background
Emotional analysis is used in my sister's graduation thesis. He has used crawler software to crawl various microblog accounts, and the text and comments on a topic are stored in excel.
Intends to use Baidu intelligent cloud, Natural Language Processing - > sentiment analysis.
realization
Get access_token
To use these two parameters
- client_id: required parameter, API Key applied;
- client_secret: required parameter, the applied Secret Key;
The specific location of these two parameters:
- First log in to the official website with baidu account: https://login.bce.baidu.com/?account=
- Find your product: natural language processing
- In the application, create a new application and enter a name and description
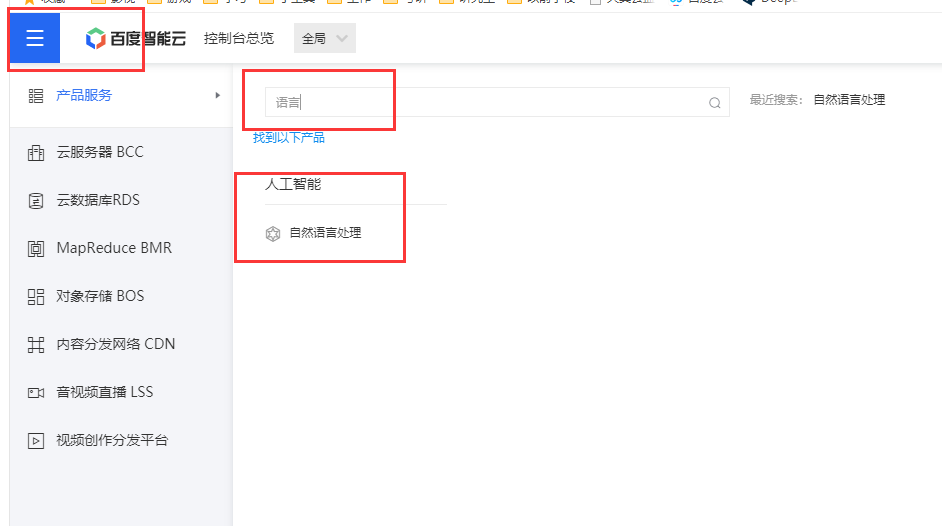
- You can see that we need to copy the two parameters API Key and Secret Key, and replace the following code.
def get_token():
API_Key = 'Copy and paste as above'
Scret_Key = 'Copy and paste as above'
url3 = 'https://aip.baidubce.com/oauth/2.0/token'
data3 = {
"grant_type":"client_credentials", # Fixed value
"client_id":API_KEY2, #
"client_secret":s_key2
}
resp3 = requests.post(url3,data=data3)
print("access_token:" ,resp3.json()['access_token'])
Request emotion analysis interface
import requests
import json,time
import re,os
# Remove the HTML code and emoticons in the text through the re module
def re_delete(content):
dr = re.compile(r'<[^>]+>', re.S)
emoji = re.compile("["u"\U0001F600-\U0001F64F"u"\U0001F300-\U0001F5FF"
u""u"\U0001F680-\U0001F6FF"u"\U0001F1E0-\U0001F1FF""]+", flags=re.UNICODE)
content = dr.sub('', content)
content = emoji.sub('', content)
return content
# Request Baidu interface, return positive probability, confidence, negative probability, classification result 0 negative, 1 neutral, 2 positive
def fenxi(tex = "I love my country"):
# headers = {'Content-Type': 'application/json'} # You can ask for it without adding it
tex = re_delete(tex) # If your text does not have HTML or emoticons, you can not use this
if not tex:
return []
access_token = '24.37f133deb9fefa877cf39583244079f8.2592000.1640158969.282335-25209811'
url = f'https://aip.baidubce.com/rpc/2.0/nlp/v1/sentiment_classify?access_token={access_token}&charset=UTF-8'
if len(tex.encode()) < 2048: # The length of text bytes written in the document is up to 2048 bytes, which is almost 680 Chinese characters
body = {'text' : tex}
# Convert python dictionary type to json type
body = json.dumps(body)
# print(body)
resp1 = requests.post(url=url,data=body)
try:
items = resp1.json()['items'][0]
# round(x,3) means to keep the floating point number x to three decimal places
return [round(items['positive_prob'],3), round(items['confidence'],3),
round(items['negative_prob'],3), items['sentiment']]
except:
print("The request is incorrect\n",resp1.text)
# The printed error code can be compared with the official document
return ["The request is incorrect"]
else:
print("Byte encoding length exceeds 2048\n",tex)
# Because my text is generally not so long, I won't continue to analyze it. You can split the text here and call the interface
return ["The length is too long"]
if __name__ == '__main__':
# get_token()
result = fenxi("I love my country")
print(result)
Official documents: https://cloud.baidu.com/apiexplorer/index.html?Product=GWSE -p64nCQphmTY&Api=GWAI-7WcMrFnWb8M
You can view the parameter description and online call attempt at the above website, which is more detailed than that written in the previous document.
