
Guide: in order to improve the editing efficiency of good-looking creators, fast editing improves the editing efficiency by intelligently identifying subtitles, repeated sentences and blank sentences in the video, and clearing invalid clips with one click. This article aims to share with you the construction path of fast editing and the problems encountered in the process of practice.
The full text is 5886 words and the expected reading time is 15 minutes.
1, Design background
As a pan knowledge video editing tool produced by Baidu, Duca clip carries the editing work of the creator, and fast clip mainly solves the problem of quickly removing invalid clips.

-
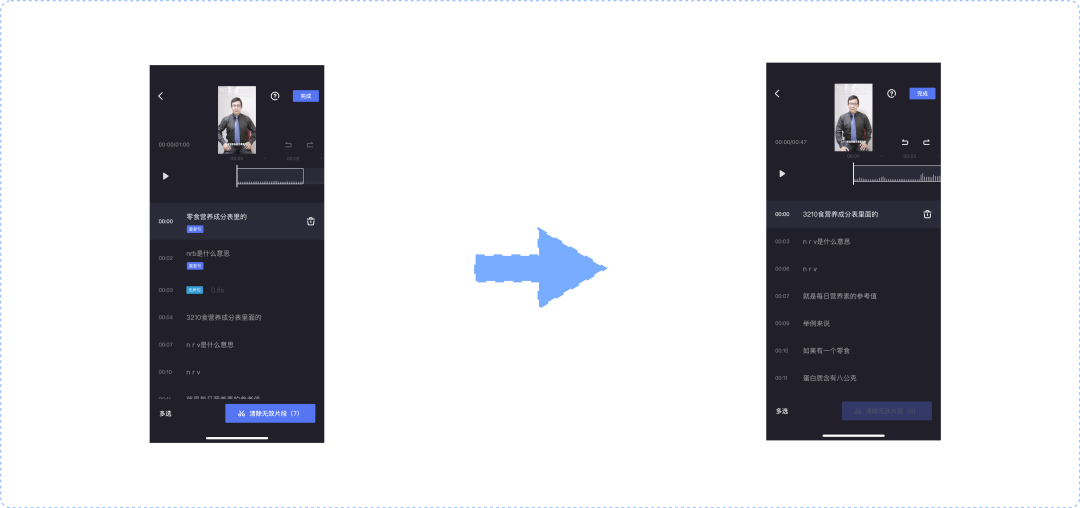
Trim clip
Usually, when we trim clips, we need to manually jump to the approximate position, and then play the video to locate the specific position to be trimmed. Quick clip identifies the subtitles in the video through NLP, aligns and displays them according to the video timeline, and then maps the video time segments through the subtitle duration to quickly trim them.
-
Tone, pause, repetition
Due to the particularity of Pan knowledge video, tone, pause and repeated sentences often appear in the recording process of creators. If we need to trim similar clips, we can only judge manually by playing video, and the operation is cumbersome.
Based on the audio extracted from the video, the fast clip marks the segments with tone with the help of NLP, and then directly marks the silent segment area through the time gap between subtitles. Repeated sentences can be marked by calculating the character repetition of adjacent sentence patterns.
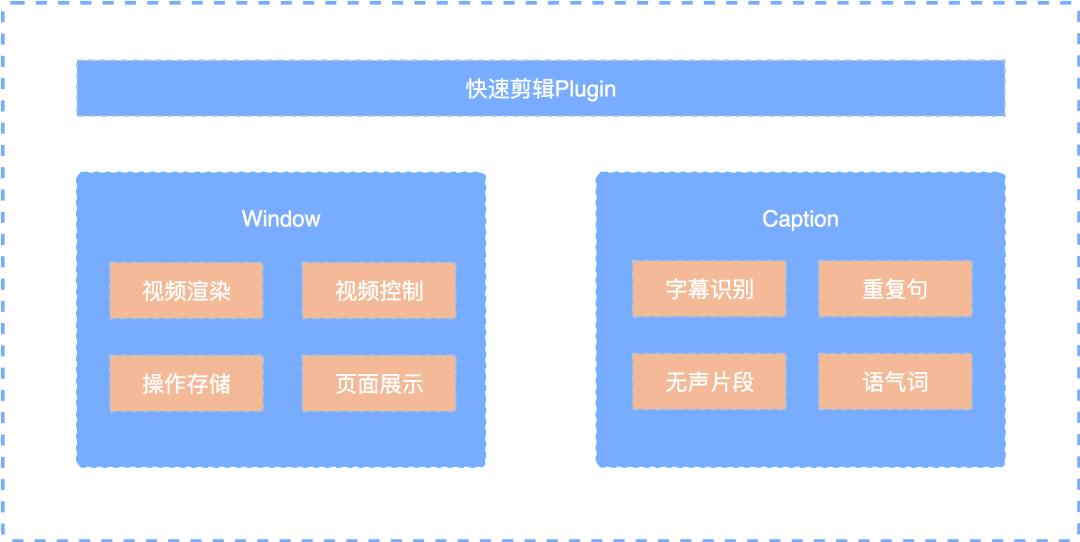
2, Overall architecture
-
Plugin: used to show the quick shear controller.
