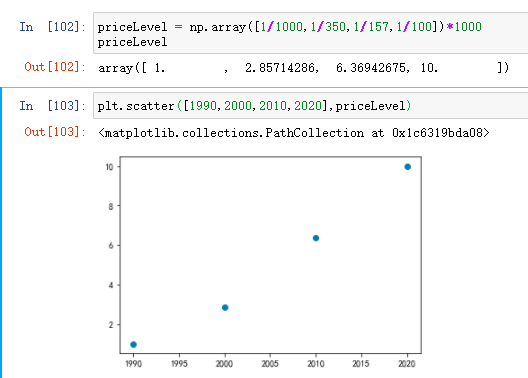
Therefore, based on 1990, the price levels are 1 (1990), 2.86 (2000), 6.37 (2010) and 10 (2020) respectively

Then look at the distribution of the release time of the top 500 films. As shown in the figure below, the earliest release time is 2000, so our price level needs to be from 2000 to 2021.
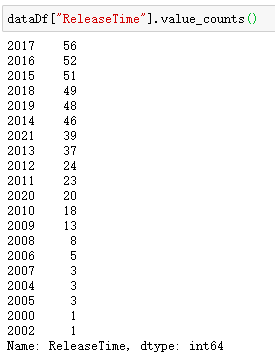
So the problem is, we need 21 years of data, but we only have 4 years of price level, so what should we do?
Hahaha, after all, it's entertainment. Just make do with it!
From the picture, the distribution of the four points is still straight. Use the least square method to fit a straight line!
Least squares Code:
#Least squares OLS
def standRegres(xArr,yArr):
xMat = mat(xArr)
yMat = mat(yArr).T
xTx = xMat.T*xMat
if linalg.det(xTx) == 0.0:
print("singular")
return
ws = xTx.I * (xMat.T*yMat)
# print(ws)
return wsThe specific fitting conditions are as follows, and the error is OK:
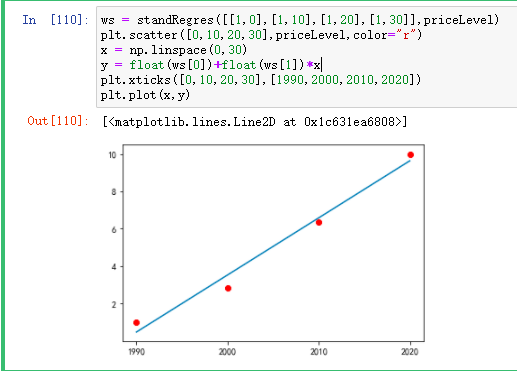
Therefore, the price level from 2000 to 2021 can be calculated through the following code:
priceLevelNew = []
for each in range(10,32):
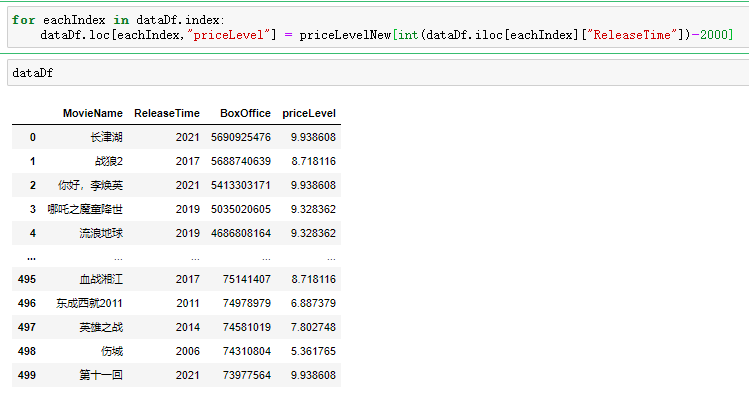
priceLevelNew.append(float(ws[0])+float(ws[1])*each)Therefore, the current idea is very clear, that is, add the price level of the corresponding year in Df in Section 1, and then correct the box office data. The specific code and results are shown in the figure below. From the figure, we can see that the price level has been matched to the corresponding release year.
