introduction
1, Results
1.1 reading images

1.2 after blob analysis

2, Halcon code
*
* bottle.hdev: Segment and read numbers on a beer bottle
*
* Step 0: Preparations
* Specify the name of the font to use for reading the date on the bottle.
* It is easiest to use the pre-trained font Industrial_0-9_NoRej. If you
* have run the program bottlet.hdev in this directory, you can activate
* the second line to use the font trained with this program.
FontName := 'Industrial_0-9_NoRej'
* FontName := 'bottle'
*
* Step 1: Segmentation
// Turns on or off the automatic output of icon output objects to the graphics window during program execution
dev_update_window ('off')
read_image (Bottle, 'bottle2')
get_image_size (Bottle, Width, Height)
dev_close_window ()
dev_open_window (0, 0, 2 * Width, 2 * Height, 'black', WindowID)
set_display_font (WindowID, 16, 'mono', 'true', 'false')
dev_display (Bottle)
disp_continue_message (WindowID, 'black', 'true')
stop ()
*
* Create Automatic Text Reader and set some parameters
//create_text_model_reader — Create a text model.
create_text_model_reader ('auto', FontName, TextModel)
* The printed date has a significantly higher stroke width
//set_text_model_param — Set parameters of a text model
set_text_model_param (TextModel, 'min_stroke_width', 5)
* The "best before" date has a particular and known structure
set_text_model_param (TextModel, 'text_line_structure', '2 2 2')
*
* Read the "best before" date
//find_text — Find text in an image.
find_text (Bottle, TextModel, TextResultID)
*
* Display the segmentation results
*// get_text_object - an icon value of the query text segmentation result
get_text_object (Characters, TextResultID, 'all_lines')
dev_display (Bottle)
dev_display (Characters)
stop ()
* Display the reading results
* //get_text_result - control value of query text segmentation result
get_text_result (TextResultID, 'class', Classes)
//area_center — Area and center of regions
area_center (Characters, Area, Row, Column)
for Index := 0 to |Classes| - 1 by 1
disp_message (WindowID, Classes[Index], 'image', 80, Column[Index] - 3, 'green', 'false')
endfor
*
* Free memory
* //clear_text_result - clear text result
clear_text_result (TextResultID)
//clear_text_model — Clear a text model
clear_text_model (TextModel)
3, Case main operator analysis
1.create_text_model_reader (Operator)
create_text_model_reader - create text model
function
create_text_model_reader( : : Mode, OCRClassifierMLP : TextModel) //parameter Mode (input_control) //The Mode of the text model. Default value: 'auto' List of values: 'auto', 'manual' OCRClassifierMLP (input_control) //OCR classifier Default value: 'Industrial_Rej.omc' Suggested values: 'Document_A-Z+_NoRej.omc', 'Document_0-9A-Z_NoRej.omc', 'Document_0-9_NoRej.omc', 'Document_NoRej.omc', 'Document_A-Z+_Rej.omc', 'Document_0-9A-Z_Rej.omc', 'Document_0-9_Rej.omc', 'Document_Rej.omc', 'DotPrint_A-Z+.omc', 'DotPrint_0-9A-Z.omc', 'DotPrint_0-9.omc', 'DotPrint_0-9+.omc', 'DotPrint.omc', 'HandWritten_0-9.omc', 'Industrial_A-Z+_NoRej.omc', 'Industrial_0-9A-Z_NoRej.omc', 'Industrial_0-9_NoRej.omc', 'Industrial_0-9+_NoRej.omc', 'Industrial_NoRej.omc', 'Industrial_A-Z+_Rej.omc', 'Industrial_0-9A-Z_Rej.omc', 'Industrial_0-9_Rej.omc', 'Industrial_0-9+_Rej.omc', 'Industrial_Rej.omc', 'MICR.omc', 'OCRB_A-Z+.omc', 'OCRA_0-9A-Z.omc', 'OCRA_0-9.omc', 'OCRA.omc', 'OCRB_A-Z+.omc', 'OCRB_0-9A-Z.omc', 'OCRB_0-9.omc', 'OCRB.omc', 'OCRB_passport.omc', 'Pharma_0-9A-Z.omc', 'Pharma_0-9.omc', 'Pharma_0-9+.omc', 'Pharma.omc', 'SEMI.omc' TextModel (output_control) //New text model.
create_text_model_reader creates a TextModel that describes how to use find_ Texttext to split.
The parameter value of Mode determines which text segmentation method to use. Possible values are automatic and manual.
Generally, the parameter Mode should be set to "auto" because this Mode is more stable and requires less configuration work. Note that in this case, the OCR classifier must also be passed in the OCR classifier MLP. The Mode must be set to manual only if one of the following restrictions applies:
- The lattice needs to be segmented.