-
Window: for rendering and video control.
-
Caption: used for caption display and operation.
2.1 Window
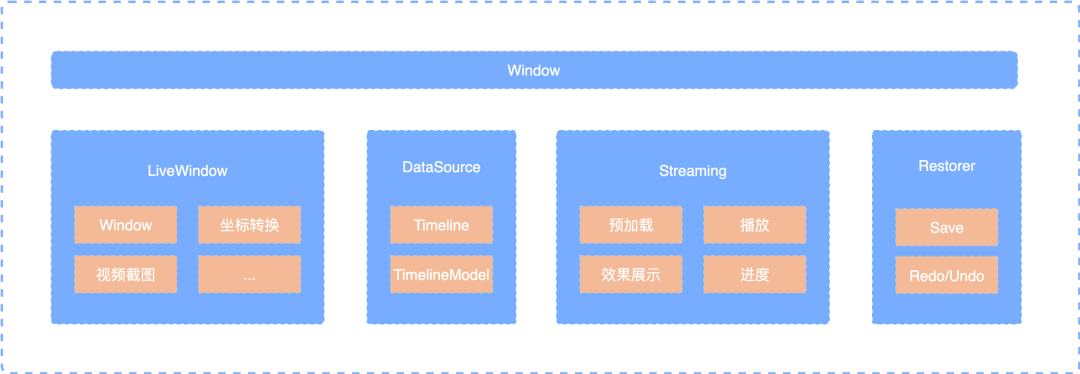
Window mainly includes video rendering, control and Undo functions:
-
Timeline: store clip data of video; TimelineModel: stores data information such as stickers and subtitles.
-
Streaming: responsible for rendering Timeline and TimelineModel data information, video preloading, playback control, progress callback, etc.
-
LiveWindow: used to display the View rendered by Streaming, adjust the size background, coordinate conversion, etc.
-
Restorer: used to save user operations and undo and redo them.
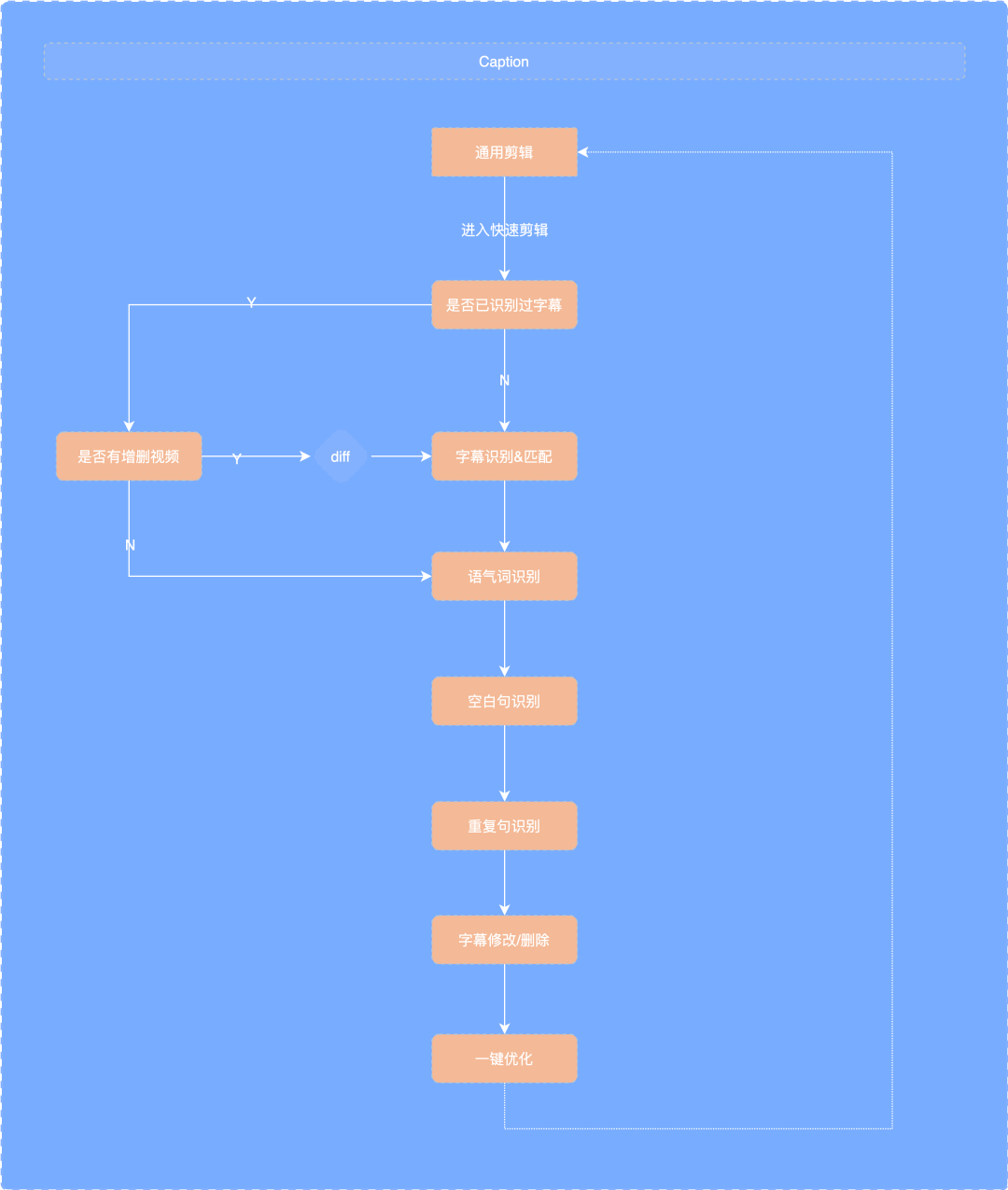
2.2 Caption
Caption contains the main functions of quick cutting: subtitle recognition, subtitle matching, modal particles, repeated sentences, etc.
-
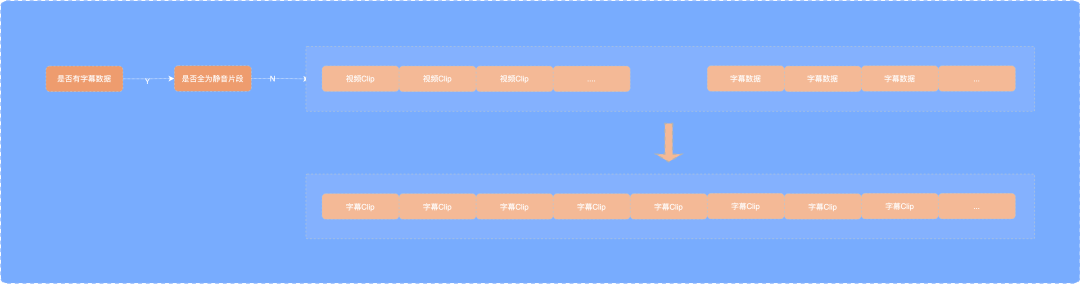
When entering the quick clip page, it will first detect whether the subtitle has been recognized. If N, it will extract the video and audio and upload it to the back end for NLP analysis to obtain the subtitle and tone segment data.
Since the obtained subtitles only contain valid fragments, the subtitles need to be time matched with the timeline.
(video information is stored by clip objects, and each clip object represents a separate video clip. A clip contains trimIn, trimOut, inPoint and outPoint. These data are used to determine which video clip is displayed and where the video is displayed. Similarly, the text is placed in the correct position through the clip data of subtitles.)
-
If there is already a subtitle file, compare whether there is an added video since the last recognition. If there is a new video, extract the video without subtitle recognition and send it to the back end for NLP analysis and recognition.
-
If there is no new video after comparison, it will directly enter the blank sentence recognition stage.