Finally, we can roughly correct the currency in different periods through the price level, that is:
The number of RMB in this year = the number of RMB in t * the price level of this year / the price level of T
Sort according to the corrected box office. The codes and results are as follows:
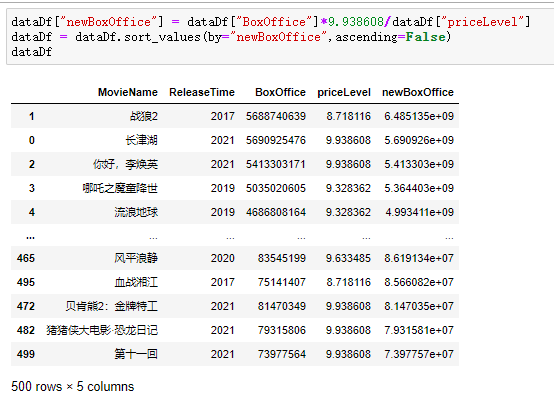
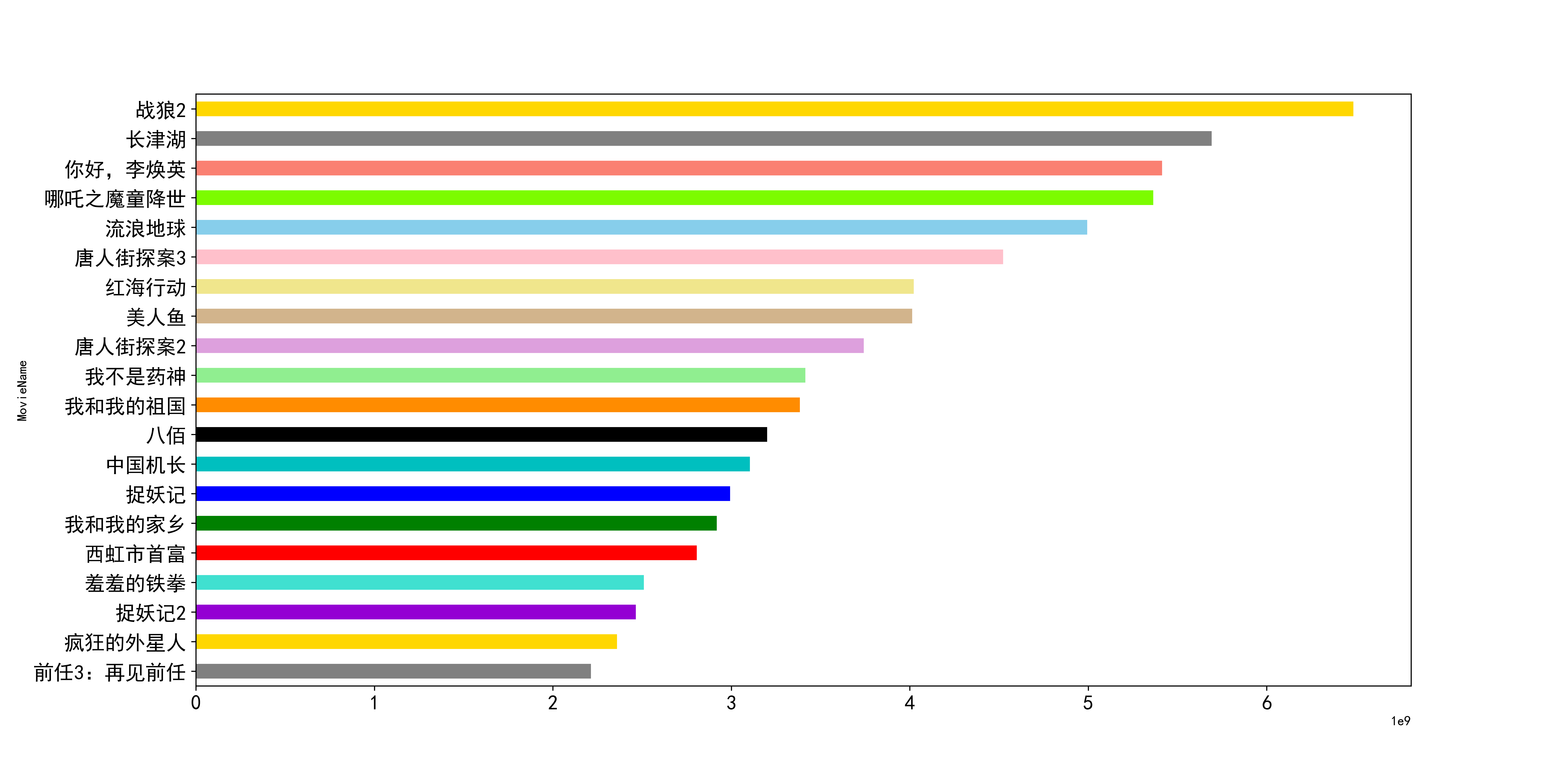
Finally, we draw the revised ranking:
3, Finally
Ha ha, embarrassing conclusion, the ranking has not changed much.