- It is necessary to segment text with strong local changes in polarity. For example, carved text usually has strong local variations due to reflection.
- No suitable MLP based OCR classifier is available (see below).
If Mode = 'auto', then find_ Textcan extract text of any size. You can limit the search to characters with specific properties. For more information, see set_text_model_param. In addition, the OCR classifier must be passed in the OCRClassifierMLP. The OCR classifier must be based on multi-layer perceptron (MLP). In addition, it is strongly recommended to use an OCR classifier that provides a rejection class (see set_rejection_params_ocr_class_mlp) and train with regularization parameters (see set_regularization_params_ocr_class_mlp). A suitable OCR classifier can use create_ocr_class_mlp create or use read_ocr_class_mlp read. You can also pass a string containing a path to a used write_ocr_class_mlp stored OCR classifier.
To enable text segmentation when Mode = 'manual', you must use set_text_model_param sets reasonable parameters for the text model, including the expected character height and width. In this case, the value of OCRClassifierMLP will be ignored.
TextModel parameters can be set_text_model_param and get_text_model_param to set and query.
2.set_text_model_param (Operator)
3.find_text
4.get_text_object
set_text_model_param — Set parameters of a text model.
function
set_text_model_param( : : TextModel, GenParamName, GenParamValue : ) //parameter TextModel (input_control, state is modified) //Text model. GenParamName (input_control) //The name of the parameter to set. Default value: 'min_contrast' List of values: 'add_fragments', 'base_line_tolerance', 'char_height', 'char_width', 'eliminate_border_blobs', 'eliminate_horizontal_lines', 'fragment_size_min', 'is_dotprint', 'is_imprinted', 'max_char_height', 'max_char_width', 'max_line_num', 'max_stroke_width', 'min_char_height', 'min_char_width', 'min_contrast', 'min_stroke_width', 'mlp_classifier', 'persistence', 'polarity', 'return_punctuation', 'return_separators', 'return_whole_line', 'stroke_width', 'text_line_separators', 'text_line_structure', 'text_line_structure_0', 'text_line_structure_1', 'text_line_structure_2', 'uppercase_only' GenParamValue (input_control) //Parameter value to set Default value: 10 List of values: 'auto', 'both', 'dark_on_light', 'false', 'light_on_dark', 'true'
set_text_model_param sets the parameters of the text model. The list of allowed parameter values for GenParamName varies depending on the use of create_ text_ model_ The mode set when the reader creates a text model. The parameter values of the text model with Mode = 'auto' are listed first, and then the parameter values of the text model with Mode = 'manual'.
The name and value of the parameter must be given in GenParamName and GenParamValue. The following values are possible:
Mode = text model parameter of 'auto'
'min_contrast': The minimum contrast between the character and its surrounding background. Value list: the integer or floating-point value of byte image is between 1 and 255, and uint2 The integer or floating-point value of the image is between 1 and 65.535 between Default: 15
'polarity': 'dark_on_light'If the text to be segmented is darker than its background, 'light_on_dark'If the text to be split is brighter than its background,'both'If both texts are segmented. List of values: 'dark_on_light', 'light_on_dark', 'both' Default value: 'both'
min_char_height': The minimum height of the character in pixels. If you want to split text of any height, you can pass'auto'. Please note that, 'min_char_height' Only characters. The height of punctuation marks or separators is not affected“ min_char_height"Limitations.
'max_char_height': The minimum height (in pixels) of a character. If you want to split text of any height, you can pass'auto'. Please note that, 'min_char_height' Only characters. The height of punctuation marks or separators is not affected“ min_char_height"Limitations. List of values: integer or float value greater or equal to 1 Default value: 'auto'
'min_char_width': The minimum width of a character in pixels. If you want to split text of any width, you can pass 'auto'. Please note that, 'min_char_width' Only characters. The width of punctuation marks or separators is not affected“ min_char_width"Limitations. List of values: integer or float value greater or equal to 1 Default value: 'auto'
'max_char_width': The maximum width of a character in pixels. If you want to split text of any width, you can pass 'auto'. Please note that, "max_char_width"Only characters. The width of punctuation marks or separators is not affected“ max_char_width"Limitations. List of values: integer or float value greater or equal to 1 Default value: 'auto'