-
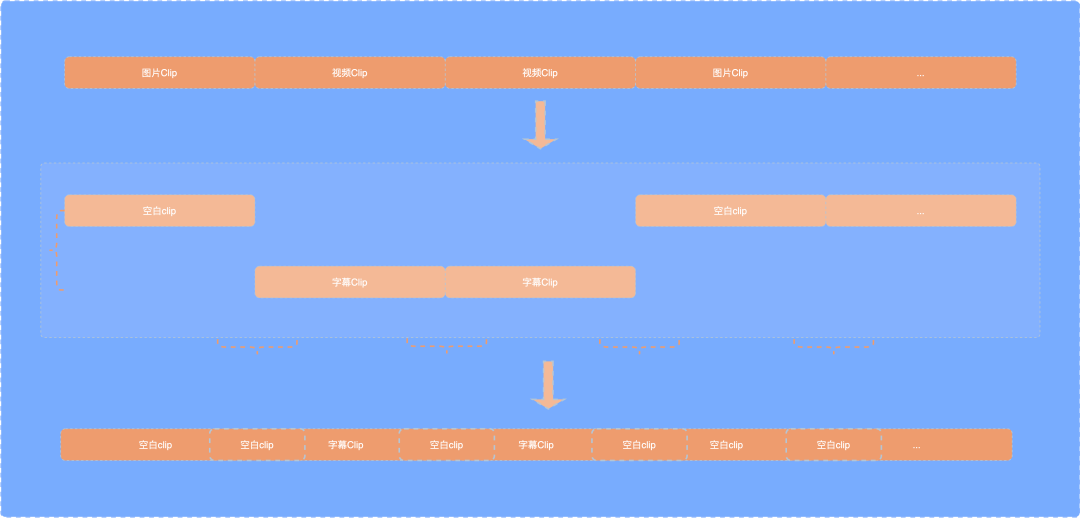
Based on the caption clip and video clip data obtained above, a blank caption clip is added to adjacent subtitles according to the blank sentence rules.
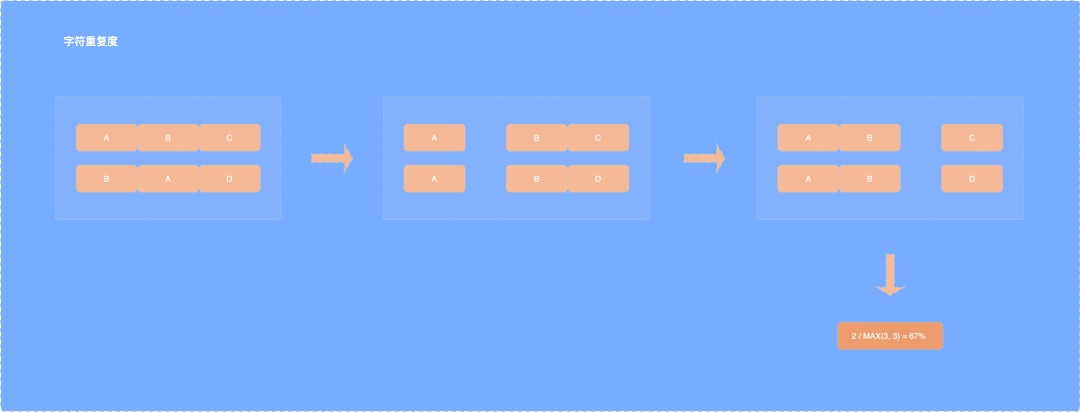
- At present, the above and below four sentences of quick cut repeated sentences, which are longer than 3 and must contain Chinese, are the judgment conditions. The repetition rate is calculated by integrating three strategies: character repetition, levinstein distance and cosine similarity.
/**
* Character repetition
*/
private func similarity(s1: String, s2: String) -> Float {
var simiCount: Float = 0
var string2Array = [String]()
for i in 0..<s2.count {
// Intercept from any position to any position and close the interval
let string = subOneString(string: s2, from: i)
string2Array.append(string)
}
for i in 0..<s1.count {
let string1 = subOneString(string: s1, from: i)
if string2Array.contains(string1) {
let index2 = string2Array.firstIndex(of: string1)
string2Array.remove(at: index2!)
simiCount = simiCount + 1
}
}
if simiCount == 0 {
return 0.0
}
let rate: Float = simiCount / Float(max(s1.count, s2.count))
return rate
}
/**
* Levinstein distance is a kind of editing distance. Refers to the minimum number of editing operations required to convert from one string to another between two strings.