However, at least some areas can be improved. For example, not only consider the top 500 box offices in the current box office list, make the year of film distribution as far away as possible from now, but also improve the index to measure the price level hhh!
I'll say, this post is purely entertainment, believe it or not!
4, Code
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import cm
from pylab import *
import requests
plt.rcParams['axes.unicode_minus']=False #Used to solve the problem that negative signs cannot be displayed
mpl.rcParams['font.sans-serif'] = ['SimHei']
#Least squares OLS
def standRegres(xArr,yArr):
xMat = mat(xArr)
yMat = mat(yArr).T
xTx = xMat.T*xMat
if linalg.det(xTx) == 0.0:
print("This matrix is singular, cannot do inverse")
return
ws = xTx.I * (xMat.T*yMat)
# print(ws)
return ws
data = {"status":1,"des":"success","userstatus":0,"version":0,"data":{"table0":[{"MovieName":"Changjin Lake","AvgAudienceCount":23,"ReleaseTime":"2021-09-30","AvgBoxOffice":47,"BoxOffice":5689581646,"Irank":1,"EnMovieID":703496},{"MovieName":"Warwolf 2","AvgAudienceCount":37,"ReleaseTime":"2017-07-27","AvgBoxOffice":36,"BoxOffice":5688740633,"Irank":2,"EnMovieID":641515},{"MovieName":"Hello, Li Huanying","AvgAudienceCount":24,"ReleaseTime":"2021-02-12","AvgBoxOffice":45,"BoxOffice":5413303171,"Irank":3,"EnMovieID":662746},{"MovieName":"Nezha's demon child came into the world","AvgAudienceCount":23,"ReleaseTime":"2019-07-26","AvgBoxOffice":36,"BoxOffice":5035020595,"Irank":4,"EnMovieID":662685},{"MovieName":"Wandering the earth","AvgAudienceCount":29,"ReleaseTime":"2019-02-05","AvgBoxOffice":45,"BoxOffice":4686808164,"Irank":5,"EnMovieID":642412},{"MovieName":"Chinatown detective 3","AvgAudienceCount":29,"ReleaseTime":"2021-02-12","AvgBoxOffice":48,"BoxOffice":4522345605,"Irank":6,"EnMovieID":676314},{"MovieName":"Avengers 4: the final battle","AvgAudienceCount":23,"ReleaseTime":"2019-04-24","AvgBoxOffice":49,"BoxOffice":4250383910,"Irank":7,"EnMovieID":670808},{"MovieName":"Operation Red Sea","AvgAudienceCount":33,"ReleaseTime":"2018-02-16","AvgBoxOffice":39,"BoxOffice":3651886398,"Irank":8,"EnMovieID":655823},{"MovieName":"Chinatown detective 2","AvgAudienceCount":39,"ReleaseTime":"2018-02-16","AvgBoxOffice":39,"BoxOffice":3397688097,"Irank":9,"EnMovieID":663419},{"MovieName":"mermaid","AvgAudienceCount":43,"ReleaseTime":"2016-02-08","AvgBoxOffice":37,"BoxOffice":3397175023,"Irank":10,"EnMovieID":626153},{"MovieName":"Me and my country","AvgAudienceCount":35,"ReleaseTime":"2019-09-30","AvgBoxOffice":38,"BoxOffice":3176119334,"Irank":11,"EnMovieID":691481},{"MovieName":"eight