'min_stroke_width': The minimum stroke width of a character in pixels. If you want to automatically estimate the minimum stroke width during text segmentation, Can be passed“ auto". Please note“ min_stroke_width"Only characters. The stroke width of punctuation marks or separators is not affected“ min_stroke_width"Limitations. List of values: integer or float value greater or equal to 1 Default value: 'auto' 'max_stroke_width': The maximum stroke width of a character in pixels. If you want to automatically estimate the maximum stroke width during text segmentation, Can be passed“ auto". Please note“ max_stroke_width"Only characters. The stroke width of punctuation marks or separators is not affected“ max_stroke_width"Limitations. List of values: integer or float value greater or equal to 1 Default value: 'auto'
'eliminate_border_blobs': True if the area touching the boundary of the image domain should be discarded, otherwise false. List of values: 'true','false' Default value: 'false'
'return_punctuation': Of punctuation marks (for example, dots or commas)'true'Should also be returned. If punctuation should not be returned; otherwise 'false'. List of values: 'true','false' Default value: 'true' 'return_separators': If you should also return a minus or equal sign separator; otherwise 'true'. If the delimiter should not be returned; otherwise 'false'. List of values: 'true','false' Default value: 'true'
'add_fragments': If the clip (for example“ i"Point on) should be added to the segmented character; otherwise'true',Otherwise, it is "false". Please note that, This may cause noise to be added to segmented characters. List of values: 'true','false' Default value: 'true'
'text_line_structure': To simplify the search for a specific structure in segmented text, such as a date or serial number, you can define a text line structure. For each text line, the distances between characters are calculated, and the text line is divided into text blocks according to these distances. '.','_' and '-' Short characters such as are ignored and treated as spaces in this process. In addition,You can define user specific delimiters, These delimiters are also ignored. For more information, see“ text_line_separators"Description of the. Then test whether any user-defined text line structure is suitable for the generated text block. For example, if the text to find is a date that contains two characters, month, day, and year, the structure will be "2". If the year may consist of two or four characters, the structure is "2"-4",Indicates that the last character block consists of two to four characters By appending an index to the parameter name, multiple structures can be provided to match, for example'text_line_structure_0','text_line_structure_1'. If 'text_line_structure' Set to empty string ' ',The text to find can have any structure. Note that each text line structure found is saved as a unique text line in the text result. Therefore, When called get_text_object When, the "line" refers to a valid text line structure. If you want to return the entire text line containing the text line structure, you can set it accordingly 'return_whole_line'. Default value: ' ' 'text_line_separators': A string containing a list of characters to ignore when looking for text line structure. For more information, See“ text_line_structure". Note that the user specific delimiter must be the one used OCR classifier Valid characters in. For example, if you want to ignore ':' and '\',Should be passed ':\\'. Please note that, '\' Any special symbol is escaped to treat it as text, so it needs to be passed '\\' To use '\' As a separator. List of values: '/',':', ':\\' , '\\/:' ,... Default value: ' '
5.get_text_result (Operator)
get_text_result - control value of query text segmentation result
function
get_text_result( : : TextResultID, ResultName : ResultValue) //parameter TextResultID (input_control) //Text result. ResultName (input_control) //Name of the result to be returned. Default value: 'class' List of values: 'class', 'class_line', 'confidence', 'confidence_line', 'num_lines', 'polarity', 'polarity_line', 'thresholds' ResultValue (output_control) //Value of ResultName.
get_text_result query find_text Returned TextResultID Control results ResultName. ResultName The possible parameter values will be different, Depending on find_text The text model used in the text segmentation process. Listed below first Mode = 'auto'Possible parameter values of the text model, And then Mode = 'manual'Parameter values of text model:
Step results
- Step 1: Segmentation

- Display the segmentation results
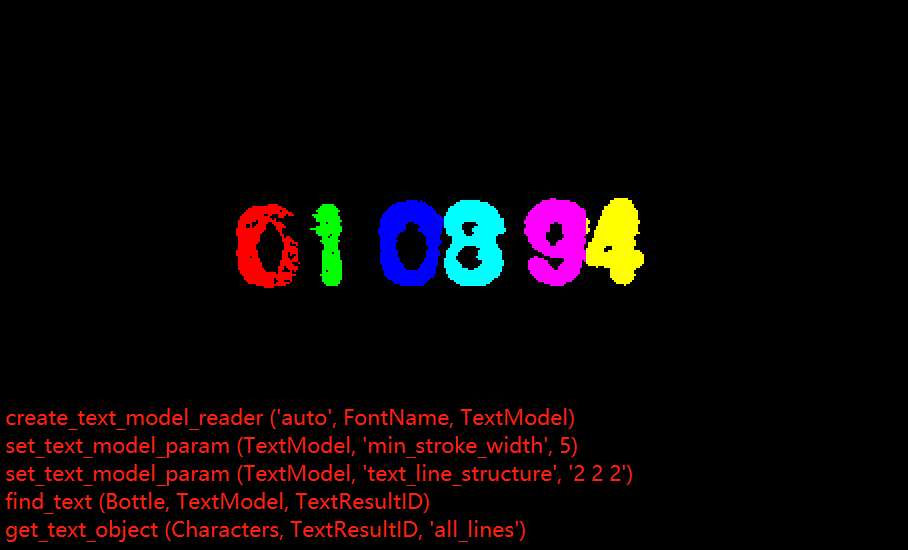
- Display the reading results