*/
-(CGFloat)levenshteinDistance:(NSString *)s1 compare:(NSString *)s2 {
NSInteger n = s1.length;
NSInteger m = s2.length;
// A string is empty
if (n * m == 0) {
return n + m;
}
// DP array
int D[n + 1][m + 1];
// Boundary state initialization
for (int i = 0; i < n + 1; i++) {
D[i][0] = i;
}
for (int j = 0; j < m + 1; j++) {
D[0][j] = j;
}
// Calculate all DP values
for (int i = 1; i < n + 1; i++) {
for (int j = 1; j < m + 1; j++) {
int left = D[i - 1][j] + 1;
int down = D[i][j - 1] + 1;
int left_down = D[i - 1][j - 1];
NSString *i1 = [s1 substringWithRange:NSMakeRange(i - 1, 1)];
NSString *j1 = [s2 substringWithRange:NSMakeRange(j - 1, 1)];
if ([i1 isEqualToString:j1] == NO) {
left_down += 1;
}
D[i][j] = MIN(left, MIN(down, left_down));
}
}
NSInteger maxLength = MAX(s1.length, s1.length);
CGFloat rate = 1.0 - ((CGFloat) D[n][m] / (CGFloat)maxLength);
returnrate;
}
/**
* Cosine similarity: first vectorize the string, and then find the cosine value of the angle between their vectors in a plane space.
*/
-(CGFloat)cos:(NSString *)s1 compare:(NSString *)s2 {
NSMutableSet *setA = [NSMutableSet new];
for (int i = 0; i < [s1 length]; i++) {
NSString *string = [s1 substringWithRange:NSMakeRange(i, 1)];
[setA addObject:string];
}
NSMutableSet *setB = [NSMutableSet new];
for (int i = 0; i < [s2 length]; i++) {
NSString *string = [s2 substringWithRange:NSMakeRange(i, 1)];
[setB addObject:string];
}
// Statistical word frequency
NSMutableDictionary *dicA = [NSMutableDictionary new];
NSMutableDictionary *dicB = [NSMutableDictionary new];
for (NSString *key in setA) {
NSNumber *value = dicA[key];
if (value == nil) {
value = @(0);
}
NSNumber *newValue = @([value integerValue] + 1);
dicA[key] = newValue;
}
for (NSString *key in setB) {
NSNumber *value = dicB[key];
if (value == nil) {
value = @(0);
}
NSNumber *newValue = @([value integerValue] + 1);
dicB[key] = newValue;
}
// Vectorization, union
NSMutableSet *unionSet = [setA mutableCopy]; //After union
[unionSet unionSet:setB];
NSArray *unionArray = [unionSet allObjects];
NSMutableArray *aVec = [[NSMutableArray alloc] initWithCapacity:unionSet.count];
NSMutableArray *bVec = [[NSMutableArray alloc] initWithCapacity:unionSet.count];
for (NSInteger i = 0; i < unionArray.count; i++) {
[aVec addObject:@(0)];
[bVec addObject:@(0)];
}
for (NSInteger i = 0; i < unionArray.count; i++) {
NSString *object = unionArray[i];
NSNumber *numA = dicA[object];
if (numA == nil) {
numA = @(0);
}
NSNumber *numB = dicB[object];
if (numB == nil) {
numB = @(0);
}
aVec[i] = numA;
bVec[i] = numB;
}
// Calculate the three parameters separately
NSInteger p1 = 0;
for (NSInteger i = 0; i < aVec.count; i++) {
p1 += ([aVec[i] integerValue] * [bVec[i] integerValue]);
}
CGFloat p2 = 0.0f;
for (NSNumber *i in aVec) {
p2 += ([i integerValue] * [i integerValue]);
}
p2 = (CGFloat)sqrt(p2);
CGFloat p3 = 0.0f;
for (NSNumber *i in bVec) {
p3 += ([i integerValue] * [i integerValue]);
}
p3 = (CGFloat)sqrt(p3);
CGFloat rate = ((CGFloat) p1) / (p2 * p3);
return rate;
}
-
Because refreshing the timeline is very performance-consuming, when deleting subtitles, you can only modify the subtitle clip data source, refresh the tableview display below, and then refresh the timeline when the user exits, so as to avoid the performance problems caused by real-time refresh.
-
After one click optimization, the subtitle data is returned to the general clip for caching and display, which is also convenient to enter the fast clip again.
3, Thinking and summary
Because caption recognition is carried out at the remote end and heavily depends on the network, Duca will pass in the future Flying oar Complete audio source data analysis, subtitle, repetition, tone and other segment recognition in the terminal, enhance timeliness and data security, and save traffic storage cost. The above is the path practice of the whole quick editing one key intelligent editing. I hope this article can let you gain and learn from it.
Recommended reading:
| implementation of large-scale service governance application based on etcd
| short video personalized Push project
| architecture and practice of Baidu aifanfan data analysis system
---------- END ----------
Baidu Geek said
The official account of Baidu technology is on the line.
Technology dry goods, industry information, online salon, industry conference
Recruitment Information · internal push information · technical books · Baidu peripheral
Welcome to pay attention