hundred","AvgAudienceCount":20,"ReleaseTime":"2020-08-21","AvgBoxOffice":38,"BoxOffice":3102323734,"Irank":12,"EnMovieID":669412},{"MovieName":"I'm not a god of medicine","AvgAudienceCount":27,"ReleaseTime":"2018-07-05","AvgBoxOffice":35,"BoxOffice":3099961063,"Irank":13,"EnMovieID":676313},{"MovieName":"Chinese Captain","AvgAudienceCount":26,"ReleaseTime":"2019-09-30","AvgBoxOffice":37,"BoxOffice":2913117677,"Irank":14,"EnMovieID":681319},{"MovieName":"My People, My Homeland","AvgAudienceCount":19,"ReleaseTime":"2020-10-01","AvgBoxOffice":39,"BoxOffice":2828832552,"Irank":15,"EnMovieID":701620},{"MovieName":"Speed and passion 8","AvgAudienceCount":30,"ReleaseTime":"2017-04-14","AvgBoxOffice":37,"BoxOffice":2670959285,"Irank":16,"EnMovieID":659757},{"MovieName":"The richest man in Xihong City","AvgAudienceCount":28,"ReleaseTime":"2018-07-27","AvgBoxOffice":35,"BoxOffice":2547571742,"Irank":17,"EnMovieID":671983},{"MovieName":"Demon catching","AvgAudienceCount":41,"ReleaseTime":"2015-07-16","AvgBoxOffice":37,"BoxOffice":2441462276,"Irank":18,"EnMovieID":627896},{"MovieName":"Speed and passion 7","AvgAudienceCount":42,"ReleaseTime":"2015-04-12","AvgBoxOffice":39,"BoxOffice":2426586547,"Irank":19,"EnMovieID":629625},{"MovieName":"Avengers 3: Infinite War","AvgAudienceCount":19,"ReleaseTime":"2018-05-11","AvgBoxOffice":38,"BoxOffice":2390537273,"Irank":20,"EnMovieID":675789},{"MovieName":"Demon catching 2","AvgAudienceCount":44,"ReleaseTime":"2018-02-16","AvgBoxOffice":38,"BoxOffice":2237154621,"Irank":21,"EnMovieID":656875},{"MovieName":"Crazy aliens","AvgAudienceCount":30,"ReleaseTime":"2019-02-05","AvgBoxOffice":42,"BoxOffice":2214254201,"Irank":22,"EnMovieID":638300},{"MovieName":"Iron fist of shame","AvgAudienceCount":25,"ReleaseTime":"2017-09-30","AvgBoxOffice":33,"BoxOffice":2201748735,"Irank":23,"EnMovieID":661004},{"MovieName":"dominant sea power","AvgAudienceCount":18,"ReleaseTime":"2018-12-07","AvgBoxOffice":36,"BoxOffice":2013198359,"Irank":24,"EnMovieID":665526},{"MovieName":"Transformers 4: extinction and rebirth","AvgAudienceCount":50,"ReleaseTime":"2014-06-27","AvgBoxOffice":42,"BoxOffice":1977522388,"Irank":25,"EnMovieID":612232},{"MovieName":"Ex 3: goodbye, ex","AvgAudienceCount":29,"ReleaseTime":"2017-12-29","AvgBoxOffice":35,"BoxOffice":1941740154,"Irank":26,"EnMovieID":663359},{"MovieName":"Venom: deadly Guardian","AvgAudienceCount":17,"ReleaseTime":"2018-11-09","AvgBoxOffice":36,"BoxOffice":1870680440,"Irank":27,"EnMovieID":662209},{"MovieName":"Kung Fu Yoga","AvgAudienceCount":33,"ReleaseTime":"2017-01-28","AvgBoxOffice":38,"BoxOffice":1752603744,"Irank":28,"EnMovieID":629898},{"MovieName":"Gallop