Read text operation
- The request interface is successful, and then the difference code reads the text in batch to make a request
- Everyone's text is different. Maybe csv,excel,txt and so on will not be written in detail here
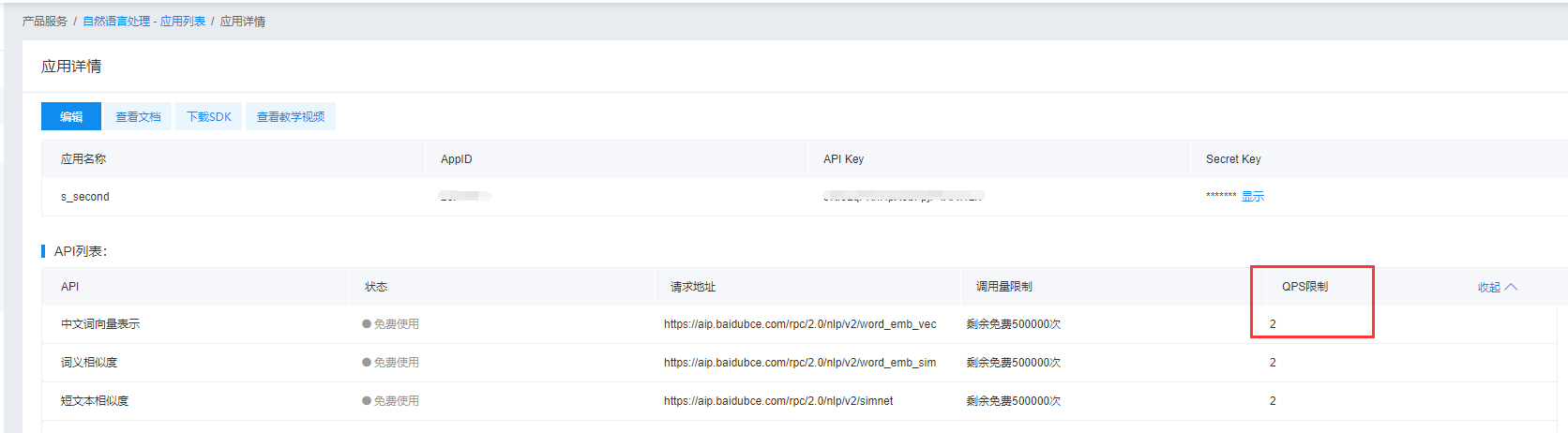
- A reminder is that Baidu has a QPS limit, that is, it can request several times a second at most. If there are many requests, it will return an error
- When you request, just add time.sleep(0.5). The number of 0.5 is 1/qQPS
- Of course, you can also spend money. There will be a lot of requests. You can find more Baidu accounts and get more access_ Just a token
- pycharm can run multiple py codes at the same time (there are still restrictions on applying for access_token s of different applications for the same account)
- Thank you for reading. If you think it's useful, you might as well give a compliment before you go