life","AvgAudienceCount":25,"ReleaseTime":"2019-02-05","AvgBoxOffice":42,"BoxOffice":1729373180,"Irank":29,"EnMovieID":676018},{"MovieName":"Fire Hero","AvgAudienceCount":19,"ReleaseTime":"2019-08-01","AvgBoxOffice":36,"BoxOffice":1707188998,"Irank":30,"EnMovieID":692321},{"MovieName":"Jurassic world 2","AvgAudienceCount":19,"ReleaseTime":"2018-06-15","AvgBoxOffice":36,"BoxOffice":1695881571,"Irank":31,"EnMovieID":667168},{"MovieName":"Dragon searching formula","AvgAudienceCount":40,"ReleaseTime":"2015-12-18","AvgBoxOffice":36,"BoxOffice":1682742863,"Irank":32,"EnMovieID":614981},{"MovieName":"Journey to the West subdues demons chapter","AvgAudienceCount":36,"ReleaseTime":"2017-01-28","AvgBoxOffice":39,"BoxOffice":1655926405,"Irank":33,"EnMovieID":619719},{"MovieName":"Hong Kong embarrassment","AvgAudienceCount":40,"ReleaseTime":"2015-09-25","AvgBoxOffice":33,"BoxOffice":1614103585,"Irank":34,"EnMovieID":618038},{"MovieName":"Jiang Ziya","AvgAudienceCount":19,"ReleaseTime":"2020-10-01","AvgBoxOffice":40,"BoxOffice":1602983421,"Irank":35,"EnMovieID":682630},{"MovieName":"Young you","AvgAudienceCount":16,"ReleaseTime":"2019-10-25","AvgBoxOffice":36,"BoxOffice":1559025893,"Irank":36,"EnMovieID":680681},{"MovieName":"Transformers 5: The Last Knight","AvgAudienceCount":23,"ReleaseTime":"2017-06-23","AvgBoxOffice":37,"BoxOffice":1551242789,"Irank":37,"EnMovieID":656946},{"MovieName":"Zootopia","AvgAudienceCount":28,"ReleaseTime":"2016-03-04","AvgBoxOffice":34,"BoxOffice":1534528494,"Irank":38,"EnMovieID":643235},{"MovieName":"Me and my parents","AvgAudienceCount":16,"ReleaseTime":"2021-09-30","AvgBoxOffice":43,"BoxOffice":1474411166,"Irank":39,"EnMovieID":706356},{"MovieName":"World of Warcraft","AvgAudienceCount":25,"ReleaseTime":"2016-06-08","AvgBoxOffice":37,"BoxOffice":1472297906,"Irank":40,"EnMovieID":402117},{"MovieName":"Avengers 2: the Austrian epoch","AvgAudienceCount":29,"ReleaseTime":"2015-05-12","AvgBoxOffice":40,"BoxOffice":1464392888,"Irank":41,"EnMovieID":631792},{"MovieName":"Charlotte's troubles","AvgAudienceCount":33,"ReleaseTime":"2015-09-30","AvgBoxOffice":32,"BoxOffice":1447823756,"Irank":42,"EnMovieID":628183},{"MovieName":"Speed and passion: special action","AvgAudienceCount":15,"ReleaseTime":"2019-08-23","AvgBoxOffice":36,"BoxOffice":1434299899,"Irank":43,"EnMovieID":682202},{"MovieName":"Give you a little red flower","AvgAudienceCount":12,"ReleaseTime":"2020-12-31","AvgBoxOffice":37,"BoxOffice":1432524430,"Irank":44,"EnMovieID":701874},{"MovieName":"youth","AvgAudienceCount":25,"ReleaseTime":"2017-12-15","AvgBoxOffice":34,"BoxOffice":1422584326,"Irank":45,"EnMovieID":659453},{"MovieName":"Jurassic World","AvgAudienceCount":33,"ReleaseTime":"2015-06-10","AvgBoxOffice":38,"BoxOffice":1420732578,"Irank":46,"EnMovieID":348959},{"MovieName":"Spider Man: Heroic expedition","AvgAudienceCount":17,"ReleaseTime":"2019-06-28","AvgBoxOffice":36,"BoxOffice":1417682748,"Irank":47,"EnMovieID":682139},{"MovieName":"Number one player","AvgAudienceCount":18,"ReleaseTime":"2018-03-30","AvgBoxOffice":36,"BoxOffice":1396660613,"Irank":48,"EnMovieID":657862},{"MovieName":"Speed and passion 9","AvgAudienceCount":13,"ReleaseTime":"2021-05-21","AvgBoxOffice":39,"BoxOffice":1392333894,"Irank":49,"EnMovieID":682199},{"MovieName":"Later we","AvgAudienceCount":21,"ReleaseTime":"2018-04-28","AvgBoxOffice":34,"BoxOffice":1361525311,"Irank":50,"EnMovieID":663327}]}}
url = "https://ys.endata.cn/enlib-api/api/home/getrank_mainland.do"
myData = {'top':'500','type':'1'}
res = requests.post(url,data=myData)
res = res.json()
print(len(res["data"]["table0"]))
dataDf = pd.DataFrame()
for myIndex,each in enumerate(res["data"]["table0"]):
dataDf = dataDf.append(pd.DataFrame({"MovieName":each["MovieName"],
"ReleaseTime":each["ReleaseTime"].split("-")[0],
"BoxOffice":each["BoxOffice"]},index=[myIndex]))
#kind:barh transverse bar graph
#figsize: picture size
#legend=False: do not display legend
#Color: set color
#fontsize: sets the label text size
#List [:: - 1] - > reverse order
dataDf[:20][::-1].plot("MovieName","BoxOffice",kind='barh',figsize=(16,8),fontsize=15,legend=False,
color=["grey","gold","darkviolet","turquoise","r","g","b","c",
"k","darkorange","lightgreen","plum", "tan","khaki", "pink", "skyblue","lawngreen","salmon"])
plt.savefig("before",dpi=500)
print(dataDf["ReleaseTime"].value_counts())
priceLevel = np.array([1/1000,1/350,1/157,1/100])*1000
plt.scatter([1990,2000,2010,2020],priceLevel)
ws = standRegres([[1,0],[1,10],[1,20],[1,30]],priceLevel)
plt.scatter([0,10,20,30],priceLevel,color="r")
x = np.linspace(0,30)
y = float(ws[0])+float(ws[1])*x
plt.xticks([0,10,20,30],[1990,2000,2010,2020])
plt.plot(x,y)
priceLevelNew = []
for each in range(10,32):
priceLevelNew.append(float(ws[0])+float(ws[1])*each)
for eachIndex in dataDf.index:
dataDf.loc[eachIndex,"priceLevel"] = priceLevelNew[int(dataDf.iloc[eachIndex]["ReleaseTime"])-2000]
dataDf["newBoxOffice"] = dataDf["BoxOffice"]*9.938608/dataDf["priceLevel"]
dataDf = dataDf.sort_values(by="newBoxOffice",ascending=False)
dataDf
dataDf[:20][::-1].plot("MovieName","newBoxOffice",kind='barh',figsize=(16,8),fontsize=15,legend=False,
color=["grey","gold","darkviolet","turquoise","r","g","b","c",
"k","darkorange","lightgreen","plum", "tan","khaki", "pink", "skyblue","lawngreen","salmon"])
plt.savefig("after",dpi=500)